-
kafka学习-生产者
目录
1、消息生产流程
2、生产者常见参数配置

3、序列化器
基本概念
- 在Kafka中保存的数据都是字节数组。
- 消息发送前,需要将消息序列化为字节数组进行发送。
- 生产者通过key.serializer和value.serializer指定key和value的序列化器。
- Kafka使用org.apache.kafka.common.serialization.Serializer接口定义序列化器。
- Kafka已实现的序列化器有:ByteArraySerializer、ByteBufferSerializer、BytesSerializer、DoubleSerializer、FloatSerializer、IntegerSerializer、StringSerializer、LongSerializer、ShortSerializer。
自定义序列化器
实现org.apache.kafka.common.serialization.Serializer
接口,并实现其中的serializer方法。 - @Data
- public class User {
- private Integer userId;
- private String username;
- }
- public class UserSerializer implements Serializer
{ - @Override
- public void configure(Map
- // do nothing
- }
- @Override
- public byte[] serialize(String topic, User data) {
- try {
- // 如果数据是null,则返回null
- if (data == null) return null;
- Integer userId = data.getUserId();
- String username = data.getUsername();
- int length = 0;
- byte[] bytes = null;
- if (null != username) {
- bytes = username.getBytes("utf-8");
- length = bytes.length;
- }
- // 第一个4字节存储userId的值
- // 第二个4字节存储username字节数组的长度int值
- // 第三个length长度,存储username序列化之后的字节数组
- ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + length);
- buffer.putInt(userId);
- buffer.putInt(length);
- buffer.put(bytes);
- return buffer.array();
- } catch (UnsupportedEncodingException e) {
- throw new SerializationException("序列化数据异常");
- }
- }
- @Override
- public void close() {
- // do nothing
- }
- }
4、分区器
默认分区规则
KafkaProducer.partition();DefaultPartitioner.partition();
- 如果record提供了分区号,则使⽤record提供的分区号
- 如果record没有提供分区号,则使⽤key的序列化后的值的hash值对分区数量取模
- 如果record没有提供分区号,也没有提供key,则使⽤轮询的⽅式分配分区号。
自定义分区器
实现org.apache.kafka.clients.producer.Partitioner接口,并实现其中的partition方法。
在生产者参数中通过配置partitioner.class指定自定义分区器。
- /**
- * 自定义分区器
- */
- public class MyPartitioner implements Partitioner {
- @Override
- public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
- // 此处可以计算分区的数字。
- // 我们直接指定为2
