-
KubeSphere Namespace 数据删除事故分析与解决全记录
作者:宇轩辞白,运维研发工程师,目前专注于云原生、Kubernetes、容器、Linux、运维自动化等领域。
前言
2023 年 7 月 23 日在项目上线前夕,K8s 生产环境出现故障,经过紧急修复之后,K8s 环境恢复正常;另外我们环境引入了 KubeSphere 云原生平台技术,为了方便研发人员对于 K8s 权限的细粒度管理,我方手动将 K8s Namespace(生产环境业务命名空间)加入到 KubeSphere 中的 Workspace(企业空间),就在此时,发生了让人后背一凉、极度可怕的事故,就是生产命名空间(Namespace)被自动删除了,熟悉 K8s 的人都知道,这意味着该命名空间下的所有数据,都被清空了。
问题简述
事故的来龙去脉
我们项目环境有两套 K8s 集群(即生产/测试),两套 K8s 环境准备完毕之后,分别在两套 K8s 引入 KubeSphere 云原生平台,计划通过 KubeSphere 启用多集群模式去管理两套 K8s:生产 K8s 集群将设置为 Host 主集群,测试环境 K8s 设置为 Member 集群。在此期间一切准备就绪,就等次日正式对外上线。
在 2023 年 7 月 22 号晚上七点十分,忽然收到研发人员反馈:测试环境 KubeSphere 平台无法正常使用,数据库都无法打开。
随后我展开排查,发现整个 KubeSphere 平台都瘫痪了。经过确认,是因第三方客户技术人员做资源克隆,间接性影响了生产环境。
排查未果,情急之下我直接卸载了 KubeSphere 进行重装,重装之后暂时恢复了正常。随后我将两套 K8s 集群重新加入到 KubeSphere 平台托管,再将 K8s 的 Namespace 加入到 KubeSphere 所创建好的 WorkSpace 进行管理。
