-
朴素贝叶斯
贝叶斯理论一个重要的概念是条件概率
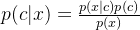
c,x不独立时,p(cx)=p(c|x)p(x)
意思是cx都发生的概率=x发生的概率乘以x发生的情况下c发生的概率
- from __future__ import print_function
- from numpy import *
- """
- p(xy)=p(x|y)p(y)=p(y|x)p(x)
- p(x|y)=p(y|x)p(x)/p(y)
- """
- # 项目案例1: 屏蔽社区留言板的侮辱性言论
- def loadDataSet():
- """
- 创建数据集
- :return: 单词列表postingList, 所属类别classVec
- """
- postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #[0,0,1,1,1......]
- ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
- ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
- ['stop', 'posting', 'stupid', 'worthless', 'garbage'],
- ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
- ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
- classVec = [0, 1, 0, 1, 0, 1] # 1 is abusive, 0 not
- return postingList, classVec
- def createVocabList(dataSet):
- """
- 获取所有单词的集合
- :param dataSet: 数据集
- :return: 所有单词的集合(即不含重复元素的单词列表)
- """
- vocabSet = set([]) # create empty set
- for document in dataSet:
- # 操作符 | 用于求两个集合的并集
- vocabSet = vocabSet | set(document) # union of the two sets
- return list(vocabSet)
- def setOfWords2Vec(vocabList, inputSet):
- """
- 遍历查看该单词是否出现,出现该单词则将该单词置1
- :param vocabList: 所有单词集合列表
- :param inputSet: 输入数据集
- :return: 匹配列表[0,1,0,1...],其中 1与0 表示词汇表中的单词是否出现在输入的数据集中
- """
- # 创建一个和词汇表等长的向量,并将其元素都设置为0
- returnVec = [0] * len(vocabList)# [0,0......]
- # 遍历文档中的所有单词,如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为1
- for word in inputSet:
- if word in vocabList:
- returnVec[vocabList.index(word)] = 1
- else:
- print("the word: %s is not in my Vocabulary!" % word)
- return returnVec
- def _trainNB0(trainMatrix, trainCategory):
- """
- 训练数据原版
- :param trainMatrix: 文件单词矩阵 [[1,0,1,1,1....],[],[]...]
- :param trainCategory: 文件对应的类别[0,1,1,0....],列表长度等于单词矩阵数,其中的1代表对应的文件是侮辱性文件,0代表不是侮辱性矩阵
- :return:
- """
- # 文件数
- numTrainDocs = len(trainMatrix)
- # 单词数
- numWords = len(trainMatrix[0])
- # 侮辱性文件的出现概率,即trainCategory中所有的1的个数,
- # 代表的就是多少个侮辱性文件,与文件的总数相除就得到了侮辱性文件的出现概率
- pAbusive = sum(trainCategory) / float(numTrainDocs)
- # 构造单词出现次数列表
- p0Num = zeros(numWords) # [0,0,0,.....]
- p1Num = zeros(numWords) # [0,0,0,.....]
- # 整个数据集单词出现总数
- p0Denom = 0.0
- p1Denom = 0.0
- for i in range(numTrainDocs):
- # 遍历所有的文件,如果是侮辱性文件,就计算此侮辱性文件中出现的侮辱性单词的个数
- if trainCategory[i] == 1:
- p1Num += trainMatrix[i] #[0,1,1,....]->[0,1,1,...]
- p1Denom += sum(trainMatrix[i])
- else:
- # 如果不是侮辱性文件,则计算非侮辱性文件中出现的侮辱性单词的个数
- p0Num += trainMatrix[i]
- p0Denom += sum(trainMatrix[i])
- # 类别1,即侮辱性文档的[P(F1|C1),P(F2|C1),P(F3|C1),P(F4|C1),P(F5|C1)....]列表
- # 即 在1类别下,每个单词出现次数的占比
- p1Vect = p1Num / p1Denom# [1,2,3,5]/90->[1/90,...]
- # 类别0,即正常文档的[P(F1|C0),P(F2|C0),P(F3|C0),P(F4|C0),P(F5|C0)....]列表
- # 即 在0类别下,每个单词出现次数的占比
- p0Vect = p0Num / p0Denom
- return p0Vect, p1Vect, pAbusive
- def trainNB0(trainMatrix, trainCategory):
- """
- 训练数据优化版本
- :param trainMatrix: 文件单词矩阵
- :param trainCategory: 文件对应的类别
- :return:
- """
- # 总文件数
- numTrainDocs = len(trainMatrix)
- # 总单词数
- numWords = len(trainMatrix[0])
- # 侮辱性文件的出现概率
- pAbusive = sum(trainCategory) / float(numTrainDocs)
- # 构造单词出现次数列表
- # p0Num 正常的统计
- # p1Num 侮辱的统计
- # 避免单词列表中的任何一个单词为0,而导致最后的乘积为0,所以将每个单词的出现次数初始化为 1
- p0Num = ones(numWords)#[0,0......]->[1,1,1,1,1.....]
