-
2023高教社杯全国大学生数学建模竞赛C题代码解析
因为一些不可抗力,下面仅展示部分代码(第一问的部分),其余代码看文末
首先导入需要的包:
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
- import os
- import warnings
- warnings.filterwarnings('ignore')
- from sklearn.preprocessing import LabelEncoder
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
- from sklearn.linear_model import LogisticRegression
- from sklearn.tree import DecisionTreeClassifier
- import matplotlib.font_manager as fm
读取数据:
- Read the data
- '''
- # data_1: 6 个蔬菜品类的商品信息
- # data_2: 销售流水明细数据
- # data_3: 蔬菜类商品的批发价格
- # data_4: 蔬菜类商品的近期损耗率
- 附件 1 中,部分单品名称包含的数字编号表示不同的供应来源。
- 附件 4 中的损耗率反映了近期商品的损耗情况,通过近期盘点周期的数据计算得到。
- '''
- data_1 = pd.read_excel('../data/附件1.xlsx')
- data_2 = pd.read_excel('../data/附件2.xlsx')
- data_3 = pd.read_excel('../data/附件3.xlsx')
- data_4 = pd.read_excel('../data/附件4.xlsx')
中间我跳过一些数据处理的部分,来看看可视化结果:
- # 以季度为周期,可视化不同蔬菜品类销售量的变化趋势
- # 将销售数据按照季度进行重采样
- quarterly_sales = merged_data.resample('Q', on='销售日期')['销量(千克)'].sum()
- # 将销售数据按照分类名称和季度进行分组,计算每个品类在每个季度的销售量
