-
NIO原理浅析(二)
IO分类
阻塞和非阻塞
阻塞IO:用户空间引发内核空间的系统调用,需要内核IO操作彻底完成之后,返回值才会返回到用户空间,执行用户的操作。阻塞指的用户空间程序的执行状态,用户空间程序需要等到IO操作彻底执行完毕。java中,默认创建的socket是阻塞的。
非阻塞IO:用户空间引发内核空间的系统调用,不需要等待内核IO操作彻底完成,内核立即给用户返回一个返回值。用户空间程序继续执行用户的操作,处于非阻塞的状态。java中,设置非阻塞的IO,以socket为例,见如下所示的代码:
serverChannel = ServerSocketChannel.open() serverChannel.configureBlocking(false)- 1
- 2
有兴趣,也可以参考java中关于Socket这个类的文档
同步和异步
同步IO:用户空间和内核空间的调用发起方式。同步IO是指用户空间的线程是主动发起IO请求的一方,内核空间是被动接受方。
异步IO:用户空间和内核空间的调用发起方式。异步IO是指用户空间的线程是被动接受方,但是内核空间里面的kernel是主动发起IO请求的一方。
四种常见的IO模型
服务器端的编程需要构造高性能的IO模型,常见的IO模型有四类:
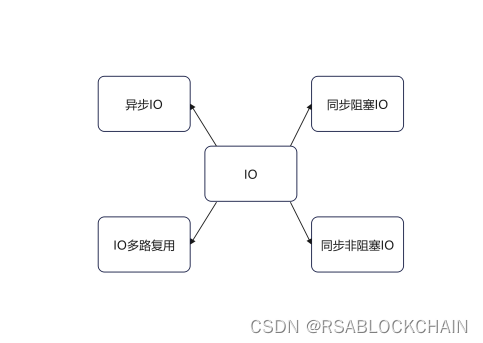
同步阻塞IO(Blocking IO):
结合上面的描述,同步阻塞IO指的是用户空间主动发起的调用,然后需要等待内核空间将IO操作彻底完成之后才会返回用户空间,这期间,用户空间线程将会处于阻塞状态。
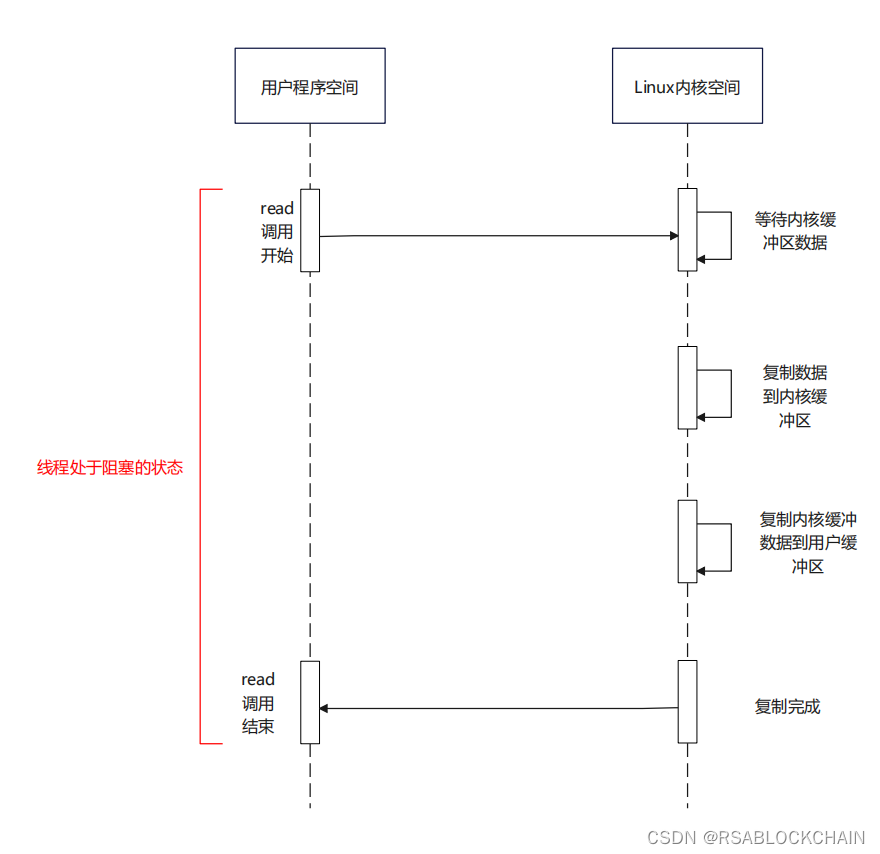
BIO优点: 程序简单,在阻塞等待数据的期间,用户挂起线程,用户线程基本不会占用CPU资源。
