-
“百模大战”大模型哪家强?开源的全面评测来了!
最近,一则推送在网上火了:《世界人工智能大会上的大模型都在这了,让你一次看个够》 小编兴奋地点开文章,好家伙,整篇文章没有字,只有满眼的 “大模型”。

小编顶着昏花的老眼,手动数了一下,在 WAIC 大会上发布的大模型,至少有 58 个之多。🤦
而根据今年的《中国人工智能大模型地图研究报告》,国内现在已经发布了多达 79 个参数 10 亿规模以上的大模型。可谓是百花齐放,各有千秋。在各家对各自模型的宣传中,也都展示了自己模型强悍的一面,让不少围观者不禁为之振奋,直呼牛哇。
然而,市面上也存在着相当一部分疑惑的声音——作为用户,我们怎么能直观地知道哪个模型更强呢?不可否认的是,目前大模型评测还是一个比较困难的问题。尽管此前已经有了 MMLU、CEval 等比较权威的开源数据集榜单,可是它们只能反映模型在某个点上的能力,并无法准确地衡量出一个模型的综合能力。
另一方面,市面上也存在着一些对大模型进行评测的方案。可是,它们有的偏向学术研究,上手较难,让普通用户望而却步;有的方案并非完全公开,用户想要得知结果,只能手动提交评测申请,再望穿秋水地等待结果。 这时,我们就需要一个全面、公正、开源的裁判,让大家伙儿随时在同一条起跑线上进行全能测试。小编在此隆重介绍我们今天的主角 —— OpenCompass!
先简单介绍一下 OpenCompass 的几大亮点:
-
提供了约 30 万道题目,全面测试模型五大能力;
-
全面支持各类开源模型(InternLM, LLaMA, ChatGLM2, Baichuan 等)和 API 模型(ChatGPT, Claude 等);
-
分布式高效评测,三小时完成千亿模型评测(资源充足的情况下☺️)
-
支持零样本、小样本及思维链评测,轻松激发模型最大性能;
-
代码和提示词全面开源,评测结果可自行复现;
-
支持对多模态模型开展全面的能力评测(包括 KOSMOS-2/MiniGPT-4 等最新多模态模型)。
另外,OpenCompass 也同步维护一份公开的评测榜单。用户可以选择提交自己的模型接口,评测完成后榜单上亦会实时更新最新结果。
接下来,就让我们详细了解一下 OpenCompass 的各项亮点吧!
全面的能力维度测评
MMLU、CEval、AGIEval,是此前各家大模型常测的几个大数据集。然而,它们都只反映了模型在考试方面的能力。而在 OpenAI 给出的报告中,也仅展示了 ChatGPT 在 7 个数据集上的能力。对于急切想要比较不同模型性能之间差异的业界来说,这还远远不够。
OpenCompass 则完成了一件狠活——一口气把各家常用的数据集统统支持了上去。同时,根据数据集的不同,把测评的方向汇总为知识、语言、理解、推理、学科等五大能力维度,合计提供了 50+ 个数据集约 30 万题的的模型评测方案。感受一下目前支持的所有数据集:

