-
论文笔记:一分类及其在大数据中的潜在应用综述
0 概述
论文:A literature review on one‑class classification and its potential applications in big data
发表:Journal of Big Data在严重不平衡的数据集中,使用传统的二分类或多分类通常会导致对具有大量实例的类的偏见。在这种情况下,对少数类实例的建模和检测是非常困难的。一分类(OCC)是一种检测与已知类实例相比较的异常数据点的方法,可以用于解决与严重不平衡数据集相关的问题,这在大数据中尤其常见。我们对近十年来出版的与OCC相关的文献作品进行了详细的调查。我们将不同的工作分为三类: 异常值检测、新颖性检测、深度学习和OCC。我们仔细检查和评估有关OCC的选定作品,以便在综述中呈现出方法、手段和应用领域的良好横截面。讨论了OCC中常用的离群值检测技术和新颖性检测技术。我们观察到,在与OCC相关的文献中,有一个领域在很大程度上被忽略了,那就是OCC在大数据中的应用背景及其固有的相关问题,如严重的类失衡、类稀缺、噪声数据、特征选择和数据约简。我们认为这项综述将受到大数据领域研究人员的欢迎。
1 引言
大数据的五个v是体积(volume)、种类(variety)、价值(value)、准确性(veracity)和速度(velocity)。巨大的大数据量带来了独特的挑战,例如,在二分类问题中,与负类的实例数量相比,正类(感兴趣的类)的实例数量微不足道。这就带来了一些问题,如如何处理大数据中非常高的类别不平衡,大数据中积极类别实例的类别稀缺性[1-4],以及对消极类别(兴趣较少的类别)的建模偏差。多样性表明大数据可以有多个来源的数据。价值通常被认为是大数据最重要的方面,这是因为挖掘如此庞大的数据语料库应该产生对最终用户具有实际业务价值的结果。大数据中的准确性通常是指大数据集中数据点的真实性,例如,缺失的数据点如何处理?如何清理数据集?数据点有多准确?速度表示数据输入的速度,以及它可能如何改变大数据量的特征。有限的实时数据是否比低速的大量数据更好?
虽然我们不打算在本文中关注大数据的每个方面,但我们关注的是一分类(OCC)如何帮助归因于大数据的特定问题。其中包括严重的类不平衡、类稀有、为提高数据质量而进行的数据清理、特征选择和数据量减少。为此,清楚地理解数据挖掘和机器学习领域中的单分类领域是很重要的。在本文中,我们重点探讨了在一分类中所做的各种工作。此外,我们还评论了在OCC与大数据方面是否已经做了足够的工作,为研究人员提供了解决上述大数据问题的技术。我们认为,当前对OCC方法的调查将为解决大数据遇到的一些具体问题提供深入的见解。
在具有正类和负类实例的二分类问题中,传统的机器学习算法旨在区分这两个类,并建立一个预测模型,该模型可以准确地对这两个类的未标记(以前未见过)实例进行分类。然而,在类不平衡的情况下,与正类(感兴趣的类)中的实例数量相比,负类中的实例数量不成比例地高。在这种情况下,典型的分类器将倾向于具有较多实例的类,即负类。当类失衡严重时,使用传统的二分类器对正类进行准确分类是非常具有挑战性的,有时甚至是不切实际的。例如,在银行非法交易的调查中,积极事例(非法交易)的数量远远少于消极事例(合法交易)的数量,因此存在严重的类不平衡。在这种情况下,如果积极实例上的数据可用,而消极实例上的数据要么不可用,要么未标记,那么如何执行基于分类的预测建模?为了解决这样的问题,可以使用基于单分类(OCC)概念的方法。
单分类是多类或二分类的一种特定类型,其中通过检查和分析一个类(通常是感兴趣的类)的实例来解决分类问题。在OCC问题场景中,正类的标记实例要么不可用,要么数量不足,无法训练传统的机器学习者。重新审视对合法/非法银行交易进行分类的问题,OCC可以用来将以前看不见的交易分类为合法或非法。我们将在下一节中进一步讨论OCC。在本研究中,我们对过去10-11年(即2010-2021年)的文献中关于OCC的方法、方法和算法进行了综述。综述的目的是提供不同的方法和途径的OCC和它的应用综述在过去10-11年的一个很好的横截面,并不意味着是一个详尽的综述所有相关工作。
在我们的调查工作中,观察到异常值检测和新颖性检测是一分类的主要应用领域。此外,我们还在单分类的背景下基于深度学习的使用对综述作品进行了分类。离群点检测和新颖性检测在概念和应用上有细微的差别。在新颖性检测中,在测试数据集中检测异常,而训练数据集中不包含任何异常数据点。在异常点检测中,训练数据集可能包含正常和异常数据点,任务是确定两者之间的边界。边界随后应用于测试数据集,测试数据集也可能包含正常和异常数据点。
本文的其余部分结构如下。“一分类”一节提供了OCC及其主要类型的进一步详细信息。“调研成果总结”部分从离群值检测、新颖性检测、深度学习在OCC中的应用等方面对OCC的调研成果进行了详细的总结。本节还讨论了以前关于OCC的调查论文,以及本文与那些论文的不同之处。“讨论”部分提供了对调查工程和整体OCC问题的讨论。结语部分对本文进行总结,并对今后的工作提出建议。
2 一分类
在一些真实世界的数据集中,标记的例子只能用于一个类。由于未标记样本的数量可能很大,这增加了标准分类方法的学习时间,这主要是由于数据集的规模很大。此时,解决分类问题的解决方案之一是采用一类分类,将看不见的交易分类为合法(正常)或非法(异常)。由于单类分类仅由一个类的实例执行,因此需要更复杂的解决方案才能获得准确的结果。单类分类(OCC)是一种特定类型的多分类或二元分类任务,仅由一个类的实例完成。其他类样本要么不可用,要么数量不够,无法训练更传统的(非OCC)分类器。在某些情况下,采集的样本数量不能令人满意。
为了阐明OCC的概念,我们考虑一些例子。考虑一些具体的问题,比如向客户发放信用卡。在此示例中,提供信用卡的组织需要评估新客户的申请或现有客户的行为,以接受或拒绝它们。由于大多数客户偿还贷款,很少有人违约,我们没有一个可接受的违约比例,数据集非常不平衡。又如,在涡轮机或海上平台的健康监测中,设备状态的正常数据非常丰富。然而,异常状态很少发生,专家们对检测这些罕见情况很感兴趣。可以引用其他类似的例子来解释OCC的使用和重要性。
假设训练集的样本充足的类作为目标类,而异常类实例非常稀疏或不可用。异常类的不可用性可能导致测量困难,或者收集样本的成本高。在一些单分类算法中,寻找训练集上的决策边界是一个目标。OCC的主要特点是它可以通过单类学习来区分一个类对象和其他对象。这意味着即使没有其他类的示例,OCC也是适用的。此外,由于OCC的目标之一是识别目标类样本的隐藏异常值,因此产生鲁棒决策边界是OCC的基本部分。单类分类器的目标可以通过不同的类型来获得,例如分配一个类标签,考虑一个类周围的区域,或者一个对象属于(和不属于)一个类。使用OCC的流行原因之一是它在检测异常对象或异常值或可疑模式方面的效力。仅使用目标类对象进行训练,使OCC成为离群点检测和新颖性检测的实用选择。
缺乏来自单分类的实例可能会破坏分类过程。只有一个训练有素的类使得其示例之间的决策边界区分变得困难。此外,单个类实例给特征选择带来了问题[5,6],因为与传统的二元或多类问题相比,我们只需要处理一个类。因此,在类之间找到具有适当分离的最佳特征子集是一项繁重的工作。由于没有离群值实例,训练集只包含目标实例,使得数据边界非凸[7]。因此,与更传统或传统的多/二分类问题相比,需要额外的实例数量来训练模型。在典型的单类分类中,决定接受一个数据点为内样点还是离群点是基于两个参数:一个是计算样本到目标类的距离的参数,另一个是用户定义的比较距离和接受或拒绝该对象为内样点的阈值限制[8]。Khan等人[9]基于分类器的模型、被分析的数据类型和特征的时间关系对OCC技术进行了分类。分类器的模型分为基于密度的、基于边界的和基于重构的三种类型。
基于密度的单类分类方法基于估计训练数据密度来执行,该密度与阈值(模型参数)进行比较。这些类型的方法适用于具有大量训练样本的良好采样数据。高斯法、混合高斯法和帕森密度法被归类为基于密度的方法。在基于边界的方法中,建立了一个封闭的边界和内层周围的边界,这使得边界的优化成为建模的挑战。任何在边界外的样本都被认为是一个离群值。一类支持向量机(OCSVM)是基于支持向量机(svm)的一种基于核的方法。OCSVM是通过开发一个超平面来构建的,该超平面使离原点距离最大化,并将离群点与内线点分离[10]。另一种基于核的一类分类方法是支持向量数据描述(SVDD),它构建一个半径最小的超球,该超球由目标样本组成,任何在超球之外的样本都被视为离群值[11]。与基于密度的方法相比,基于边界的方法需要更少的数据样本来获得相似的性能。在基于重构的方法中,在生成模型时需要特定领域的历史数据(先验知识)作为假设。异常样本通常不符合模型中嵌入的历史数据假设,因此,任何具有高重构误差的样本都被认为是异常样本。在该方法中,输入模式被表示为输出,重构误差被最小化。基于 k k k均值聚类的一类分类器[12],基于主成分分析(PCA)的一类分类器[13],基于学习向量量化(LVQ)的一类分类器[14],以及Auto-Encoder[15]或多层感知器(multilayer Perceptron (MLP)[16]方法都是基于重构的模型。
基于集成的单类分类器是多个单类分类器的组合,以共同受益于每个分类器。Desir 等人[17] 提出了单类随机森林 (OCRF),它增强了一些弱分类器,并集成了人工离群点生成过程,将单分类变为二元学习器。基于一类聚类的集成(OCClustE)从特征空间构建聚类[18]。这种方法大大减少了处理时间。一类线性规划(One-Class Linear Programming, OCLP)是一种检测不相似表示的有效方法[19]。OCLP方法的优点是减少了测试对象的数量。基于图的OCSVM半监督一类分类方法用于检测正常样本较少的异常肺音[20]。作者建立了一个谱图来显示样本之间的关系。[21]对基于极限学习(ELM)的单类分类进行了全面比较,其中包括两种基于边界的方法和基于重建的方法。Krawczyk和Wozniak提出了增量学习和遗忘的加权单类支持向量机[22]。在增量学习中,定期使用数据来增加模型知识,从而改变先前的决策边界。该方法可用于数据流建模和分析。
3 已有工作概述
本节总结了一组关于单分类的精选著作。精选组是在过去十年(2010-2021)的OCC相关作品中获得的。虽然不打算对所有OCC相关作品进行详尽的调查,但我们试图呈现一个很好的横截面(据我们所知)在过去十年中出版的单分类作品。根据概述工作的重点和方法,我们将其分为三类: 异常值检测和OCC、新颖性检测和OCC、深度学习和OCC。
3.1 异常值检测和OCC
Bartkowiak[7]提出了一个在计算机系统调用中检测异常模式(或伪装者)的案例研究。该数据集表示50个用户,每个用户有15000个系统调用序列。系统调用的集合被抽象为两个集合,即50个块(A部分)和100个块(B部分),每个块包含100个调用。在A部分中没有假面者,而在B部分中,一些区块被20个冒充假面者的用户的区块所取代。这里的OCC问题是检测这些伪装块。对一个用户的异常块进行了详细的分析,该用户的异常块大约有20个。在伪装器检测中,使用OCC对数据密度建模来建立决策边界。构造基于经典高斯分布、鲁棒高斯分布和支持向量机。作者表明,在案例研究的背景下,应用OCC方法监测异常事件是可行的。研究还表明,重建方法可能是有用的,因为用户调查了大约一半的植入块(伪装者)需要被检测到。除了案例研究之外,本文还讨论了统计方法和机器学习方法在网络异常检测中的优势。如果实际的外来(未经授权的)用户参与数据集并被检测到,该研究可能会对伪装者检测有更可靠的吸引力。此外,具有大量用户和系统调用的案例研究将有助于改进工作的泛化性。
Leng 等人[23]提出了一种基于极端学习机(ELM)的单类分类器,其中神经网络的隐层不需要调整,输出权重通过分析计算得出,因此学习时间相对较短。他们将自己提出的方法与自动编码器神经网络进行了比较,并采用重构方法建立了单类分类器。离群点检测分析 对七个 UCI 数据集和三个人工生成的数据集进行了离群点检测分析。虽然随机特征映射和内核都可用于所提议的分类器,但后者比前者能产生更好的结果。主要比较研究 基于 ELM 的模型和自动编码器神经网络之间的主要比较研究表明,前者有一个分析解决方案,可以获得更好的泛化性能,而且在网络学习时间相对较短的情况下也是如此。而且网络学习时间相对较短。这项研究的一个缺点是,研究中调查的数据集相对较少。本研究的不足之处在于,研究中调查的数据集规模相对较小,因此在如何将所建议的方法扩展到更大的规模方面还存在研究空白。特别是由于神经网络以学习速度相对较慢而臭名昭著。作者基于 ELM 的 方法如何在大数据中有效发挥作用?
