-
《protobuf》基础语法
消息体定义
- 文件内定义
message Phone { string number = 1; } message PeopleInfo { string name = 1; int32 age = 2; Phone phone = 3; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 内嵌定义
message PeopleInfo { string name = 1; int32 age = 2; message Phone { string number = 1; } Phone phone = 3; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 文件外定义
// 文件 Phone.proto syntax = "proto3"; package phone; message Phone { string number = 1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
import "Phone.proto"; message PeopleInfo { string name = 1; int32 age = 2; // 引⼊的⽂件声明了package,使⽤消息时,需要⽤ ‘命名空间.消息类型’ 格式 phone.Phone phone = 3; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
字段规则
消息的字段可以用下面几种规则来修饰:
- singular :消息中可以包含该字段零次或⼀次(不超过⼀次)。proto3 语法中,字段默认使⽤该
规则。 - repeated :消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理解为定义了⼀个数组。
续回上篇,继续完善
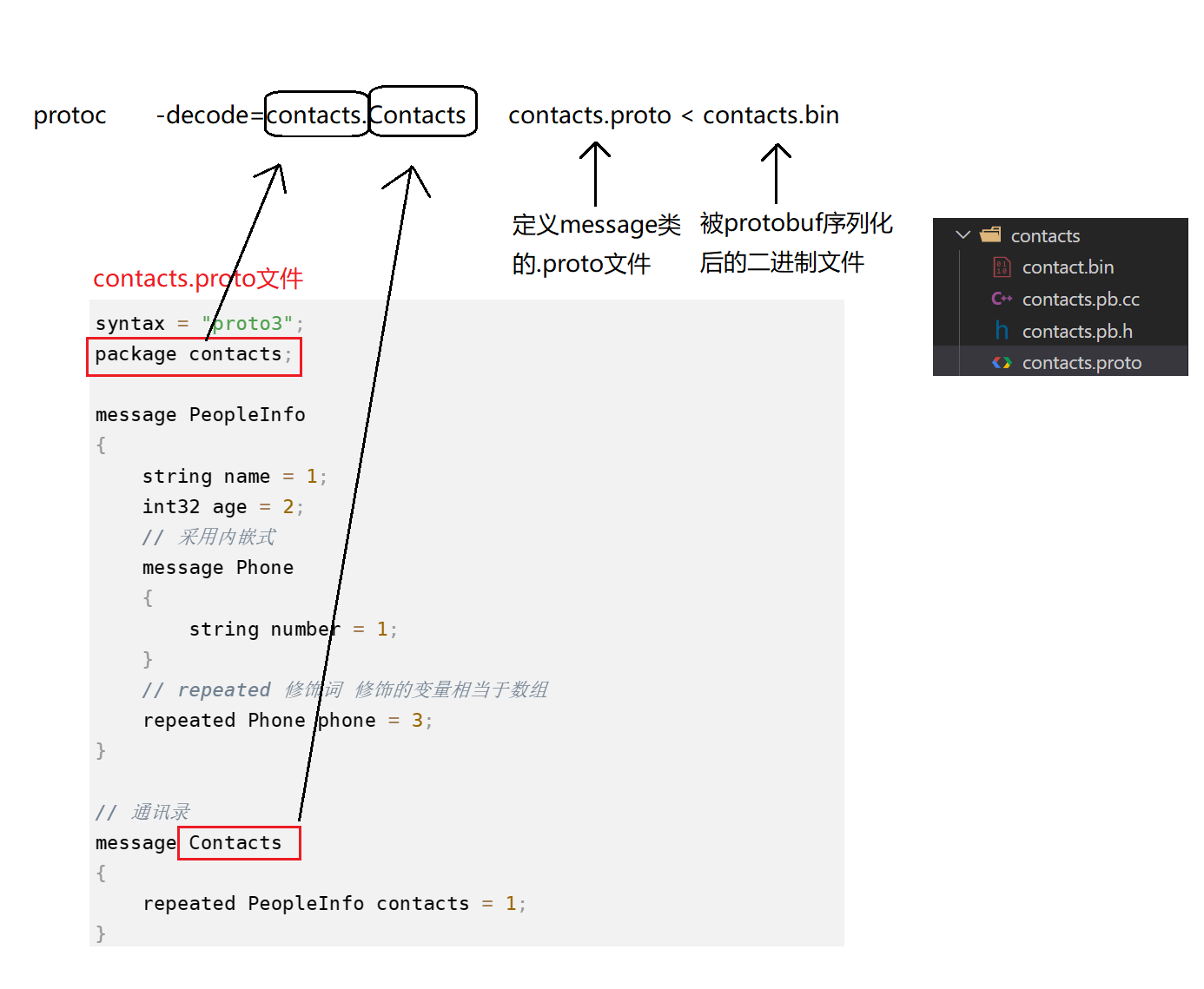
contacts.proto文件的内容syntax = "proto3"; package contacts; message PeopleInfo { string name = 1; int32 age = 2; // 采用内嵌式 message Phone { string number = 1; } // repeated 修饰词 修饰的变量相当于数组 repeated Phone phone = 3; } // 通讯录 message Contacts { repeated PeopleInfo contacts = 1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
编译选项
补充上篇:
- -h : protoc -h 表示帮助
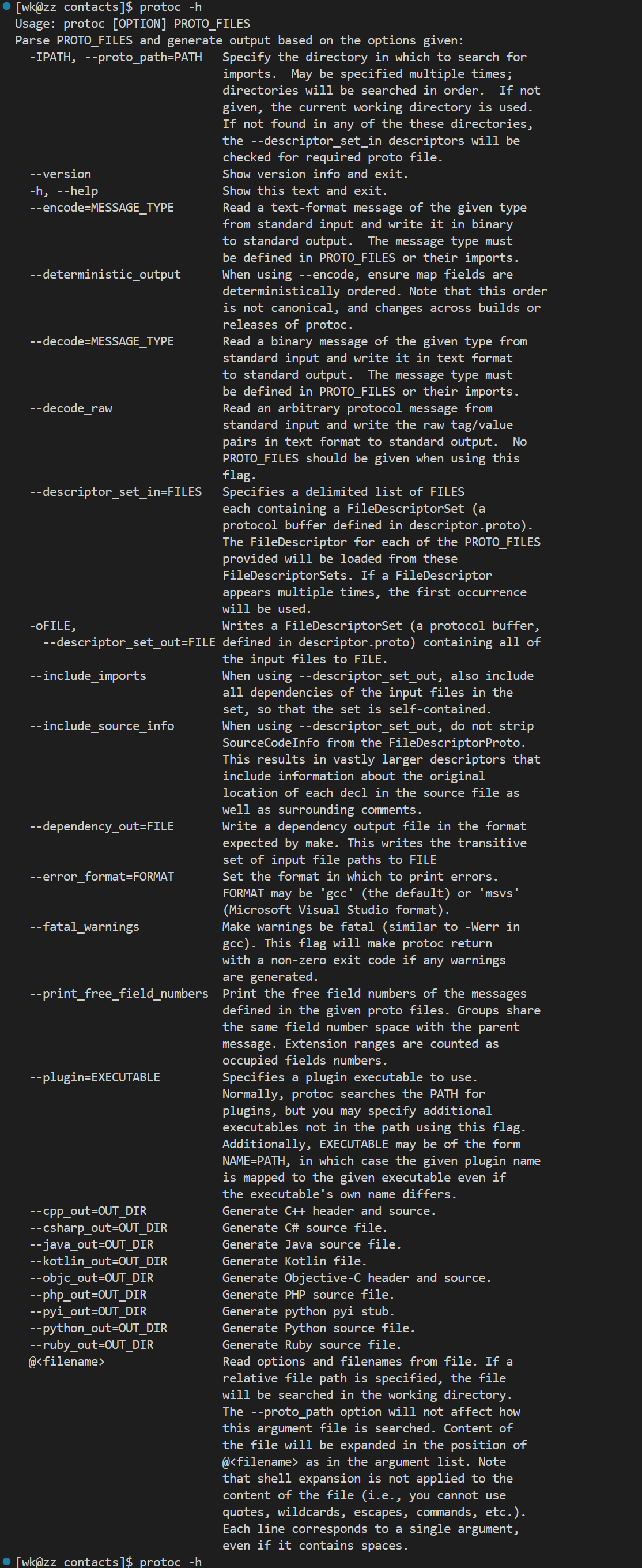
