-
MySQL主从复制与读写分离
在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的。无论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的。因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。
主从复制
是指slave服务器复制master服务器的数据 的过程,可以保证数据完整性 。
MySQL的复制类型
1、基于语句的复制:在服务器上执行sql语句,在从服务器上执行同样的语句。
2、基于行的复制:把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
3、混合类型的复制:默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。
主从复制的架构
一主多备架构

总结:一般用来读写分离, master写,slave读,这种架构最大的问题“I/O” 压力集中在master 上,多台同步影响“I/O”。
M-S-S架构

总结:slave 中间 使用black-hole 存储引擎,不会把数据存储的磁盘,只记录在二进制日志当中。
M-M架构

总结:很多人误以为这样可以做mysql负载均衡,实际上没有好处,每个服务器需要同样的同步更新,破坏了事物的隔离性和数据的一致性。
主从复制的工作过程

1、当数据写入到master节点的数据库中,master节点会通知存储引擎提交事务,同时会将数据保存在二进制文件中。
2、slave节点会开启 I/O 线程,用于监听master的二进制日志的更新,一旦发生更新内容,则向master的dump线程发出同步请求。
3、master的dump线程在接收到salve的I/O请求后,会读取二进制日志文件中更新的数据,并发送给slave的I/O线程。
4、slave的I/O线程接收到数据后,会保存在slave节点的中继日志中。
5、同时,slave节点中的SQL线程,会读取中继日志中的数据,更新在本地的mysql数据库中。
主从复制延迟
主要原因有:
1、master服务器高并发,形成大量事务。
2、网络延迟。
3、主从硬件设备导致。
4、本来就不是同步复制、而是异步复制
解决方案:
从数据库优化Mysql参数。比如增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作。
从数据库使用高性能主机。包括cpu强悍、内存加大。避免使用虚拟云主机,使用物理主机,这样可以提升了i/o性能。
从数据库使用SSD磁盘。
网络优化,避免跨机房实现同步。
同步复制,半同步复制与异步复制
异步复制
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给客户端,并不关心从库是否已经接收并处理。
同步复制
指当master执行完一个事务,所有的从都完成同步数据,master就返回给客户端。
半同步复制
只要有一个从完成同步数据,master就返回给客户端。
相关命令
- Mysql主从服务器时间同步
- yum install ntp -y
- ntpdate ntp.aliyun.com
- 主服务器设置
- vim /etc/my.cnf
- server-id = 1
- log-bin=master-bin 添加,主服务器开启二进制日志
- binlog_format = MIXED
- log-slave-updates=true 添加,允许slave从master复制数据时可以写入到自己的二进制日志
- systemctl restart mysqld
- mysql -u root -p123456
- grant replication slave on * .* to 'root'@'192.168.11.%' identified by '123456';
- flush privileges;
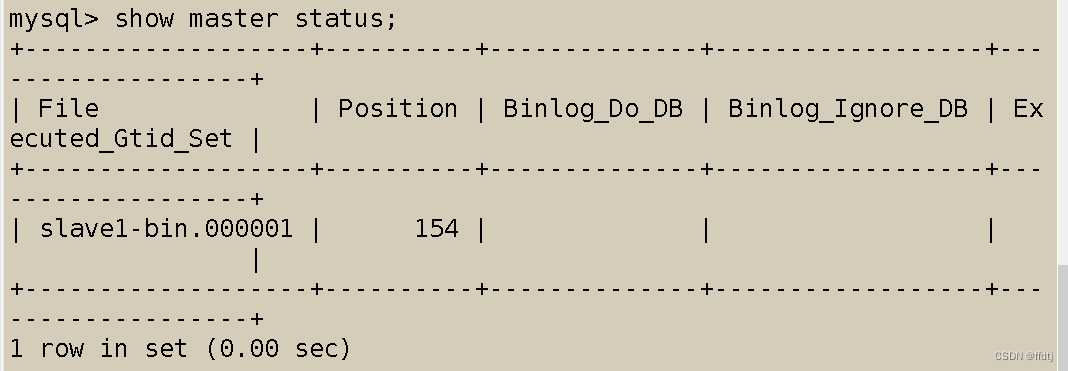
- show master status;
- 从服务器设置
- vim /etc/my.cnf
- server-id = 2 id要与Master的不同,两个Slave的id也要不同
- relay-log=relay-log-bin 添加,开启中继日志,从主服务器上同步日志文件记录到本地
- relay-log-index=slave-relay-bin.index
- 添加,定义中继日志文件的位置和名称,一般和relay-log在同一目录
- relay_log_recovery = 1
- systemctl restart mysqld
- mysql -u root -p123456
- change master to master_host='192.168.11.11',master_user='root',master_password='123456',master_log_file='master-bin.000001',master_log_pos=154;
- show slave status\G #查看 Slave 状态