Gautam等人[21]提出了六种OCC方法,分为两类: 三种基于重建的OCC方法和三种基于边界的OCC方法。所提出的OCC方法基于ELM和在线顺序极限学习机(OSELM)。作者讨论了OCC的在线和离线方法。在四种离线方法中,两种方法执行随机特征映射,另外两种方法执行核特征映射。案例研究数据集由两个人工创建的数据集和来自不同领域的八个基准数据集组成,用于评估OCC模型的性能。作者指出,所提出的分类器比十个传统的OCC和两个基于elm的分类器性能更好。在OCC背景下,ELM也被其他研究使用,例如Dai等[24]和Leng等[23]。 虽然作者使用了一些基准数据集,但他们的分析和结论也是基于人工生成的数据集。
Dreiseitl等[25]研究了一类支持向量机在黑色素瘤异常预后检测中的异常值检测。一类分类旨在模拟未获得转移状态的黑色素瘤患者的分布,在这种情况下,这是黑色素瘤患者的正常类别(病例)。案例研究数据来自维也纳医科大学皮肤学系。清洗后的数据集包括270个血清学血液测试,其中包括37名转移性疾病患者和233名无转移性疾病患者。将一类支持向量机方法与常规两类支持向量机和人工神经网络(ANN)算法进行了比较。使用WEKA数据挖掘工具对这些进行了调查[26]。他们的实证工作表明,一类支持向量机是标准分类算法的一个很好的替代方案,在这种情况下,只有少数病例来自感兴趣的类别,即在这种情况下,转移性疾病的患者。当一类支持向量机模型在少数类中使用的案例数少于一半时,一类支持向量机模型的性能优于两类支持向量机模型。本研究的一个潜在问题是案例研究的数据集规模非常小,以及他们的方法是否可扩展到更大的数据集,如大数据。
Mouro- miranda等[27]提出了一种用一类支持向量机(OCSVM)对患者脑活动进行分类的方法。该方法分析了功能性磁共振成像(fMRI)对抑郁症患者悲伤面部表情的反馈。他们检查了这些患者的功能磁共振成像,将他们与健康(非抑郁)患者进行比较,并得出结论,抑郁患者的功能磁共振成像反应被归类为异常值。数据集包括19名抑郁症患者和19名非抑郁症患者。OCSVM分类显示,健康患者边界与抑郁症汉密尔顿评定量表之间存在很强的相互联系。此外,OCSVM在患者中发现了两个亚类。这些子类别是根据患者对治疗的反应进行分类的。为了将个体划分为抑郁和健康,该算法使用了两种类型的大脑数据,如全脑和大脑区域的体素(体素大小是图像的空间3D分辨率),它提取了大约500个全脑特征和348个区域特征。考虑脑区域图像并使用OCSVM对患者进行治疗,使本研究成为OCC在医疗保健中应用的一个值得注意的工作。案例研究的数据集非常小,很难得出广泛的泛化结论,特别是在大数据的背景下。
Bartkowiak和Zimroz[28]研究了行星齿轮箱(安装在斗轮挖掘机上)的振动信号并检测到离群数据。他们从分割的振动信号频谱中收集了两个数据集,分别作为“好”数据集和“坏”数据集。在齿轮箱处于不良状态时,产生的谐波信号较多,信噪比较高,而在齿轮箱处于良好状态时,谐波和信噪比相对较低。好的数据集的样本数为951,有15个属性。他们应用神经尺度技术(一种可视化方法)将属性减少到两个特征,因此,数据可以绘制在x-y平面上。为了估计数据的分布,作者使用了三种方法,包括Parzen窗口,支持向量数据描述(SVDD)和混合高斯。由于这些方法都是边界方法,所以对好的数据建立一类决策边界,用坏的数据对模型进行检验。结果表明,在测试数据集上,模型识别出98%是坏的,即异常值。这项工作是在机械系统中发现异常值作为故障的一个很好的例子,因为这些信息在系统诊断中是有用的。
Desir等人[29]提出了一项实证研究,研究了他们之前提出的一类随机森林(OCRF)[17]的行为,该方法基于随机森林学习器和一种新的离群值生成过程。后者既减少了要创建的人工异常值的数量,也减少了生成异常值的特征空间的大小。在[29]中,作者在几个UCI数据集的背景下,对OCRF与一些参考的一类分类算法(即高斯密度模型、Parzen估计器、高斯混合模型和一类支持向量机)进行了比较案例研究。他们的工作表明,带有离群值生成的ocf方法的性能与上述参考算法相似或更好。此外,他们提出的解决方案在高维特征空间中表现出稳定的性能,而其他一些OCC算法可能表现不佳。虽然没有在[29]中进行探讨,但我们认为他们的方法可以潜在地用于大数据,其中大量特征通常是一个有问题的问题。
Krawczyk等[18]提出了一种基于加权单类支持向量机(OCSVM)的多分类器系统,并对目标类中的数据点进行聚类。多分类器系统构建一个分类器的集合,在这种情况下,它是基于从目标类的实例池派生的集群构建的分类器。作者提出了“一个弹性和高效的框架来完成这项任务,它只需要选择几个组件,即聚类算法、个体分类器模型和融合方法[18]。” 基于多个基准数据集(包括来自UCI库的19个数据集)的实证案例研究表明,该方法优于几种OCC方法,包括单类和多类问题的OCSVM。作者没有与SVDD进行比较,SVDD是一种有效的OCC方法,基于我们对调查中探索的各种研究的观察。此外,所有的案例研究数据集的规模都相对较小,这就把模型的可扩展性问题摆在了前面。
Lang等人[20]提出了一种使用基于图的半监督OCSVM的新方法。应用领域是异常肺音的检测,在远程医疗中肺部疾病的诊断和患者监护中具有重要意义。该方法利用少量标记的正常实例和大量未标记的实例来描述正常的肺音并检测异常的肺音。构建了一个谱图来表示所有样本之间的关系,这丰富了只有少数标记的正态样本所提供的信息。然后,建立了基于图的半监督OCSVM模型,并给出了求解方法。利用谱图中的信息,提高了识别和泛化的效果,这是有效检测异常肺音的关键。”[20]。该方法的性能随着未标记异常实例数量的增加而提高。
Krawczyk和Woźniak[22]解决了处理数据流的问题,特别是在存在概念漂移的情况下。讨论了OCC在数据流分析中是一个很有前途的研究方向,可用于单类实例的二值分类、离群值检测和新颖性检测。提出了一种新的加权OCSVM,该算法可以处理逐渐的概念漂移。所提出的OCC可以使其决策边界适应新的传入数据,因为它还采用了一种遗忘方案,提高了分类器跟踪模型变化的能力。此外,本文还提出了不同的增量学习和遗忘策略,并在几个案例研究的背景下进行了评估。主要结论是所提出的OCC对于存在概念漂移的数据流分类问题具有有效的可用性。在大数据概念漂移的背景下,观察所提出的解决方案的有效性将是一件有趣的事情。与其他流行的OCC方法的比较将为所提出的方法提供更强的验证。
Das等人[30]在智能家居中应用传感器网络监测痴呆症患者活动的背景下研究了OCC。监测这些事件总是与检测错误相关联,在[30]的背景下,这意味着(痴呆症患者)没有正确完成一项活动。活动完成和错误问题被表述为异常值检测的一类分类。个案研究的基础是监测诸如吸尘、除尘、浇花、接电话等常见家庭活动的完成情况或缺乏情况。完全完成一项活动的问题被认为是一个异常值。不同类型的运动检测和压力检测振动传感器用于数据收集。提出的分类模型,检测实时活动错误(DERT),是由580个数据点组成的无错误数据(即一个类)训练的。基于OCSVM的DERT表现优于简单的基线离群值检测方法。所提议的方法的验证需要通过与其他OCC技术(包括SVDD)的比较研究来支持。
Deng等人[31]重点研究了物联网传感器数据中的异常值检测问题。他们开发了一类支持塔克机(OCSTuM),这是一种涉及塔克分解技术的无监督异常值检测方法。塔克分解通过产生一个核心张量和因子矩阵来表示张量。案例研究数据存在高维问题,需要将特征子集选择作为解决方案的一部分。作者提出了一种应用遗传算法改进OCSTuM的特征选择和离群点检测的方法(称为GA-OCSTuM)。他们的工作涉及多个数据集,包括Montes传感器数据集、TAO项目传感器数据集、日常和体育活动数据集(DSAD)、开放采样设置中的气体传感器阵列数据集(GSAOSD)和南佛罗里达大学步态数据集(USFGD)。OCC训练数据集是干净的,没有任何异常值,但测试数据混合了5%的异常值样本。将所提算法与基线方法(如OCSVM)进行比较。实证结果表明,GA-OCSTuM方法在所有数据集上都优于基线方法(包括SVDD、R-SVDD、OCSVM和OCSTuM)。在OCC离群值检测的背景下,研究中考虑的数据集与其说是一个大数据问题,不如说是一个高维问题。此外,已知遗传算法(GAs)的计算性能较慢,并且该研究并未揭示遗传算法对所提出的GA-OCSTuM解决方案的时间性能的影响。
Gautam等人[32]开发了一种基于深度核的单类分类器(DKRLVOC)模型,通过一对自编码器的帮助来减少对象方差并改善特征学习。该方法在18个数据集和2个真实数据集上进行了测试,其中包括fMRI数据集检测阿尔茨海默氏症和病理图像数据集检测乳腺癌。提出的基于最小方差嵌入深度核的一类分类方法包括三层:基于最小方差嵌入核的自编码器、基于核的自编码器和基于核的OCC。该方法与三种基于核的极限学习机方法OCKELM、VOCKELM[33]和ML-OCKELM进行了比较。关于这些模型的更多细节见[32]。实证结果表明,对于较小的生物医学数据集,所提出的方法在F1得分方面表现最好。对于中等规模的生物医学数据集,本文方法的有效性高于ML-OCKELM和OCKELM,但低于VOCKELM。这组作者在小型和中型生物医学数据集的背景下比较了不同的模型,这让人们对他们推荐的方法如何在更大的数据集(如大数据)上执行产生了一些怀疑。
Kauffmann等人[34]开发了一种方法,一类深度泰勒分解(OCDTD),用于解释一类支持向量机中的异常值。在异常值检测过程之后,提供解释性解释是有益的,这表明这些输入负责产生异常值。这种解释最大限度地发挥了由神经网络创建的结构的优势。在他们的方法中,OCSVM被输入到一个“神经化”的过程中,以揭示异常值解释的结构。随后,将结构馈送到深度泰勒分解中,并将预测反向传播到显示有效生成异常值的输入。在生成离群值时最具影响力的特征表示为热图。为了最大化使用神经网络的优势,应用了分层相关传播技术,其中应用了一组传播规则来向后传播预测[35]。鉴于神经网络环境中使用了反向传播,计算时间性能研究将为实验结果和研究分析提供更好的见解。
Aguilera等人[36]在OCC背景下提出了k- strong - strengths (kSS)算法[37]的两种变体。这两种算法分别被命名为OCC-kSS和Global Strength Classifier (gSC),并使用抑郁症和厌食症基准数据集进行评估。此外,作者在kSS方法的背景下引入了质量,作为确定社交媒体数据中抑郁症和厌食症文本相关性的措施。算法使用四个数据集进行评估,分别为Dep2017、Dep2018、Anx2018和Anx2019,这些数据集来自2017-2109版本的eRisk共享任务。结果表明,gSC算法总体上优于OCC-kSS算法。这项工作缺乏与其他现有OCC方法的比较,特别是本文中讨论的几个方法。
Wang等人[38]使用KDD入侵检测数据集(简称NSL-KDD)的修改版本,提出了一种在网络入侵检测系统(NIDS)背景下进行异常检测的组合方法。该方法结合子空间聚类(SSC)和OCSVM进行NIDS异常检测,并与K-means、DBSCAN和SSC- ea方法进行比较[39]。基于真阳性率、假阳性率和ROC曲线(两个阈值),作者证明了他们的方法比其他三种方法产生更好的性能。据报道,该方法的计算时间高于K-means和DBSCAN。KDD数据集及其变体在网络安全和入侵检测方面有点过时。在该领域有更多的当前数据集供研究人员探索,然而,在他们的研究中没有这样做。
