-
深度解析BERT:从理论到Pytorch实战
本文从BERT的基本概念和架构开始,详细讲解了其预训练和微调机制,并通过Python和PyTorch代码示例展示了如何在实际应用中使用这一模型。我们探讨了BERT的核心特点,包括其强大的注意力机制和与其他Transformer架构的差异。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
一、引言
在信息爆炸的时代,自然语言处理(NLP)成为了一门极其重要的学科。它不仅应用于搜索引擎、推荐系统,还广泛应用于语音识别、情感分析等多个领域。然而,理解和生成自然语言一直是机器学习面临的巨大挑战。接下来,我们将深入探讨自然语言处理的一些传统方法,以及它们在处理语言模型时所面临的各种挑战。
传统NLP技术概览
规则和模式匹配
早期的NLP系统大多基于规则和模式匹配。这些方法具有高度的解释性,但缺乏灵活性。例如,正则表达式和上下文无关文法(CFG)被用于文本匹配和句子结构的解析。
基于统计的方法
随着计算能力的提升,基于统计的方法如隐马尔可夫模型(HMM)和最大熵模型逐渐流行起来。这些模型利用大量的数据进行训练,以识别词性、句法结构等。
词嵌入和分布式表示
Word2Vec、GloVe等词嵌入方法标志着NLP从基于规则到基于学习的向量表示的转变。这些模型通过分布式表示捕捉单词之间的语义关系,但无法很好地处理词序和上下文信息。
循环神经网络(RNN)与长短时记忆网络(LSTM)
RNN和LSTM模型为序列数据提供了更强大的建模能力。特别是LSTM,通过其内部门机制解决了梯度消失和梯度爆炸的问题,使模型能够捕获更长的依赖关系。
Transformer架构
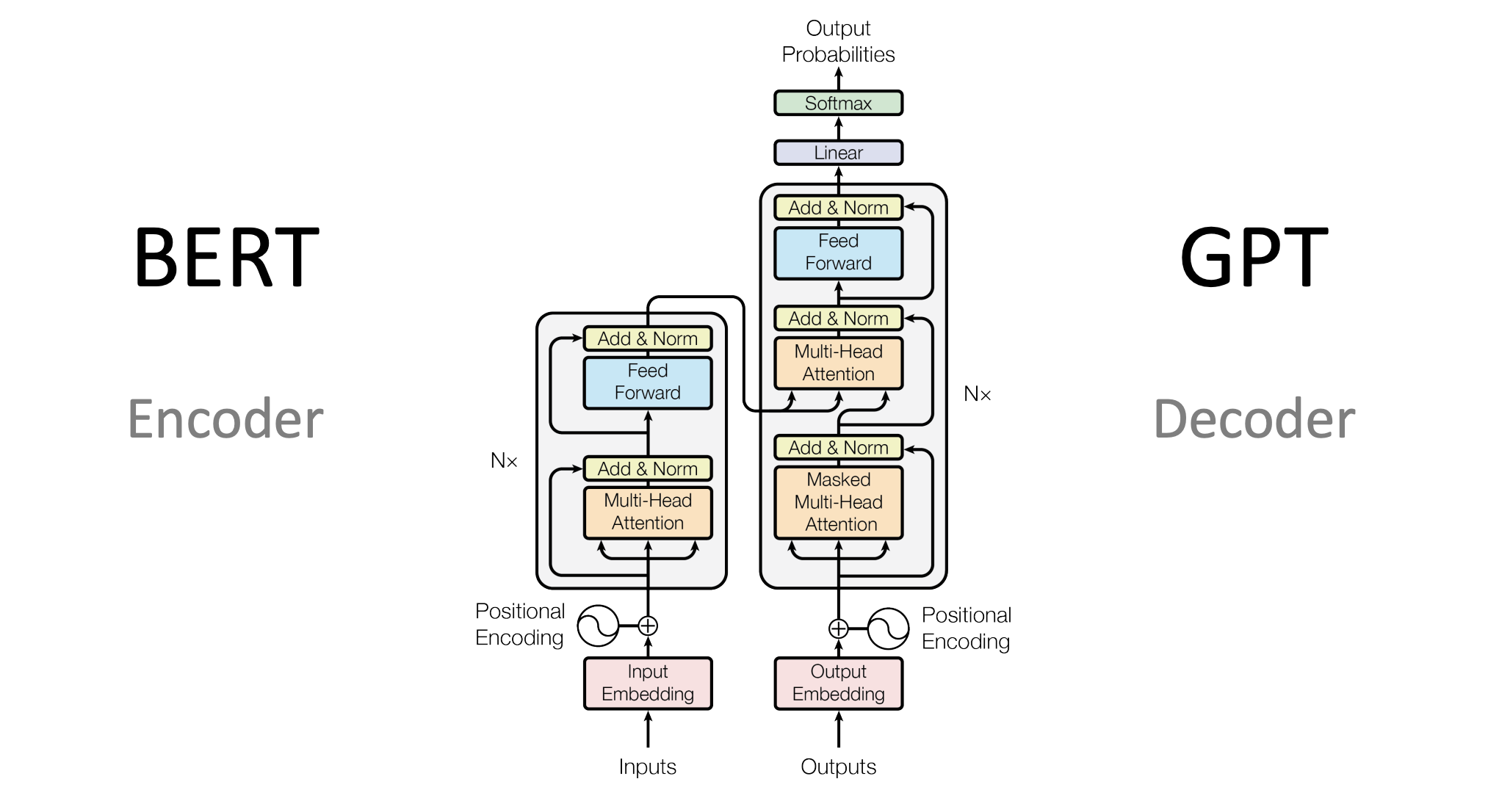
Transformer模型改变了序列建模的格局,通过自注意力(Self-Attention)机制有效地处理了长距离依赖,并实现了高度并行化。但即使有了这些进展,仍然存在许多挑战和不足。在这一背景下,BERT(Bidirectional Encoder Representations from Transformers)模型应运而生,它综合了多种先进技术,并在多个NLP任务上取得了显著的成绩。
二、什么是BERT?
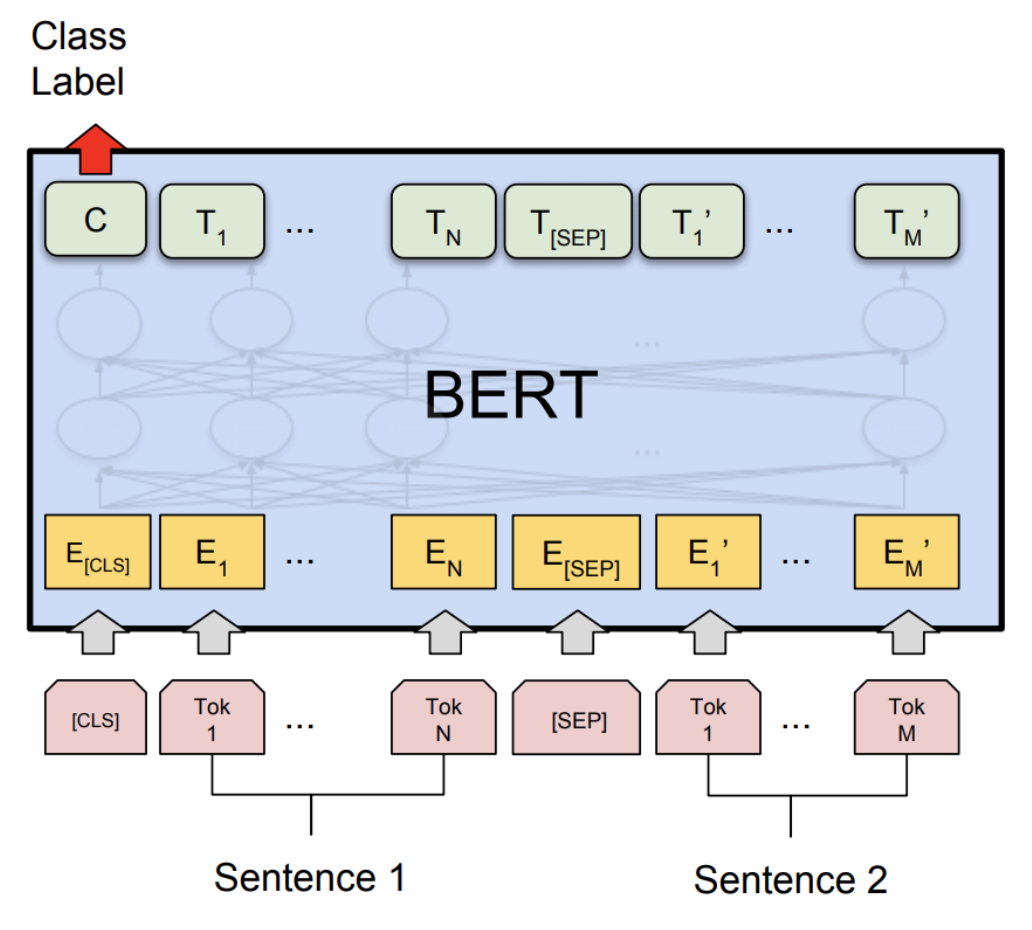
BERT的架构
BERT(Bidirectional Encoder Representations from Transformers)模型基于Transformer架构,并通过预训练与微调的方式,对自然语言进行深度表示。在介绍BERT架构的各个维度和细节之前,我们先理解其整体理念。
整体理念
BERT的设计理念主要基于以下几点:
-
双向性(Bidirectional): 与传统的单向语言模型不同,BERT能同时考虑到词语的前后文。
-
通用性(Generality): 通过预训练和微调的方式,BERT能适用于多种自然语言处理任务。
-
深度(Depth): BERT通常具有多层(通常为12层或更多),这使得模型能够捕捉复杂的语义和语法信息。
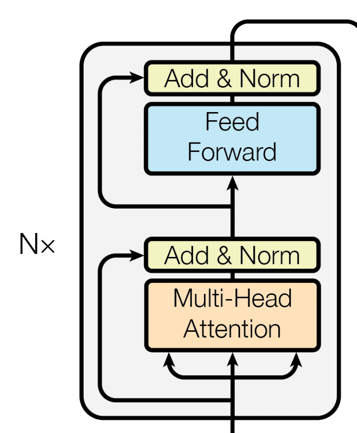
架构部件
Encoder层
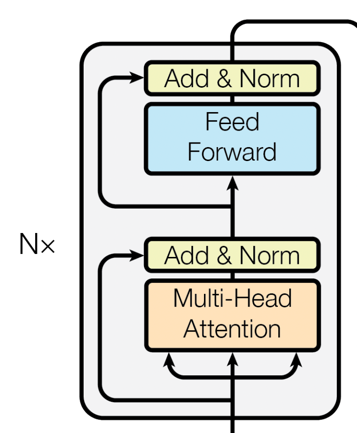
BERT完全基于Transformer的Encoder层。每个Encoder层都包含两个主要的部分:-
自注意力机制(Self-Attention): 这一机制允许模型考虑到输入序列中所有单词对当前单词的影响。
-
前馈神经网络(Feed-Forward Neural Networks): 在自注意力的基础上,前馈神经网络进一步对特征进行非线性变换。
嵌入层(Embedding Layer)
