-
HashMap、LinkedHashMap、ConcurrentHashMap、ArrayList、LinkedList的底层实现。
HashMap、LinkedHashMap、ConcurrentHashMap、ArrayList、LinkedList的底层实现。
HashMap相关问题
1、你用过HashMap吗?什么是HashMap?你为什么用到它? 用过,HashMap是基于哈希表的Map接口的非同步实现, 它允许null键和null值,且HashMap依托于它的数据结构的设计 ,存储效率特别高,这是我用它的原因 2、你知道HashMap的工作原理吗?你知道HashMap的get()方法 的工作原理吗? 上面两个问题属于同一答案的问题 HashMap是基于hash算法实现的,通过put(key,value) 存储对象到HashMap中,也可以通过get(key)从HashMap中获取对象。 当我们使用put的时候,首先HashMap会对key的hashCode()的值 进行hash计算,根据hash值得到这个元素在数组中的位置, 将元素存储在该位置的链表上。当我们使用get的时候, 首先HashMap会对key的hashCode()的值进行hash计算, 根据hash值得到这个元素在数组中的位置,将元素从该位置上的链表中取出 3、当两个对象的hashcode相同会发生什么? hashcode相同,说明两个对象HashMap数组的同一位置上, 接着HashMap会遍历链表中的每个元素, 通过key的equals方法来判断是否为同一个key, 如果是同一个key,则新的value会覆盖旧的value, 并且返回旧的value。如果不是同一个key, 则存储在该位置上的链表的链头 4、如果两个键的hashcode相同,你如何获取值对象? 遍历HashMap链表中的每个元素,并对每个key进行hash计算, 最后通过get方法获取其对应的值对象 5、如果HashMap的大小超过了负载因子(load factor)定义的容量, 怎么办? 负载因子默认是0.75,HashMap超过了负载因子定义的容量, 也就是说超过了(HashMap的大小*负载因子)这个值, 那么HashMap将会创建为原来HashMap大小两倍的数组大小, 作为自己新的容量,这个过程叫resize或者rehash 6、你了解重新调整HashMap大小存在什么问题吗? 当多线程的情况下,可能产生条件竞争。当重新调整HashMap大小的时候, 确实存在条件竞争,如果两个线程都发现HashMap需要重新调整大小了, 它们会同时试着调整大小。在调整大小的过程中, 存储在链表中的元素的次序会反过来, 因为移动到新的数组位置的时候, HashMap并不会将元素放在LinkedList的尾部,而是放在头部, 这是为了避免尾部遍历(tail traversing)。 如果条件竞争发生了,那么就死循环了 7、我们可以使用自定义的对象作为键吗? 可以,只要它遵守了equals()和hashCode()方法的定义规则, 并且当对象插入到Map中之后将不会再改变了。 如果这个自定义对象时不可变的,那么它已经满足了作为键的条件, 因为当它创建之后就已经不能改变了。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
HashSet与HashMap区别
HashMap实现了Map接口 HashSet实现了Set接口 HashMap储存键值对 HashSet仅仅存储对象 HashMap使用put()方法将元素放入map中 HashSet使用add()方法将元素放入set中 HashMap中使用键对象来计算hashcode值 HashSet使用成员对象来计算hashcode值 HashMap比较快,因为是使用唯一的键来获取对象 HashSet较HashMap来说比较慢- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
HashTable与HashMap的区别
Hashtable方法是同步的 HashMap方法是非同步的 Hashtable基于Dictionary类 HashMap基于AbstractMap,而AbstractMap基于Map接口的实现 Hashtable中key和value都不允许为null,遇到null, 直接返回 NullPointerException HashMap中key和value都允许为null,遇到key为null的时候, 调用putForNullKey方法进行处理,而对value没有处理 Hashtable中hash数组默认大小是11,扩充方式是old*2+1 HashMap中hash数组的默认大小是16,而且一定是2的指数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
LinkedHashMap的有序性