- p1Num = ones(numWords)
- # 整个数据集单词出现总数,2.0根据样本/实际调查结果调整分母的值(2主要是避免分母为0,当然值可以调整)
- # p0Denom 正常的统计
- # p1Denom 侮辱的统计
- p0Denom = 2.0
- p1Denom = 2.0
- for i in range(numTrainDocs):
- if trainCategory[i] == 1:
- # 累加辱骂词的频次
- p1Num += trainMatrix[i]
- # 对每篇文章的辱骂的频次 进行统计汇总
- p1Denom += sum(trainMatrix[i])
- else:
- p0Num += trainMatrix[i]
- p0Denom += sum(trainMatrix[i])
- # 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表
- p1Vect = log(p1Num / p1Denom)
- # 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表
- p0Vect = log(p0Num / p0Denom)
- return p0Vect, p1Vect, pAbusive
- def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
- """
- 使用算法:
- # 将乘法转换为加法
- 乘法: P(C|F1F2...Fn) = P(F1F2...Fn|C)P(C)/P(F1F2...Fn)
- 加法: P(F1|C)*P(F2|C)....P(Fn|C)P(C) -> log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
- :param vec2Classify: 待测数据[0,1,1,1,1...],即要分类的向量
- :param p0Vec: 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表
- :param p1Vec: 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表
- :param pClass1: 类别1,侮辱性文件的出现概率
- :return: 类别1 or 0
- """
- # 计算公式 log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
- # 使用 NumPy 数组来计算两个向量相乘的结果,这里的相乘是指对应元素相乘,即先将两个向量中的第一个元素相乘,然后将第2个元素相乘,以此类推。
- # 我的理解是: 这里的 vec2Classify * p1Vec 的意思就是将每个词与其对应的概率相关联起来
- # 可以理解为 1.单词在词汇表中的条件下,文件是good 类别的概率 也可以理解为 2.在整个空间下,文件既在词汇表中又是good类别的概率
- p1 = sum(vec2Classify * p1Vec) + log(pClass1)
- p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
- if p1 > p0:
- return 1
- else:
- return 0
- def bagOfWords2VecMN(vocabList, inputSet):
- returnVec = [0] * len(vocabList)
- for word in inputSet:
- if word in vocabList:
- returnVec[vocabList.index(word)] += 1
- return returnVec
- def testingNB():
- """
- 测试朴素贝叶斯算法
- """
- # 1. 加载数据集
- listOPosts, listClasses = loadDataSet()
- # 2. 创建单词集合
- myVocabList = createVocabList(listOPosts)
- # 3. 计算单词是否出现并创建数据矩阵
- trainMat = []
- for postinDoc in listOPosts:
- # 返回m*len(myVocabList)的矩阵, 记录的都是0,1信息
- trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
- # 4. 训练数据
- p0V, p1V, pAb = trainNB0(array(trainMat), array(listClasses))
- # 5. 测试数据
- testEntry = ['love', 'my', 'dalmation']
- thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
- print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))
- testEntry = ['stupid', 'garbage']
- thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
- print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))
- # ------------------------------------------------------------------------------------------
- # 项目案例2: 使用朴素贝叶斯过滤垃圾邮件
- # 切分文本
- def textParse(bigString):
- '''
- Desc:
- 接收一个大字符串并将其解析为字符串列表
- Args:
- bigString -- 大字符串
- Returns:
- 去掉少于 2 个字符的字符串,并将所有字符串转换为小写,返回字符串列表
- '''
- import re
- # 使用正则表达式来切分句子,其中分隔符是除单词、数字外的任意字符串
- listOfTokens = re.split(r'\W*', bigString)
- return [tok.lower() for tok in listOfTokens if len(tok) > 2]
- def spamTest():
- '''
- Desc:
- 对贝叶斯垃圾邮件分类器进行自动化处理。
- Args:
- none
- Returns:
- 对测试集中的每封邮件进行分类,若邮件分类错误,则错误数加 1,最后返回总的错误百分比。
- '''
- docList = []
- classList = []
- fullText = []
- for i in range(1, 26):
- # 切分,解析数据,并归类为 1 类别
- wordList = textParse(open('data/4.NaiveBayes/email/spam/%d.txt' % i).read())
- docList.append(wordList)
- classList.append(1)
- # 切分,解析数据,并归类为 0 类别
- wordList = textParse(open('data/4.NaiveBayes/email/ham/%d.txt' % i).read())
- docList.append(wordList)
- fullText.extend(wordList)
- classList.append(0)
- # 创建词汇表
- vocabList = createVocabList(docList)
- trainingSet = range(50)
- testSet = []
- # 随机取 10 个邮件用来测试
- for i in range(10):
- # random.uniform(x, y) 随机生成一个范围为 x - y 的实数
- randIndex = int(random.uniform(0, len(trainingSet)))
- testSet.append(trainingSet[randIndex])
- del(trainingSet[randIndex])
- trainMat = []
- trainClasses = []