BERT使用了Token Embeddings, Segment Embeddings和Position Embeddings三种嵌入方式,将输入的单词和附加信息编码为固定维度的向量。
部件的组合
-
每个Encoder层都依次进行自注意力和前馈神经网络计算,并附加Layer Normalization进行稳定。
-
所有Encoder层都是堆叠(Stacked)起来的,这样能够逐层捕捉更抽象和更复杂的特征。
-
嵌入层的输出会作为第一个Encoder层的输入,然后逐层传递。
架构特点
-
参数共享: 在预训练和微调过程中,所有Encoder层的参数都是共享的。
-
灵活性: 由于BERT的通用性和深度,你可以根据任务的不同在其基础上添加不同类型的头部(Head),例如分类头或者序列标记头。
-
高计算需求: BERT模型通常具有大量的参数(几亿甚至更多),因此需要大量的计算资源进行训练。
通过这样的架构设计,BERT模型能够在多种自然语言处理任务上取得出色的表现,同时也保证了模型的灵活性和可扩展性。
三、BERT的核心特点
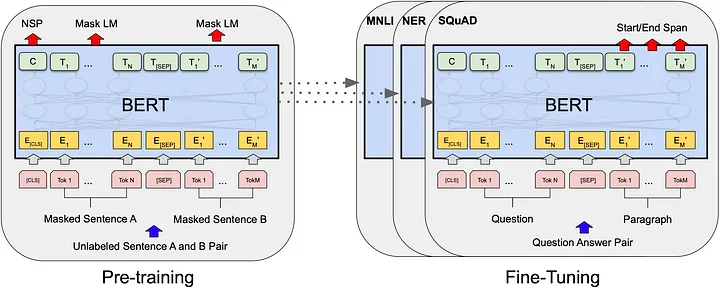
BERT模型不仅在多项NLP任务上取得了显著的性能提升,更重要的是,它引入了一系列在自然语言处理中具有革新性的设计和机制。接下来,我们将详细探讨BERT的几个核心特点。Attention机制
自注意力(Self-Attention)
自注意力是BERT模型中一个非常重要的概念。不同于传统模型在处理序列数据时,只能考虑局部或前序的上下文信息,自注意力机制允许模型观察输入序列中的所有词元,并为每个词元生成一个上下文感知的表示。
# 自注意力机制的简单PyTorch代码示例 import torch.nn.functional as F class SelfAttention(nn.Module): def __init__(self, embed_size, heads): super(SelfAttention, self).__init__() self.embed_size = embed_size self.heads = heads self.head_dim = embed_size // heads assert ( self.head_dim * heads == embed_size ), "Embedding size needs to be divisible by heads" self.values = nn.Linear(self.head_dim, self.head_dim, bias=False) self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False) self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False) self.fc_out = nn.Linear(heads * self.head_dim, embed_size) def forward(self, values, keys, queries, mask): N = queries.shape[0] value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1] # Split the embedding into self.head different pieces values = values.reshape(N, value_len, self.heads, self.head_dim) keys = keys.reshape(N, key_len, self.heads, self.head_dim) queries = queries.reshape(N, query_len, self.heads, self.head_dim) values = self.values(values) keys = self.keys(keys) queries = self.queries(queries) # Scaled dot-product attention attention = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) if mask is not None: attention = attention.masked_fill(mask == 0, float("-1e20")) attention = torch.nn.functional.softmax(attention, dim=3) out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape( N, query_len, self.heads * self.head_dim ) out = self.fc_out(out) return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
多头注意力(Multi-Head Attention)
BERT进一步引入了多头注意力(Multi-Head Attention),将自注意力分成多个“头”,每个“头”学习序列中不同部分的上下文信息,最后将这些信息合并起来。
预训练和微调
BERT模型的成功很大程度上归功于其两阶段的训练策略:预训练(Pre-training)和微调(Fine-tuning)。下面我们会详细地探讨这两个过程的特点、技术点和需要注意的事项。
预训练(Pre-training)
预训练阶段是BERT模型训练过程中非常关键的一步。在这个阶段,模型在大规模的无标签文本数据上进行训练,主要通过以下两种任务来进行:
-
掩码语言模型(Masked Language Model, MLM): 在这个任务中,输入句子的某个比例的词会被随机地替换成特殊的
[MASK]标记,模型需要预测这些被掩码的词。 -
下一个句子预测(Next Sentence Prediction, NSP): 模型需要预测给定的两个句子是否是连续的。
技术点:
-
动态掩码: 在每个训练周期(epoch)中,模型看到的每一个句子的掩码都是随机的,这样可以增加模型的鲁棒性。
-
分词器: BERT使用了WordPiece分词器,能有效处理未登录词(OOV)。
注意点:
- 数据规模需要非常大,以充分训练庞大的模型参数。
- 训练过程通常需要大量的计算资源,例如高性能的GPU或TPU。
微调(Fine-tuning)
在预训练模型好之后,接下来就是微调阶段。微调通常在具有标签的小规模数据集上进行,以使模型更好地适应特定的任务。
技术点:
-
学习率调整: 由于模型已经在大量数据上进行了预训练,因此微调阶段的学习率通常会设置得相对较低。
-
任务特定头: 根据任务的不同,通常会在BERT模型的顶部添加不同的网络层(例如,用于分类任务的全连接层、用于序列标记的CRF层等)。
注意点:
- 避免过拟合:由于微调数据集通常比较小,因此需要仔细选择合适的正则化策略,如Dropout或权重衰减(weight decay)。
通过这两个阶段的训练,BERT不仅能够捕捉到丰富的语义和语法信息,还能针对特定任务进行优化,从而在各种NLP任务中都表现得非常出色。
BERT与其他Transformer架构的不同之处
预训练策略
虽然Transformer架构通常也会进行某种形式的预训练,但BERT特意设计了两个阶段:预训练和微调。这使得BERT可以首先在大规模无标签数据上进行预训练,然后针对特定任务进行微调,从而实现了更广泛的应用。
双向编码
大多数基于Transformer的模型(例如GPT)通常只使用单向或者条件编码。与之不同,BERT使用双向编码,可以更全面地捕捉到文本中词元的上下文信息。