- # sales_by_category = merged_data[merged_data['销售类型'] == '销售'].groupby(['分类名称', pd.Grouper(key='销售日期', freq='Q')])['销量(千克)'].sum() - merged_data[merged_data['销售类型'] == '退货'].groupby(['分类名称', pd.Grouper(key='销售日期', freq='Q')])['销量(千克)'].sum()
- sales_by_category = merged_data[merged_data['销售类型'] == '销售'].groupby(['分类名称', pd.Grouper(key='销售日期', freq='Q')])['销量(千克)'].sum()
- # 可视化销售量变化趋势
- fig, ax = plt.subplots(figsize=(10, 6))
- for category in sales_by_category.index.levels[0]:
- ax.plot(sales_by_category.loc[category].index, sales_by_category.loc[category].values, label=category)
- ax.legend()
- ax.set_xlabel('季度')
- ax.set_ylabel('销售量(千克)')
- ax.set_title('蔬菜各品类销售量变化趋势')
- plt.savefig('../results/sales_num_trend.png', dpi=300, bbox_inches='tight')

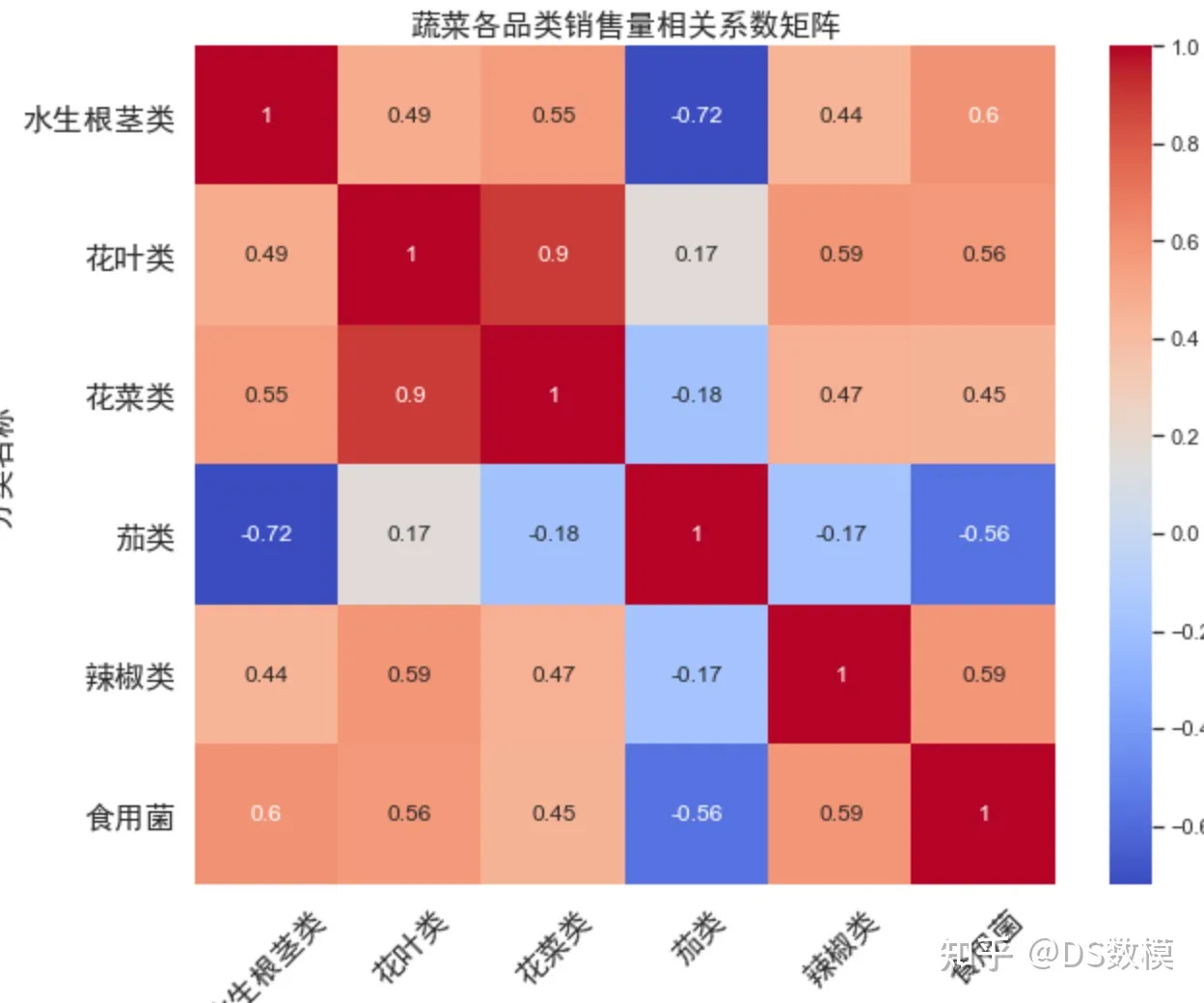
热力图的部分代码:
- # 计算各品类销售量之间的相关系数
- corr_matrix = sales_by_quarter.corr()
- # 可视化相关系数矩阵
- sns.set(style='white')
- fig, ax = plt.subplots(figsize=(10, 8))
- sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', ax=ax)
- ax.set_title('蔬菜各品类销售量相关系数矩阵', fontproperties=font)
- for tick in ax.get_xticklabels():
- tick.set_rotation(45)
- tick.set_fontproperties(font)
- for tick in ax.get_yticklabels():
- tick.set_rotation(0)