就在此刻,我发现加入到 WorkSpace 的 Namespace 竟在顷刻间自动删除,致使我 NameSpace 下的所有生产数据资源全部丢失。我以为是 Workspace 的问题,因此重建新的 Workspace 测试进行测试,结果同样被删除。
此时此刻,我心想,坏了出大事了!
集群环境
- Kubesphere 3.3.1
- K8s v1.22
[root@k8s-master01 ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core) [root@k8s-master01 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master01 Ready,SchedulingDisabled51d v1.22.0 k8s-master02 Ready,SchedulingDisabled 51d v1.22.0 k8s-master03 Ready,SchedulingDisabled 51d v1.22.0 k8s-node01 Ready 51d v1.22.0 k8s-node02 Ready 51d v1.22.0 k8s-node03 Ready 51d v1.22.0 k8s-node04 Ready 12d v1.22.0 k8s-node05 Ready 12d v1.22.0 [root@k8s-master01 ~]# kubectl get cluster NAME FEDERATED PROVIDER ACTIVE VERSION host true KubeSphere true v1.22.0 test-host true v1.22.0 [root@k8stst-master01 ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core) [root@k8stst-master01 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8stst-master01 Ready,SchedulingDisabled 58d v1.22.0 k8stst-master02 Ready,SchedulingDisabled 58d v1.22.0 k8stst-master03 Ready,SchedulingDisabled 58d v1.22.0 k8stst-node01 Ready 58d v1.22.0 k8stst-node02 Ready 58d v1.22.0 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
分析排查
故障演示
创建一个名为
testv1的 Namespace,然后将其加入到名为ws1的 Workspace 中。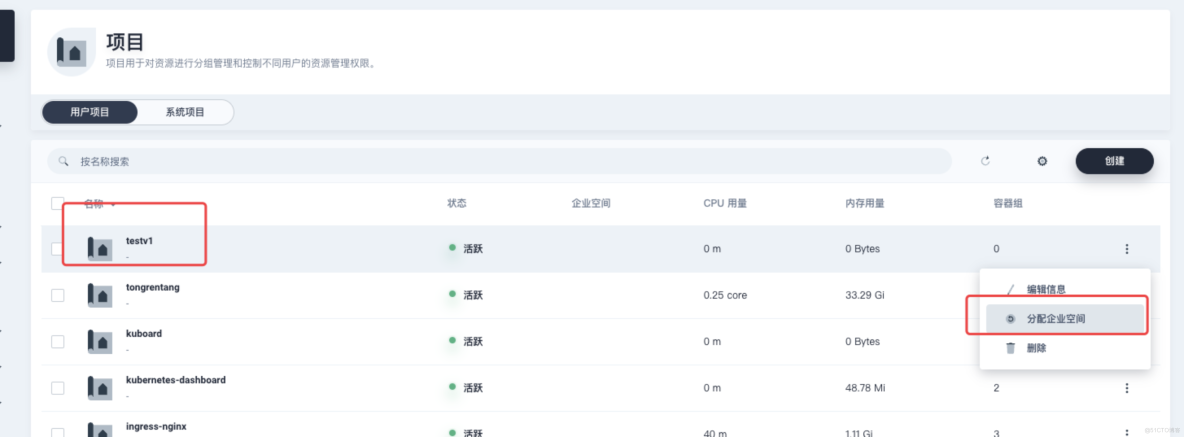
将
testv1分配至ws1下,点击确定右上角就出现了错误提示。role.rbac.authorization.k8s.io"admin" not fount这表示在 K8s 集群中没有找到名为
admin的 KubeSphere role。这个错误通常发生在试图为 KubeSphere 添加或配置角色时,使用了一个不存在的角色名称。此时我们继续往下看。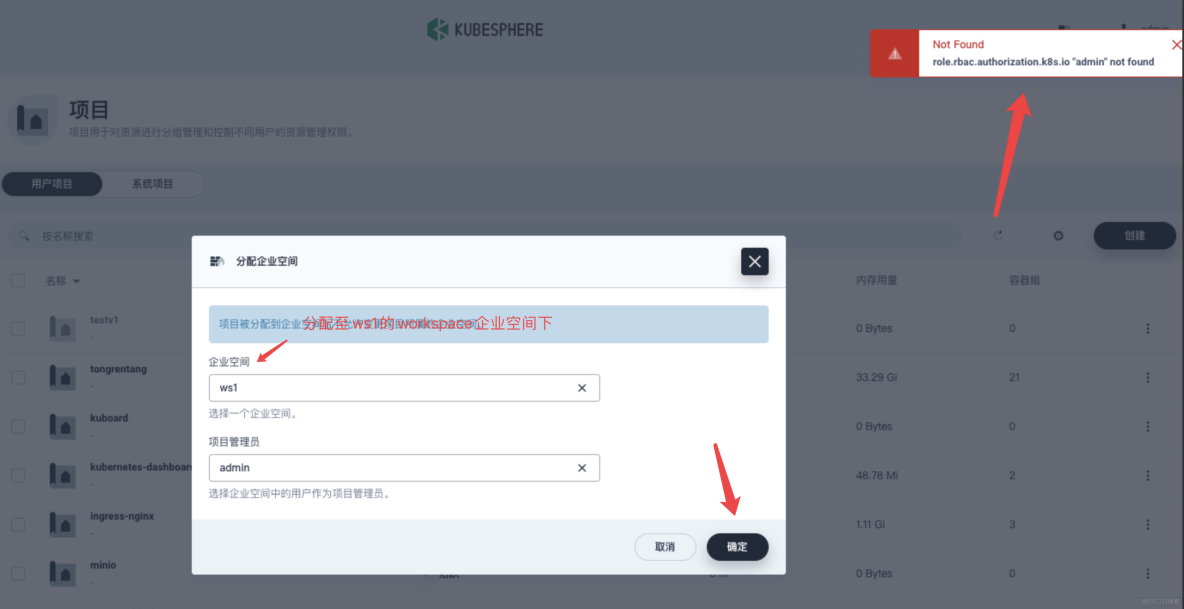
加入之后你会发现,Namespace 已处于自动删除状态中。
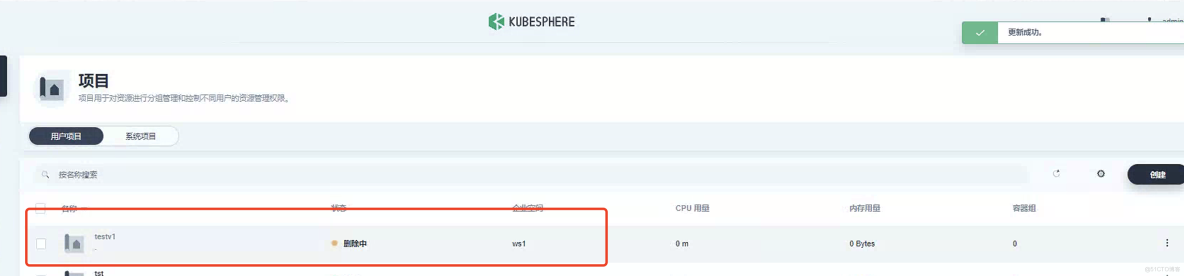
然后我发现刚才创建的 Namespace
testv1这个命名空间确实被删除了。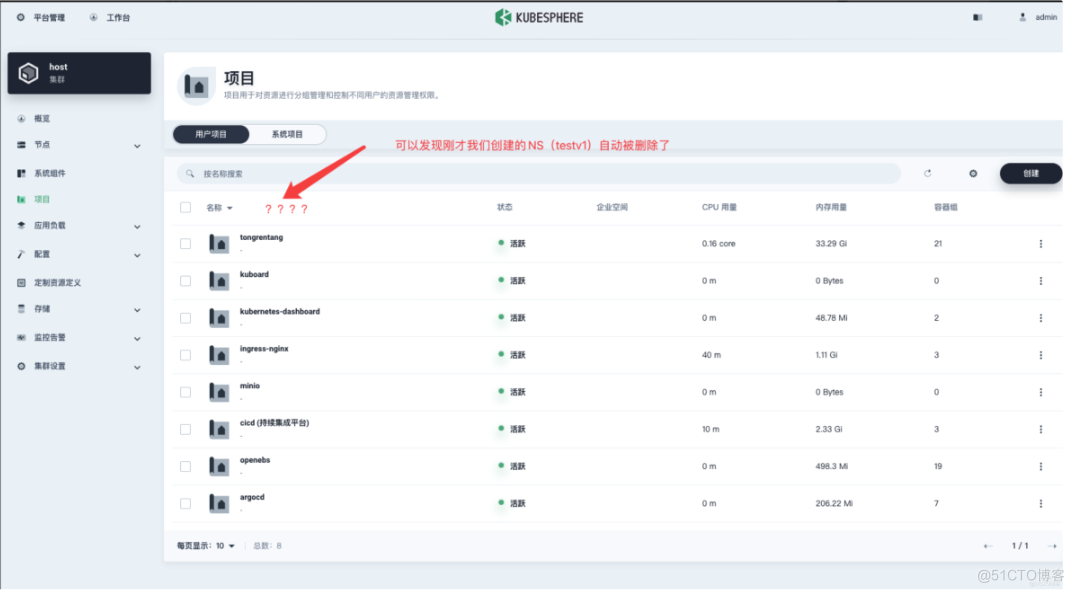
而且这个删除是彻底的,在 Etcd 中都找不到丝毫痕迹。