LinkedHashMap底层使用哈希表与双向链表来保存所有元素, 它维护着一个运行于所有条目的双向链表 (如果学过双向链表的同学会更好的理解它的源代码), 此链表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序 1.按插入顺序的链表:在LinkedHashMap调用get方法后, 输出的顺序和输入时的相同,这就是按插入顺序的链表, 默认是按插入顺序排序 2.按访问顺序的链表:在LinkedHashMap调用get方法后, 会将这次访问的元素移至链表尾部, 不断访问可以形成按访问顺序排序的链表。简单的说, 按最近最少访问的元素进行排序(类似LRU算法)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们可以通过例子来理解我们上面所说的LinkedHashMap的插入顺序和访问顺序
public static void main(String[] args) { Map<String, String> map = new HashMap<String, String>(); map.put("apple", "苹果"); map.put("watermelon", "西瓜"); map.put("banana", "香蕉"); map.put("peach", "桃子"); Iterator iter = map.entrySet().iterator(); while (iter.hasNext()) { Map.Entry entry = (Map.Entry) iter.next(); System.out.println(entry.getKey() + "=" + entry.getValue()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上面是简单的HashMap代码,通过控制台的输出,我们可以看到HashMap是没有顺序的
banana=香蕉
apple=苹果
peach=桃子
watermelon=西瓜我们现在将HashMap换成LinkedHashMap,其他代码不变
Map<String, String> map = new LinkedHashMap<String, String>();- 1
看一下控制台的输出
apple=苹果
watermelon=西瓜
banana=香蕉
peach=桃子我们可以看到,其输出顺序是完成按照插入顺序的,也就是我们上面所说的保留了插入的顺序。下面我们修改一下代码,通过访问顺序进行排序。
public static void main(String[] args) { Map<String, String> map = new LinkedHashMap<String, String>(16,0.75f,true); map.put("apple", "苹果"); map.put("watermelon", "西瓜"); map.put("banana", "香蕉"); map.put("peach", "桃子"); map.get("banana"); map.get("apple"); Iterator iter = map.entrySet().iterator(); while (iter.hasNext()) { Map.Entry entry = (Map.Entry) iter.next(); System.out.println(entry.getKey() + "=" + entry.getValue()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
代码与之前的相比
1.替换了LinkedHashMap的构造函数,使用三个参数的构造函数,第三个参数传进true就是表明用访问顺序来排序,默认是false(即插入顺序)
2.增加了两句LinkedHashMap的get方法,来表示最近已经访问过这两个元素了//修改的代码 Map<String, String> map = new LinkedHashMap<String, String>(16,0.75f,true); ...... map.get("banana"); map.get("apple");- 1
- 2
- 3
- 4
- 5
- 6
看一下控制台的输出结果
watermelon=西瓜
peach=桃子
banana=香蕉
apple=苹果我们可以看到,顺序是先从最少访问的元素开始遍历(西瓜、桃子),而香蕉、苹果是因为分别调用了get方法,香蕉是最先访问的,所以它的比苹果更少用一些。这也就是我们之前提到过的,LinkedHashMap可以选择按照访问顺序进行排序
LinkedHashMap与HashMap的区别
LinkedHashMap有序的,有插入顺序和访问顺序
HashMap无序的LinkedHashMap内部维护着一个运行于所有条目的双向链表
HashMap内部维护着一个单链表什么是ArrayList
ArrayList可以理解为动态数组,它的容量能动态增长,该容量是指用来存储列表元素的数组的大小,随着向ArrayList中不断添加元素,其容量也自动增长
ArrayList允许包括null在内的所有元素
ArrayList是List接口的非同步实现