掩码语言模型(Masked Language Model)
BERT在预训练阶段使用了一种名为“掩码语言模型”(Masked Language Model, MLM)的特殊训练策略。在这个过程中,模型需要预测输入序列中被随机掩码(mask)的词元,这迫使模型更好地理解句子结构和语义信息。
四、BERT的场景应用
BERT模型由于其强大的表征能力和灵活性,在各种自然语言处理(NLP)任务中都有广泛的应用。下面,我们将探讨几个常见的应用场景,并提供相关的代码示例。
文本分类
文本分类是NLP中最基础的任务之一。使用BERT,你可以轻松地将文本分类到预定义的类别中。
from transformers import BertTokenizer, BertForSequenceClassification import torch # 加载预训练的BERT模型和分词器 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertForSequenceClassification.from_pretrained('bert-base-uncased') # 准备输入数据 inputs = tokenizer("Hello, how are you?", return_tensors="pt") # 前向传播 labels = torch.tensor([1]).unsqueeze(0) # Batch size 1, label set as 1 outputs = model(**inputs, labels=labels) loss = outputs.loss logits = outputs.logits- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
情感分析
情感分析是文本分类的一个子任务,用于判断一段文本的情感倾向(正面、负面或中性)。
# 继续使用上面的模型和分词器 inputs = tokenizer("I love programming.", return_tensors="pt") # 判断情感 outputs = model(**inputs) logits = outputs.logits predictions = torch.softmax(logits, dim=-1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
命名实体识别(Named Entity Recognition, NER)
命名实体识别是识别文本中特定类型实体(如人名、地名、组织名等)的任务。
from transformers import BertForTokenClassification # 加载用于Token分类的BERT模型 model = BertForTokenClassification.from_pretrained('dbmdz/bert-large-cased-finetuned-conll03-english') # 输入数据 inputs = tokenizer("My name is John.", return_tensors="pt") # 前向传播 outputs = model(**inputs) logits = outputs.logits- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
文本摘要
BERT也可以用于生成文本摘要,即从一个长文本中提取出最重要的信息。
