-
大数据技术之Hadoop:提交MapReduce任务到YARN执行(八)
目录
一、前言
我们前面提到了MapReduce,也说了现在几乎没有人再写MapReduce代码了,因为它已经过时了。然而不写代码不意味着它没用,当下很火的HIve技术就到了MapReduce,所以MapReduce还是相当重要的。
但是本章我们暂时不用管MapReduce程序是如何编写的,它的语法结构是什么,我们通过Hadoop系统自带MapReduce示例程序到YARN运行。目的是让各位有一个直观的认识。
在部署并成功启动YARN集群后,我们就可以在YARN上运行各类应用程序了。
YARN作为资源调度管控框架,其本身提供资源供许多程序运行,常见的有:
- MapReduce程序
- Spark程序
- Flink程序
Spark和Flink是大数据后续的学习内容,我们目前先来体验一下在YARN上执行MapReduce程序的过程。
二、示例程序
Hadoop官方内置了一些预置的MapReduce程序代码,我们无需编程,只需要通过命令即可使用。
常用的有2个MapReduce内置程序:
wordcount:单词计数程序 统计指定文件内各个单词出现的次数 pi:求圆周率 通过蒙特卡罗算法(统计模拟法)求圆周率 这些内置的示例MapReduce程序代码,都在:
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar 这个文件内。
可以通过 hadoop jar 命令来运行它,提交MapReduce程序到YARN中。
语法: hadoop jar 程序文件 java类名 [程序参数] ... [程序参数]
2.1 提交wordcount示例程序
介绍
单词计数示例程序的功能很简单:
给定数据输入的路径(HDFS)、给定结果输出的路径(HDFS)
将输入路径内的数据中的单词进行计数,将结果写到输出路径
步骤
我们可以准备一份数据文件,并上传到HDFS中。
- itheima itcast itheima itcast
- hadoop hdfs hadoop hdfs
- hadoop mapreduce hadoop yarn
- itheima hadoop itcast hadoop
- itheima itcast hadoop yarn mapreduce
将上述内容保存到Linux中为words.txt文件,并上传到HDFS。
- hadoop fs -mkdir -p /input/wordcount
- hadoop fs -mkdir /output
- hadoop fs -put words.txt /input/wordcount/
执行如下命令,提交示例MapReduce程序WordCount到YARN中执行
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount hdfs://node1:8020/input/wordcount/ hdfs://node1:8020/output/wc1注意:
- 参数wordcount,表示运行jar包中的单词计数程序(Java Class)
- 参数1是数据输入路径(hdfs://node1:8020/input/wordcount/)
- 参数2是结果输出路径(hdfs://node1:8020/output/wc1), 需要确保输出的文件夹不存在
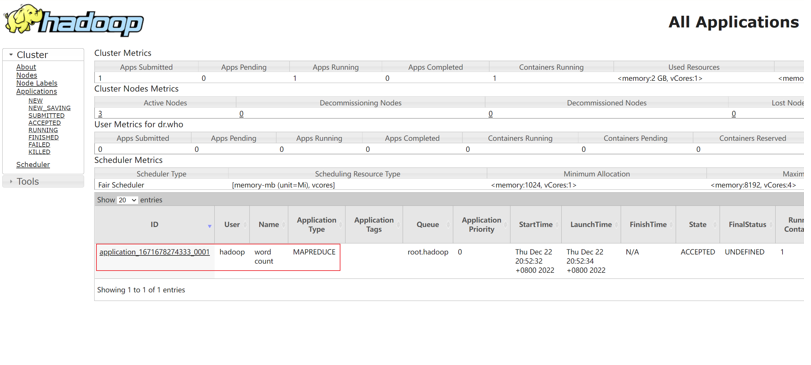
提交程序后,可以在YARN的WEB UI页面看到运行中的程序(http://centos100:8088/cluster/apps)
执行完成后,可以查看HDFS上的输出结果

- _SUCCESS文件是标记文件,表示运行成功,本身是空文件
- part-r-00000,是结果文件,结果存储在以part开头的文件中
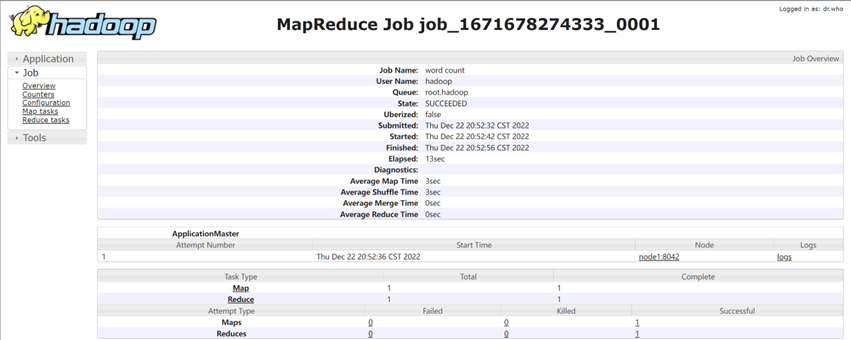
执行完成后,可以借助历史服务器查看到程序的历史运行信息
ps:如果没有启动历史服务器和代理服务器,此操作无法完成(页面信息由历史服务器提供,鼠标点击跳转到新网页功能由代理服务器提供)


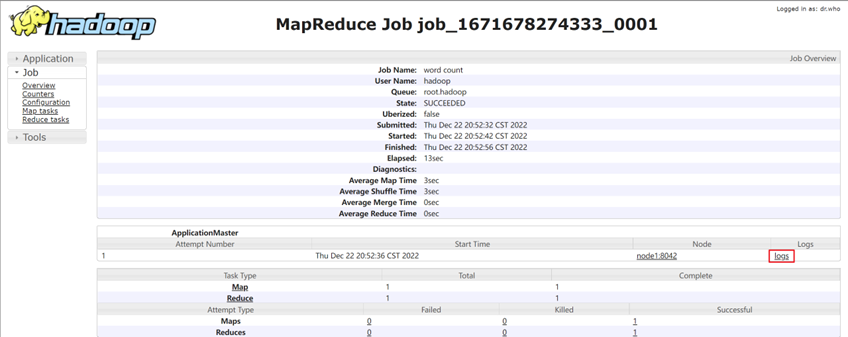
查看运行的日志

2.2 提交求圆周率示例程序
可以执行如下命令,使用蒙特卡罗算法模拟计算求PI(圆周率)
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 3 1000
- 参数pi表示要运行的Java类,这里表示运行jar包中的求pi程序
- 参数3,表示设置几个map任务
- 参数1000,表示模拟求PI的样本数(越大求的PI越准确,但是速度越慢)

如图,运行完成,求得PI值(样本1000太小,不够精准,仅演示)
三、写在最后
到这一章结束,我们的Hadoop学习就告一段落了。不是说Hadoop技术学完了,而是可以说已经入门了。至于后续要深入学习也有了方向性。下一步我们将讲解Hive技术。过程中会补充MapReduce的一些知识点。
最难不过坚持,加油!🧡
-
相关阅读:
mapstruct学习及使用较全
【MySQL自学之路】第1天——数据库基本概念名词
Windows如何启动MySQL
【数据结构】二叉树OJ练习
C++ Reference: Standard C++ Library reference: C Library: cwchar: wmemcpy
城市公交查询系统的设计与实现
【web-解析目标】(1.2.1)解析应用程序:确定用户输入入口
[C语言数据结构]队列
数字医疗解决方案:互联网医院平台的创新应用
StrictMode卡顿与泄漏检测-StrictMode原理
- 原文地址:https://blog.csdn.net/YuanFudao/article/details/132789718