BIO缺点:每个请求可能会配置一套独立的线程,当并发量很高的场景下,内存和线程切换的成本很高。
应用举例:在Java中使用线程池的方式去连接数据库,就是使用的同步阻塞IO模型。
同步非阻塞IO(Non-blocking IO):
如果是socket被设置为non-blocking,NIO模型如果出现了系统调用,会出现以下两种情况:
(1)当内核缓存区里面没有数据,那么当用户空间发起的系统调用时,会立即返回一个失败的信息
(2)当内核缓存区里面有数据,那么当用户空间发起的系统调用时,会进入到阻塞状态,将内核缓存区里面的数据复制到用户缓冲区。直到数据返回成功,才会解除阻塞的状态。
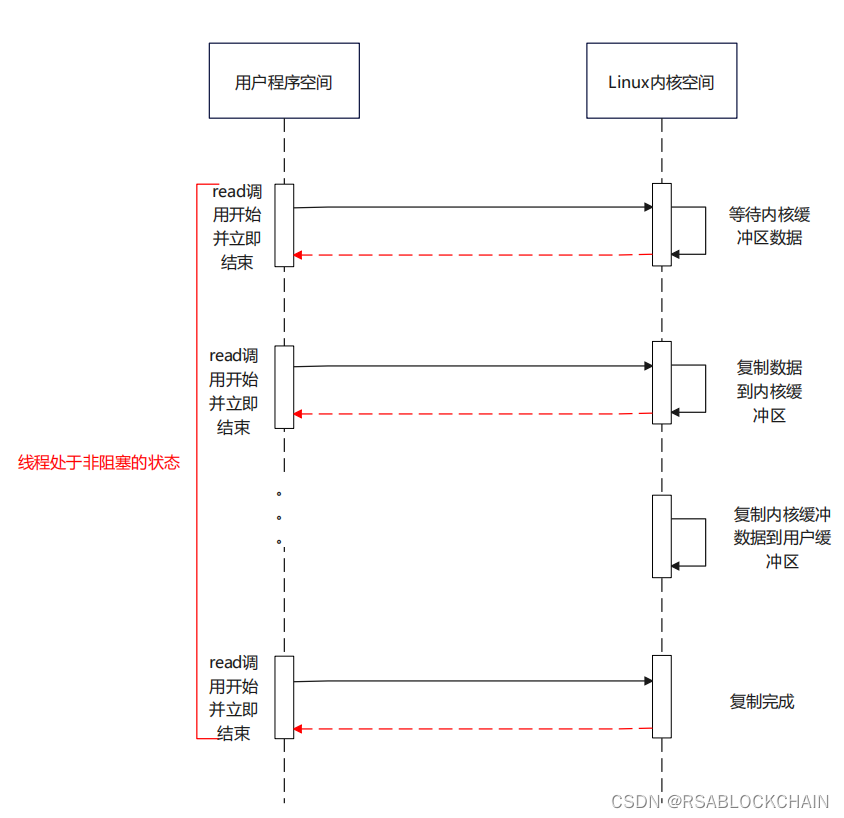
NIO的优点:每次发起IO系统调用,线程在内核等待缓冲区数据的时候,会立即返回值,不会阻塞。实时性比较好。
NIO的缺点:需要不断地轮询发起系统调用,这样会占用大量的CPU时间,资源利用率很低。
IO多路复用(IO Multiplexing)
首先从字面意思来理解多路复用:
-
多路: 多个socket网络连接
-
复用:复用一个线程,使用一个线程来检查多个文件套接字(又称文件句柄)的就绪状态
IO多路复用是一种同步IO模型,实现用一个线程监视多个文件句柄,一旦有文件句柄准备就绪,就可以通知应用程序进行相应的读写操作。没有文件句柄就绪,就会阻塞应用程序,然后交出CPU的时间片。
通过对之前两种IO模型的总结,我们可以发现:
针对高并发的场景,同步阻塞模型的缺点是需要做频繁的内存和线程的切换,效率很低。同步非阻塞的缺点是要在用户程序空间轮询的发起系统调用,这导致内核态和用户态的频繁切换,也会消耗大量的资源。