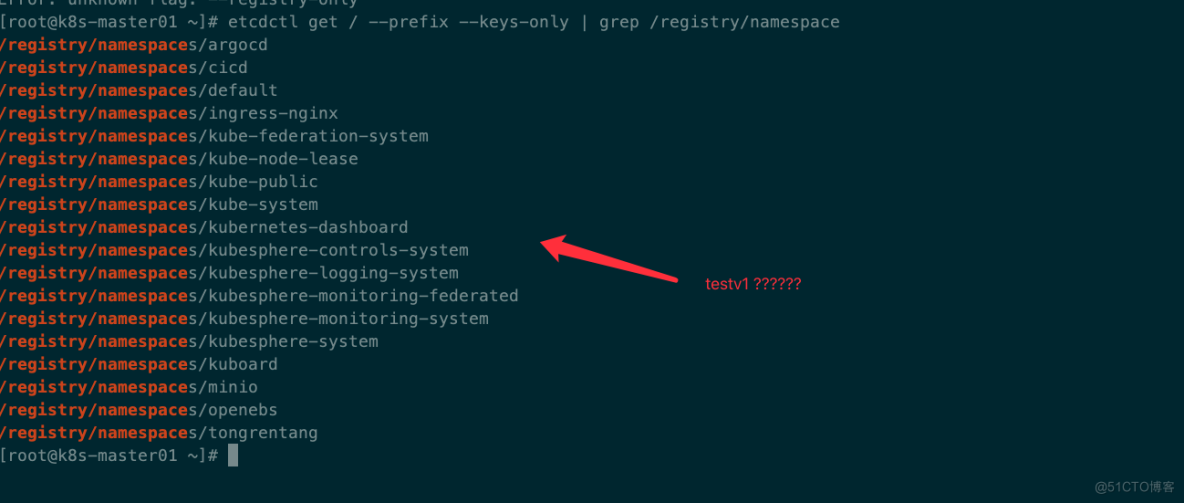
随后我进一步展开排查,想通过
kubefed-controller-managerpod 日志寻找一些有价值的线索。#kubectl -n kube-federation-system get pod NAME READY STATUS RESTARTS AGE kubefed-admission-webhook-6f9f5dcbbf-8krrp 1/1 Running 1 (13d ago) 13d kubefed-controller-manager-78c4dbc5f8-bbqj6 1/1 Running 0 11d kubefed-controller-manager-78c4dbc5f8-qvsrb 1/1 Running 0 11d #kubectl -n kube-federation-system logs -f kubefed-controller-manager-78c4dbc5f8-qvsrb- 1
- 2
- 3
- 4
- 5
你可以手动模拟将 Namespace 加入到 Workspace 的同时,实时输出
kubefed-controller-manager日志信息。可以看到,在 Namespace 加入 Workspace 之后,Namespace 就被干掉了。

最后我检查了 KubeSphere Workspace 的状态,发现 Workspace 不稳定,从现象上看 Host 集群中 Workspace 被不停的创建和删除。
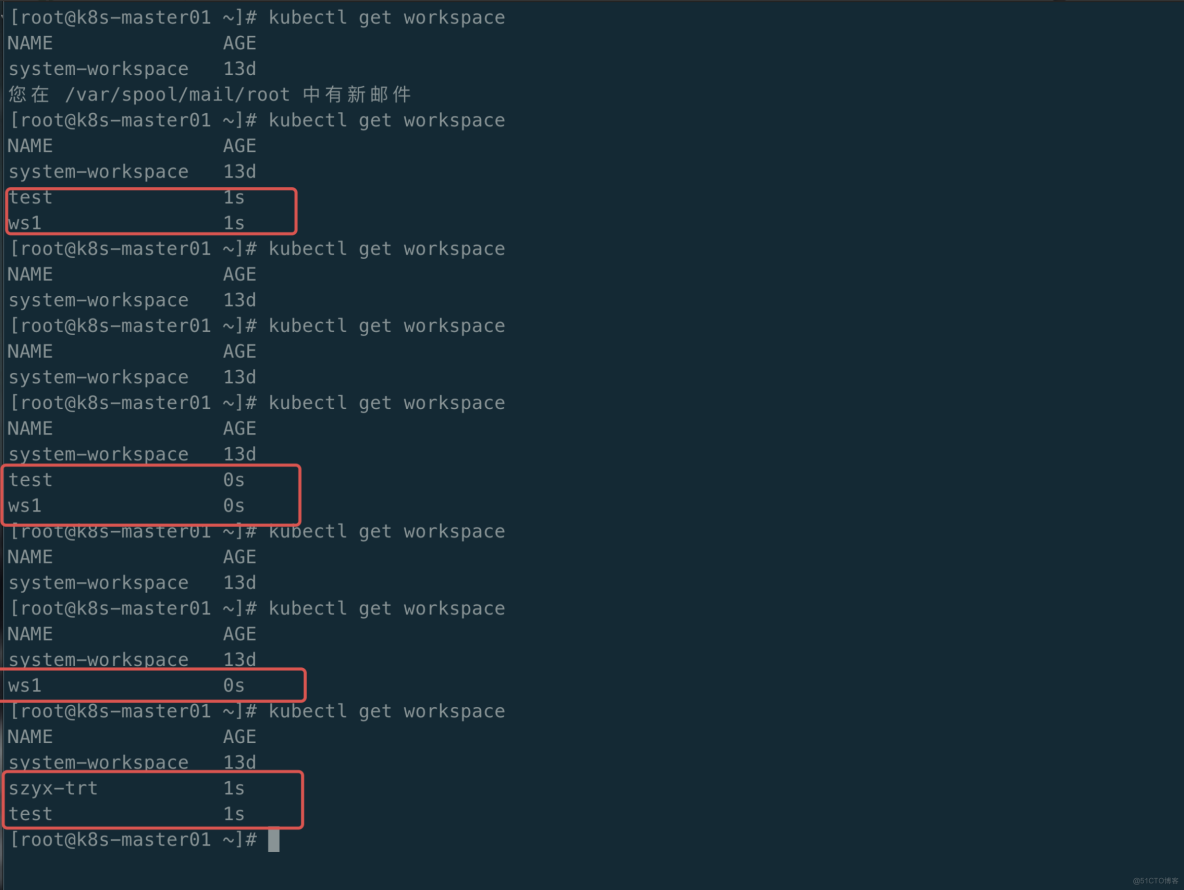
分析判断
首先我们可以将问题范围缩小至 KubeSphere 多集群管理这里,该功能使用了 Kubefed 这个组件,思考以下几点疑问:
问题 1:为什么重装了 KubeSphere 之后会出现这种情况呢?难道是我卸载之后再重装,该环境没有彻底清除干净?