上图是所有内容,下面重点讲解一下- decode - decode
 大概意思是:从标准输入读取给定类型的二进制消息,并以文本格式将其写入标准输出。消息类型必须在PROTO FILES或其导入中定义。
大概意思是:从标准输入读取给定类型的二进制消息,并以文本格式将其写入标准输出。消息类型必须在PROTO FILES或其导入中定义。
先看用法
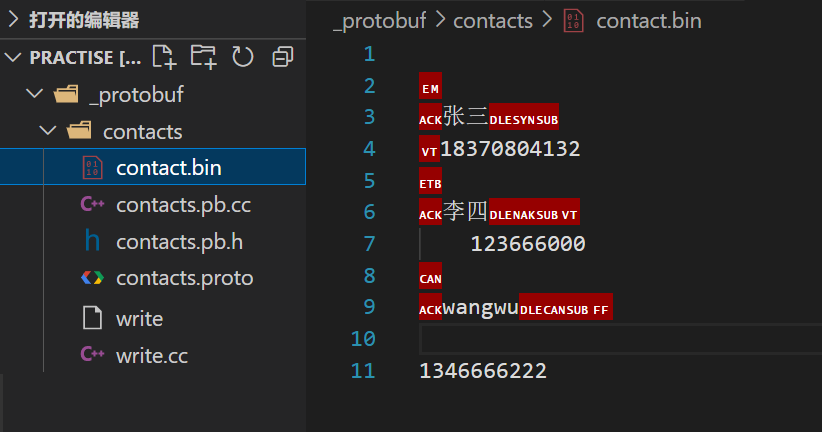
protoc -decode=contacts.Contacts contacts.proto < contacts.bin- 1
执行指令后,结果如下
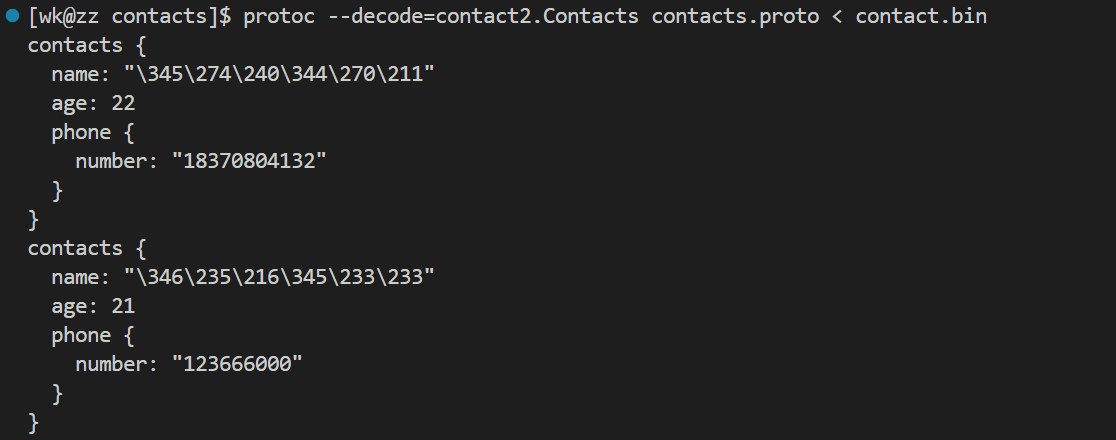
这个编译条件可以快速查看序列化后二进制文件的内容,是一个很便捷的操作查看二进制内容的工具还有hexdump
hexdump:是Linux下的一个二进制文件查看工具,它可以将二进制文件转换为ASCII、八进制、十进制、十六进制格式进行查看。
-C: 表示每个字节显示为16进制和相应的ASCII字符hexdump -C 二进制文件名 eg:hexdump -C contact.bin- 1
- 2

实战:编写一个通讯录文件
上面完善编写了
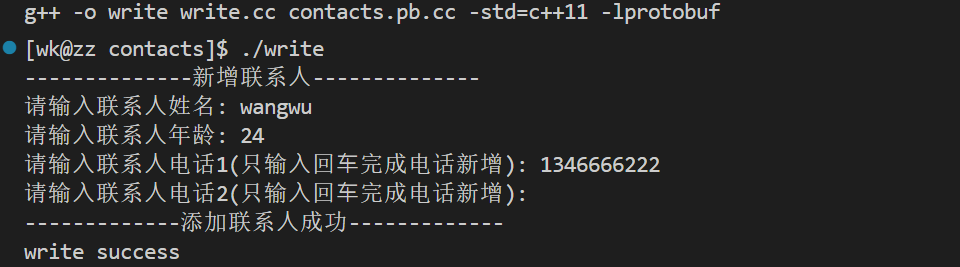
contacts.proto文件,现在完成写文件write.cpp和读文件read.cpp,write.cpp文件主要用于将通讯录信息通过protobuf的序列化,然后写入contact.bin文件内,read.cpp文件主要用于通过protobuf的反序列化,对contact.bin文件内容的读取。write.cpp的编写
#include#include #include"contacts.pb.h" using namespace std; void AddPeopleInfo(contact2::PeopleInfo *people) { cout << "--------------新增联系⼈--------------" << endl; cout << "请输⼊联系⼈姓名: "; string name; getline(cin, name); people->set_name(name); cout << "请输⼊联系⼈年龄: "; int age; cin >> age; cin.ignore(256, '\n'); // 清除缓冲区的内容,大于256或遇到'\n'停止 people->set_age(age); for(int i = 1; ;++i) { cout << "请输⼊联系⼈电话" << i << "(只输⼊回⻋完成电话新增): "; string number; getline(cin, number); if(number.empty()) break; people->add_phone()->set_number(number); } cout << "-------------添加联系⼈成功-------------" << endl; } int main() { contacts::Contacts con; fstream in("contact.bin", ios::in | ios::binary); if(!in) cout << "contact.bin not exist, it is being created now" << endl; // ParseFromIstream方法的作用: 读取in里的内容并将其反序列化保存起来 else if(!con.ParseFromIstream(&in)) { cerr << "Fail to parse" << endl; in.close(); return -1; } in.close(); // 写入通讯录信息 // 前文有提到,repeated修饰的变量相当于数组,所以 // con.add_contacts()就相当新分配了一个contacts变量 AddPeopleInfo(con.add_contacts()); fstream out("contact.bin", ios::out | ios::trunc | ios::binary); // SerializeToOstream方法的作用: 读取out里的内容并将其序列化保存起来 if(!con.SerializeToStream(&out)) { cerr << "Fail to serialize" << endl; out.close(); return -1; } cout << "write success" << endl; out.close(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
执行效果如下:
read.cpp的编写
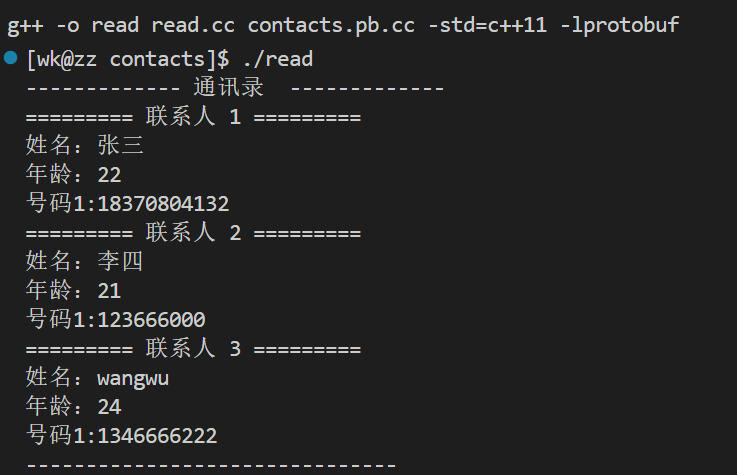
#include#include #include "contacts.pb.h" using namespace std; void PrintfContacts(contact2::Contacts &con) { cout << "------------- 通讯录 -------------" << endl; for(int i = 0; i < con.contacts_size(); ++i) { cout << "========= 联系人 " << i+1 << " =========" << endl; const contact2::PeopleInfo people = con.contacts(i); cout << "姓名:" << people.name() << endl; cout << "年龄:" << people.age() << endl; for(int j = 0; j < people.phone_size(); ++j) { auto phone = people.phone(j); cout << "号码" << j+1 << ":" << phone.number() << endl; } } cout << "-------------------------------" << endl; } int main() { contact2::Contacts con; fstream in("contact.bin", ios::in | ios::binary); if(!in) cout << "contact.bin not exist, it is being created now" << endl; else if(!con.ParseFromIstream(&in)) { in.close(); return -1; } PrintfContacts(con); in.close(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
执行效果如下:
补充:主要函数的使用
-
bool ParseFromIstream(std::istream* input);
Parse 系列的函数有很多,因为前面用了文件流提取内容,所以这里使用 Parse 系列的Istream()。
作用:读取 input 里的内容并将其反序列化保存起来 -
add_contacts()
因为 Contacts 里的 contacts 字段被 repeat 修饰,所以相当于数组,这个函数是专门新增一个 contacts 变量的。(ps:因为有contacts所以才是 add_contacts() ,如果是 其他 那么就会对应生成 add_其他()) -
bool SerializeToOstream(std::ostream* output) const;
作用: 读取 output 里的内容并将其序列化保存起来 -
contacts_size();
求变量个数(可以认为数组大小),注意 size 前面的名称是变量名称。 -
set_变量名();
代码里有出现,set_age(age),set_name(name),set_number(number) 没错,这些都是设置值的函数
以上函数均包含在
文件.pb.h里,必要是时可以跳转进去里面学习函数使用,上面仅讲解了使用到的函数 -
相关阅读:
SpringBoot+SpringMVC+MybatisPlus
项目day(3) 前台环境搭建
Shell编程从看懂到看开①(Shell概述、变量、运算符、条件判断)
maven的进阶学习
【数学分析笔记】平均值不等式证明
Python3,我用这种方式讲解python模块,80岁的奶奶都说能理解。建议收藏 ~ ~
解决方案:读取两个文件夹里不同名的文件,处理映射不对应的文件
idea 插件推荐第二期
深入分析TaskView源码之触摸相关
另辟蹊径者 PoseiSwap:背靠潜力叙事,构建 DeFi 理想国
- 原文地址:https://blog.csdn.net/qq_56166591/article/details/132756127
