-
Map,List,Set 等集合以及底层数据结构
概述
集合类存放于java.util包中。集合类存放的都是对象的引用,而非对象本身。常见的集合主要有三种——Set(集)、List(列表)和Map(映射)。其中,List和Set
都实现了 Collection 接口,并且List和Set也是接口,而Map 为独立接口。常见的实现类如下:List 的实现类有:ArrayList、Vector、LinkedList; Set
的实现类有:HashSet、LinkedHashSet、TreeSet; Map
的实现类有:Hashtable、HashMap、ArrayMap、LinkedHashMap、TreeMap。补充知识:散列表,也叫哈希表(Hash table),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
一、Collection接口
(1)List列表 —— 有序、值可重复
1、ArrayList
优点: 底层数据结构是数组Array,查询快。增删慢。
缺点: 线程不安全,效率高2、Vector
优点: 底层数据结构是数组Array,查询快。增删慢。
缺点: 线程安全,效率低*Vector是实现了 synchronized 的,这也是Vector和ArrayList的唯一的区别。
3、LinkedList
优点: 底层数据结构是链表LinkedList,增删快。查询慢。
缺点: 线程不安全,效率高*链表的每一个节点(Node)都包含两方面的内容:1.节点本身的数据(data);2.下一个节点的信息(nextNode)。所以当对LinkedList做添加,删除动作的时候就不用像基于Array的List一样,必须进行大量的数据移动。只要更改nextNode的相关信息就可以实现了。这就是LinkedList的优势。
(2)Set 集 —— 值不可重复
1、HashSet
调用add()方法向Set中添加对象,底层数据结构是哈希表,无序。
依赖两个方法来保证元素唯一性:hashCode()和equals()。使用对象的值来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性。2、LinkedHashSet
底层数据结构是双向链表和哈希表,有序。
由链表保证元素有序,由哈希表保证元素唯一。3、TreeSet
底层数据结构是红黑树,内部实现排序,也可以自定义排序规则。
自然排序、比较器排序保证元素排序。根据比较的返回值是否是0来保证元素唯一性。4、ArraySet
底层数据结构是双数组,有序。
Android.util包下的类,实时扩容,节约内存。推荐代替使用HashSet。
ArraySet添加元素的源码:@Override public boolean add(@Nullable E value) { final int hash; int index; if (value == null) {//允许key、value有一个为null hash = 0; index = indexOfNull(); } else { hash = value.hashCode();//算出hash码 index = indexOf(value, hash);//在hash码数组中,二分查找拿到index值 } if (index >= 0) { return false; } index = ~index; if (mSize >= mHashes.length) {//安全判断 final int n = mSize >= (BASE_SIZE * 2) ? (mSize + (mSize >> 1)) : (mSize >= BASE_SIZE ? (BASE_SIZE * 2) : BASE_SIZE); final int[] ohashes = mHashes; final Object[] oarray = mArray; allocArrays(n); if (mHashes.length > 0) { System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length); System.arraycopy(oarray, 0, mArray, 0, oarray.length); } freeArrays(ohashes, oarray, mSize); } if (index < mSize) { System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index); System.arraycopy(mArray, index, mArray, index + 1, mSize - index); } mHashes[index] = hash;//hash码数组 mArray[index] = value;//存放数据 mSize++; return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
