-
【Linux从入门到精通】通信 | 管道通信(匿名管道 & 命名管道)

本派你文章主要是对进程通信进行详解。主要内容是介绍 为什么通信、怎么进行通信。其中本篇文章主要讲解的是管道通信。希望本篇文章会对你有所帮助。
文章目录
🙋♂️ 作者:@Ggggggtm 🙋♂️
👀 专栏:Linux从入门到精通 👀
💥 标题:管道通信💥
❣️ 寄语:与其忙着诉苦,不如低头赶路,奋路前行,终将遇到一番好风景 ❣️
一、进程通信简单介绍
1、1 什么是进程通信
进程通信是指不同进程之间进行数据交换、消息传递和协作的过程。在操作系统中,每个进程都是独立运行的单位,它们拥有各自的内存空间和执行环境。为了实现进程之间的互动和合作,需要通过进程通信来进行数据共享、状态同步、任务协作等操作。
我们知道进程都是独立的,各自有各自的地址空间。而进程通信的本质是让不同的进程能够看到同一块“内存”。而这块内存并不属于任何一个进程,是所有进程共享的。
1、2 为什么要进行通信
我们之前学习的都是单进程。单进程不能使用并发能力,更无法实现多进程协同。下面给出需要进程通信的原因:
-
数据共享和传递:不同的进程可能需要共享数据,例如一个进程产生的结果可能需要被其他进程使用。通过进程间通信,可以实现数据的传递和共享,让不同的进程能够获取彼此的数据,并保持数据的一致性。
-
任务协作和协调:在复杂的应用程序中,多个进程往往需要协同工作完成某个任务。通过进程间通信,进程可以互相发送消息和指令,协调彼此的行动,实现任务的划分、分工和协作。
-
资源共享和管理:在计算机系统中,各个进程需要共享有限的资源,如内存、文件、设备等。进程间通信能够确保多个进程正确地访问和管理共享资源,避免冲突和资源浪费。
-
进程控制和同步:进程间通信提供了一种机制,使得进程能够进行进程间的控制和同步操作。例如,一个进程可能需要等待另一个进程完成某个任务后才能继续执行,通过进程间通信,可以实现进程的阻塞和唤醒,实现进程的协调。
1、3 进程通信的方式
常见的进程通信方法包括以下几种:
-
管道(Pipe):管道提供了一种半双工的、单向的通信机制,通常用于具有父子关系的进程之间进行通信。