丰富的模型支持
作为目前最受欢迎的大模型托管平台,HuggingFace 存放了市面上几乎所有流行的开源模型。OpenCompass 则一步到位,允许用户直接评测上面的语言模型。同时,OpenCompass 也约定了一套非常简洁的模型接口,使得 API 模型和自定义模型的接入十分简单。OpenCompass 目前已经支持了 OpenAI 接口的调用(支持测试ChatGPT/GPT-4),后续还会持续支持 Claude, PaLM 等多种 API 模型,及 InternLM 的高性能推理,敬请大家期待!
分布式高效评测
大模型时代,时间成本已经变得不可忽视。即便推理阶段,一个数据集跑个十几小时也是常有的事情。如果不作任何优化,光是完成 50+ 个数据集的评测的时间,大概都足够小编去欢度一个黄金周了 🤦
所幸,OpenCompass 原生提供了分布式评测方案,支持了本机或集群上的计算任务并行分发,实现评测并行式的提速。此外,还通过分割大任务、合并小任务等策略,控制各计算任务的执行时间尽可能相等,实现计算负载均衡,更加充分地利用所有的计算资源。在我们内部的测试中,运算资源充足的情况下,OpenCompass 最短仅需要 3 个小时即完成千亿参数量级模型的完全评测,从而实现了模型训练-评测链路上的快速迭代,可谓是打工人的福音! 🥰
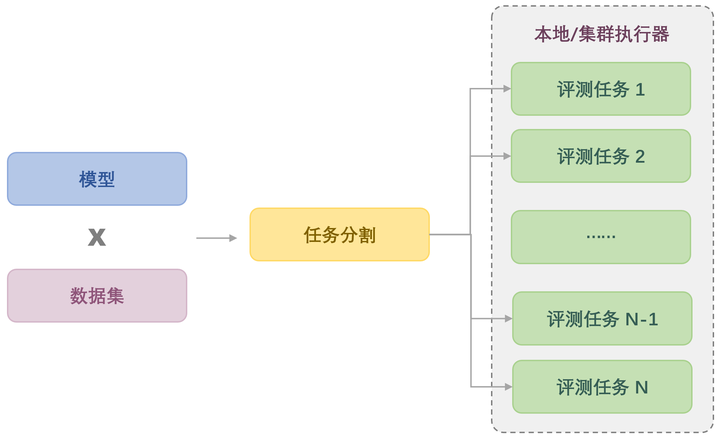
支持任务自由切割和组合,高效并发评测
多样化评测范式
在模型评测时,评测策略的选择也对模型结果有至关重要的影响。例如,在测评模型时,有时需要给模型提供一些上下文样例(in-context examples),以便模型更好地按照格式回答问题。此外,在对逻辑推理能力要求较高的数据集上,思维链 (chain-of-thought) 式的评测策略能很好地激发模型的推理能力。对于一些经过微调的对话式模型,我们可能还需要把提示词以对话的模式输入模型,才能对齐对话模型的性能。
而 OpenCompass 除了最基础的零样本评测策略外,也支持小样本的评测策略,甚至还提供了 7 种不同的上下文样例的提取方案,助你花式构建提示词。同时,也即将支持思维链式的评测。
此外,OpenCompass 还针对对话模型的特性,首创了与模型绑定的提示词模板(meta template),允许用户自定义模型的对话模板,从而把提示词以最优的方式传入基座或对话模型。

支持多种评测提示词构建策略,最大程度激发模型性能
开源可复现
最重要的是,OpenCompass 作为一个公开的评测方案,项目的一切是全面开源的!OpenCompass 已经为大家提前整理了所有支持的数据集,用户可以根据文档一键下载。此外,经过精心设计的代码架构也允许大家快速添加新的模型和数据集,或者自定义数据划分策略,甚至接入新的集群管理后端。OpenCompass 还同步开源了各数据集多版本的提示词,供社区参考使用。通过多方位全链路的公开,确保评测结果可以被完整复现。同时,我们也非常欢迎社区各界共同参与贡献,持续优化提示词和测试逻辑,共同打造更强大、更全面的大模型评测基准。