在桥梁自主结构健康监测的背景下,Favarelli和Giorgetti[40]提出了一种机器学习方法,用于从振动数据中自动检测桥梁结构中的异常。他们提出了两种异常检测方法:一类分类器神经网络OCCNN和OCCNN2。案例研究数据基于一座桥梁结构(Z-24)的加速度测量数据数据库[40]。OCCNN采用粗边界估计和细边界估计两步方法检测正常运行条件下特征空间的正常类边界。OCCNN2是基于将OCCNN方法的两步方法与自关联神经网络(ANN)相结合[40]。将这两种方法与现有的一些异常检测方法进行了比较,包括:主成分分析、核主成分分析、高斯混合模型(GMM)和神经网络。与其他方法相比,OCCNN方法具有更好的准确性和F1分数;然而,OCCNN2方法在响应性、准确性和F1分数方面表现最佳。
Mahfouz等[41]提出了一种基于OCSVM的网络入侵检测模型,该模型在正常网络流量样本上进行训练,形成n维特征空间中正常数据具有高概率密度的区域。随后,不出现在或代表这些(正常)区域内的数据样本被标记为异常(即入侵)。虽然他们对网络指令异常检测的定义并不新颖,但本文的主要贡献在于创建并用于案例研究的网络入侵数据集。作者实现了现代蜂蜜网络(MHN),一个集中式服务器来管理和收集来自蜜罐的数据[41]。他们使用Excel创建了一个数据集工具,将来自不同蜜罐的独立网络监视器的数据聚合到一个数据集中。训练和测试数据分割为70:30,所提出模型的准确率略低于98%。作者没有将他们的方法与现有的几种网络入侵异常检测方法进行比较。
在初步研究中,Zaidi和Lee[42]讨论了软件开发中现有的bug分类方法无法为bug报告分配新添加的开发人员。
“Bug分类是一个软件工程问题,其中一个开发人员被分配到一个Bug报告中。“[42]。作者引用了现有的方法,这些方法使用社交网络分析、主题建模、挖掘存储库、机器学习和深度学习来完成开发人员分配给bug报告的任务。但是,这些方法不能将新添加的开发人员分配给bug报告。他们的实证研究使用了Eclipse[43]和Mozilla[44]软件项目中的Bug报告数据。利用正样本建立OCSVM模型,实现对负样本的检测。作者声明他们的经验结果是可以接受的,并且对于分配新添加的开发人员到bug报告的挑战性问题进行额外的研究是有保证的。
表1总结了OCC和离群值检测综述工作的关键信息。
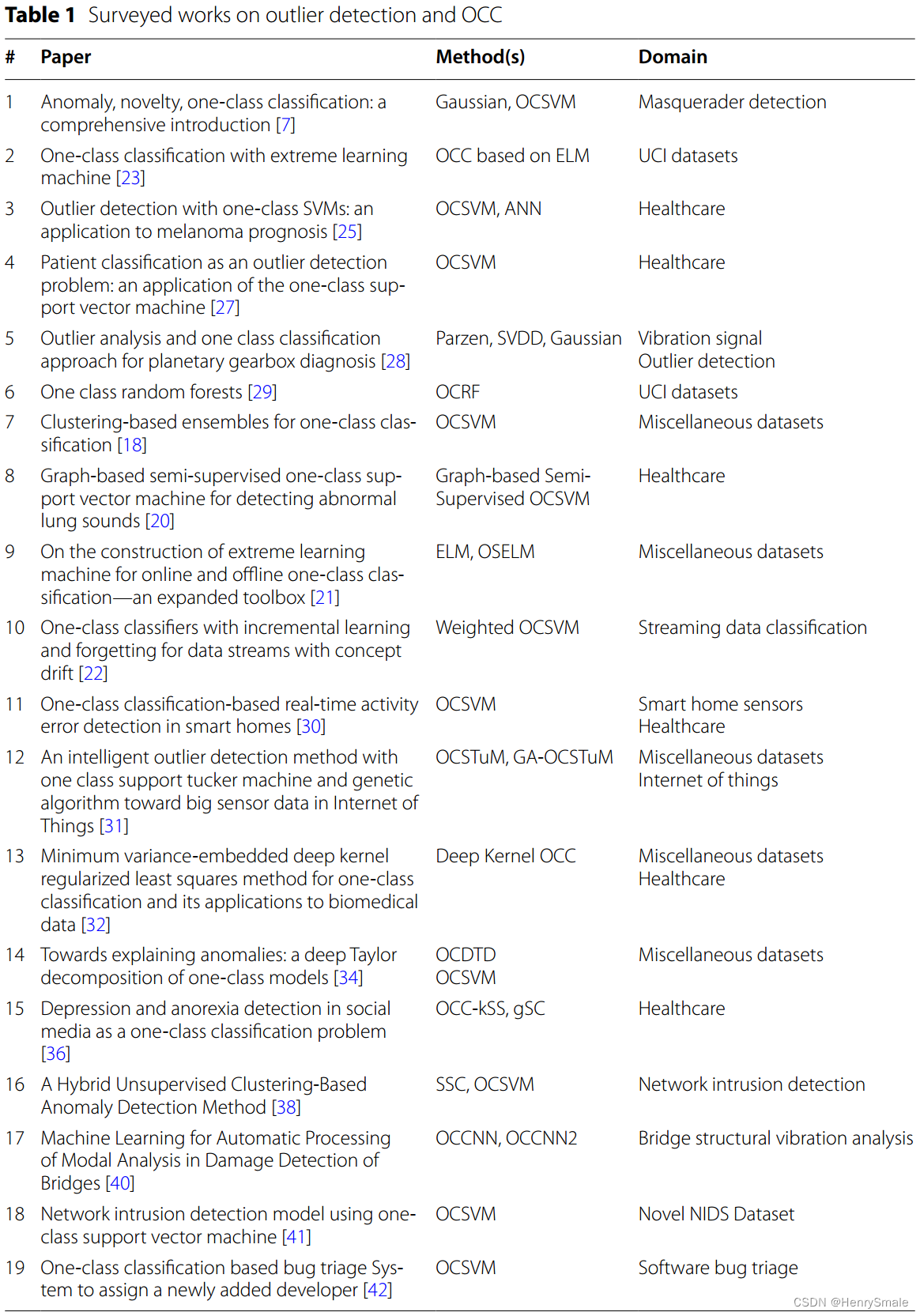
3.2 新颖性检测和OCC
如前所述,异常值检测和新颖性检测在概念和应用上有着微妙的区别。在新颖性检测中,在测试数据集中检测异常,而训练数据集中不包含任何异常数据点。在离群点检测中,训练数据集可能同时包含正常和异常数据点,任务是确定两者之间的边界,然后将该边界应用于同样可能包含正常和异常数据点的测试数据集。
Clifton等[45]利用改进的OCSVM方法在基于生命体征健康数据(如呼吸频率、血氧饱和度、心率等)识别患者恶化的背景下进行新颖性检测。新颖性检测模型通过正常数据进行训练,然后对测试数据进行检测,将测试数据分类为正常或异常。训练数据是通过监测19名患者收集的,产生了1500个实例的数据集。用该方法对高斯混合模型(GMM)和OCSVM两种模型进行了测试,结果表明OCSVM优于GMM模型。案例研究数据是从降压单元(SDU)收集的,它的急性程度低于重症监护病房的数据。数据集的规模很小,这对所得结果和结论的泛化产生了一些怀疑。
Kemmler等[46]提出了一种基于高斯过程回归和近似高斯分类的单类分类新颖性检测框架。将该方法与SVDD的新颖性检测方法和Parzen密度估计方法进行了比较。实验使用来自多个领域的数据集,并使用不同的图像核函数。案例研究结果表明,该方法的性能与其他两种方法相似,甚至优于其他两种方法。他们的方法的应用,特别是基于高斯过程回归的OCC分数,将是理解大数据中的类稀缺性问题的一个有趣的研究。
Beghi等[47]研究了一种用于HVAC系统新颖性检测的OCSVM方法。预先监测可能出现的故障有助于节省成本和能源。在如此的系统中,异常的数据很少,而且通常是不可用的。研究了冷凝器结垢、制冷机泄漏、蒸发器水流量减少和冷凝器水流量减少四种故障类型。调查的案例研究数据来自美国采暖、制冷和空调工程师协会(ASHRAE)。作者将主成分分析(PCA)与OCSVM模型相结合,观察到与单独使用OCSVM相比,主成分分析与OCSVM相结合的AUC性能有所提高。作者没有与文献中的其他新颖性检测方法进行比较,这限制了其工作在更广泛意义上的推广和应用有效性。
Domingues等[48]提出了一种基于深度高斯过程(Deep Gaussian Processes, DGP)的自动编码器配置的无监督新异检测建模方法。所提出的DGP自编码器通过使用随机特征展开来逼近DGP层,并通过对随后的近似模型进行随机变分推理来训练。DGP自编码器可以对复杂的数据分布进行建模,并有助于提出一种新颖性检测的评分方法。在7个UCI数据集和4个来自国际航空服务提供商的数据集的背景下,将所提出的模型与隔离森林和鲁棒密度估计方法进行了比较。实证结果表明,该模型优于其他两种方法。虽然作者在多个数据集上进行了实验,但其中大多数数据集的规模相对较小,因此无法深入了解他们的方法在大数据上的性能。
Sadooghi和Khadem[49]在OCSVM中引入了预处理步骤以提高其性能。他们的工作背景是旋转系统轴承振动信号的新颖性检测。预处理包括一种新的去噪方案、特征提取、向量化、归一化和降维,每一项都使用详细的系统方法实现。案例研究来自case Western Reserve大学轴承数据中心、Tarbiat Modares大学试验台数据和PRONOSTIA平台数据。要了解这些数据资源的更多细节,请参考[49]。本文提出的系统方法表明,非线性特征本身可以有效地提高新颖性检测的性能,包括显著提高OCSVM的分类率(在某些情况下可达到95%至100%)。所提出的OCSVM修正方案似乎与案例研究的领域紧密耦合,并且没有确定这些方案在其他领域的应用,这限制了它们在其他领域的应用。
Yin等人[50]研究并提出了一种基于主动学习的方法来改进新颖性检测背景下的SVDD。SVDD是目前应用最广泛的新颖性检测方法之一,对其进行改进是本文的一个很好的研究方向。然而,当数据量太大或数据质量差时,SVDD可能会表现不佳。用少量的标记样本描述数据分布在机器学习中有它的好处,例如,可以保证有限的数据是无噪声和高质量的。提出的基于主动学习的SVDD方法可以减少标记数据的数量,推广数据的分布,并利用局部密度来指导选择过程,减少噪声的影响。案例研究数据包括三个UCI数据集(电离层、Splice和图像分割)和田纳西东部过程基准数据。 实证结果表明,基于主动学习的SVDD在UCI数据集上具有明显的优势。主动学习是基于用专家(“专家”)标记的数据取代未标记的数据,但几乎没有提供关于基于专家的数据标记过程的信息。此外,虽然本文的目标是将主动学习与SVDD结合起来以提高其在大型数据集上的性能,但没有进行关于改变数据集大小和调查基于SVDD的主动学习性能的研究。
Mohammadian等[51]研究了一种基于OCSVM的新颖检测方法,用于检测帕金森和自闭症患者的异常活动。在帕金森和自闭症谱系障碍(ASD)疾病中,使用可穿戴和惯性测量单元(IMU)传感器进行患者监测已经引起了相当大的关注。早期发现病人不寻常的身体活动对他们的护理和治疗至关重要。本文采用深度规范建模的方法,弥补了OCSVM在大数据和噪声数据中表现不佳的不足。由于标记数据的限制,生成正常模型来展示患者的正常运动,正常运动模型的大(实质性)变化被认为是异常。在步态冻结(FOG)和典型运动(SMMs)数据集上对该方法进行了测试,结果表明该模型在相对较大的数据中是新颖性检测的替代选择,并且具有实时非典型运动检测的潜力。作者指出,他们的方法仅限于基于距离的新颖性检测方法,因此不适用于基于密度的新颖性检测方法。
Sabokrou等人[52]提出了一种生成式对抗网络(GAN)[53],用于不同图像和视频数据集背景下的新颖性检测。作者提出了OCC问题的端到端深度网络。该体系结构由R和d两个模块组成。R模块对输入进行细化,并在学习过程中逐渐注入判别规则,以创建积极和新奇的实例(内线和离群值),而第二个模块(检测器)将积极和新奇的实例分离开来。他们的方法用两个图像数据集进行了研究,包括MNIST和Caltech-256数据集。此外,他们还研究了一个视频数据集UCSDPed2。对于图像数据集,与局部离群因子(LOF)和区分重建自动编码器(DRAE)方法相比,该方法显示出更高的f1分数。对于视频数据集,视频数据中的行人被认为是正类,其他任何东西都被认为是异常。该异常检测方法与一些新颖性检测方法具有可比性。在Sabokrou等人[54]的相关工作中,提出了一种对抗训练模型来检测端到端深度学习模型中的异常值。他们在图像和视频数据集上测试了他们的方法,并得出结论,所提出的模型可以有效地学习检测异常值。他们的方法在图像/视频数据以外的领域,特别是大数据领域的效果还有待观察。
Oosterlink等人[55]提出了一项新颖性检测的研究,将单类分类与基于专家的两类分类进行了比较。作者研究了一种检测电信公司订阅新的移动家庭计划服务中的欺诈行为的方法。由于欺诈,组织和公司的经济损失可能相当大,对这些交易的检测很有吸引力。一个有效的欺诈检测系统是每个服务提供商公司的关键前提。为了解决这一问题,人类行为跟踪在检测人类活动异常和欺诈检测方面是实用的。作者探讨了将专家制备的合成阴性样品与阳性样品相结合的有效性。这项工作证实,使用专家知识来构建负样本并将一类分类转换为二元分类可以提高分类器的性能。两类专家生成样本方法优于人工生成和传统的一类分类方法。在建模过程中引入专家进行决策可能会导致人为错误,本文未对其对模型性能的影响进行研究。
Xing和Liu[56]提出了一种结合OCSVM的改进AdaBoost算法来提高单类分类的性能。AdaBoost[57]与支持向量机的结合总体上提高了二值和多类分类问题的性能;然而,AdaBoost结合OCSVM并没有提高OCC的性能。提出了一种基于鲁棒AdaBoost的OCSVM集成方法,该方法利用牛顿-拉夫森技术改变AdaBoost的权重。案例研究数据包括两个合成数据集,正弦离群值和平方离群值,以及来自UCI存储库的20个数据集。该方法优于多种单类分类方法,包括AdaBoost OCSVM集成、基于随机子空间方法的OCSVM集成、基于聚类的OCSVM集成和高斯核OCSVM。该方法的平均性能优于大多数其他方法。由于所探索的所有数据集都相对较小,因此所提出的方法的可扩展性需要进一步研究。
Perera等人[58]提出了一种用于新颖性检测的单类GAN (OCGAN)模型,其解决方案基于使用去噪自编码器网络学习类内样本的潜在表示。作者认为,新颖性检测涉及两种类型的表征建模,包括确保类内样本得到很好的表征和确保类外样本得到很差的表征。他们指出,在新颖性检测方面,先前的现有工作尚未解决后者,而这正是他们的主要贡献所在。他们提出的模型考虑了两种类型的表示需求的建模。案例研究数据由四个公开的多类目标识别数据集组成,包括MNIST、FMNIST、COIL100和CIFAR10[58]。对于本文所考虑的四种数据集,该模型的新颖性优于现有的一类新颖性检测方法。不同技术之间的比较工作缺乏对模型性能的统计验证和验证。此外,作者没有讨论所提出的方法对非图像数据集的适用性。
