-
【Mysql专题】使用Mysql做排行榜,线上实例
背景
我们这里有个需求,对存量用户的余额做排行处理,这个实现方式很多,这边介绍的是,通过
Mysql直接实现,将排名也直接返回出来。
我知道大家在网上能找到一大把这种实例,我在这里可不是【重复造轮子】。我是这么想的,通过剖析的方式让大家理解这么写的原理,以及用到了什么知识点。一、普通排行,使用会话变量
业务需求:获取系统中,用户余额的排行榜。相同余额排名先后顺序无所谓
sql语句如下:select tmp.*,(@r:=@r+1) as rank from ( SELECT uu.phone_number, uw.balance_type, uw.wallet_balance FROM us_wallet uw INNER JOIN us_user uu ON uw.user_id = uu.user_id order by uw.wallet_balance desc ) tmp,(select @r:=0) r;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输入如下:
补充说明:我想上面的表
us_user跟us_wallet以及他们的字段就不用我多说了吧,这是我系统的业务,你们也不用关心我的表跟字段是如何设计的,通过表名跟字段名都能理解了知识点剖析:
这里我认为有4个知识点,并且有2个是比较陌生的需要给大家说说。(select @r:=0) r:select是向mysql拿数据;@r:=0代表向mysql定义一个变量,初始化值为0;外层的r是定义别名select * from (...省略...) tmp,(select @r:=0) r:这里的关键点是两个表tmp跟r之间,使用逗号,是什么意思呢?我们可以把这个叫做【逗号连接符】,等同于inner join运算。那inner join大家应该知道啥意思吧?就是做【笛卡尔积】。【笛卡尔积】的意思如下:- 假设A={a, b},B={1, 2, 3}。那么对A跟B做【笛卡尔积】得到的结果是:A ✖ B = {(a, 1), (a, 2), (a,3), (b, 1), (b, 2), (b, 3)}。 以上是数学表示方式
- 数据库表中解释:左边表的记录 ✖ 右边表的记录
- 既然是等同于
inner join,那inner join的on怎么体现出来?首先,inner join其实可以省略on的,相当于对左右两张表做全乘积,如果是大表的话就完犊子了!加上on是做条件筛选而已;其次,【逗号连接符】也可以使用where来做条件筛选的,就这么简单而已 (@r:=@r+1):既然知道@r是变量来的,这个我想大家都知道啥意思吧?就是每调用@r一次就对@r做一次累加咯
二、并列排行,使用会话变量
这个算是对我上一个实例业务的补充,我也是在网上看文章偶然学习到的。我们前面的业务有一个条件是:相同余额排名先后顺序无所谓。如果需求改成:相同余额排名并列,后面的排名不存在跳跃,那该如何写呢?哈哈,其实也不难,我们上面不是已经学习了【如何向mysql新增一个变量】嘛,新增一个变量存上一次的余额不就行了吗skr
(PS:不跳跃,即2个人并列第1后面是第2;跳跃,即2个人并列第1后面是第3)
sql如下:SELECT tmp.*, IF(@last = tmp.wallet_balance, @r, @r := @r+1) AS rank, @last := tmp.wallet_balance AS last FROM ( SELECT uu.phone_number, uw.balance_type, uw.wallet_balance FROM us_wallet uw INNER JOIN us_user uu ON uw.user_id = uu.user_id ORDER BY uw.wallet_balance DESC ) tmp, (SELECT @r := 0, @last := 0) r;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出如下:
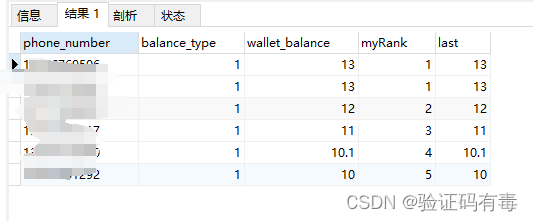
知识点剖析:
IF(expr1, expr2, expr3):这里用了一个跟之前不一样的函数,使用IF函数来决定排名@r的操作@last := tmp.wallet_balance AS last:使用这样的方式来记录上一次余额的情况
三、并列排行,开窗函数(Mysql8.0后才支持)
对于【二】中的问题,其实还可以用一个高级函数解决。不过这个在Mysql8.0之后才支持,有点蛋疼。这个东西用到了一个叫做【开窗函数】的东西。sql代码如下:
SELECT uu.phone_number, uw.balance_type, uw.wallet_balance, dense_rank() over(ORDER BY uw.wallet_balance DESC) myRank FROM us_wallet uw INNER JOIN us_user uu ON uw.user_id = uu.user_id ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出如下:
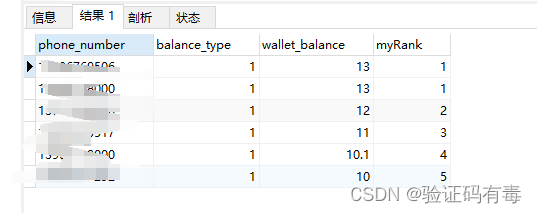
这里还有一个变种,如果需要的是跳跃的排名,那就把dense_rank改成rank函数,输出如下:
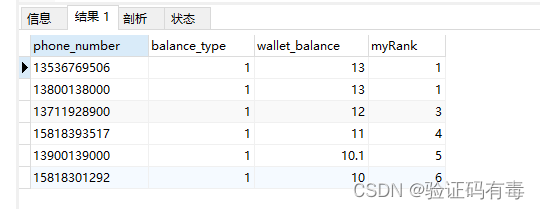
看看这两个图的区别,你就知道什么是【跳跃】了。四、开窗函数介绍
未完待续… 太晚了,该睡了
感谢
感谢大佬图图淘气的文章《mysql开窗函数》
-
相关阅读:
厚积薄发丨美格智能子公司众格智能荣获“张江之星”“闵行区企业技术中心”双项企业授牌
npm 无法将“npm”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。
操作系统实验二、进程和线程管理(Windows 2学时)多线程创建
ts面试题总结
Spring框架的两大核心IOC&DI
都是星光赶路人
用 Antlr 重构脚本解释器
暑期JAVA学习(37)定时器
eBPF Talk: 宏的两种写法
el-date-picker(日期时间选择)那些事
- 原文地址:https://blog.csdn.net/qq_32681589/article/details/132733084