- for docIndex in trainingSet:
- trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
- trainClasses.append(classList[docIndex])
- p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses))
- errorCount = 0
- for docIndex in testSet:
- wordVector = setOfWords2Vec(vocabList, docList[docIndex])
- if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
- errorCount += 1
- print('the errorCount is: ', errorCount)
- print('the testSet length is :', len(testSet))
- print('the error rate is :', float(errorCount)/len(testSet))
- def testParseTest():
- print(textParse(open('data/4.NaiveBayes/email/ham/1.txt').read()))
- # -----------------------------------------------------------------------------------
- # 项目案例3: 使用朴素贝叶斯从个人广告中获取区域倾向
- # 将文本文件解析成 词条向量
- def setOfWords2VecMN(vocabList,inputSet):
- returnVec=[0]*len(vocabList) # 创建一个其中所含元素都为0的向量
- for word in inputSet:
- if word in vocabList:
- returnVec[vocabList.index(word)]+=1
- return returnVec
- #文件解析
- def textParse(bigString):
- import re
- listOfTokens=re.split(r'\W*', bigString)
- return [tok.lower() for tok in listOfTokens if len(tok)>2]
- #RSS源分类器及高频词去除函数
- def calcMostFreq(vocabList,fullText):
- import operator
- freqDict={}
- for token in vocabList: #遍历词汇表中的每个词
- freqDict[token]=fullText.count(token) #统计每个词在文本中出现的次数
- sortedFreq=sorted(freqDict.iteritems(),key=operator.itemgetter(1),reverse=True) #根据每个词出现的次数从高到底对字典进行排序
- return sortedFreq[:30] #返回出现次数最高的30个单词
- def localWords(feed1,feed0):
- import feedparser
- docList=[];classList=[];fullText=[]
- minLen=min(len(feed1['entries']),len(feed0['entries']))
- for i in range(minLen):
- wordList=textParse(feed1['entries'][i]['summary']) #每次访问一条RSS源
- docList.append(wordList)
- fullText.extend(wordList)
- classList.append(1)
- wordList=textParse(feed0['entries'][i]['summary'])
- docList.append(wordList)
- fullText.extend(wordList)
- classList.append(0)
- vocabList=createVocabList(docList)
- top30Words=calcMostFreq(vocabList,fullText)
- for pairW in top30Words:
- if pairW[0] in vocabList:vocabList.remove(pairW[0]) #去掉出现次数最高的那些词
- trainingSet=range(2*minLen);testSet=[]
- for i in range(20):
- randIndex=int(random.uniform(0,len(trainingSet)))
- testSet.append(trainingSet[randIndex])
- del(trainingSet[randIndex])
- trainMat=[];trainClasses=[]
- for docIndex in trainingSet:
- trainMat.append(bagOfWords2VecMN(vocabList,docList[docIndex]))
- trainClasses.append(classList[docIndex])
- p0V,p1V,pSpam=trainNB0(array(trainMat),array(trainClasses))
- errorCount=0
- for docIndex in testSet:
- wordVector=bagOfWords2VecMN(vocabList,docList[docIndex])
- if classifyNB(array(wordVector),p0V,p1V,pSpam)!=classList[docIndex]:
- errorCount+=1
- print('the error rate is:',float(errorCount)/len(testSet))
- return vocabList,p0V,p1V
- # 最具表征性的词汇显示函数
- def getTopWords(ny,sf):
- import operator
- vocabList,p0V,p1V=localWords(ny,sf)
- topNY=[];topSF=[]
- for i in range(len(p0V)):
- if p0V[i]>-6.0:topSF.append((vocabList[i],p0V[i]))
- if p1V[i]>-6.0:topNY.append((vocabList[i],p1V[i]))
- sortedSF=sorted(topSF,key=lambda pair:pair[1],reverse=True)
- print("SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**")
- for item in sortedSF:
- print(item[0])
- sortedNY=sorted(topNY,key=lambda pair:pair[1],reverse=True)
- print("NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**")
- for item in sortedNY:
- print(item[0])
- testingNB()
- spamTest()
- laTest()
-
相关阅读:
java计算机毕业设计技术旅游平台MyBatis+系统+LW文档+源码+调试部署
MyBatis-plus 分页功能实现
前端文件word Excel pdf PPT预览
Win7系统电脑调节屏幕亮度的几种方法。
Proteus软件初学笔记
Python configparser模块
Linux下mysql数据文件转移攻略
【数智化人物展】同方有云联合创始人兼总经理江琦:云计算,引领数智化升级的动能...
代码随想录算法训练营第六天 |18. 四数之和、344.反转字符串、541. 反转字符串II
ArcGIS Pro创建、发布、调用GP服务全过程示例(等高线分析)
- 原文地址:https://blog.csdn.net/qq_36973725/article/details/132622349