在图像新颖性检测方面,Zhang等[59]提出了“基于置信度估计的对抗学习一类新颖性检测”模型。作者认为,大多数现有的新颖性检测方法,特别是那些使用深度学习技术的方法,都不是端到端的,并且往往对新颖性检测预测过于自信。该模型包括两个模块:表示模块和检测模块,这两个模块通过对抗性建模来协同训练和学习数据语料库的早期分布。此外,该模型使用基于置信度的估计来确保其预测的更高效率。该模型使用四个公开可用的图像数据集进行检验,即:MNIST, FMINST, COIL100,和CIFAR10,并与现有的几种新颖性检测方法进行比较[59]。作者的结论是,他们提出的模型优于几种现有的一类新颖性检测方法。此外,一项消融研究表明,所提出模型的每个模块在其功能上都是至关重要的。与之前的研究类似,本研究中不同技术之间的比较工作缺乏对模型性能的统计验证和验证。
表2总结了OCC和新颖性检测方面调查工作的关键信息。

3.3 深度学习和OCC
Kim等人[60]提出了一种新的深度学习模型,该模型涉及受限玻尔兹曼机和一种改进的SVDD,称为深度SVDD (DSVDD)。后者涉及隐藏层,其中每层有 k k k个SVDD节点,用于典型的 k k k类问题。网络的所有层都包含隐藏层,最后一层对测试数据样本进行决策提取。提出的研究背景是通过结合深度学习的表示能力和SVDD的泛化性能来减少过拟合问题。案例研究数据包括三个UCI数据集,包括威斯康星州乳腺癌、气候模型模拟崩溃和皮马印第安人糖尿病数据集。设置0.55的置信度度量来过滤可疑或确信的样本。实证结果表明,DSVDD的性能优于SVM、SVDD和Deep Belief Networks。由于研究中使用的数据集相对较小,因此需要在大数据背景下考察不同方法的性能优劣,即对于非常大且严重不平衡的数据集,DSVDD模型是否表现良好。
Erfani等人[61]在异常检测的背景下解决了高维问题。不相关特征的存在可以隐藏异常样本,使其检测困难。高维数据环境下的异常检测存在指数搜索空间、数据窥探偏差、提取特征不相关等问题。为了解决这些问题,提出的方法将深度学习模型与单类分类器相结合。本文提出了一种无监督的异常检测方法DBN- 1svm,该方法利用DBN提取鲁棒特征和OCSVM进行训练。由于dbn对复杂的高维数据集的学习效率高,并且降低了数据的维数,因此将dbn与OCSVM相结合是有利的,即将dbn的非线性降维结果馈入OCSVM进行学习。作者使用智能手机数据集作为真实数据集,香蕉和微笑数据集作为合成数据集,对森林成人气体传感器阵列漂移、机会活动识别、日常和体育活动以及人类活动识别进行了测试。DBN-1SVM与基于平面的单类SVM (PSVM)、SVDD和选择线性或RBF核的自动编码器(AE)进行了比较。实验结果表明,DBN-1SVM的鲁棒性优于其他方法,具有更好的性能。鉴于所提出的方法获得的良好结果,研究该方法在其他领域以及非常大而复杂的数据集中的功效和效率将是有趣的。
Sun等人[62]提出了一种用于监控视频异常检测的深度单类分类(DOC)学习器。视频监控数据中异常事件的自动检测是智能监控报警系统的一个重要问题。DOC模型是SVM和卷积神经网络(Convolutional Neural Network, CNN)的集成[63],其中SVM除了区分正常和异常对象外,还起到优化器的作用。将提出的模型DOC与其他四种方法进行比较,包括动态纹理混合[64]、稀疏重建成本[65]、外观和运动深度网络[66]以及Adam等人[67]的监控视频异常检测方法。案例研究数据是UCSD行人数据集,Ped1和Ped2。在帧级和像素级对不同的方法进行了比较。像素级实验结果表明,该方法优于其他方法。在帧级,DOC和外观和运动深度网络方法产生相当的性能。将所提出的方法与SVDD和Deep SVDD进行比较会很有趣,因为它们通常非常有效地与OCC一起进行异常检测。
Zhang等[68]通过将一类CNN分类器模型与典型的两类CNN分类器模型进行比较来评估一类CNN分类器模型。该模型将OCC和深度神经网络相结合,并将混合模型应用于图像缺陷检测。两种模型的总体架构相似,除了两类分类器CNN模型在一类分类器的最后一层上有一个额外的两神经元输出层完全连接。一类分类器的损失函数为对比损失函数,二类分类器的损失函数为softmax损失函数。案例研究数据集由数量有限的少量电子元件图像组成。缺陷图像类型多样,包括白色部分不完整、灰色部分不完整、变形、斑点、划痕、凹坑等。手动标记的数据集由1090张图像组成,其中600张无缺陷图像和490张有缺陷图像。将这两种模型应用于电子部件数据集,结果表明,一类分类器优于两类分类器,鲁棒性更强。应将一项私隐赔偿计划与其他私隐赔偿计划方法进行比较,以衡量拟议私隐赔偿计划是否有效和公平;然而,在这项研究中并没有这样做。
Gutoski等人[69]研究了一种基于“深度自动编码器”的图像异常检测分类器,该分类器使用深度嵌入聚类(DEC)方法。不包含异常的图像被认为是正常的,只有正常的数据被用于他们的一类分类研究。使用正常实例的堆叠去噪自动编码器(Stacked Denoising AutoEncoder, SDAE)开始模型训练,并将其输出输入到深度嵌入聚类优化器中,该优化器同时确定聚类中心。案例研究数据由三个数据集组成:(1)STL-10,由96×96像素的彩色图像数据组成,分为10类,每类800张图像,其中500张图像为标记实例;(2) MNIST,由6万张图像作为训练数据和1万张图像作为测试数据组成,每张图像灰度为28×28像素;(3) NOTMINST,这是一个打印字符数据集,由a到J的10类字母组成,包含20万张图像作为训练数据,1万张图像作为测试数据,图像灰度为28×28像素。作者认为,应用SDAE后再应用深度嵌入聚类可以提高单类分类的准确率,即图像分类中异常检测的性能。
Ruff等人[70]在异常检测和一分类的背景下引入了深度支持向量数据描述(Deep SVDD)方法。如前所述,常用的基于OCC的异常检测在高维数据集上的性能会下降,这主要是由于高计算成本和数据复杂性。Deep SVDD模型参数使用Adam[71]和随机梯度下降(SGD)方法进行优化。SGD导致训练数据批次的并行执行,并有助于深度SVDD的可扩展性。作者在这项工作中进行了两个案例研究。第一个涉及到MNIST和CIFAR-10数据集。第二个研究重点是在德国交通标志识别基准(GTSRB)[73]数据集的背景下,对抗性攻击的可能性,如边界攻击[72]。深度SVDD方法与一些OCC方法进行了比较,如SVDD、核密度估计、隔离森林、深度卷积自编码器和基于生成对抗网络(GANs)的异常检测[74]。对于MNIST和GTSRB数据集,Deep SVDD方法产生最佳性能。然而,对于CIFAR-10数据集,核密度估计方法和SVDD方法优于Deep SVDD方法。由于三个数据集的混合结果,在图像数据集以及其他领域数据集的情况下,深度SVDD的效果并不十分清楚。
Chalapathy等人[75]提出了一种基于深度神经网络的异常检测中一分类方法。这是一种基于Ruff等人[70]工作的混合方法;然而,在他们的整体异常检测方法中,作者用OCSVM取代了SVDD。网络的隐藏层执行数据表示,而在后续阶段,OCSVM检测发生的任何异常。案例研究数据包括德国交通标志识别基准数据集[73]、MNIST、CIFAR-10和一个综合生成的数据集。所提出的策略与其他方法不同,这些方法使用混合方法,使用自动编码器学习深度特征,然后将特征馈送到单独的异常检测方法(如OCSVM或OCSVDD)。实例研究结果表明,所提出的方法与最先进的OCC方法相似。与OCSVDD、隔离森林、核密度估计、深度卷积自编码器等方法进行了比较。
Schlachter等[76]在使用深度学习网络进行OCC的背景下研究了Intra-Class Splitting (ICS)。该方法将一个类别(正常类别)的数据分成两个子集,“典型正态”和“非典型正态”。通过将正常类划分为两个子集,该方法使用二进制损失并为基于距离的约束定义辅助子网。对于基于距离的子集约束,考虑了三种不同的规则:具有典型正常实例的小距离;典型和非典型之间的距离较大;非典型的正常个体之间的距离也很大。OCC使用任意深度神经网络,其中第一层进行特征提取,后一层表示分类子网络。第三个子网络,距离子网络,仅在训练过程中使用,以满足两个子集的约束。案例研究数据包括对MNIST、Fashion-MNIST和CIFAR-10数据集的应用,并将所提出的方法与其他OCC方法进行了比较,包括带RBF核的OCSVM、隔离森林、带OCSVM的ImageNet、不带ICS的Naïve神经网络、带ICS但不带子集距离约束的神经网络和Deep SVDD[70]。对比结果表明,该方法的性能优于大多数其他OCC方法。
Perera和Patel[77]提出了一种单类迁移学习的深度学习方法,其中使用来自不相关任务的标记数据进行OCC中的特征学习(关于迁移学习的调查研究请参见Pan和Yang[78])。提出了一种基于紧性损失和描述性损失两个损失函数的联合优化框架。前者用于评估所考虑的类在学习特征空间中的紧密性,而后者基于使用外部多类数据集评估描述性。神经网络主干架构是Alexnet和VGG16,这是两个成功的预训练神经网络[77]。本案例研究涉及研究三种场景的数据集:图像新颖性检测、异常图像检测和主动认证。对于图像新颖性检测,使用Caltech 246数据集,包含30,607张图像和256个类。再一次,两种神经网络的性能都比其他OCC方法有所改善。将6类1001个异常对象数据集用于异常检测研究,两种神经网络的性能均优于其他OCC方法。在主动认证研究中,使用UMDAA-02移动AA数据集[79],该数据集包含来自48个用户的多模态传感器面部观测。在这种情况下,所提出的方法对两个神经网络都没有显示出令人满意的结果。
Burlina等人[80]提出了一种无监督的方法来诊断肌病(肌炎是肌病中罕见的一种疾病),他们研究了Myositis3K基准数据集的深度学习和一类新异检测。后者由作者开发,由每个受试者双侧7个肌肉群的超声图像组成[80]。完整的数据集包括来自89名受试者的图像,大小为476×476,其中包括35名正常/对照组和54名肌炎患者(19名包体体肌炎,15名多发性肌炎,20名皮肌炎)。这次采集的结果是3586张图像的数据集。一般的方法是:通过深度特征嵌入,建立新的超声图像表示;通过PCA对图像进行降维;应用t分布随机邻居嵌入(t-SNE) [81];最后,应用新颖性检测评分算法对异常进行检测。将该方法与隔离森林(IF)、椭圆包络(EE)、局部离群因子(LOF)、OCSVM和生成对抗网络(GANomaly)等一类新颖性检测方法进行了比较。超声图像的分割采用基于图像的分割(IP)和基于患者的分割(PP)两种方法。实验发现了将深度学习技术应用于肌炎新颖性检测的有希望的结果。OCSVM效果最好,EE、IF、LOF次之。深度学习仅应用于建模过程的一部分(即深度特征嵌入),而不是用于肌病检测的无监督学习的整个过程。