当 Slave_IO_Running和Slave_SQL_Running都是YES时 ,表示主从同步状态成功。
排障
如果I/O不是yes,如何排查
首先排查网络问题,使用ping 命令查看从服务器是否能与主服务器通信。
再查看防火墙和核心防护是否关闭(增强功能)。
接着查看从服务slave是否开启。
两个从服务器的server-id 是否相同导致只能连接一台。
master_log_file master_log_pos的值跟master值是否一致。
读写分离
读写分离,基本的原理是让主数据库处理事务性增、改、删操作,而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
MySQL 读写分离原理
读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库 。
为什么要读写分离
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用。利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能。
所以读写分离,解决的是,数据库的写入,影响了查询的效率。
MySQL 读写分离形式
1、基于程序代码内部实现。
2、基于中间代理层实现(Amoeba,MySQL-Proxy等)。
进行读写分离
1、在主从复制的基础上进行
- Master 服务器:192.168.11.11 mysql5.7
- Slave1 服务器:192.168.11.44 mysql5.7
- Slave2 服务器:192.168.11.55 mysql5.7
- Amoeba 服务器:192.168.11.66 jdk1.6、Amoeba
- 客户端 服务器:192.168.11.66 mysql
2、 Amoeba服务器配置
- 安装 Java 环境
- cd /opt/
- cp jdk-6u14-linux-x64.bin /usr/local/
- cd /usr/local/
- chmod +x jdk-6u14-linux-x64
- ./jdk-6u14-linux-x64.bin
- mv jdk1.6.0_14/ /usr/local/jdk1.6
- vim /etc/profile
- export JAVA_HOME=/usr/local/jdk1.6
- export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
- export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
- export AMOEBA_HOME=/usr/local/amoeba
- export PATH=$PATH:$AMOEBA_HOME/bin
- source /etc/profile
- java -version
3、安装 Amoeba软件
- mkdir /usr/local/amoeba
- tar zxvf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
- chmod -R 755 /usr/local/amoeba/
- /usr/local/amoeba/bin/amoeba
- 如显示amoeba start|stop说明安装成功
4、授权
- 在Master、Slave1、Slave2的mysql上开放权限给Amoeba访问
- grant all on *.* to test@'192.168.11.%' identified by '123456';
5、配置amoeba服务
- cd /usr/local/amoeba/conf/
- cp amoeba.xml amoeba.xml.bak
- vim amoeba.xml
- --30行--
- <property name="user">amoeba</property>
- --32行--
- <property name="password">123456</property>
- --115行--
- <property name="defaultPool">master</property>
- --117-去掉注释-
- <property name="writePool">master</property>
- <property name="readPool">slaves</property>
6、修改数据库配置文件
- --23行--注释掉 作用:默认进入test库 以防mysql中没有test库时,会报错
- <!-- <property name="schema">test</property> -->
- --26--修改
- <property name="user">test</property>
- --29--去掉注释
- <property name="password">123456</property>
- --45--修改,设置主服务器的名Master
- <dbServer name="master" parent="abstractServer">
- --48--修改,设置主服务器的地址
- <property name="ipAddress">192.168.11.11</property>
- --52--修改,设置从服务器的名slave1
- <dbServer name="slave1" parent="abstractServer">
- --55--修改,设置从服务器1的地址
- <property name="ipAddress">192.168.11.44</property>
- --58--复制上面6行粘贴,设置从服务器2的名slave2和地址
- <dbServer name="slave2" parent="abstractServer">
- <property name="ipAddress">192.168.11.55</property>
- --65行--修改
- <dbServer name="slaves" virtual="true">
- --71行--修改
- <property name="poolNames">slave1,slave2</property>
7、启动服务
- /usr/local/amoeba/bin/amoeba start&
- netstat -anpt | grep java
- 查看8066端口是否开启,默认端口为TCP 8066
-
相关阅读:
一文讲透,商业智能BI未来发展趋势如何
GitHub | 在 GitHub 上在线展示 Vue 项目
docker容器化部署nginx php项目(步骤清晰简洁)
SpringBoot防Xss攻击
渗透测试-红队从资产收集到打点
linux中运行springboot jar包,内存占用多运行时报错
基于长短期神经网络铜期货价格预测,基于LSTM的铜期货价格预测,LSTM的详细原理
【Linux私房菜】—— 使用虚拟机时的几个小技巧
Spring Cache和Mysql主从复制
2021年数维杯数学建模A题外卖骑手的送餐危机求解全过程文档及程序
- 原文地址:https://blog.csdn.net/ffdtj/article/details/132707150