ArrayList是有序的ArrayList实现了List接口、底层使用数组保存所有元素,其操作基 本上是对数组的操作 ArrayList继承了AbstractList抽象类,它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能 ArrayList实现了RandmoAccess接口,即提供了随机访问功能,RandmoAccess是java中用来被List实现,为List提供快速访问功能的,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问 ArrayList实现了Cloneable接口,即覆盖了函数clone(),能被克隆 ArrayList实现了java.io.Serializable接口,意味着ArrayList支持序列化- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
什么是LinkedList
LinkedList基于链表的List接口的非同步实现
LinkedList允许包括null在内的所有元素
LinkedList是有序的
LinkedList是fail-fast的LinkedList与ArrayList的区别
LinkedList底层是双向链表
ArrayList底层是可变数组
LinkedList不允许随机访问, 即查询效率低 ArrayList允许随机访问,即查询效率高
LinkedList插入和删除效率快
ArrayList插入和删除效率低解释一下:
对于随机访问的两个方法,get和set,ArrayList优于LinkedList,因为LinkedList要移动指针
对于新增和删除两个方法,add和remove,LinedList比较占优势,因为ArrayList要移动数据什么是ConcurrentHashMap
ConcurrentHashMap基于双数组和链表的Map接口的同步实现
ConcurrentHashMap中元素的key是唯一的、value值可重复
ConcurrentHashMap不允许使用null值和null键
ConcurrentHashMap是无序的为什么使用ConcurrentHashMap
我们都知道HashMap是非线程安全的,当我们只有一个线程在使用HashMap的时候,自然不会有问题,但如果涉及到多个线程,并且有读有写的过程中,HashMap就会fail-fast。要解决HashMap同步的问题,我们的解决方案有
Hashtable
Collections.synchronizedMap(hashMap)
这两种方式基本都是对整个hash表结构加上同步锁,这样在锁表的期间,别的线程就需要等待了,无疑性能不高,所以我们引入ConcurrentHashMap,既能同步又能多线程访问ConcurrentHashMap的数据结构
ConcurrentHashMap的数据结构为一个Segment数组,Segment的数据结构为HashEntry的数组,而HashEntry存的是我们的键值对,可以构成链表。可以简单的理解为数组里装的是HashMap
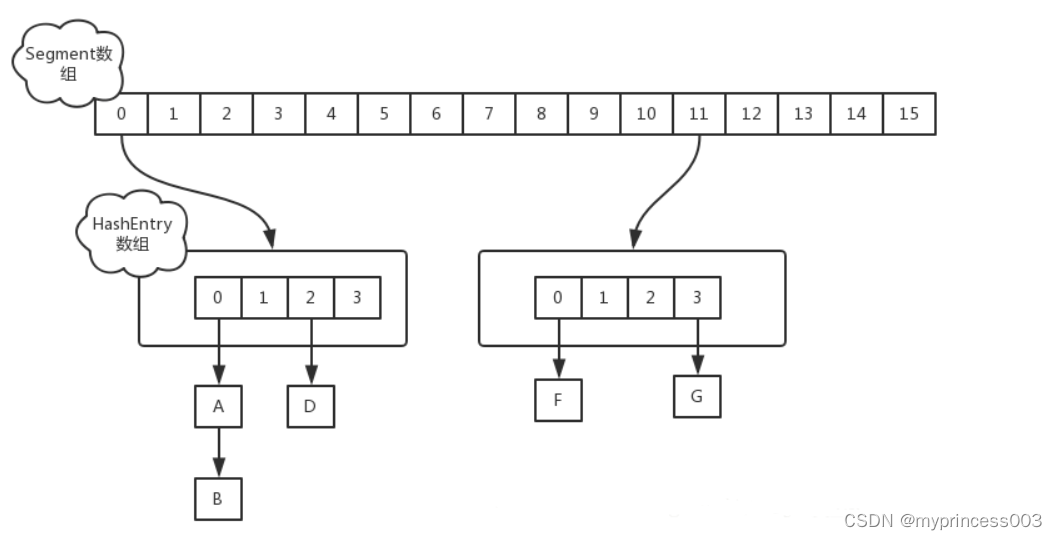
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment。正是因为其内部的结构以及机制,ConcurrentHashMap在并发访问的性能上要比Hashtable和同步包装之后的HashMap的性能提高很多。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作什么是Vector
Vector是基于可变数组的List接口的同步实现
Vector是有序的
Vector允许null键和null值
Vector已经不建议使用了Vector实现了List接口、底层使用数组保存所有元素,其操作基本上是对数组的操作
Vector继承了AbstractList抽象类,它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能
Vector实现了RandmoAccess接口,即提供了随机访问功能,RandmoAccess是java中用来被List实现,为List提供快速访问功能的,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问
Vector实现了Cloneable接口,即覆盖了函数clone(),能被克隆
Vector实现了java.io.Serializable接口,意味着ArrayList支持序列化Vector和ArrayList的区别
Vector同步、线程安全的
ArrayList异步、线程不安全Vector 需要额外开销来维持同步锁,性能慢
ArrayList 性能快Vector 可以使用Iterator、foreach、Enumeration输出
ArrayList 只能使用Iterator、foreach输出 -
相关阅读:
C认证笔记 - 计算机通识 - 多媒体基础参数
獲取Kinect的三維空間座標
零代码使用air32做USB转串口
SpringBoot + Redis + Token 解决接口幂等性问题,挑选最佳方案!
windows下的docker和Kubernetes安装
指针和数组试题解析(3)字符数组部分续集
工业web4.0UI风格超凡脱俗
5年经验之谈 —— App测试、Web测试和接口测试一般测试流程!
loT行业生死竞速:Aqara绿米得用户得天下
BiMPM实战文本匹配【上】
- 原文地址:https://blog.csdn.net/weixin_45817985/article/details/132649995