OpenCompass 为每个数据集都提供了多种评测方案(图片以 ARC 为例)
公开评测榜单
最后,OpenCompass 还会在官方网站上持续维护一份大模型的性能榜单(OpenCompassleaderboard-llm),上面会定期更新大模型的综合性能评分,供大家参考。目前,OpenCompass 已经放出了 ChatGPT,以及一批 7B 和 13B 开源模型的评测结果。
在定期维护之外,OpenCompass 同样接受社区提交的评测申请,评测结果会在完成后被实时更新在榜单上。(备注:排行榜分数受到 OpenCompass 当前支持的数据集及提示词影响,分值和相对排名仅供参考。OpenCompass 将会持续保持榜单、测试数据及评分细则的公开。)
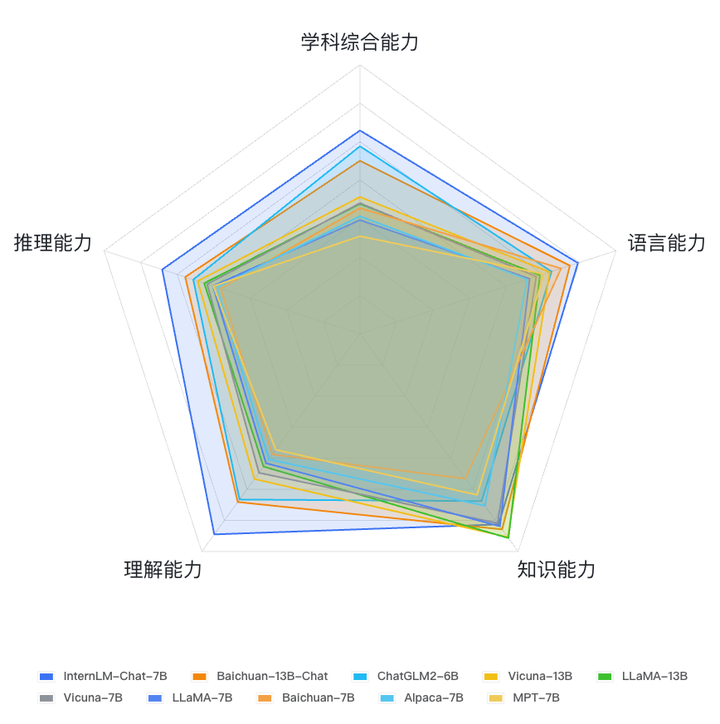
6-7B 模型能力一览 (数据截止至 2023.7.13)

榜单一览 (数据截止至 2023.7.13)
面向多模态模型的能力评测方案
OpenCompass 平台也正在逐步建设面向多模态模型的评测能力。近期我们发布了MMBench,帮助社区全面评估当前多模态模型,弥补了其他评测方案的不足。 MMBench 包含以下特点:
-
涵盖多个评测能力维度的数据集,目前该数据集涵盖 2974 道单项选择题,20 个评测能力项
-
率先提出 CircualrEval 的评测方式,以及利用 ChatGPT 来对模型的输出进行打分。
目前数据集和 Paper 都进行了开源 ,欢迎社区各路多模态模型在 MMBench Leaderboard 进行 PK。
Paper 链接:
https://arxiv.org/pdf/2307.06281.pdf
Project 链接:
Leaderboard 链接:
以上就是关于 OpenCompass 的全部介绍,感兴趣的小伙伴欢迎来猛烈 Star, Fork, PR!
同时欢迎社区用户尝试 OpenCompass 的姊妹项目
LMDeploy: LLM 任务的全套轻量化、部署和服务解决方案
GitHub - InternLM/lmdeploy: LMDeploy is a toolkit for compressing, deploying, and serving LLMs.
InternLM: 全面开源、免费商用的 7B 大语言模型
-
-
相关阅读:
kotlin协程CoroutineScope Dispatchers.IO launch 线程Id
【SpringCloud微服务实战01】Eureka 注册中心
python爬虫(Selenium案列)第二十四
前端工程师的素养
使用Python进行自然语言处理(NLP):NLTK与Spacy的比较【第133篇—NLTK与Spacy】
Jetpack Compose 入门教程之Text
JSP连接MySQL数据库
使用腾讯云发送短信 ---- 手把手教你搞定所有步骤
Tower for Mac:Git管理的新境界
Pytorch实用教程:nn.CrossEntropyLoss()的用法
- 原文地址:https://blog.csdn.net/qq_39967751/article/details/132755786
 https://github.com/open-compass/opencompass
https://github.com/open-compass/opencompass