-
基于Vgg-Unet模型自动驾驶场景检测
1.VGG
VGG全称是Visual Geometry Group属于牛津大学科学工程系,其发布了一些列以VGG开头的卷积网络模型,可以应用在人脸识别、图像分类等方面,VGG的输入被设置为大小为224x244的RGB图像。为训练集图像上的所有图像计算平均RGB值,然后将该图像作为输入输入到VGG卷积网络。使用3x3或1x1滤波器,并且卷积步骤是固定的。有3个VGG全连接层,根据卷积层+全连接层的总数,可以从VGG11到VGG19变化。最小VGG11具有8个卷积层和3个完全连接层。最大VGG19具有16个卷积层+3个完全连接的层。此外,VGG网络后面没有每个卷积层后面的池化层,也没有分布在不同卷积层下的总共5个池化层。
结构图如下:

架构图
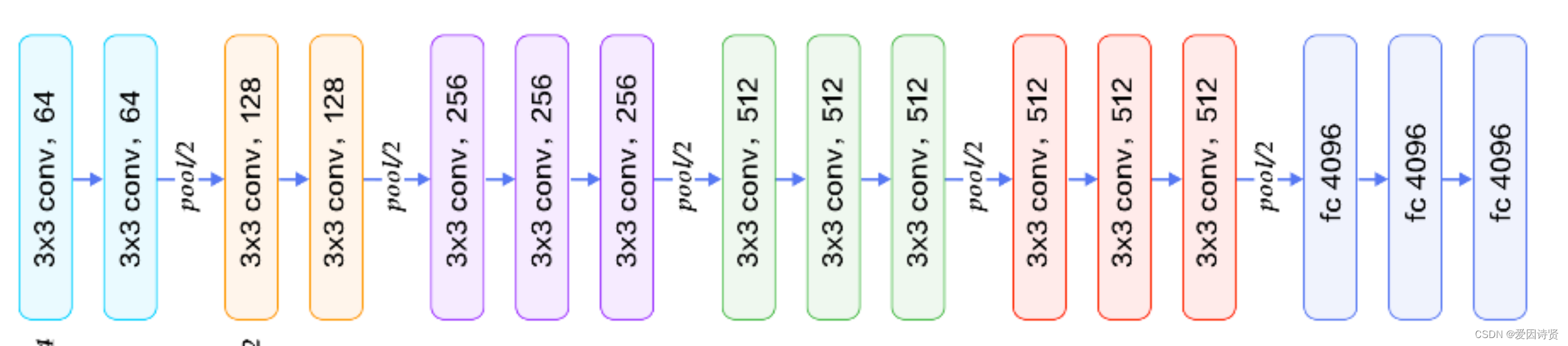
2.Unet模型:
Unet是一个优秀的语义分割模型,其主要执行过程与其它语义分割模型类似。与CNN不同的之处在于CNN是图像级的分类,而unet是像素级的分类,其输出的是每个像素点的类别

主要代码如下:
def get_vgg_encoder(input_height=224, input_width=224, channels=3): if channel == 'channels_first': img_input = Input(shape=(channels, input_height, input_width)) elif channel == 'channels_last': img_input = Input(shape=(input_height, input_width, channels)) x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1', data_format=channel)(img_input) x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2', data_format=channel)(x) x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool', data_format=channel)(x) f1 = x # Block 2 x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1', data_format=channel)(x) x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2', data_format=channel)(x) x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool', data_format=channel)(x) f2 = x # Block 3 x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1', data_format=channel)(x) x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2', data_format=channel)(x) x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3', data_format=channel)(x) x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool', data_format=channel)(x) f3 = x # Block 4 x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1', data_format=channel)(x) x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2', data_format=channel)(x) x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3', data_format=channel)(x) x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool', data_format=channel)(x) f4 = x # Block 5 x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1', data_format=channel)(x) x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2', data_format=channel)(x) x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3', data_format=channel)(x) x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool', data_format=channel)(x) f5 = x return img_input, [f1, f2, f3, f4, f5] def _unet(classes, encoder, l1_skip_conn=True, input_height=416, input_width=608, channels=3): img_input, levels = encoder( input_height=input_height, input_width=input_width, channels=channels) [f1, f2, f3, f4, f5] = levels o = f4 o = (ZeroPadding2D((1, 1), data_format=channel))(o) o = (Conv2D(512, (3, 3), padding='valid' , activation='relu' , data_format=channel))(o) o = (BatchNormalization())(o) o = (UpSampling2D((2, 2), data_format=channel))(o) o = (concatenate([o, f3], axis=-1)) o = (ZeroPadding2D((1, 1), data_format=channel))(o) o = (Conv2D(256, (3, 3), padding='valid', activation='relu' , data_format=channel))(o) o = (BatchNormalization())(o) o = (UpSampling2D((2, 2), data_format=channel))(o) o = (concatenate([o, f2], axis=-1)) o = (ZeroPadding2D((1, 1), data_format=channel))(o) o = (Conv2D(128, (3, 3), padding='valid' , activation='relu' , data_format=channel))(o) o = (BatchNormalization())(o) o = (UpSampling2D((2, 2), data_format=channel))(o) if l1_skip_conn: o = (concatenate([o, f1], axis=-1)) o = (ZeroPadding2D((1, 1), data_format=channel))(o) o = (Conv2D(64, (3, 3), padding='valid', activation='relu', data_format=channel, name="seg_feats"))(o) o = (BatchNormalization())(o) o = Conv2D(classes, (3, 3), padding='same', data_format=channel)(o) model = get_segmentation_model(img_input, o) return model- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
-
相关阅读:
JVM调优实战
C++之STL
Node.js | 常用内置模块之 path 路径模块
雷电9模拟器抓包
CV学习基础
TypeScript 简介
JS操作字符串常见方法
Python的文件操作
【线程池、有返回值的线程池、线程池监控】
FSK解调技术的FPGA实现
- 原文地址:https://blog.csdn.net/qq_38937634/article/details/132675159
