-
Claude 2,它有 GPT-4 一些无法超越的能力
场景1:处理长文本
和 ChatGPT 相比,Claude 2 最大的优势就是它高达 10 万的 Token 数量。要知道标准的 GPT-4 才 8000,而 GPT-32K 也仅仅 3 万 2。
和 ChatGPT 或 Claude 2 这样的大模型对话就像与一个拥有短期记忆的朋友聊天。它可以记住你最后说过的几句话,通过理解上下文,让对话顺利进行。而 Token 数量就像是大模型的短期记忆,Token 数量越大,它能记住的东西越多。因此,当你向 ChatGPT 提交过长的文本时,它常常会出现下图所示的错误信息。
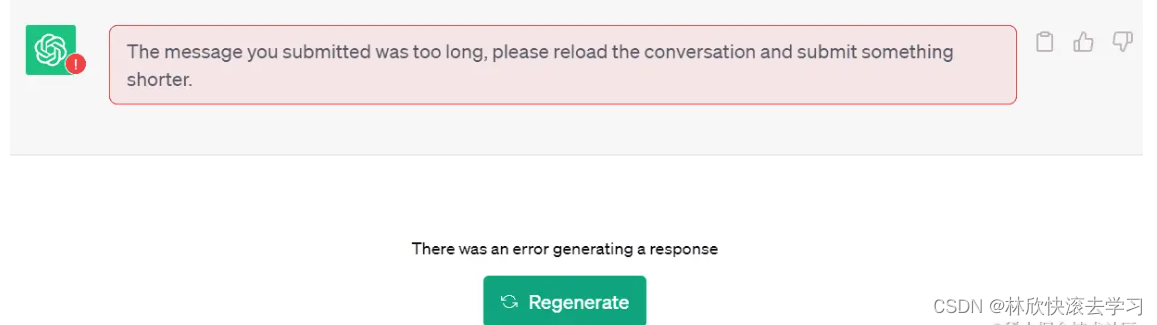
解决方案当然也有很多,比如:- 在 OpenAI Playground 中使用 Token 数量更大的模型,比如 “GPT-4.5-turbo-16k” 或
“gpt-4-32k”。但是这样需要额外消耗 API 的费用。 - 写一个提示词,告诉 ChatGPT 你将会把提交的内容分为若干部分依次上传。提示词可以这样写 “The text that I’m
about to submit will be divided into several parts. I request that
you wait until all parts have been provided before summarizing or
answering any questions about it.
(我即将提交的文本将分为几个部分。我请求您等到所有部分都提供完之后,再对其进行总结或回答任何问题。)”。上传结束以后,你再向
ChatGPT 提问题或者分配任务。 - 使用谷歌浏览器插件 “ChatGPT File Uploader Extended”。这个插件会自动帮你把文件里的长文本分为若干部分提交给
ChatGPT。 - 放到记事本文件里并使用 ChatGPT 的代码解释器上传。
场景2:上传文件
除了和 ChatGPT 进行对话以外,我们常常会让它帮我们执行任务,比如总结 PDF 的内容。ChatGPT 本身是不支持文件上传的,如果要上传 PDF 并总结内容,需要借助 ChatGPT 插件。大多数插件是不支持文件上传的,只能总结在线 PDF 的内容。
AskYourPDF 这个插件虽然支持上传,但是得脱离 ChatGPT 进入 AskYourPDF 的网站上。 它总结文件里长文本非常有效,但它们是通过自己的服务器对长文本进行二次处理,需要你花费额外的等待时间。本身 GPT-4 的响应速度就比较慢,再加上插件执行任务的时间,真的需要耐心等待。
比如我上传了一个学术论文,并问它论文里的事实,假设和结论是什么。它需要调用三次 API,然后汇总出一个答案。
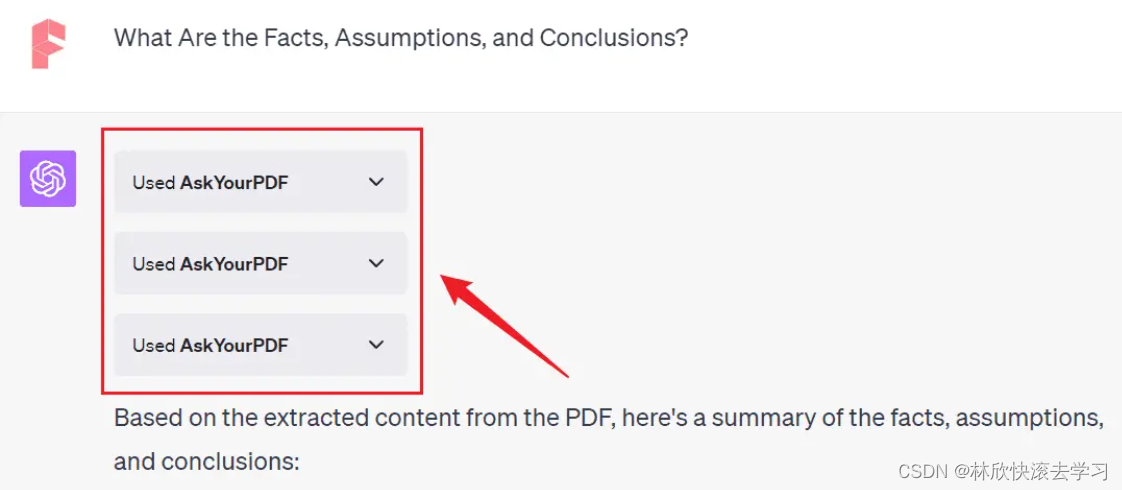