Ghafoori和Leckie[82]提出了深度多球面支持向量数据描述(Deep Multi-sphere Support Vector Data Description, DMSVDD)方法,该方法假设训练数据集可以具有多个数据分布,而大多数分类方案通常假设数据分布是单一的。应用k-means聚类方法[83],将数据映射到簇中,并以球体的最小体积为度量,将数据从输入空间投影到超球形簇中。参数映射使用自编码器完成,这有助于减少重构误差。案例研究数据集为MNIST、CIFAR10和MobiAct,其中MobiAct包括67人的数据,捕获了11个正常活动和4个异常活动。考虑以下版本的MNIST数据集:MNIST0,其中0位为正常,其他数字为异常;MNIST01,其中0、1位为正常,其他位数为异常;和MNIST013,其中0、1、3位为正常,其余为异常。将该方法与SVDD、核密度估计(KDE)、RBF、IF、OCSVM、Deep SVDD (DSVDD)和Deep Convolutional AutoEncoders (DCAE)进行了比较。由于OCSVM、SVDD和RBF收敛于相似解,本文只报道了SVDD的结果。对于MNIST0数据集,DCAE、DSVDD和DMSVDD具有相似的精度。对于MNIST01数据集,DCAE和DSVDD的性能略有下降,而SVDD、KDE和IF的性能则有相当大的下降。所提出的方法DMSVDD在MNIST01上显示出令人鼓舞的结果。对于MNIST013数据集,DMSVDD结果最好,其次是DCAE;然而,对于SVDD、KDE、IF和DSVDD,可以观察到性能下降。对于CIFAR10数据集,使用SVDD观察到的性能最好,其次是DSVDD,然后是DMSVDD,这表明所提出的方法与非深度方法相比性能较差。对于MobiAct数据集,DMSVDD表现最好,其次是DCAE,而SVDD、KDE和IF表现较差。本文的结果表明,所提出的方法对底层数据集敏感。由于三个数据集的混合结果,DMSVDD的疗效并不十分清楚。
Liu等[84]提出了一种基于指纹表示攻击检测的光学相干技术(OCT)图像的一类表示攻击检测(OCPAD)方法。在他们的实证研究中使用的数据集包括来自101种材料的121个(121×400 b扫描)演示攻击和来自137个受试者的233个(233×400 b扫描)指纹(真实指纹)。将该模型与现有的PAD方法进行了比较,包括基于特征的方法、基于监督学习的方法和单类GAN方法。实证研究表明,本文提出的方法优于上述三种方法。更具体地说,当假阳性率为10%时,该方法的真阳性率为99.43%,当假阳性率为5%时,真阳性率为96.59%。文中给出了三种方法性能的ROC曲线,但未报道AUC值。此外,没有对三种方法之间性能差异的显著性进行统计验证和验证研究。
Cao等人[85]认为,现有的OCC方法虽然对高斯噪声具有鲁棒性,但在检测大量离群值时效果较差。为了解决这个问题,他们提出了一个基于最大熵准则的OCC ELM模型(MC-OCELM),并将该模型进一步扩展到一个层次网络,以提高其表征复杂数据的能力,其中扩展模型缩写为HC-OCELM。他们的实证案例研究基于8个UCI基准数据集,以说明所提出模型的有效性,然后与几种现有方法进行比较,包括Parzen, Naïve Parzen, K-means, K-centers, 1-NN, KNN, AutoEncoder, PCA,基于最小生成树(MST)的OCC,极小极大概率机(MPM), SCDD,线性规划差异数据描述(LPDD), SVM和OC-ELM。这两种方法在F-score度量方面优于其他方法。本文还研究了CIFAR10数据集,并将所提出的方法与Deep SVDD、IF、Deep Convolutional AEs、kernel density estimation、Soft-Boundary Deep SVDD和Deep Convolutional GAN进行了比较。HC-OCELM模型对10个CIFAR-10数据集中的7个提供了更好的结果,Deep SVDD在两个数据集上提供了更好的结果。总体而言,作者认为该方法在实证研究中优于其他方法。
Fontella-Romero等人[86]提出了分布式奇异值分解自编码器(DSVD-AUTO),它可以在不需要共享原始数据的情况下促进分布式场景下的学习。此外,该方法还解决了数据隐私保护问题。分布式学习环境下的数据共享和数据隐私是大数据分析面临的两个问题。案例研究包括10个数据集,大小从420个样本到11,000,000个样本不等,在建模中省略了缺少数据的实例。将该方法与LOF、OCSVM、AUTO-NN和APE等四种OCC异常检测方法进行了比较[86]。虽然OCSVM方法的平均AUC比提出的方法产生更好的结果,但作者认为前者需要调整多个超参数。然而,在从概括的角度自信地陈述所提出方法的有效性之前,还需要进行额外的调查。
Moustafa等人[87]提出了一种分布式异常检测(DAD)系统来检测边缘网络中的零日攻击。该系统采用基于高斯混合的相关熵,这是一种OCC模型。使用主成分分析选择重要的数据特征,然后传递给所提出的系统来检测异常。他们的案例研究中包含的数据集包括NSL-KDD和UNSW-NB15数据集。使用来自两个数据集的350,000个数据样本,将所提出的模型与五种异常检测方法进行了比较,包括多元相关分析(MCA)、三角区域最近邻(TANN)、几何区域分析(GAA-ADS)、离群Dirichlet混合物(ODM)和基于攻击检测的卷积神经网络(AD-CNN)。作者得出结论,他们的方法优于这五种异常检测方法,在检测率、误报率和处理时间方面。使用完整的数据集(NSL-KDD和UNSW-NB15)而不是使用两个数据集的有限样本来研究所提出的模型的性能将是有趣的。这样的研究将被视为提议的大数据方法的应用;然而,在上面的文章中并没有这样做。
Pourreza等人[88]提出了一种基于gan的单类分类深度学习方法。作者指出,为OCC训练和实现gan通常很麻烦。为了简化过程,他们将OCC问题视为一个二元分类任务,其中两个深度神经网络(生成器和鉴别器)在正常样本的GAN设置中进行训练。在训练过程的早期阶段,生成器很可能无法正确生成正常样本,因此被认为是异常样本生成器。通过这样做,深度神经网络生成了两组样本——正常和异常。随后,在这些生成的样本(使用正常和异常样本)上训练二元分类器进行异常检测。提出的G2D模型由三个主要模块组成[88]:(1)不规则产生网络,(2)批评网络,(3)检测器网络。案例研究涉及图像异常检测和视频异常检测,包括以下数据集[88]:UCSD, MNIST和Caltech-256。所提出的方法被证明在异常点检测方面具有竞争力,包括R-graph、REAPER、OutlierPursuit、LRR、SSGAN和ALOCC[88]。
现在,我们将简要介绍OCC中涉及某种形式的深度学习的其他一些工作。我们这样做是因为本节中介绍的调查作品代表了OCC中涉及深度学习的作品的一个很好的横截面。Chong等人[89]在Deep SVDD的背景下解决了超球崩溃(或模式崩溃)的问题。如果模型的体系结构不符合特定的体系结构约束,例如去除偏差项,从而限制了模型的适应性和性能,则容易出现此问题。Tan等人[90]和Golan等人[91]提出了该方法在问题上下文和应用上下文中的变化。Ruff等人提出并评估了一种深度半监督异常检测(Deep SAD)[92]。该研究的重点是借助一些标记实例来改进传统的无监督异常检测方法的性能。Goyal等人[93]通过提出和评估一种深度鲁棒单类分类方法来解决模式崩溃问题,该方法的动机是假设感兴趣的类位于局部线性低维流形上。
表3总结了深度学习和OCC调查工作的关键信息。

3.4 关于OCC的综述
在他们2014年的综述中,Khan和Madden[9]提供了“对OCC一般问题的统一看法,通过提出OCC问题的研究分类,这是基于训练数据的可用性、使用的算法和应用的应用领域。”根据训练数据的可用性进行分组的文献作品包括仅使用正数据进行学习或使用未标记数据、正数据和一些离群实例进行学习。根据所使用的方法分组的工作涉及基于单类支持向量机(osvm)或非osvm方法(例如,分类集成方法)的方法。分类法中的第三组是应用程序域,涉及到OCC是应用于文本分析/分类还是应用于其他应用程序域。我们相信作者使用的分类法是恰当的;因此,在我们的研究中,我们没有提供类似的被调查作品分类。然而,我们确实认为,与[9]所涵盖的调查相比,本研究中提出的调查提供了一个更新得多的OCC相关作品集合,特别是自2014年以来已经发表了一些关于OCC的作品。
Pimentel等人[94]将新颖性检测作为OCC问题进行了回顾。所调查的工作分为五类,包括基于概率的方法、基于距离的方法、基于重建的方法、基于领域的方法和基于信息理论的方法。在他们的工作中调查的应用领域包括电子信息技术安全、医疗信息学、医疗诊断和监控、工业监控和损伤检测、图像处理、视频监控、文本挖掘和传感器网络[94]。在选择新颖性检测方法时,需要考虑训练数据的可用性、应用领域以及数据维度、数据格式和数据连续性等数据特征。与[94]相比,除了基于OCC的新颖性检测外,本文还总结了基于OCC的离群值检测和深度学习方面的工作。因此,与文献[94]中的调查工作相比,我们对单类分类进行了更广泛的调查研究。
4 讨论
在我们调查的工作中,观察到异常值检测和新颖性检测是单类分类的主要使用领域。然而,数据挖掘和机器学习中的重要问题,如大数据中的阶级不平衡问题以及其他与大数据相关的问题,在被调查的作品中并没有得到解决。这些以及与之相关的课题都可以成为OCC很好的应用领域,如类稀有度检测、大数据中严重类失衡的影响等。例如,当数据高度不平衡时,使用OCC可以更有效地检测感兴趣的类,因为后者专注于检测感兴趣的正面类。
在被调查的作品中,OCC被频繁地应用于生物医学数据的分析。Parzen Windows的方法经常被使用;然而,基于核的方法(如SVDD和OCSVM)的性能相对较好。在异常值检测中,OCSVM似乎是一个突出的选择。它已被用于检测各种疾病的异常值,包括结核病、抑郁症和阿尔茨海默氏症。在患者监测应用的背景下,新颖性检测有助于疾病的早期检测。由于异常活动是罕见的数据点,因此与这些应用相关的数据集严重不平衡。此外,为监督学习标记数据既耗时又困难,使得监督单类学习在这种情况下不实用。
在神经成像领域,数据在特征空间中具有较高的维数,而可用的一类样本相对较少。在这种情况下,传统学习者往往表现不佳。此外,在临床诊断数据不明确或对识别患者亚组感兴趣的情况下,传统的二元分类往往表现不佳。在这种情况下,高阶层失衡是关键问题。OCC已被应用于解决痴呆检测和老年人活动完成表现的分类问题。对于这些特定领域的问题,OCSVM产生了有希望的结果。结果表明,将集成方法与OCSVM结合使用并不能提高算法的性能。
在单类分类器中,SVDD非常适合于异常点检测和异常点损失降低。然而,在有噪声或不确定数据的情况下,SVDD可能会显示过拟合。在某些数据类型中,例如可能存在采样误差的传感器数据,目标超球没有得到优化。SVDD在没有数据先验信息的高维特征空间中表现良好。在数据库知识发现领域,常用的OCC离群点检测方法有SVDD、Parzen Windows、LOF和LOCI。其中,SVDD和LOF在相关文献中取得了较好的结果。