-
消息队列(Message Queue):消息队列是一种使用消息缓冲区进行通信的形式,进程可以把消息发送到队列中,然后其他进程从队列中读取消息。
-
共享内存(Shared Memory):共享内存是一种将一块内存区域映射到多个进程的机制,多个进程可以直接访问这块共享内存,实现高效的数据共享。
-
信号量(Semaphore):信号量是一种用于进程之间同步和互斥的机制,可以通过提供一个计数器,控制多个进程对共享资源的访问。
管道通信又分为匿名管道和命名管道通信。本篇文章讲解的重点就是管道通信。
二、匿名管道
2、1 什么是管道
在Linux中,管道是一种用于进程间通信的特殊文件。它可以连接一个进程的输出到另一个进程的输入,实现数据的传输和共享。管道通信是一种基于管道的进程间通信方式。
举一个具体的例子来解释一下如何使用管道和进行管道通信:假设有两个命令,command1和command2,我们希望将command1的输出传递给command2进行处理。首先,我们可以使用管道符号
|将这两个命令连接起来。具体如下:command1 | command22、2 匿名管道通信
匿名管道顾名思义:没有名字的管道。匿名管道只能在具有亲缘关系的进程间使用,通常用于父进程和子进程之间进行通信。我们上面了解了管道是一个文件,文件不都是有名字的吗?在磁盘上的文件都是有名字的。但是匿名管道并不是在磁盘上,而是在内存中存储。需要注意的是,匿名管道的数据是临时存储在内存中的,而不是永久保存在磁盘上。当相关的进程结束时,管道和其中的数据也会被释放,不会留下任何痕迹。那我们接下来看看是怎么进行通信的。
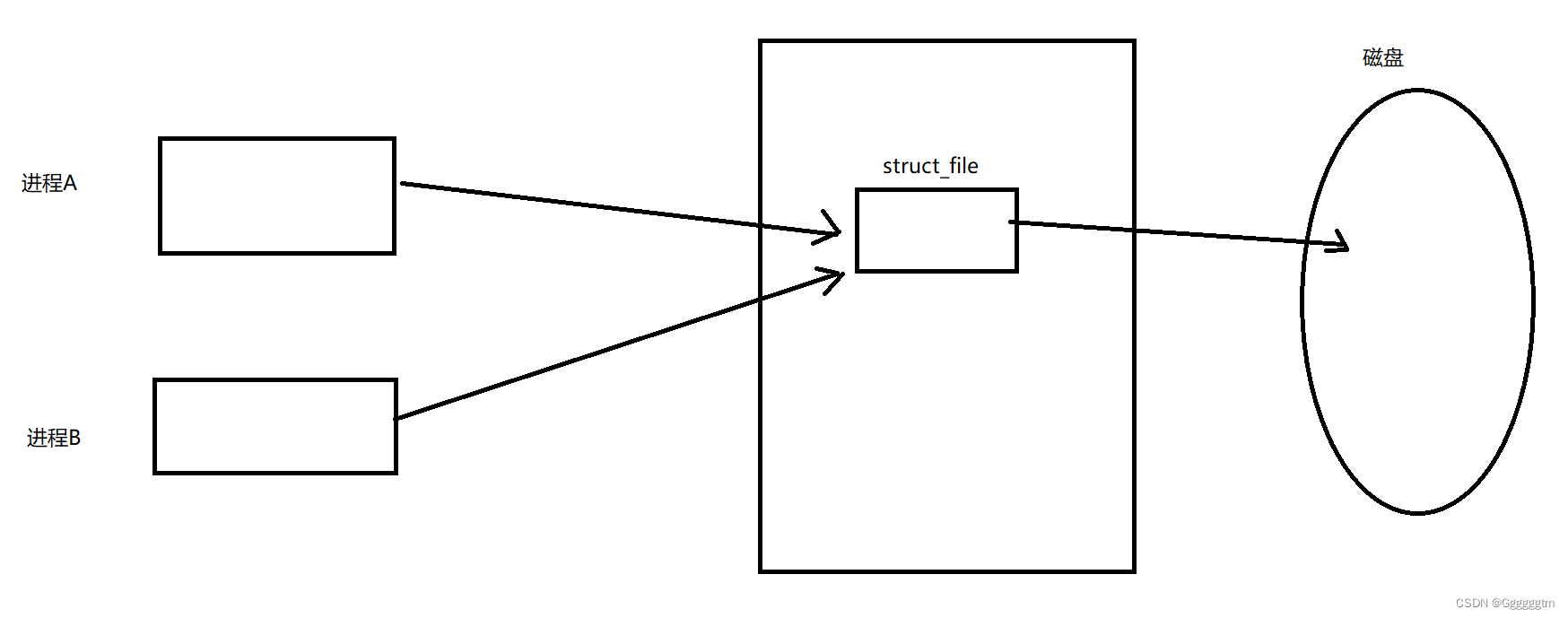
管道通信本质上就是进程通信。也可以理解为进程通信的手段是利用了管道。我们创建一个进程,以读写的形式打开一个文件。具体如下图:
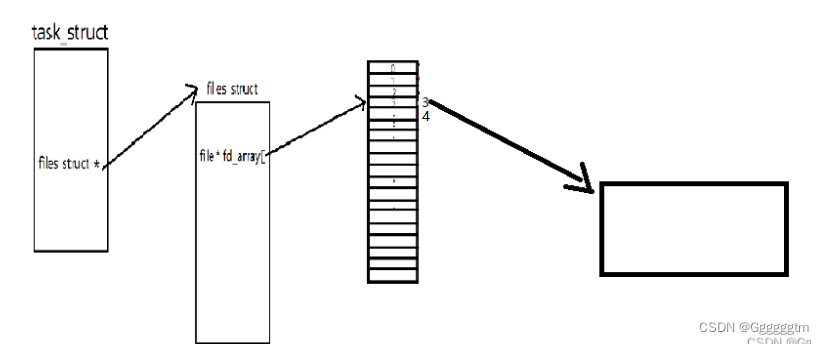
然后我们再创建一个子进程。我们知道子进程会继承父进程的相关代码个数据结构的。创建完子进程后,具体如下图:
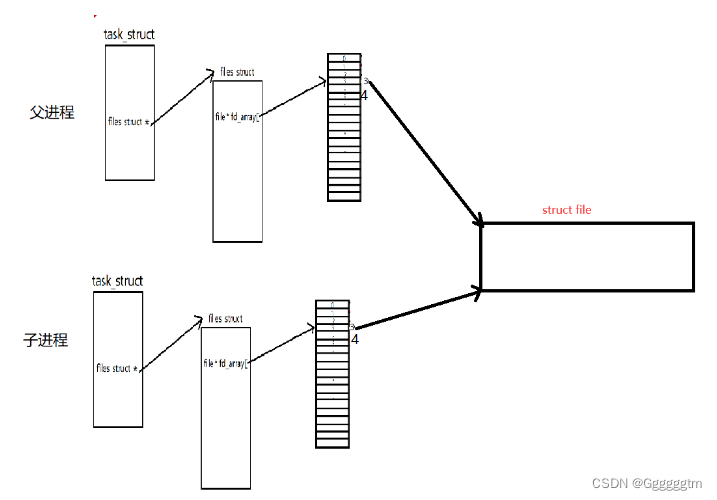
我们知道相关的数据结构会继承,但是文件也会被继承吗(就是所指向的文件也会被拷贝一份吗)?并不会的。这时候不就是让不同的进程看到了同一块内存资源吗!!!管道是单向通信的机制。然后我们再关闭我们不需要的文件描述符(fd),不就是我们所说的管道吗!!!
从上述过程我们发现了, 创建匿名管道分为以下三个步骤:
- 分别以读写的方式打开同一个文件;
- fork()创建子进程;
- 父子进程各自关闭自己不需要的文件描述符(fd)。
下面我们不妨模拟一下管道通信,是我们的理解更加深刻。
2、3 管道通信 demo代码
2、3、1 pipe 创建管道
我们怎么同时以读写的方式打开一个文件呢?可以利用一个系统调用函数:pipe。
pipe函数是一种创建管道的系统调用。它被用于在进程间进行通信,使得一个进程的输出能够直接成为另一个进程的输入。我们来看一下pipe函数的使用。
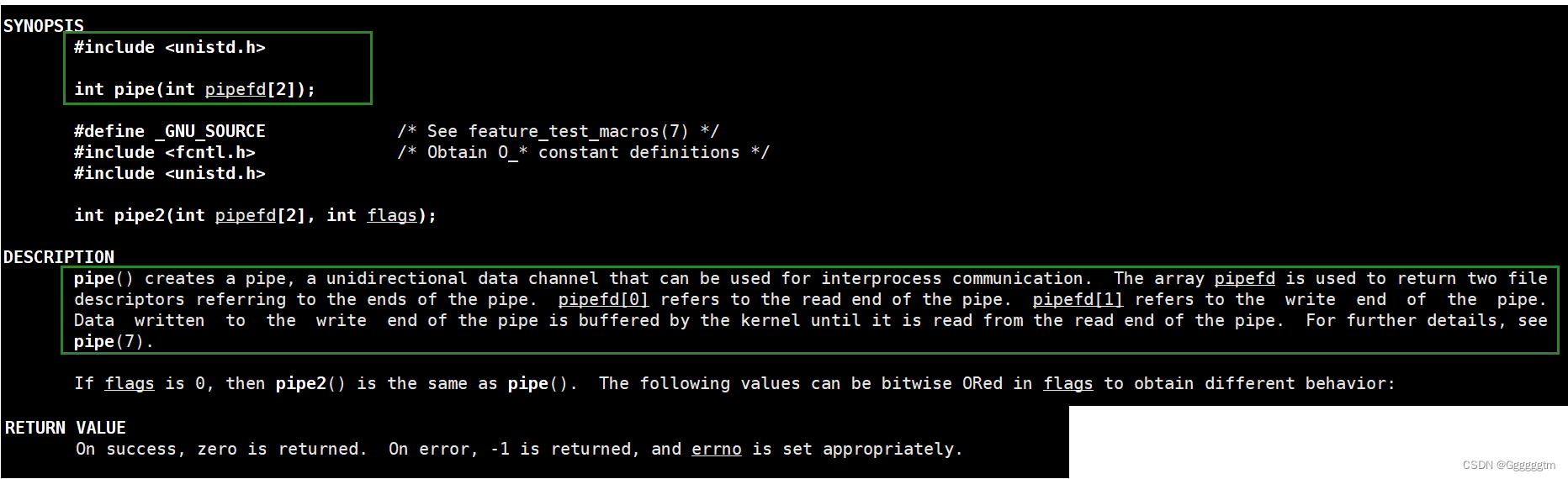
参数 pipefd[2] 是输出型参数。调用成功后,会将所打开文件的读端、写端的文件描述符写入该数组。pipefd[0]用于读取管道数据,pipefd[1]用于写入管道数据。我们不妨来测试一下pipefd 数组中是否获得了所打开文件的文件描述符。代码如下:
- #include
- #include
- #include
- using namespace std;
- int main()
- {
- int pipefd[2];
- int n=pipe(pipefd);
- assert(n != -1);
- cout<< "pipefd[0] : "<cout<< "pipefd[1] : "<return 0;}
我们来看一下输出结果:

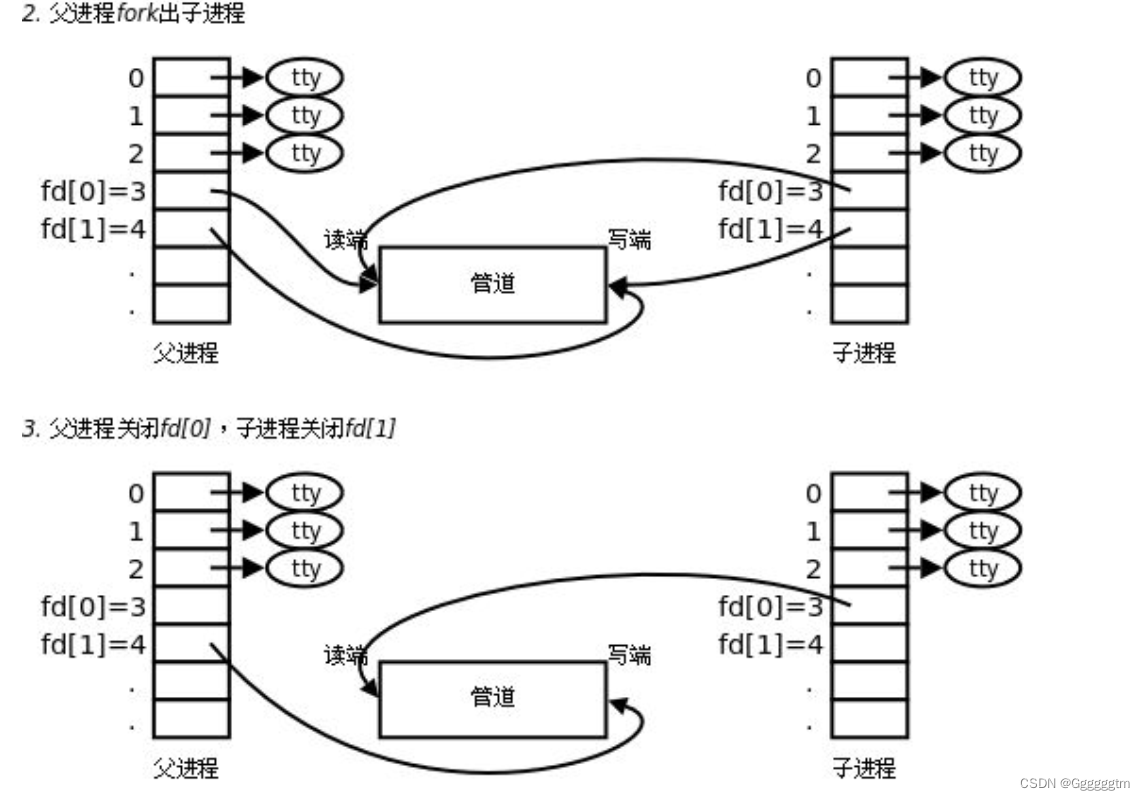
根据我们之前学的文件描述符章节,确实是将新打开的文件描述符写入了数组。加入我们是想要父进程写,子进程来读。那我们就可以让父子进程各自进行关闭对应的不需要的文件描述符了。具体结合下图理解:
