-
MySQL (2) DQL
DQL(Data Query Language数据查询语言),查询数据
操作须知
※ where条件要用字段名(不能用别名)去做限制
※ ●运算符:sql语句中可以进行数学运算(+ - × ÷) //如果非数值类型(可以是varchar类型的数字)参与运算,结果为null
●比较符:大于> 小于< 大于等于>= 小于等于<= 不等于<>
●逻辑符:与AND或OR非NOT
●判空:不能用=,要用IS NULL或IS NOT NULL
※ 表达式:●NOW()当前日期时间 CURDATE()当前日期 CRUTIME()当前时间
●DATE_SUB/DATE_ADD('2020-10-20 16:30:30',INTERVL n DAY/MONTH/YEAR)得到指定日期时间前/后n天/月/年的日期时间
●IF(boolean结果,'值1','值2')true为'值1',false为'值2' IFNULL(字段,'替换值')如果字段为null,会被"替换值"替换
●FLOOR('小数')去掉小数取整 RAND()生成一个0~1之间的小数 //FLOOR(RAND()*100)生成0~99的随机整数
●LENGTH(字段)字符串所占的字节数
CHAR_LENGTH(字段)字符串长度
●DATE_FORMAT(字段,'%Y-%m-%d %H:%i:%s')将日期时间转换为对应的格式
●EXIST(子查询)返回true/false,检查子查询是否有结果
1 单表查询
1.1 范围查询
SELECT*FROM 表名 WHERE 字段 BETWEEN 最小值 AND 最大值 //(包含"最小值"和"最大值")这种方式只能作用于"数值数据" //范围查询(BETEEN,<,>)不走索引
SELECT*FROM 表名 WHERE 字段 IN (值1,值2...) //可以作用于"非数值数据"
1.2 模糊查询
SELECT*FROM 表名 WHERE 字段 (NOT)LIKE '_字符串%' //通配符:_表示一个字符,%表示0个或多个字符
SELECT*FROM 表名 WHERE CHAR_LENGTH(字段)<100 //找某个字段中长度小于100的数据
1.3 去重查询
SELECT DISTINCT * FROM 表名 //DISTINCT(放于所有字段最前面):去掉所查的完全相同的记录
1.4 正则查询
SELECT * FROM 表名 WHERE 字段 REGEXP '正则表达式' //只查询指定字段符合'正则表达式'的记录
1.5 替换查询
SELECT REPLACE(字段名,'值1','值2') FROM 表名 //部分替换,将指定字段的数据中包含的所有'值1'替换为'值2'
SELECT CASE 字段 WHEN 'aaa' THEN 'AAA' WHEN 'bbb' THEN 'BBB' END FROM 表名 //完全替换,如果字段的值是'aaa'就替换为'AAA',如果字段的值是'bbb'就替换为'BBB',不能完全匹配的显示Null
1.6 排序查询
SELECT * FROM 表名 ORDER BY 字段1 ASC,字段2 DESC //查到的记录先按字段1升序(ASC(默认)),再按字段2降序 (DESC)
ORDER BY RAND() //对查询的记录随机排序
SELECT * FROM 表名 ORDER BY RAND() LIMIT 2 //获取随机查询的前2条记录
1.7 聚合+分组查询
1.7.1 聚合查询(只有1行)
COUNT(字段) //统计字段数据个数(不会统计null) COUNT(*) //统计记录数(会统计null)
SUM(字段) //求和 AVG(字段) //平均值(不统计null) MAX()/MIN()最大/小值
1.7.2 分组查询(针对"聚合查询")
SELECT COUNT(*) FROM 表名 where 筛选条件 GROUP BY 分组字段1,分组字段2... HAVING 分组筛选条件 //WHERE在分组前执行(只能操作原始表字段),HAVING在分组后执行(可以操作聚合函数字段)
GROUP BY DAY/WEEK/MONTH/YEAR(日期时间字段) //按每日/周/月/年分组
1.8 分页查询
SELECT * FROM 表名 LIMIT A,B //A:跳过的记录数(不写默认0),B:每页显示的记录数