碰撞冲突:如果在第二个数组键值对中的key和前面输入的查询key不一致时产生。
开放地址法:以该key为中心点,分别上下展开,逐个去对比查找,直到找到匹配的值。
扩容机制:在创建时是严格按照大小创建,如下:
System.arraycopy(ohashes, 0, mHashes, 0, mSize); System.arraycopy(oarray, 0, mArray, 0, mSize);- 1
- 2
在添加、删除操作方法中都会调用如下:
System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index); System.arraycopy(mArray, index, mArray, index + 1, mSize - index);- 1
- 2
小结:
ArraySet通过调用System中提供的一个native静态方法arraycopy(),实现数组之间的复制。采取一种用时间换取内存空间的优化思路,其元素扩容是时刻变化的,也就是说会随时根据内容动态调整数组的大小。因为每次操作都要实现数组复制,会影响到元素操作的效率。理论上来说,在大数据量的情况下,更频繁的数据条数大幅度变化下,效率会变低。但实际上,发现其速度在数万条数据的情况下,相差无几。
二、Map接口
Map接口有三个比较重要的实现类:HashMap、TreeMap、HashTable。
(1)HashMap —— 无序
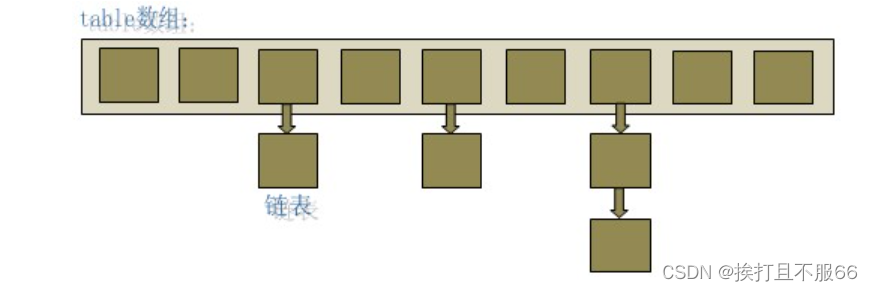
如上图,HashMap是链表散列的数据结构,即数组和链表的结合体。底层是一个数组结构,数组中的每一项元素又是一个链表结构,即Entry
transient Entry[] table; static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
Entry就是数组中的元素,每个 Map.Entry 其实就是一个key-value对,它持有一个指向下一个元素的引用,这就构成了链表。下面看一下put方法,如下:
public V put(K key, V value) { // 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。 if (key == null) return putForNullKey(value); // 根据key的keyCode重新计算hash值。 int hash = hash(key.hashCode()); // 搜索指定hash值在对应table中的索引。 int i = indexFor(hash, table.length); // 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { // 如果发现已有该键值,则存储新的值,并返回原始值 V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 如果i索引处的Entry为null,表明此处还没有Entry。 modCount++; // 将key、value添加到i索引处。 addEntry(hash, key, value, i); return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
小结:
- 如果key相同,则覆盖原始值;如果key出现冲突,则将当前的key-value放入链表。在链表中做进一步的对比value。
- 没有 synchronized关键字,即非线程安全,因此效率较高;
- 允许存放null键和null值
工作原理:
通过put()方法传递键(key)和值(value)时,我们先对键调用hashCode()方法,计算并返回的hashCode是用于找到Map数组的位置来储存Entry对象。hashCode()方法中是根据key的hash值来求得对应数组中的位置。因为HashMap的数据结构是数组和链表的结合,如果元素位置尽量的分布均匀些,使得每个位置上的元素数量只有一个,当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。所以,我们首先想到的就是把hashcode对数组长度取模运算。
1、取模法
假如数组的长度等于5,这时有一个数据6,我们如何把这个6储存到长度只有5的数组中呢?取余法计算6%5等于1,即把6这个数据放到数组下标为1的位置。如果再有一个数据需要存储,取余法计算后也等于1,就调用equals()判断值是否相同,相同的话就不存储。但是,问题来了,值不相同就会造成Hash碰撞冲突了。