如前所述,一类分类的另一个应用是新颖性检测,其中在测试数据集中检测异常值,而训练数据集不包含任何异常值。在异构或高维数据中,新颖性检测是检测异常的一种解决方案。一般来说,当标记数据难以获得时,新颖性检测是一种无监督学习解决方案。
由于工业数据分布不是高斯分布,因此在减少实现开销和提高性能方面,高斯过程回归有利于单类分类。在深度学习方法的帮助下,许多监督学习问题已经在OCC的背景下得到了解决。然而,在这一领域,关于无监督学习方法的选择,还需要进行大量的研究。为了解决用于新颖性检测的深度神经网络中的过拟合问题,深度高斯过程具有优势,它使深度模型能够训练过于复杂的数据或混合类型的特征。新颖性检测是监测工业机械运动部件可靠性和安全性的首选方法之一,因为可以获得大量高质量的数据。新颖性检测方法需要进行预处理以提高性能;特别是非线性特性,因为非线性振动信号对性能的影响很大。
物联网获得的大数据在计算时间和复杂度方面都需要深入考虑。由于这种系统中离群点检测的准确性与提取的特征数量有关,因此找到完美的特征子集至关重要。然而,对于大多数单类分类方法,基于向量的表示是适用的,而物联网数据最适合基于张量的方法。对于这种复杂的高维数据集,基于张量的一类分类方法优于基于向量的分类方法。处理工业数据等大数据中标注数据不足的一种适用方法是一类主动学习,它接受未标注的数据,需要的标注数据点相对较少。在暖通空调系统中,由于系统中数据的多变性,导致系统故障难以发现,常将异常情况误认为正常情况。观察到PCA是忽略这些错误条件的实用解决方案,并且与OCSVM结合使用时显示出良好的性能。
欺诈检测在所有金融服务和交易中都是必不可少的。为了检测欺诈交易,最好的解决方案之一是人类行为跟踪和使用单类分类方法。然而,这样的问题受到少数负样本的影响;因此,人工或利用专家产生负样本是克服样本短缺问题的实用方法之一。基于专家知识的单类分类模型的性能差异很大,特别是在数据创建过程中人类行为的高度多样性。一般来说,最常用的一类分类方法是OCSVM。然而,如前所述,使用OCSVM的集成学习并不能提高学习效果。一种实际可行的提高性能的方法是对损失函数进行修改,如将两个或多个损失函数组合在一起。
SVDD具有较高的泛化性能,并且对数据集中的异常值具有鲁棒性。此外,SVDD在有噪声的数据条件下是稳定的。然而,过拟合问题仍然比较普遍,是一个需要继续研究的重要课题。
采用深度网络方法对SVDD算法进行改进,提高了算法的泛化性能。嵌入了svdd的深层赋予了组合模型表示能力,从而提高了性能。深度SVDD除了具有单类分类的深度学习的优点外,还存在模态坍缩或超球坍缩等约束和限制问题。虽然引入随机噪声的正则化可能有所帮助,但这个问题需要进一步的持续研究。
传统的单类分类方法存在一些不足,例如由于敏感的超参数,在高维数据中表现不佳[76]。此外,他们需要专家标记的数据,这是耗时和繁琐的获取。为了提高复杂数据集异常检测的性能和速度,将基于ocsvm的混合模型与深度神经网络相结合是一种很有前景的方法。将支持向量机与深度神经网络相结合,提高了异常检测的准确性。在线性核和RBF核中,一些研究证实了非线性核的效率更高,并进行了改进。虽然OCSVM已被证明对OCC有益,但由于其在建模过程中的迭代性,它的计算复杂度很高,并且需要某种正则化,例如核正则化最小二乘。
在计算机视觉异常检测中,缓解高维问题的最佳方法之一是将深度学习方法与单类分类的随机梯度下降(SGD)等优化算法相结合。这样,优化算法为混合模型带来了可扩展性和在线学习[70]。将深度学习与单类异常检测和新颖性检测相结合,在异常实例检测中显示出良好的前景;然而,需要在各个领域进行持续的研究来进一步验证这一潜力。几乎没有专门针对大数据和一类分类的研究。最近的一项研究[95]在铁路状态监测系统中开发了一种边缘处理单元。该单元由两部分组成:数据分类模型和数据传输单元。通过使用数据采样而不是使用整个可用的大数据语料库,我们认为这项工作不是OCC应用于大数据分析的一个例子。
高维问题是特定领域的大数据问题;然而,在调查作品中,公开可用的图像数据集不是大数据。虽然类不平衡仍然是单分类问题的核心,但文献中尚未对严重类不平衡的数据集进行研究。大数据中的类稀缺性和单类分类问题也不存在。虽然深度学习在OCC问题中的应用正在积极研究,但这一领域还需要进行更多的研究。例如,大数据和其他数据集中存在的噪声需要比文献中观察到的更好的解决方案。此外,大数据单类分类背景下的特征工程是一个很有前途的研究领域。创新的方法,如迁移学习,在单类分类解决方案的背景下需要额外的关注。在OCC的背景下研究基于增强的方法可能会产生有趣的结果;特别是,由于它在传统的分类问题中显示出广泛的前景。
5 结论
本研究对过去十年,即2010-2021年(2021年5月)的文献中提出的一类分类方法和方法进行了大量调查,包括特定领域的应用。我们的调查将不同的工作分为三类:异常值检测和OCC,新颖性检测和OCC,深度学习和OCC。本文考察了关于一类分类的选定作品,以便在调查中代表了方法,方法和应用领域的良好横截面。此外,本文还重点介绍了OCC在处理大数据时面临的各种问题中的潜在应用。
虽然这不是一次详尽的调查,但据我们所知,这是文献中关于单类分类作品的最新调查论文。在单类分类中,很大程度上被忽略的一个领域是大数据的应用环境及其固有的相关问题,如严重的类不平衡、类稀有、噪声数据和特征工程。我们认为这篇关于单类分类的调查论文将受到数据挖掘和机器学习大数据领域的研究人员和科学家的赞赏。此外,对于单类分类,还需要在迁移学习[96]、深度学习、特征工程和选择[97]、数据质量和数据收集、主动学习[98]、半监督学习以及其他领域应用[99]等领域进行额外的研究。
References
- Bauder RA, Khoshgoftaar TM, Hasanin T. An empirical study on class rarity in big data. In: 2018 17th IEEE international conference on machine learning and applications (ICMLA). IEEE; 2018.
- Herland M, Bauder RA, Khoshgoftaar TM. The effects of class rarity on the evaluation of supervised healthcare fraud
detection models. J Big Data. 2019;6(1):1–33. - Tawfiq H, Khoshgoftaar TM, Leevy JL, Bauder RA. Investigating class rarity in big data. J Big Data. 2020;7(1):1–7.
- Bauder RA, Khoshgoftaar TM. A study on rare fraud predictions with big Medicare claims fraud data. Intell Data Anal.
2020;24(1):141–61. - Heredia B, Khoshgoftaar TM, Prusa JD, Crawford M. Improving detection of untrustworthy online reviews using
ensemble learners combined with feature selection. Soc Netw Anal Min. 2017;7(1):1–18. - Hasanin T, Khoshgoftaar TM, Leevy J, Seliya N. Investigating random undersampling and feature selection on
bioinformatics big data. In: 2019 IEEE fifth international conference on big data computing service and applications
(BigDataService). IEEE; 2019. - Bartkowiak AM. Anomaly, novelty, one-class classification: a comprehensive introduction. Int J Comput Inf Syst Ind
Manag Appl. 2011;3(1):61–71. - Kennedy K, Mac Namee B, Delany SJ. A study of one-class classification and the low-default portfolio problem. In:
Irish conference on artificial intelligence and cognitive science; 2009, p. 174–87. - Khan SS, Madden MG. One-class classification: taxonomy of study and review of techniques. Knowl Eng Rev.
2014;29(3):345–74. - Schölkopf B, Platt JC, Shawe-Taylor J, Smola AJ, Williamson RC. Estimating the support of a high-dimensional distribution. Neural Comput. 2001;17(3):1443–71.
- Tax DM, Duin RP. Support vector data description. Mach Learn. 2004;54(1):45–66.
- Jiang MF, Tseng SS, Su CM. Two-phase clustering process for outliers detection. Pattern Recogn Lett.
2001;22(6–7):691–700. - Bishop CM. Neural networks for pattern recognition. Oxford: Oxford University Press; 1995.
- Carpenter GA, Grossberg S, Rosen. Fuzzy ART: fast stable learning and categorization of analog patterns by an adaptive resonance system. Neural Netw. 1991;4(6):759–71.
- Salekshahrezaee Z, Leevy JL, Khoshgoftaar TM. A reconstruction error-based framework for label noise detection. J
Big Data. 2021;8(1):1–16. - Japkowicz N, Myers C, Gluck M. A novelty detection approach to classification. In: International joint conference on