1.9 拼接查询
CONCAT(A,B......) //将多个字符串拼接成1个字符串 //A,B....可以是字段名,也可以是自定义的字符串 //A,B......只要有一个null,拼接结果就是null
CONCAT_WS(separator,A,B......) //与CONCAT类似,但字符之间用separator(分隔符)分隔
GROUP_CONCAT(A,B......) //作用于"聚合查询"或"分组查询",在CONCAT的基础上再进行拼接,多列合成一列(默认用","隔开)
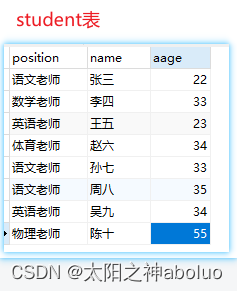
- # 聚合查询
- SELECT count(*), group_concat( NAME, age ) FROM teacher;

- # 分组查询
- SELECT position, group_concat( NAME, age ) FROM teacher GROUP BY position;

SELECT position, group_concat(CONCAT_WS('_', NAME, age) ORDER BY age DESC SEPARATOR '&') FROM teacher GROUP BY position;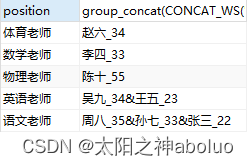
2 多表查询
WHERE和HAVING的区别:见"分组查询"
WHERE和ON对于内连接没区别:
对内连接来说:没区别
对外连接来说:WHERE只会显示符合条件的记录,ON会将一张表中不符合条件的记录也显示(左/右外连接一点要用ON,否则会报错),当然WHERE可以再对外连接ON条件后生成的临时表进行进一步过滤
2.1 内连接
只查询2张表之间有关联条件的数据
SELECT * FROM 表1,表2,表3... WHERE 关联条件 AND 筛选条件
2.2 外连接
查一张表的全部数据和领一张表的关联数据
2.2.1 左外连接
SELECT * FROM 表1 LEFT JOIN 表2 ON 关联条件1 AND 关联条件2... WHERE 筛选条件
2.2.2 右外连接
SELECT * FROM 表1 RIGHT JOIN 表2......
2.2.3 全外连接
全外连接,即求多张表的并集,但MySQL不支持全外连接的查询,但可以通过UNION语句实现
SELECT * FROM 表1 LEFT JOIN 表2 ON 关联条件 UNION SELECT * FROM 表1 RIGHT JOIN 表2 ON 关联条件
2.3 子查询
2.3.1 一行一列(一个值)
SELECT * FROM 表名 WHERE id = (SELECT MAX(id) FROM 表名)
2.3.2 多行一列(一个集合)
SELECT * FROM 表名 WHERE id IN (SELECT id FROM 表名 WHERE id<10)
2.3.3 多行多列(一个虚拟表:虚拟表都要起别名)
SELECT 表1.a , 表1.b , 表3.x , 表3.y FROM 表1 LEFT JOIN (SELECT * FROM 表2 WHERE id<10) 表3 ON 关联条件
2.4 叠加查询
SELECT 字段1,字段2 FROM 表1 UNION SELECT 字段3,字段4 FROM 表2 //UNION前表记录与UNION后表记录叠加(列数要相同,字段名取前表的) //UNION会将叠加后的记录去重,UNION ALL不会去重
3 SQL执行顺序
多表关联(ON) >> 条件(WHERE) >> 聚合 >> 分组(GROUP) >> 分组过滤(HAVING) >> 排序(ORDER BY) >> 分页(LIMIT)
-
相关阅读:
扫地机器人地图与用户终端的同步
Rockwell EDI 850 采购订单报文详解
如何解决mkdir()提示No such file or directory?
【MySQL系列】 MySQL表的增删改查(进阶)
可变性隔离
冒泡排序、插入排序、选择排序和快速排序的原理
操作系统基础知识1
华为机试 - 欢乐的周末
从中序与后序遍历序列构造二叉树
Weblogic各版本历史
- 原文地址:https://blog.csdn.net/SunnerChen/article/details/132645076