IO多路复用则可以避免内核态和用户态的频繁切换,因为IO多路复用模型将轮询套接字(又称为文件句柄)的动作,直接放在了内核态进行,这样避免了内核态和用户态的频繁切换
举例说明
我们以基础的socket模型为例,展现IO多路复用的机制:
下面是基础的socket模型伪码:
listenSocket = socket(); //系统调用socket()函数,调用创建一个主动socket bind(listenSocket); //给主动socket绑定地址和端口 listen(listenSocket); //将默认的主动socket转换成服务器使用的被动socket(也叫监听socket) while(true) { //循环监听客户端的连接请求 connectSocket = accept(listenSocket); //接受客户端连接,获取已连接socket recv(connSocket); //从客户端读取数据,只能同时处理一个客户端 send(connSocket); //给客户端返回数据,只能同时处理一个客户端 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
网络通信的流程如下图所示:
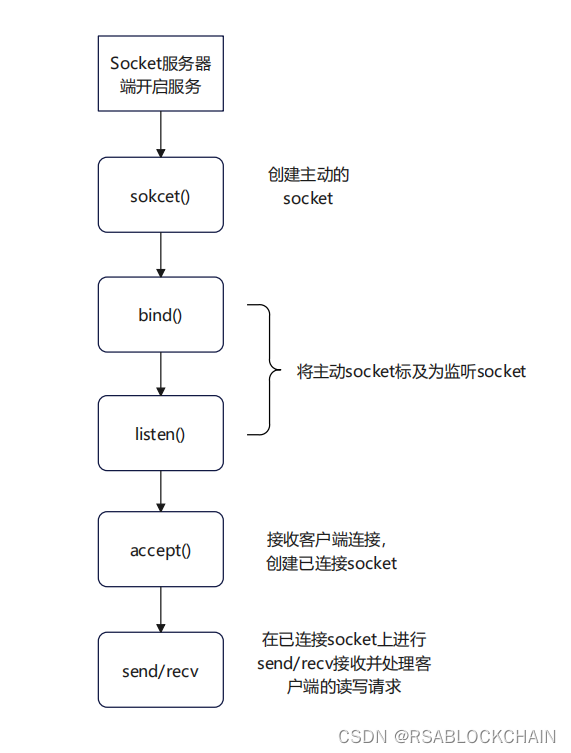
上图所示的socket网络通信,是典型的同步阻塞模型,当有大量客户端连接时,这种模型的处理性能比较差。使用IO多路复用可以解决这种困境。
linux中,操作系统提供了select、poll和epoll三种多路复用机制。
select机制
四个问题
1、IO多路复用可以最多监听多少个socket?
2、IO多路复用可以监听socket里面的哪些事件?
3、IO多路复用如何感知已经就绪的文件描述符fd?
4、IO多路复用如何实现网络通信?