2、3、2 demo 代码
对上述的了解后,我们大概知道了匿名管道通信的过程。那么下面我们看一下demo代码:
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- using namespace std;
- int main()
- {
- int pipefd[2]; //默认情况 pipefd[0]:读端口、pipefd[1]:写端口
- int n=pipe(pipefd);
- assert(n!=-1);
- (void)n;
- pid_t id=fork();
- assert(id!=-1);
- // 父写 子读
- if(id==0)
- {
- //子进程
- //构建单向通信管道,关闭不需要的端口
- close(pipefd[1]);
- char buffer[1024];
- while(true)
- {
- ssize_t s = read(pipefd[0],buffer,sizeof(buffer)-1);
- if(s > 0)
- {
- buffer[s]=0;
- cout << "child read successfully:[" << getpid() << "]<< Fatehr#" << buffer<}}close(pipefd[0]);exit(0);}//父进程close(pipefd[0]);string message="我是父进程,我正在发消息";int count=0;char send_buffer[1024];while(true){snprintf(send_buffer,sizeof(send_buffer),"%s[%d]:%d",message.c_str(),getpid(),count++);write(pipefd[1],send_buffer,strlen(send_buffer));sleep(1);}pid_t ret=waitpid(id,nullptr,0);assert(ret>0);(void)ret;close(pipefd[1]);return 0;}
