-
宏观经济和风电预测误差分析(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录

💥1 概述
本文包括以下几个部分,然后用Matlab代码实现之。


准确预测的发展和估计在许多行业和日常生活中具有特殊的重要性。对于政治和经济来说,提前了解宏观经济发展情况以确定其战略是很重要的。作为投资者,预测市场走势或利率是至关重要的,而对于良好的能源供应管理,提前了解可再生能源的产出是必要的。例如,美国为数百万电力客户提供服务的Xcel Energy Inc.将其预测误差率降低了35%,从而实现了对煤炭和天然气发电厂更加高效的管理。迄今为止,这节省了超过6000万美元。(Xcel Energy Inc. 2017a; Xcel Energy Inc. 2017b)。
为了提高预测的准确性,获取有关预测误差的知识是有用的。尽管先前的研究主要集中在绩效评估和实际时间序列的统计特性上,但本文关注的是预测误差的统计特性。目标是找到预测误差的典型事实。典型事实是对常见统计特性的简化抽象,由Kaldor(1961)首次引入。Cont(2001)在资产回报的范围内将典型事实定义为在“许多工具、市场和时间段”中普遍存在的统计特性。转移到本文中,我们寻找在许多预测方法、行业和时间段中普遍存在的统计特性。此外,我们区分行业,因为可能存在仅在单个行业中普遍存在的特性。