问题 2:什么情况会导致创建一个 Namespace 加入到 Workspace 之后会被删除掉呢?
问题 3:这里面的逻辑是什么样的呢?
以上,我带着疑问翻阅了 KubeSphere 多集群管理 Kubefed 托管的相关官网,得知,Kubefed 托管是指在 KubeSphere 平台上通过 Kubefed 控制器来管理和操作多个 K8s 集群的联邦特性:
- Kubefed 控制器:Kubefed 是一个 K8s 控制器,用于提供联邦特性,使得多个 K8s 集群可以联合管理。Kubesphere 通过部署 Kubefed 控制器来实现对多集群的联邦管理。
- 联邦 API 服务器:Kubefed 控制器在每个 K8s 集群上启动一个联邦 API 服务器。这些联邦 API 服务器相互通信,用于管理联邦资源和配置。
- 联邦配置:在 KubeSphere 中配置联邦相关的资源,例如联邦命名空间、联邦服务、联邦副本集等。这些联邦资源将通过联邦 API 服务器进行同步和管理。
- 联邦控制:Kubefed 控制器会周期性地检查联邦资源的状态和配置,并根据配置的策略自动进行同步和调度。例如,当创建一个联邦副本集时,Kubefed 控制器会将该副本集在各个联邦集群中进行创建和调度。
- 跨集群资源访问:通过联邦特性,可以在一个集群中访问和管理其他集群的资源。在 KubeSphere 中,可以通过联邦命名空间和联邦服务来实现跨集群的资源访问和通信。 总而言之,KubeSphere Kubefed 托管通过部署 Kubefed 控制器和联邦 API 服务器,结合联邦配置和控制机制,实现了对多个 K8s 集群的联邦管理和操作。
验证问题猜想
通过分析,我有了一点点头绪。很有可能当前的主集群 Host 被多个 Kubefed 托管产生了冲突。但为什么产生冲突?可能当时卸载 KubeSphere 没有清理干净:当时删除只是通过脚本清理了 KubeSphere-system 相关 pod,但是 Kubefed 相关资源没有清理掉,当重新配置新 Host 集群的时候,导致当前的 Host 集群被多个 Kubefed 托管产生了冲突。
一个是当前集群的 Kubefed,因创建的 Workspace 关联了 Host 集群,所以 Kubefed 会在 Host 上创建出 Workspace,然而在此之前,这个 Host 集群也被另外一个 Kubefed 进行托管,由于创建出来的 Workspace 带有