from transformers import BertForConditionalGeneration # 加载用于条件生成的BERT模型(这是一个假设的例子,实际BERT原生不支持条件生成) model = BertForConditionalGeneration.from_pretrained('some-conditional-bert-model') # 输入数据 inputs = tokenizer("The quick brown fox jumps over the lazy dog.", return_tensors="pt") # 生成摘要 summary_ids = model.generate(inputs.input_ids, num_beams=4, min_length=5, max_length=20) print(tokenizer.decode(summary_ids[0], skip_special_tokens=True))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这只是使用BERT进行实战应用的冰山一角。其灵活和强大的特性使它能够广泛应用于各种复杂的NLP任务。通过合理的预处理、模型选择和微调,你几乎可以用BERT解决任何自然语言处理问题。
五、BERT的Python和PyTorch实现

预训练模型的加载
加载预训练的BERT模型是使用BERT进行自然语言处理任务的第一步。由于BERT模型通常非常大,手动实现整个架构并加载预训练权重是不现实的。幸运的是,有几个库简化了这一过程,其中包括
transformers库,该库提供了丰富的预训练模型和相应的工具。安装依赖库
首先,你需要安装
transformers和torch库。你可以使用下面的pip命令进行安装:pip install transformers pip install torch- 1
- 2
加载模型和分词器
使用
transformers库,加载BERT模型和相应的分词器变得非常简单。下面是一个简单的示例:from transformers import BertTokenizer, BertModel # 初始化分词器和模型 tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") model = BertModel.from_pretrained("bert-base-uncased") # 查看模型架构 print(model)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这段代码会下载BERT的基础版本(uncased)和相关的分词器。你还可以选择其他版本,如
bert-large-uncased。输入准备
加载了模型和分词器后,下一步是准备输入数据。假设我们有一个句子:“Hello, BERT!”。
# 分词 inputs = tokenizer("Hello, BERT!", padding=True, truncation=True, return_tensors="pt") print(inputs)- 1
- 2
- 3
- 4
tokenizer会自动将文本转换为模型所需的所有类型的输入张量,包括input_ids、attention_mask等。模型推理
准备好输入后,下一步是进行模型推理,以获取各种输出:
with torch.no_grad(): outputs = model(**inputs) # 输出的是一个元组 # outputs[0] 是所有隐藏状态的最后一层的输出 # outputs[1] 是句子的CLS标签的隐藏状态 last_hidden_states = outputs[0] pooler_output = outputs[1] print(last_hidden_states.shape) print(pooler_output.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出的