为了做到这一点,我们将收集时间序列的特征和特性,并寻找共同点。此外,本文介绍了协整和误差修正模型的原理,并将其归类为预测误差的典型事实的范畴。预测是利用现有信息对未来价值进行预测的过程。该过程包括对过去和现在的价值、趋势、季节效应等进行分析。
设yt表示最后一个可用值,yt+k|t表示预测值,那么时间段k被称为预测时段。换句话说,它是估计值和实际值之间的时间段。例如,提前24小时估计的预测值具有24小时的预测时段。随着预测时段的增加,预测过程变得更加复杂,因为在t时期可用的信息较少。
为了从预测误差中得出结论,了解预测是如何创建的很重要。我们介绍了一种直观的标准方法,并简要解释了实际预测的工作原理。
持续模型,也称为不变模型,是一种简单的方法,通常用作其他方法的基准模型。它也是几种预测误差度量的一部分。定义如方程1所示,其中yt+k|t表示预测值,yt表示最后一个实际值,k表示预测时段。
yt+k|t = yt (1)
简而言之,预测值就是最后一个实际值(B.-M. Hodge和Michael Milligan 2011)。
实际使用的预测模型通常是几种更复杂方法的组合。例如,风力预测模型通常与风速预测一起构建。德国输电系统运营商50Hertz使用来自各种研究机构的预测组合(50Hertz Transmission GmbH 2017)。在M3挑战赛和欧洲央行(ECB)的专业预测师调查中使用的一些预测方法包括自回归积分移动平均(ARIMA)模型、人工神经网络和指数平滑方法。