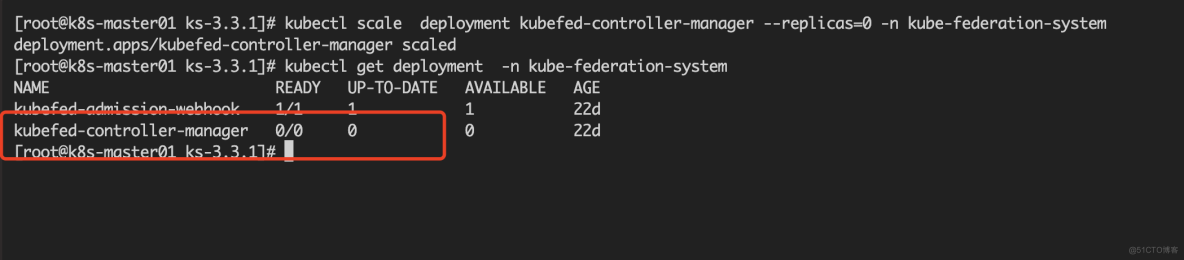
kubfed.io/managed: 'true'这个标签,此时就会产生冲突,导致 Workspace 不停的被创建和删除。为了验证该猜想,我把当前集群中的 Kubefed controller 停止(可设置为 0),然后再手动创建一个 Workspace 并打上
kubfed.io/managed: 'true'标签,验证一下是否仍然被删除。
#kubectl get deployment -n kube-federation-system 停止当前 kubefed controller #kubectl scale deployment kubefed-controller-manager --replicas=0 -n kube-federation-system deployment.apps/kubefed-controller-manager scaled- 1
- 2
- 3
Deployment 副本控制器设置为 0 之后,再手动将 Namespace 加入 Workspace。此时发现 Namespace 没有被删除,Workspace 也没有出现不断创建删除等现象。
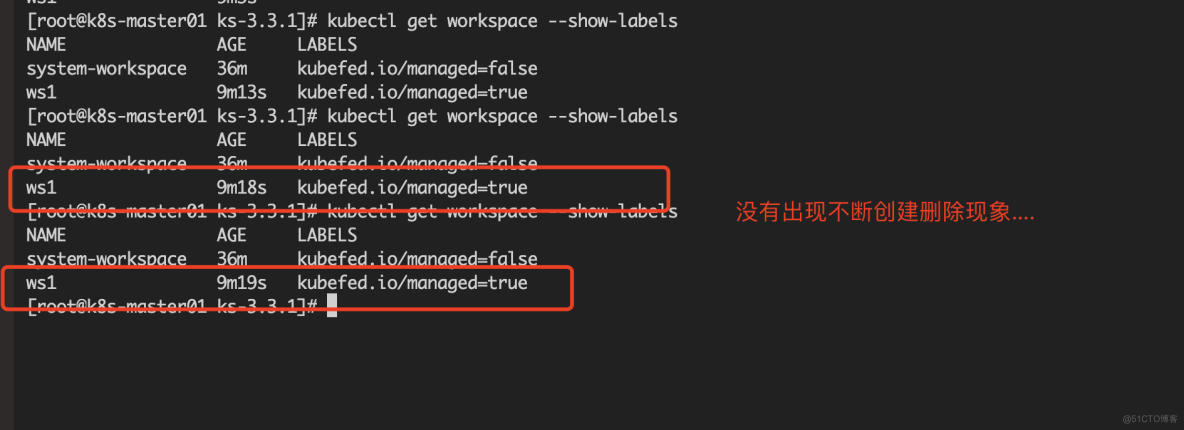
最后我们再将设置为 0 的 Kubefed controller 还原回来。
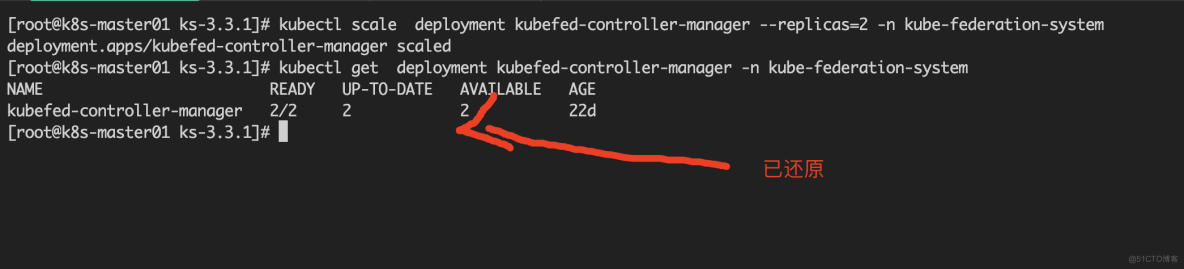
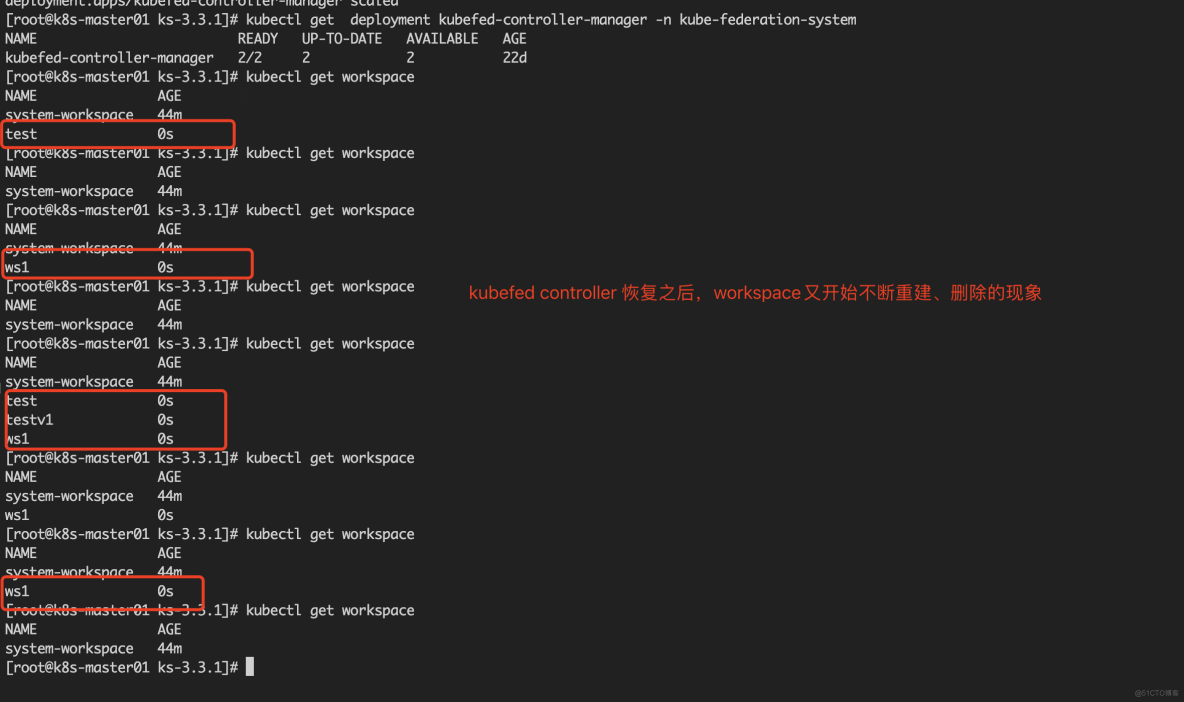
问题解决
经过上述验证发现:将当前的
kubefed controller-manager停掉,然后再创建的 Workspace 在加入了 Namespace 之后,没有继续被删除,等再将 Kubefed controller 还原之后,Workspace 又出现之前的现象。此时就可以断定,除了当前 Host 集群中的 Kubfed 之外,很有可能原始 Host 集群的 Kubfed 没有被删除。也就是说两个相同的 Host Kubefed 同时托管当前的 Host 集群,自然而然就会对当前 Host 集群产生了影响,究其原因,在起初卸载 KubeSphere 环境的时候,没有正确的将 Kubefed Host 集群中移除,当新的 Kubefed Host 起来之后,就会造成冲突。