last_hidden_states张量的形状为[batch_size, sequence_length, hidden_dim],而pooler_output的形状为[batch_size, hidden_dim]。以上就是加载预训练BERT模型和进行基本推理的全过程。在理解了这些基础知识后,你可以轻松地将BERT用于各种NLP任务,包括但不限于文本分类、命名实体识别或问答系统。
微调BERT模型
微调(Fine-tuning)是将预训练的BERT模型应用于特定NLP任务的关键步骤。在此过程中,我们在特定任务的数据集上进一步训练模型,以便更准确地进行预测或分类。以下是使用PyTorch和
transformers库进行微调的详细步骤。数据准备
假设我们有一个简单的文本分类任务,其中有两个类别:正面和负面。我们将使用PyTorch的
DataLoader和Dataset进行数据加载和预处理。from torch.utils.data import DataLoader, Dataset import torch class TextClassificationDataset(Dataset): def __init__(self, texts, labels, tokenizer): self.texts = texts self.labels = labels self.tokenizer = tokenizer def __len__(self): return len(self.texts) def __getitem__(self, idx): text = self.texts[idx] label = self.labels[idx] inputs = self.tokenizer(text, padding='max_length', truncation=True, max_length=512, return_tensors="pt") return { 'input_ids': inputs['input_ids'].flatten(), 'attention_mask': inputs['attention_mask'].flatten(), 'labels': torch.tensor(label, dtype=torch.long) } # 假设texts和labels分别是文本和标签的列表 texts = ["I love programming", "I hate bugs"] labels = [1, 0] tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') dataset = TextClassificationDataset(texts, labels, tokenizer) dataloader = DataLoader(dataset, batch_size=2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
微调模型
在这里,我们将BERT模型与一个简单的分类层组合。然后,在微调过程中,同时更新BERT模型和分类层的权重。
from transformers import BertForSequenceClassification from torch.optim import AdamW # 初始化模型 model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2) # 使用AdamW优化器 optimizer = AdamW(model.parameters(), lr=1e-5) # 训练模型 for epoch in range(3): for batch in dataloader: input_ids = batch['input_ids'] attention_mask = batch['attention_mask'] labels = batch['labels'] outputs = model(input_ids, attention_mask=attention_mask, labels=labels) loss = outputs.loss loss.backward() optimizer.step() optimizer.zero_grad() print(f'Epoch {epoch + 1} completed')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
模型评估
完成微调后,我们可以在测试数据集上评估模型的性能。
# 在测试数据集上进行评估...- 1
通过这样的微调过程,BERT模型不仅能够从预训练中获得的通用知识,而且能针对特定任务进行优化。
六、总结
经过对BERT(Bidirectional Encoder Representations from Transformers)的深入探讨,我们有机会一窥这一先进架构的内在复杂性和功能丰富性。从其强大的双向注意力机制,到预训练和微调的多样性应用,BERT已经在自然语言处理(NLP)领域中设置了新的标准。架构的价值
-
预训练和微调: BERT的预训练-微调范式几乎是一种“一刀切”的解决方案,可以轻松地适应各种NLP任务,从而减少了从头开始训练模型的复杂性和计算成本。
-
通用性与专门化: BERT的另一个优点是它的灵活性。虽然原始的BERT模型是一个通用的语言模型,但通过微调,它可以轻松地适应多种任务和行业特定的需求。
-
高度解释性: 虽然深度学习模型通常被认为是“黑盒”,但BERT和其他基于注意力的模型提供了一定程度的解释性。例如,通过分析注意力权重,我们可以了解模型在做决策时到底关注了哪些部分的输入。
发展前景
-
可扩展性: 虽然BERT模型本身已经非常大,但它的架构是可扩展的。这为未来更大和更复杂的模型铺平了道路,这些模型有可能捕获更复杂的语言结构和语义。
-
多模态学习与联合训练: 随着研究的进展,将BERT与其他类型的数据(如图像和音频)结合的趋势正在增加。这种多模态学习方法将进一步提高模型的泛化能力和应用范围。
-
优化与压缩: 虽然BERT的性能出色,但其计算成本也很高。因此,模型优化和压缩将是未来研究的重要方向,以便在资源受限的环境中部署这些高性能模型。
综上所述,BERT不仅是自然语言处理中的一个里程碑,也为未来的研究和应用提供了丰富的土壤。正如我们在本文中所探讨的,通过理解其内部机制和学习如何进行有效的微调,我们可以更好地利用这一强大工具来解决各种各样的问题。毫无疑问,BERT和类似的模型将继续引领NLP和AI的未来发展。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
-
-
相关阅读:
C++模板编程(8)---更深入的基础技术:参数化声明(Parameterized Declarations)
基于Java+SpringBoot+vue+elementui社区疫情防控系统详细设计实现
PostgreSQL执行计划
青鸾剪辑-全自动视频混剪,批量剪辑批量剪视频,探店带货系统,精细化顺序混剪,故事影视解说,视频处理大全,精细化顺序混剪,多场景裂变,多视频混剪
selenium.webdriver chrome驱动下载地址
常见的屏幕接口
0025【Edabit ★☆☆☆☆☆】【足球得分】Football Points
人力外包有什么优势
ssm+vue+elementUI 校园短期闲置资源置换平台-#毕业设计
基于蒙特卡洛法的规模化电动车有序充放电及负荷预测(Python&Matlab实现)
- 原文地址:https://blog.csdn.net/magicyangjay111/article/details/132665098