- tick.set_fontproperties(font)
- plt.xlabel('分类名称', fontproperties=font)
- plt.ylabel('分类名称', fontproperties=font)
- plt.savefig('../results/corr_matrix.png', dpi=300, bbox_inches='tight')
- plt.show()
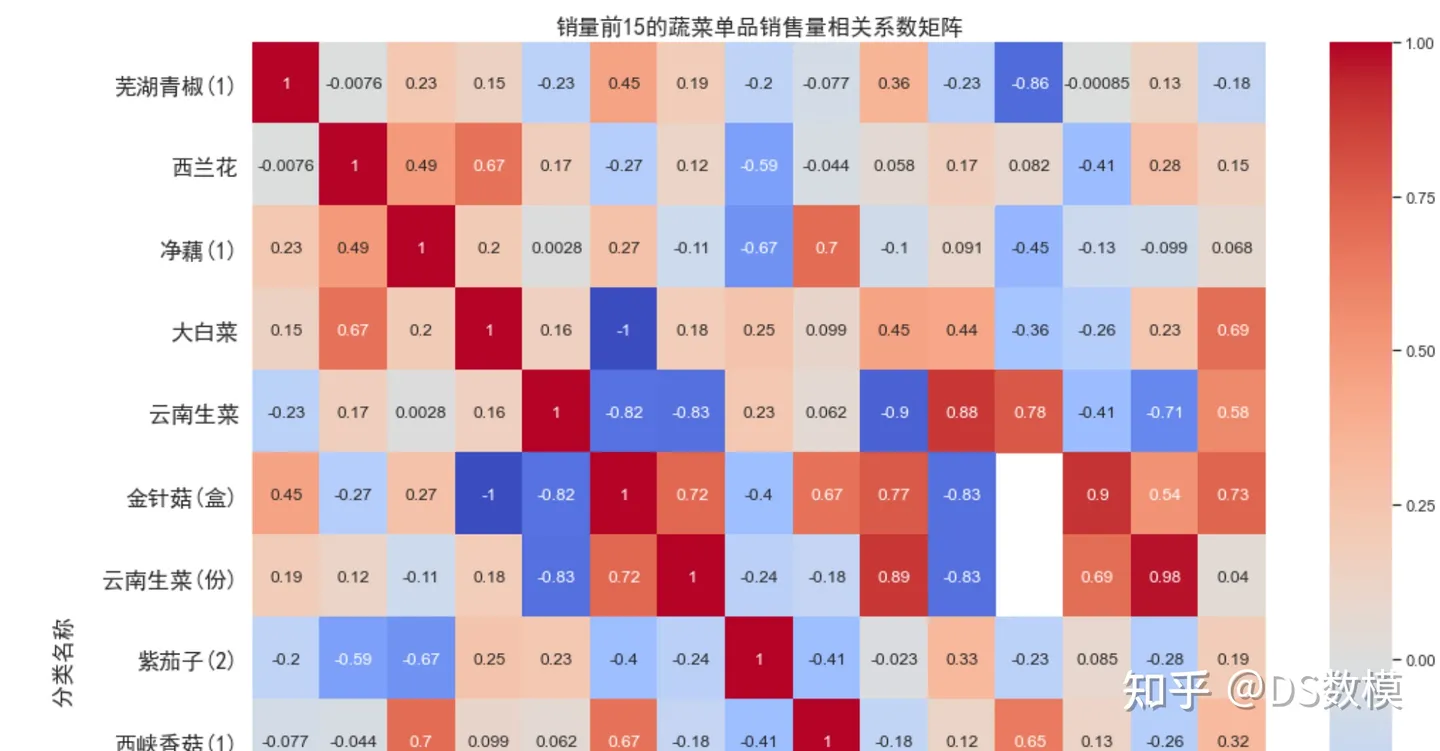
- # 可视化相关系数矩阵
- sns.set(style='white')
- fig, ax = plt.subplots(figsize=(16, 16))
- sns.heatmap(corr_matrix_top_veggies, annot=True, cmap='coolwarm', ax=ax)
- ax.set_title('销量前15的蔬菜单品销售量相关系数矩阵', fontproperties=font)
- for tick in ax.get_xticklabels():
- tick.set_rotation(45)
- tick.set_fontproperties(font)
- for tick in ax.get_yticklabels():
- tick.set_rotation(0)
- tick.set_fontproperties(font)
- plt.xlabel('分类名称', fontproperties=font)
- plt.ylabel('分类名称', fontproperties=font)
- plt.savefig('../results/corr_matrix_top_veggies.png', dpi=300, bbox_inches='tight')
- plt.show()
有关思路、相关代码、讲解视频、参考文献等相关内容可以点击下方群名片哦!
-
相关阅读:
cJSON:一个轻量级C语言JSON解析器
mysql主从复制docker版
前端开发重装系统,软件安装清单
Apriori介绍及代码批注
C++ 类模板实现栈和循环队列
NSSCTF第十页(2)
简单模拟Lur 算法
【力扣算法简单五十题】18.杨辉三角
上门服务小程序源码 理疗,足疗,美容SAP上门服务小程序源码
python 实现euler modified变形欧拉法算法
- 原文地址:https://blog.csdn.net/weixin_43345535/article/details/132746713