首先在linux平台上查看一下select函数定义,可以参考一下文章1Linux内核select源码剖析 、文章2Linux select源码分析。
/** * 参数说明 * 监听的文件描述符数量 __nfds * 被监听描述符的三个集合*__readfds, *__writefds 和 *__exceptfds * 监听时阻塞等待的超时时长*__timeout * 返回值:返回一个socket对应的文件描述符 */ int select(int __nfds, fd_set * __readfds, fd_set * __writefds, fd_set * __exceptfds, struct timeval * __timeout)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
select函数监听的文件描述符被分成三类,分别是__readfds, __writefds 和 __exceptfds,当用户调用select时,假设当前监控的是___readfds集合,select操作会将需要监控___readfds集合从用户空间拷贝到内核空间,随后在内核空间一直遍历自身的skb(SocketBuffer),检查每个skb的poll逻辑,已确定socket是否存在可读事件。若没有socket可读,则会进入到睡眠状态。当发现有sokcet可读,则会唤醒用户空间的程序,然后在用户态去遍历监控的集合,并读取数据。
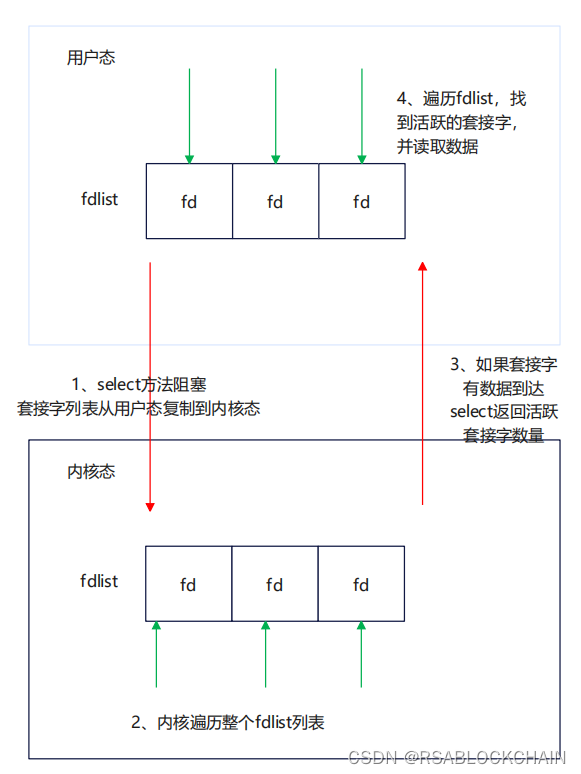
select 多路复用方法存在的缺陷:
1、调用select需要将套接字列表从用户态复制到内核态,对于多并发场景,资源消耗量比较大。
2、能监听的端口号的数量有限制,FD_SETSIZE,32位机器限制1024个套接字,64位机器限制2048个套接字。
3、被监控的fdlist列表,如果有一个套接字数据可读,业务就需要遍历一遍用户态的fdlist列表,时间复杂度O(n)。
poll
相较于select,poll优化了select的缺陷二,使用的是动态数组结构,而不是select的bitMap结构,突破了1024的限制,但是poll也没有解决缺陷1和缺陷3,仍然存在用户态到内核态的套接字复制而导致的资源消耗过大的问题。
-
相关阅读:
文件真实类型识别 - linux c file
spring MVC源码探索之AbstractHandlerMethodMapping
NVIDIA全息VR显示专利:内含多种光学方案
【微服务】SpringCloud轮询拉取注册表及服务发现源码解析
VUE~富文本简单使用~tinymce
Spring Boot : ORM 框架 JPA 与连接池 Hikari
docker 映射端口穿透内置防火墙
智慧社区管理系统03(用户列表增删查改)
场景应用:Spring容器是一个什么样的概念?有什么作用?应用上下文呢?
Oracle-性能优化篇-分区表
- 原文地址:https://blog.csdn.net/sinat_28199083/article/details/132586683