artificial intelligence (IJCAI); 1995. - Desir C, Bernard S, Petitjean C, Heutte L. A new random forest method for one class classification. In: IAPR international workshop on statistical techniques in pattern recognition (SPR), Hiroshima, Japan, vol. 7626 of LNCS; 2012, p.
282–90. - Krawczyk B, Woźniak M, Cyganek B. Clustering-based ensembles for one-class classification. Inf Sci. 2014;264:182–95.
- Pekalska EE, Tax DM, Duin R. One-class LP classifiers for dissimilarity representations. In: Advances in neural information processing systems; 2003.
- Lang R, Lu R, Zhao C, Qin H, Liu G. Graph-based semi-supervised one-class support vector machine for detecting
abnormal lung sounds. Appl Math Comput. 2020;364:124487. - Gautam C, Tiwari A, Leng Q. On the construction of extreme learning machine for online and offline one-class classification—an expanded toolbox. Neurocomputing. 2017;261:126–43.
- Krawczyk B, Woźniak M. One-class classifiers with incremental learning and forgetting for data streams with concept
drift. Soft Comput. 2015;19(12):3387–400. - Leng Q, Qi H, Miao J, Zhu W, Su G. One-class classification with extreme learning machine. In: Mathematical problems in engineering, vol. 15. London: Hindawi Publishing; 2015.
- Dai H, Cao J, Wang T, Deng M, Yang Z. Multilayer one-class extreme learning machine. Neural Netw. 2019;115:11–22.
- Dreiseitl S, Osl M, Scheibböck C, Binder M. Outlier detection with one-class SVMs: an application to melanoma
prognosis. In: AMIA annual symposium proceedings; 2010. - Witten IH, Frank E, Hall MA, Pal CJ. Data mining: practical machine learning tools and techniques. 4th ed. Burlington:
Morgan Kaufmann; 2017. - Mourão-Miranda J, Hardoon DR, Hahn T, Marquand AF, Williams SC, Shawe-Taylor J, Brammer M. Patient classification as an outlier detection problem: an application of the one-class support vector machine. Neuroimage.
2011;58(3):793–804. - Bartkowiak AM, Zimroz R0 Outliers analysis and one class classification approach for planetary gearbox diagnosis. In:
9th international conference on damage assessment of structures (DAMAS 2011); 2011. - Désir C, Bernard S, Petitjean C, Heutte L. One class random forests. Pattern Recogn. 2013;46(12):3490–506.
- Das B, Cook DJ, Krishnan NC, Schmitter-Edgecombe M. One-class classification-based real-time activity error detection in smart homes. IEEE J Select Top Signal Process. 2016;10(5):914–23.
- Deng X, Jiang P, Peng X, Mi C. An intelligent outlier detection method with one class support tucker machine and
genetic algorithm toward big sensor data in Internet of Things. IEEE Trans Industr Electron. 2018;66(6):4672–83. - Gautam C, Mishra PK, Tiwari A, Richhariya B, Pandey HM, Wang S. Minimum variance-embedded deep kernel
regularized least squares method for one-class classification and its applications to biomedical data. Neural Netw.
2020;123:191–216. - Mygdalis V, Iosifidis A, Tefas A, Pitas I. One class classification applied in facial image analysis. In: 2016 IEEE international conference on image processing (ICIP); 2016.
- Kauffmann J, Müller KR, Montavon G. Towards explaining anomalies: a deep Taylor decomposition of one-class
models. Pattern Recogn. 2020;101:107198. - Montavon G, Binder A, Lapuschkin S, Samek W, Müller KR. Layer-wise relevance propagation: an overview. Explainable AI: interpreting, explaining and visualizing deep learning; 2019. p. 193–209.
- Aguilera J, Farıas DIH, Ortega-Mendoza RM, Montes-y-Gomez M. Depression and anorexia detection in social media
as a one-class classification problem. Appl Intell. 2021. https://doi.org/10.1007/s10489-020-02131-2. - Aguilera J, Gonzalez LC, Montes-y-Gomez M, Rosso P. A new weighted k-nearest neighbor algorithm based on
Newton’s gravitational force. In: Vera-Rodriguez R, Fierrez J, Morales A, editors. Progress in pattern recognition, image
analysis, computer vision, and applications. Cham: Springer International Publishing; 2018. p. 305–13. - Pu G, Wang L, Shen J, Dong F. A hybrid unsupervised clustering-based anomaly detection method. Tsingua Sci
Technol. 2021;2(2):146–53. - Casas P, Mazel J, Owezarski P. Unsupervised network intrusion detection systems: detecting the unknown without
knowledge. Comput Commun. 2012;35(7):772–83. - Favarelli E, Giorgetti A. Machine learning for automatic processing of modal analysis in damage detection of
bridges. IEEE Trans Instrum Measure. 2021;70:1–3. - Mahfouz AM, Abuhussein A, Venugopal D, Shiva D. Network intrusion detection model using one-class support
vector machine. In: Patnaik S et al. (eds.), Advances in machine learning and computational intelligence, algorithms
for intelligent systems; 2021. - Zaidi SFA, Lee C. One-class classification based bug triage system to assign a newly added developer. In: IEEE international conference on information networking (ICOIN); 2021.