2、Hash碰撞冲突
HashCode()的作用就是保证对象返回唯一hash值对应Map数组中的bucket存储位置,但当两个数据计算后的值一样时,这就发生了碰撞冲突。例如,前面有6%5=1
得到数组下标为1的位置。此时,有个数据是11,那么11%5=1,但是这个为1的位置已经有了6这个数据了,这就叫Hash冲突。3、解决Hash冲突
(1)开放定址法
开放地址法有个非常关键的特征,就是所有输入的元素全部存放在哈希表里。它的实现是,发生哈希冲突,就以当前地址为基准,某种探查技术在散列表中形成一个探查(测)序列,去寻找下一个地址,若发生冲突再去寻找,直至找到一个为空的地址为止。假如关键字key的哈希地址(hashCode)的值
p = H(key),此时出现冲突,就以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi,将相应元素存入其中。所以这种方法又称为再散列法。开放定址法分为:线性探查法、二次探查法、伪随机探测法
- 线性探查:顺序查看表中下一单元,直到找出一个空单元或查遍全表;
- 二次探查:在表的左右进行跳跃式探测,比较灵活;
- 伪随机探测:建立一个伪随机数序列,如i=(i+p) % m,并给定一个随机数做起点,每次去加上这个伪随机数就可以了。
(2)拉链法
HashMap、HashSet其实都是采用的拉链法来解决哈希冲突的。主要是采用链表的形式去处理发生哈希冲突的关键字key。(jdk1.8之后采用链表+红黑树)
实现思想:将所有哈希地址为 i
的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。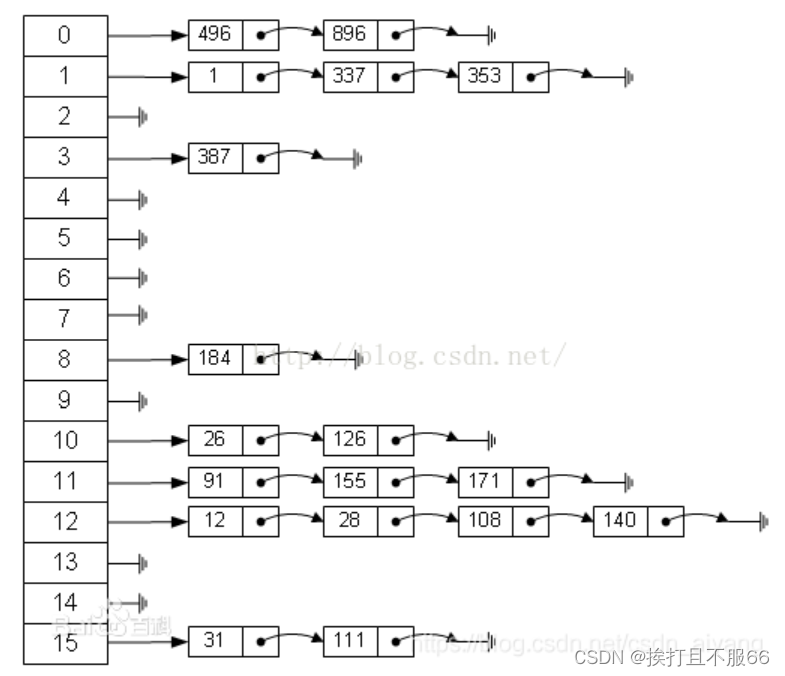
①插入操作:在输入域的关键字发生哈希冲突的时候,我们先检查带插入元素是否出现在表中。这个查找所用的次数最坏时间复杂度为O(1)。②删除操作:在删除一个元素的时候,需要更改该元素的前驱元素的next指针的属性,把该元素从链表中删除。这个操作的时间复杂度也是O(1)的。
(3)小结
拉链法与开放定址法相比
①拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
②由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
③开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
拉链法需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
(2)HashTable —— 无序
散列表,也叫哈希表,存储的内容是键值对(key-value)映射;
Hashtable源码所有 public 方法声明中都有 synchronized关键字,线程安全,效率低;
不允许null值;(因为equlas()方法需要对象)
父类是Dictionary。(3)TreeMap —— 有序
父类是SortMap接口。能够把它保存的键值对根据key排序,基于红黑树,从而保证TreeMap中所有键值对处于有序状态。
*红黑色的见解
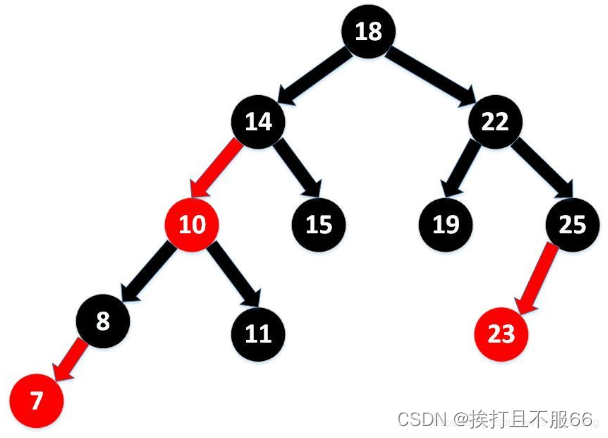
- 每个节点非红即黑
- 根节点总是黑色的
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定)
- 每个叶子节点都是黑色的空节点(NIL节点)
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
(4)ArrayMap——有序
1、概述
Hashmap和HashSet都是Java util包下的类,而ArrayMap与ArraySet都是 android.util包下的类,是google 在Android平台上作出优化后的类,在Android 源码中大量地使用了arraymap进行内存中的数据储存和管理,比如Intent.putExtra、Bundle。二者读写速度差不多,但是ArrayMap比hashmap减少30%的内存消耗。对于经常内存空间紧张,可以缓解OOM。
2、实现原理
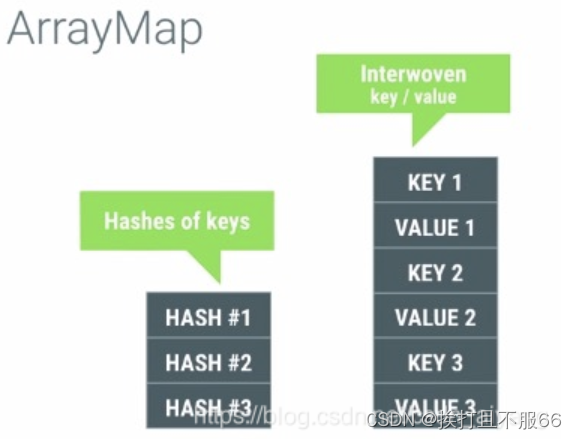
当调用 get(key) 方法 获取某个 value 时,通过计算key得到转换过后的hash值,再对(左)hash数组使用二分查找法寻找到对应的下标索引值 index,然后就可以通过这个 index 在key-value数组(右)中直接访问到需要的键值对。
源码和原理基本与ArraySet的相同。此处就不在复制黏贴了。
三、List、Set、Map的值能否为null?