Claude 2 就不同了,你可以直接在聊天界面上上传文件,而且还可以一次上传 5 个文件。它和 PDF 交互非常迅速。对于程序员来说,可以直接把多个代码文件同时上传并 Debug。当然,它对文件的处理停留在文本层面,无法像 ChatGPT 的代码解释器一样通过代码处理文档,比如给 PDF 加水印,编辑图片等等。
场景3:进行冗长的多轮对话
说到这里,你可能在想,既然 ChatGPT 的 Token 容量这么小,那么当我和它进行了那么多轮冗长的对话之后,它怎么还记得我开头说的内容。
其实它会根据你最近一次的请求内容,有选择性的截取你和它对话中最相关的内容,甚至还可以进行多次迭代来理解上下文。但本质上还是没有突破 Token 的限制,如果对话超出此范围,模型就会开始“忘记”之前的部分。比如一开始你给它设定一个角色,它在后续的对话过程中会忘记之前的部分。如果想让它一直记住某些关键信息,一个技巧就是时不时地提醒它。
因此,当我要进行很多轮冗长的对话时,也会考虑使用 Claude 2,取决于我对回答质量的要求。Claude 2 虽然 Token 容量很大,但是模型本身的参数比较小,所以它回答的质量很多时候比不上 GPT-4。
场景4:我的提示词里涉及2021年9月之后的信息
大家都知道 ChatGPT 3.5 和 ChatGPT 4 的训练数据是在 2021 年 9 月之前,对于之后发生的事件并不了解。但是 Claude 2 的训练时间要晚很多,大概停留在 2022 年11 月。比如我问它 2022 年11 月的重大事件它就知道,而 12月的事件它就不知道了。

虽然这 1 年多的训练数据听上去不算什么,但是缺了这些知识有时候会很尴尬。比如我经常需要 ChatGPT 协助我在 Midjourney 上绘图。虽然它知道很多艺术类的知识,但是却完全不懂什么是 Midjourney,因为 Midjourney 的测试版 22 年才发布。尽管我多次把有关 Midjourney 的一长串背景知识告诉 GPT-4,但是在后续的对话中它经常就忘记 Midjourney 是什么,然后生成了很多啼笑皆非的回答。为什么它会忘记呢,其实还是受制于 Token 限制,这一点我刚才解释过了。
Claude 2 则不同了,它知道 Midjourney 是什么,甚至知道如何写 Midjourney 提示词,虽然它对此的理解还停留在 2022 年。比如我问它如何写 Midjourney 提示词,它给的答案几乎没有问题。

- 在 OpenAI Playground 中使用 Token 数量更大的模型,比如 “GPT-4.5-turbo-16k” 或
-
相关阅读:
物联网行业知识概览(一)
操作系统文件使用磁盘的实现---20
Python之切片
深入探究MinimalApi是如何在Swagger中展示的
Java过滤器与拦截器的区别(一文搞懂)
物联网设备通过MQTT接入华为iot平台
linux 学习笔记
【数组】-找出有序数组中(有负有正)绝对值最小的数
2022年Redis最新面试题第1篇 - Redis基础知识
MySQL锁问题
- 原文地址:https://blog.csdn.net/m0_73728511/article/details/132777945