- return 2;
- }
- @Override
- public void close() {
- }
- @Override
- public void configure(Map
- }
- }
5、生产者拦截器
作用
在发送消息前,或者在执行回调逻辑前,对消息做一些定制化的处理,比如修改消息,打印消息日志等。此外,Producer允许设置多个拦截器从而形成一条拦截器链,Producer将按照指定顺序调用它们。
自定义拦截器
自定义拦截器实现org.apache.kafka.clients.producer.ProducerInterceptor接口,并实现其中的onSend()、onAcknowledgement()、close()接口。其中:
- onSend(ProducerRecord):Producer 确保在消息被序列化前调⽤该⽅法。⽤户可以在该⽅法中对消息做任何操作,但最好保证不要修 改消息所属的topic和分区,否则会影响⽬标分区的计算。
- onAcknowledgement(RecordMetadata, Exception):该⽅法会在消息被应答之前或消息发送失败时调⽤, 并且通常都是在Producer回调逻辑触发之前。
- close:关闭Interceptor,主要⽤于执⾏⼀些资源清理⼯作。
在生产者参数中通过配置ProducerConfig.INTERCEPTOR_CLASSES_CONFIG指定自定义拦截器。
- public class Interceptor
- private static final Logger LOGGER = LoggerFactory.getLogger(InterceptorTwo.class);
- @Override
- public ProducerRecord
- System.out.println("拦截器---go");
- // 此处根据业务需要对相关的数据作修改
- String topic = record.topic();
- Integer partition = record.partition();
- Long timestamp = record.timestamp();
- KEY key = record.key();
- VALUE value = record.value();
- Headers headers = record.headers();
- // 添加消息头
- headers.add("interceptor", "interceptor".getBytes());
- ProducerRecord
- new ProducerRecord
- return newRecord;
- }
- @Override
- public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
- System.out.println("拦截器---back");
- if (exception != null) {
- // 如果发生异常,记录在日志中
- LOGGER.error(exception.getMessage());
- }
- }
- @Override
- public void close() {
- }
- @Override
- public void configure(Map
- }
- }
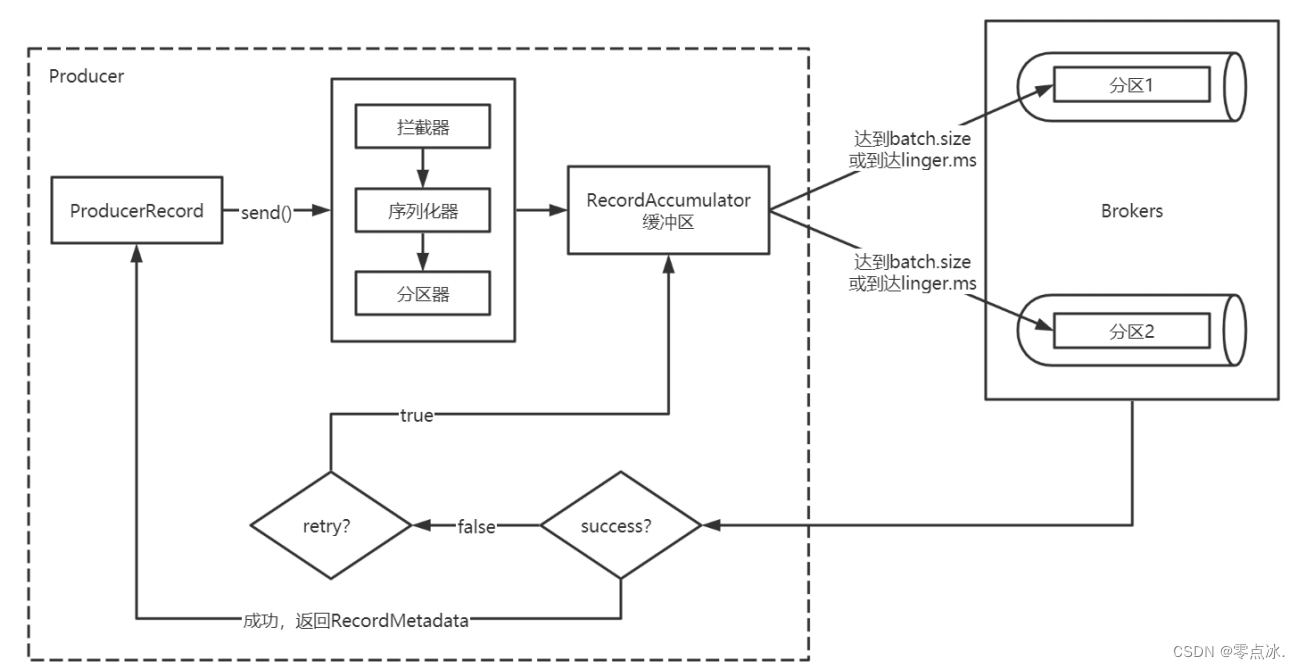
6、生产者原理解析



以上内容为个人学习理解,如有问题,欢迎在评论区指出。
部分内容截取自网络,如有侵权,联系作者删除。
-
相关阅读:
flink-sql所有数据类型-1.15
printf函数中表达式的结合顺序
展锐T618/T610安卓4G核心板/开发板/方案定制
android studio项目实例-基于Uniapp+SSM实现的Android安全网购平台
app小程序手机端Python爬虫实战19-多进程实现app多个任务端app应用数据抓取
网络安全(黑客)自学
【物理应用】基于Matlab模拟极化雷达回波
cuda11安装 nvidia-455配置报错 解决方法
vue跨域proxy详解(下)
(13.2)Latex图片、表格的绘制与排布
- 原文地址:https://blog.csdn.net/weixin_37672801/article/details/132783088