(1)List —— 允许为null
1、可以看到ArrayList可以存储多个null,ArrayList底层是数组,添加null并未对他的数据结构造成影响。
public void testArrayList(){ ArrayList<String> list = new ArrayList<>(); list.add(null); list.add(null); Assert.assertEquals(2,list.size()); // success }- 1
- 2
- 3
- 4
- 5
- 6
2、LinkedList底层为双向链表,node.value = null 也没有问题。
public void testLinkedList(){ LinkedList<String> list = new LinkedList<>(); list.add(null); list.add(null); Assert.assertEquals(2,list.size()); // success }- 1
- 2
- 3
- 4
- 5
- 6
3、Vector 底层是数组,所以不会管你元素的内容是什么,可以存储多个null。
public void VectorTest(){ Vector box = new Vector(); box.add(null); box.add(null); Assert.assertEquals(2,box.size()); //success } //Vector的add函数源码 public synchronized boolean add(E e) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = e; return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(2)Set
1、HashSet底层是HashMap,可以有1个为null的元素。
public void testHashSet(){ HashSet<String> set = new HashSet<>(); set.add(null); Assert.assertEquals(1,set.size()); //OK size = 1 set.add(null); Assert.assertEquals(2,set.size()); //Error size = 1 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、LinkHashSet底层也是hashmap,允许存在一个为null的元素。
3、TreeSet不能有key为null的元素,会报NullPointerException
(3)Map
1、HashMap中只能有一个key为null的节点。因为Map的key相同时,后面的节点会替换之前相同key的节点。
public void testHashMap(){ HashMap<String,String> map = new HashMap<>(); map.put(null,null); Assert.assertEquals(1,map.size()); //OK size = 1 map.put(null,null); Assert.assertEquals(2,map.size()); //Error size = 1 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、TreeMap的put方法会调用compareTo方法,对象为null时,会报空指针错。
public void testTreeMap(){ TreeMap<String,String> map = new TreeMap<>(); map.put(null,null); Assert.assertEquals(1,map.size()); //Error NullPointException }- 1
- 2
- 3
- 4
- 5
- 6
3、HashTable底层为散列表,无论是key为null,还是value为null,都会报错
public void HashTableTest(){ Hashtable table = new Hashtable(); table.put(new Object(),null); //Exception table.put(null,new Object()); //Exception table.put(null,null); //Exception Assert.assertEquals(1,table.size()); } //hashTable put函数源码 public synchronized V put(K key, V value) { if (value == null) { //value 需要判空,所以value不可为null throw new NullPointerException(); } Entry<?,?> tab[] = table; int hash = key.hashCode(); //key需要拥有实例去调用hashCode方法,所以也不能为空 int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index); return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
-
相关阅读:
Linux 之 Ubuntu 上 Vim 的安装、配置、常用命令的简单整理
not read Username for “https://gitee.com“: Device not configured
关于腾讯股票api股票接口的功能分析
找准边界,吃定安全 | 串联边界设备协同,便捷运营思维让安全更有效
索引常见面试题
酷开科技丨新年新玩法!酷开系统壁纸模式给客厅“换”新
污水废水硝酸盐超标,离子交换树脂工艺分析
10.过拟合、欠拟合与正则化
Kubernetes体系结构及其主要组件
电商前台项目(二):完成Home首页模块业务
- 原文地址:https://blog.csdn.net/lf_78910jqk/article/details/132733749