此时我们通过
kubectl get kubefedclusters.core.kubefed.io -n kube-federation-system可以看到两个 cluster,分别是当前的 Host cluster 和 Member cluster,当前的 Host 集群(可以理解为集群中部署的 Kubfed 管理了自己)和 Member 集群都被托管到了 Host 集群中部署的 Kubfed,并通过 KubeSphere 进行管理。查看 kubefed 联邦集群的信息 #kubectl get kubefedclusters.core.kubefed.io -n kube-federation-system- 1

通过 api 地址来判断当前是否异常的 host cluster #kubefedclusters.core.kubefed.io -n kube-federation-system -o yaml- 1

最妥当的办法就是将原始的 Kubefed cluster 删除:
#kubectl delete kubefedclusters.core.kubefed.io produce-trt -n kube-federation-system此时你会发现,问题得到解决。
总结
通过本次事故,我学习了很多,认识到了自己的不足。我仍然需要在云原生这个领域去深耕沉淀。
对于运维来讲,我觉得遇到问题是一件幸运的事情。尽管这些问题会让你崩溃甚至自我怀疑,但却是一个个成长的契机。运维的核心竞争力就是解决问题的能力。
遇到问题,你需要搞清楚里面的逻辑原理,这样才能更好的处理。所以,解决问题的过程也是一个学习的过程。
本文由博客一文多发平台 OpenWrite 发布!
-
相关阅读:
go演示GRPC的用法
oracle数据同步报错请确认数据库名是否正确
数据库系统 第7节 数据控制语言
怎么隐藏服务器的ip地址
Cn2线路异常采用Nginx反代灾备解决方案
Makefile泛谈
敏捷是怎么提高工作效率的
Feign远程调用时的步骤
DSP篇--C6678功能调试系列之DDR3调试
LeeCode《可以读通讯稿的组数》ac题解
- 原文地址:https://blog.csdn.net/zpf17671624050/article/details/132737608