- Lee SR, Heo MJ, Lee CG, Kim M, Jeong G. Applying deep learning based automatic bug triager to industrial projects.
In: Proceedings of the 11th joint meeting on foundations of software engineering; 2017, p. 926–31. - Mani S, Sankaran A, Aralikatte R. Deeptriage: exploring the effectiveness of deep learning for bug triaging. In: Proceedings of the ACM India joint international conference on data science and management of data; 2019, p. 171–9.
- Clifton L, Clifton DA, Watkinson PJ, Tarassenko L. Identification of patient deterioration in vital-sign data using
one-class support vector machines. In: 2011 federated conference on computer science and information systems
(FedCSIS); 2011. - Kemmler M, Rodner E, Wacker ES, Denzler J. One-class classification with Gaussian processes. Pattern Recogn.
2013;46(12):3507–18. - Beghi A, Cecchinato L, Corazzol C, Rampazzo M, Simmini F, Susto GA. A one-class svm based tool for machine learning novelty detection in hvac chiller systems. IFAC Proc. 2014;47(3):1953–8.
- Domingues R, Michiardi P, Zouaoui J, Filippone M. Deep Gaussian Process autoencoders for novelty detection. Mach
Learn. 2018;107:1363–83. - Sadooghi MS, Khadem SE. Improving one class support vector machine novelty detection scheme using nonlinear
features. Pattern Recogn. 2018;83:14–33. - Yin L, Wang H, Fan W. Active learning-based support vector data description method for robust novelty detection.
Knowl Based Syst. 2018;153:40–52. - Rad Mohammadian N, Van Laarhoven T, Furlanello C, Marchiori E. Novelty detection using deep normative modeling for imu-based abnormal movement monitoring in Parkinson’s disease and autism spectrum disorders. Sensors.
2018;18(10):3533. - Sabokrou M, Khalooei M, Fathy M, Adeli E. Adversarially learned one-class classifier for novelty detection. In: IEEE
conference on computer vision and pattern recognition; 2018. - Shorten C, Khoshgoftaar TM. A survey on image data augmentation for deep learning. J Big Data. 2019;6(1):1–48.
- Sabokrou M, Fathy M, Zhao G, Adeli E. Deep end-to-end one-class classifier. IEEE Trans Neural Netw Learn Syst.
2021;32(2):675–84. - Oosterlinck D, Benoit DF, Baecke P. From one-class to two-class classification by incorporating expert knowledge:
novelty detection in human behaviour. Eur J Oper Res. 2020;282(3):1011–24. - Xing HJ, Liu W. Robust AdaBoost based ensemble of one-class support vector machines. Inf Fus. 2020;55:45–58.
- Rafieipour H, Zadeh AA, Moradan A, Salekshahrezaee Z. Study of genes associated with Parkinson disease using
feature selection. J Bioeng Res. 2020;2(4):1–12. - Perera P, Nallapati R, Xiang B. OCGAN: one-class novelty detection using GANS with constrained latent representations. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR); 2019, p. 2893–901.
- Zhang Y, Zhou B, Ding X, Ouyang J, Cai X, Gao J, Yuan X. Adversarially learned one-class novelty detection with
confidence estimation. Inf Sci. 2021;552:48–64. - Kim S, Choi Y, Lee M. Deep learning with support vector data description. Neurocomputing. 2015;165:111–7.
- Erfani SM, Rajasegarar S, Karunasekera S, Leckie C. High-dimensional and large-scale anomaly detection using a
linear one-class SVM with deep learning. Pattern Recogn. 2016;58:121–34. - Sun J, Shao J, He C. Abnormal event detection for video surveillance using deep one-class learning. Multimedia
Tools Appl. 2019;78(3):3633–47. - Altaher A, Salekshahrezaee Z, Zadeh AA, Rafieipour H, Altaher A. Using multi-inception CNN for face emotion recognition. J Bioeng Res. 3(1):1-12
- Mahadevan V, Li W, Bhalodia V, Vasconcelos N. Anomaly detection in crowded scenes. In: 2010 IEEE computer society conference on computer vision and pattern recognition; 2010.
- Cong Y, Yuan J, Liu J. Sparse reconstruction cost for abnormal event detection. In: 24th IEEE conference on computer
vision and pattern recognition (CVPR 2011); 2011. - Xu D, Ricci E, Yan Y, Song J, Sebe N. Learning deep representations of appearance and motion. In: Proceedings of the
British machine vision conference (BMVC2015); 2015. - Adam A, Rivlin E, Shimshoni I, Reinitz D. Robust real-time unusual event detection using multiple fixed-location
monitors. IEEE Trans Pattern Anal Mach Intell. 2008;30(3):555–60. - Zhang M, Wu J, Lin H, Yuan P, Song Y. The application of one-class classifier based on CNN in image defect detection.
Procedia Comput Sci. 2017;114:341–8. - Gutoski M, Ribeiro M, Aquino NMR, Lazzaretti AE, Lopes HS. A clustering-based deep autoencoder for one-class
image classification. In: IEEE Latin American conference on computational intelligence (LACCI); 2017. - Ruff L, Vandermeulen R, Goernitz N, Deecke L, Siddiqui SA, Binder A, Muller E, Kloft M. Deep one-class classification.
In: International conference on machine learning; 2018. - Kingma D, Ba J. Adam: a method for stochastic optimization, v1; 2015. https://arxiv.org/abs/1412.6980.
- Brendel W, Rauber J, Bethge M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models, v1; 2017. https://arxiv.org/abs/1712.04248.
- Stallkamp J, Schlipsing M, Salmen J, Igel C. The German traffic sign recognition benchmark: a multi-class classification competition. In: Proceedings of the international joint conference on neural networks; 2011.
- Schlegl T, Seeboock P, Waldstein SM, Schmidt-Erfurth U, Langs G. Unsupervised anomaly detection with generative
adversarial networks to guide marker discovery. In: International conference on information processing in medical
imaging; 2017. - Chalapathy R, Menon AK, Chawla S. Anomaly detection using one-class neural networks, v1; 2018. https://arxiv.org/
abs/1802.06360. - Schlachter P, Liao Y, Yang B. Deep one-class classification using intra-class splitting. In: IEEE data science workshop
(DSW), June 2019, p. 100–4, Minneapolis, MN, https://doi.org/10.1109/DSW.2019.8755576. - Perera P, Patel VM. Learning deep features for one-class classification. IEEE Trans Image Process. 2019;28:5450–63.
- Pan SJ, Yang Q. A survey on transfer learning. IEEE Trans Knowl Data Eng. 2009;22(10):1345–59.
- Mahbub U, Sarkar S, Patel VM, Chellappa R. Active user authentication for smartphones: A challenge data set and
benchmark results. In: IEEE 8th international conference on biometrics theory, applications and systems (BTAS); - Burlina P, Joshi M, Billings S, Wang IJ, Albayda J. Deep embeddings for novelty detection in myopathy. Comput Biol
Med. 2019;105:46–53. - Maaten LVD, Hinton G. Visualizing data using t-SNE. J Mach Learn Res. 2008;9:2579–605.
- Ghafoori Z, Leckie C. Deep multi-sphere support vector data description. In: SIAM international conference on data
mining; 2020. - Lloyd S. Least squares quantization in PCM. IEEE Trans Inf Theory. 1982;28:129–37.
- Liu F, Liu H, Zhang W, Liu G, Shen L. One-class fingerprint presentation attack detection using auto-encoder network. IEEE Trans Image Process. 2021;30:2394–406.
- Cao J, Dai H, Lei B, Yin C, Zeng H, Kummert A. Maximum correntropy criterion-based hierarchical one-class classification. IEEE Trans Neural Netw Learn Syst. 2020. https://doi.org/10.1109/TNNLS.2020.3015356.
- Fontenla-Romero O, Pérez-Sánchez B, Guijarro-Berdiñas B. DSVD-autoencoder: a scalable distributed privacy-preserving method for one-class classification. Int J Intell Syst. 2020;26:177–99.
- Moustafa N, Keshk M, Choo KR, Lynar T, Camtepe S, Whitty M. DAD: a distributed anomaly detection system using
ensemble one-class statistical learning in edge networks. Futur Gener Comput Syst. 2021;118:240–51. - Pourreza M, Mohammadi B, Khaki M, Bouindour S, Snoussi H, Sabokrou M. G2D: generate to detect anomaly. In:
Workshop on applications of computer vision; 2021. - Chong P, Ruff L, Kloft M, Binder A. Simple and effective prevention of mode collapse in deep one-class classification.
arXiv preprint; 2020. https://arxiv.org/abs/2001.08873. - Tan WR, Chan CS, Aguirre HE, Tanaka K. ArtGAN: artwork synthesis with conditional categorical GANs. In: IEEE international conference on image processing (ICIP); 2017.
- Golan I, El-Yaniv R. Deep anomaly detection using geometric transformations. In: Advances in neural information
processing systems; 2018. - Ruff L, Vandermeulen RA, Görnitz N, Binder A, Müller E, Müller KR, Kloft M. Deep semi-supervised anomaly detection.
arXiv preprint; 2020. https://arxiv.org/abs/1906.02694. - Goyal S, Raghunathan A, Jain M, Simhadri HV, Jain P. DROCC: deep robust one-class classification. arXiv preprint;
- https://arxiv.org/abs/2002.12718.
- Pimentel MA, Clifton DA, Clifton L, Tarassenko L. A review of novelty detection. Signal Process. 2014;99:215–49.
- Saki M, Abolhasan M, Lipman J. A novel approach for big data classification and transportation in rail networks. IEEE
Trans Intell Transp Syst. 2019;21(3):1239–49. - Jintawatsakoon S, Charoenruengkit W. Novelty detection of beverage bottle images based on transfer learning. In:
IEEE 5th international conference on information technology; 2020, p. 87–91. - Tsai CF, Lin WC. Feature selection and ensemble learning techniques in one-class classifiers: an empirical study of
two-class imbalanced datasets. IEEE Access. 2021. https://doi.org/10.1109/ACCESS.2021.3051969. - Lesouple J, Tourneret JY. Incorporating user feedback into one-class support vector machines for anomaly detection. In: 28th European signal processing conference (EUSIPCO 2020); 2020, p. 1609–12, Amsterdam.
- Jaber M, Nasser A, Charara N, Mansoury A, Yao KC. One-class based learning for hybrid spectrum sensing in cognitive radio. In: 28th European signal processing conference (EUSIPCO 2020); 2020, p. 1683–6, Amsterdam.
-
相关阅读:
某金融机构分布式数据库架构方案与运维方案设计分享
1.2 什么是eBPF?(下)
UDS04-清除诊断信息服务【ServiceID = 0x14】
5G——物理层仿真
Salesforce ServiceCloud考证学习(3)
当未指定且存在多个构造器,实例化对象时Spring如何选择?
【git随笔,日常积累】
从裸机到嵌入式Linux—总纲
视频融合平台EasyCVR视频广场页脚优化为瀑布流式的实现方式
序列类型(元组()、列表[]、字符串““)、集合类型({}、set())
- 原文地址:https://blog.csdn.net/search_129_hr/article/details/132732507