📚2 运行结果
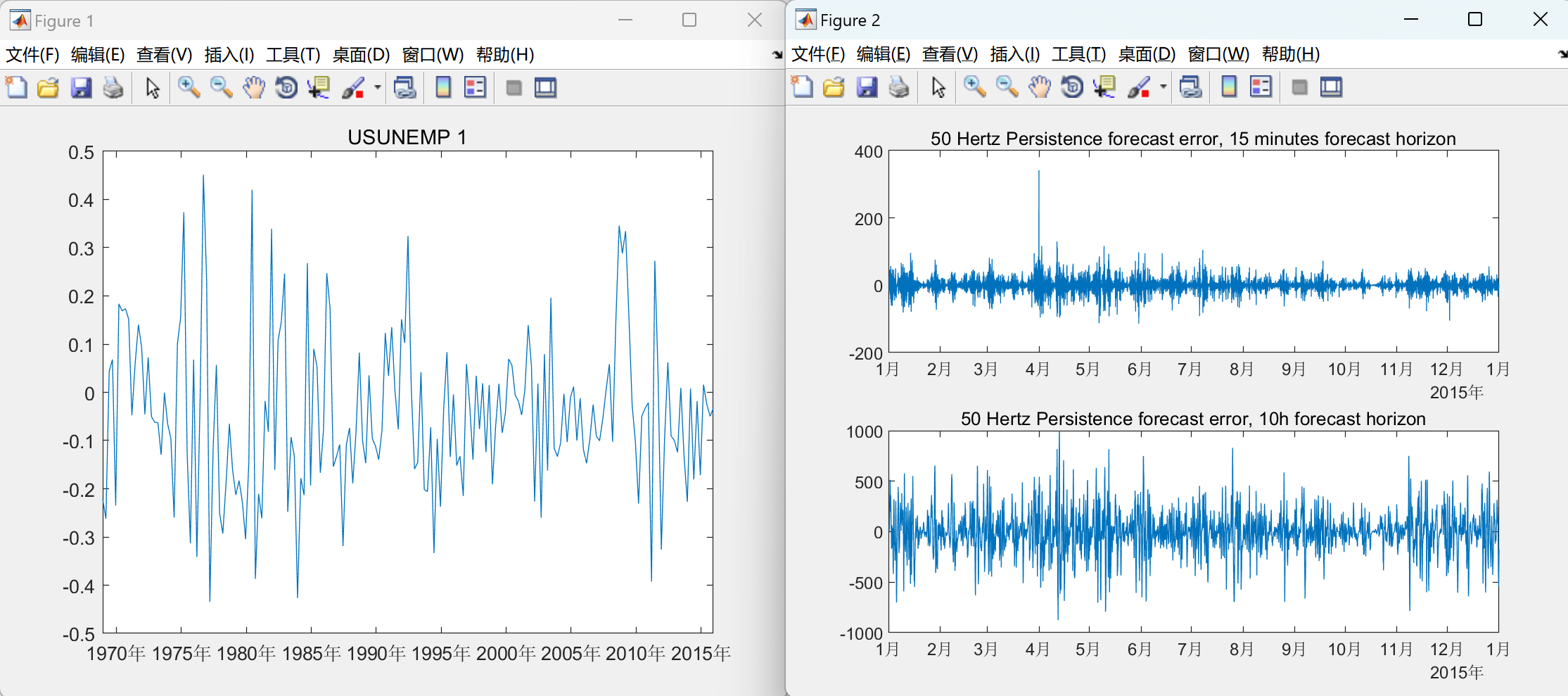
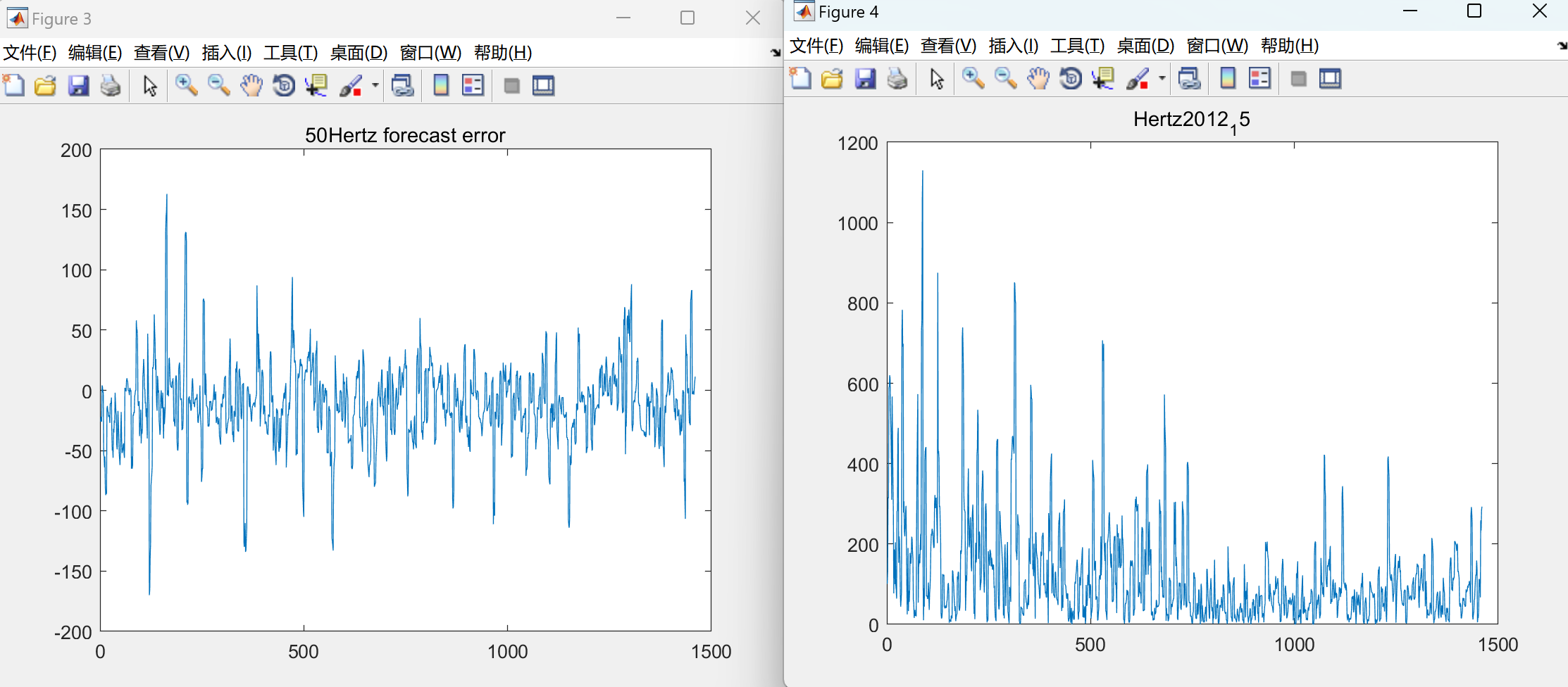



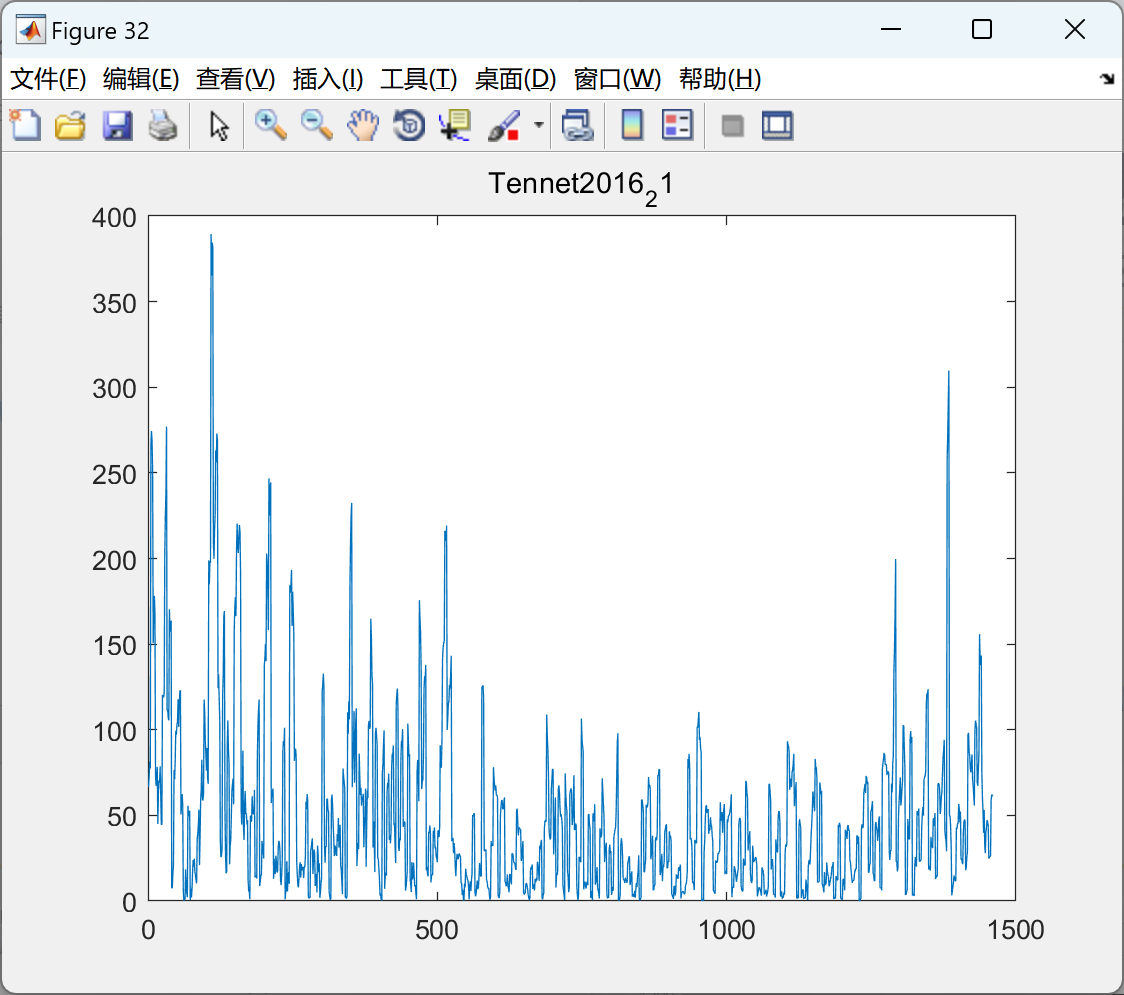
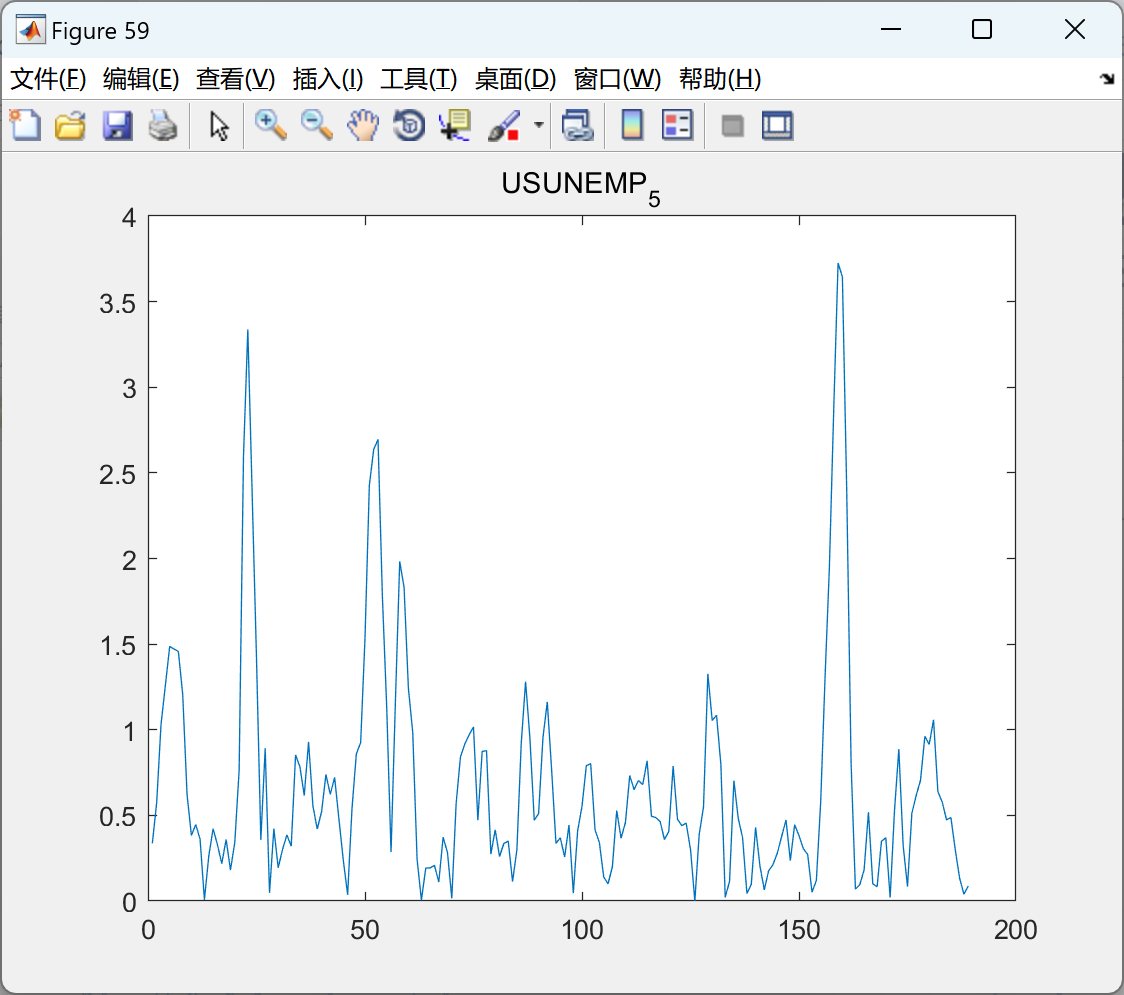
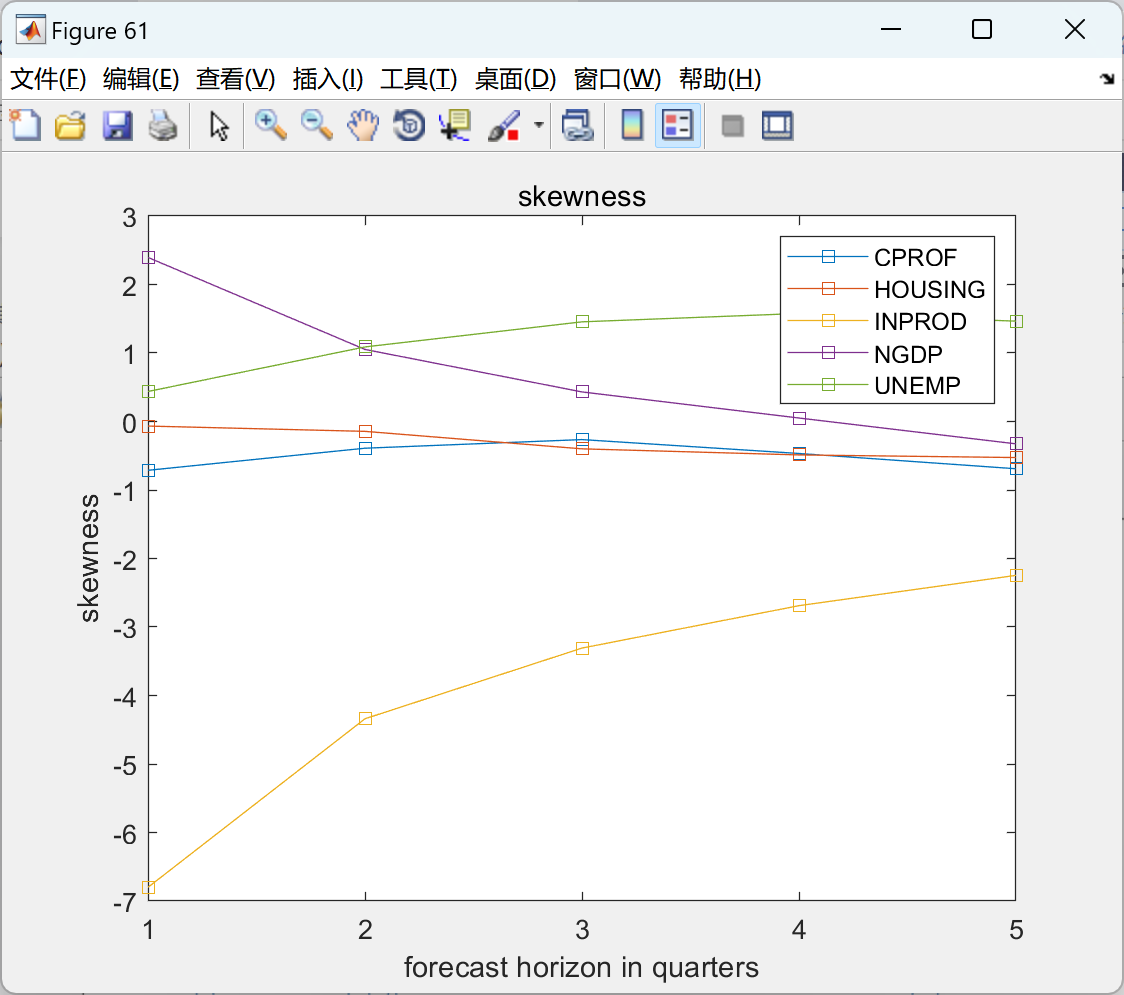


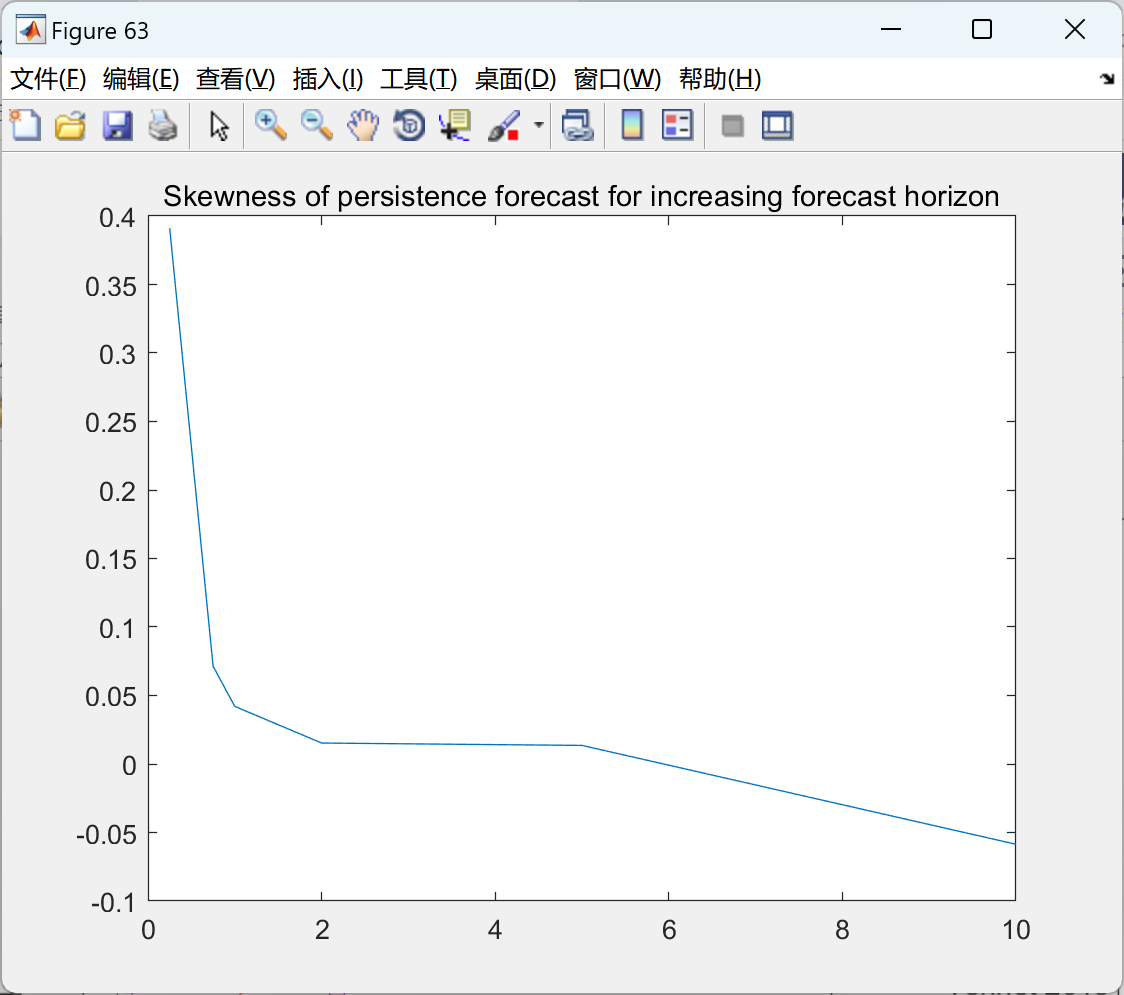
运行结果比较多,就不一一展示。
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。

🌈4 Matlab代码、数据、详细文章
-
相关阅读:
1200*B. Worms(简单杂题)
贪吃蛇游戏
毕设选题推荐基于python的django框架餐厅点餐订餐服务评价系统
JAVA多线程和JUC
华为eNSP配置防火墙策略
8、IOC 之容器扩展点
Spring Cloud Alibaba Sentinel 简单使用
Listener: 监听器
正则表达式
人文社科类夏校推荐合集
- 原文地址:https://blog.csdn.net/Yan_she_He/article/details/132565146