我们对上述demo代码的思路进行解释:
-
首先包含了一些必要的头文件,包括输入输出流、进程管理和管道相关的系统调用等。然后定义了一个整型数组
pipefd,用于存储管道的读写端口。pipe(pipefd)创建了一个匿名管道,并将读端口和写端口的文件描述符存储在pipefd数组中。 -
接下来,通过
fork()函数创建了一个子进程。子进程执行的代码是在if(id==0)条件中(子进程),首先关闭了写端口pipefd[1],然后进入一个无限循环。在循环中,子进程通过read()函数从管道的读端口pipefd[0]读取数据。如果读取成功,就将读取到的数据存储在buffer中,并在控制台上打印输出。 -
在父进程中,首先关闭了读端口
pipefd[0](因为父进程不需要从管道中读取数据),然后进入一个无限循环。在循环中,父进程将包含有特定格式信息的字符串存储在send_buffer中,然后通过write()函数将send_buffer中的数据写入管道的写端口pipefd[1]。发送完毕后,父进程通过sleep(1)函数暂停1秒。 -
最后,父进程通过
waitpid()等待子进程结束,并关闭写端口pipefd[1]。整个程序执行完成后,返回0。总结:该程序利用了管道(pipe)实现了父子进程之间的单向通信。父进程向管道写入消息,子进程从管道读取消息并输出。
上述不过成就模拟出了父子进程通过匿名管道进行了数据交互,我们也称之为进程间通信。
2、4 匿名管道特点
我们接下来再总结一下管道的特点:
- 管道是用来进行具有血缘关系的进程进性进程间通信——常用于父子通信;
- 管道具有通过让进程间协同,提供了访问控制!
- 管道提供的是面向流式的通信服务——面向字节流——协议;
- 管道是基于文件的,文件的生命周期是随进程的,管道的生命周期是随进程的!
- 管道是单向通信的,就是半双工通信的一种特殊情况;
上述特点中说到管道提供了访问控制,什么是访问控制呢?就上述我们的管导通信 demo代码来说,父进程是每隔一秒向管到文件中写入一条数据。而子进程并没有进行休眠,是一直处于读的状态。那运行结果是什么情况呢?如下图:
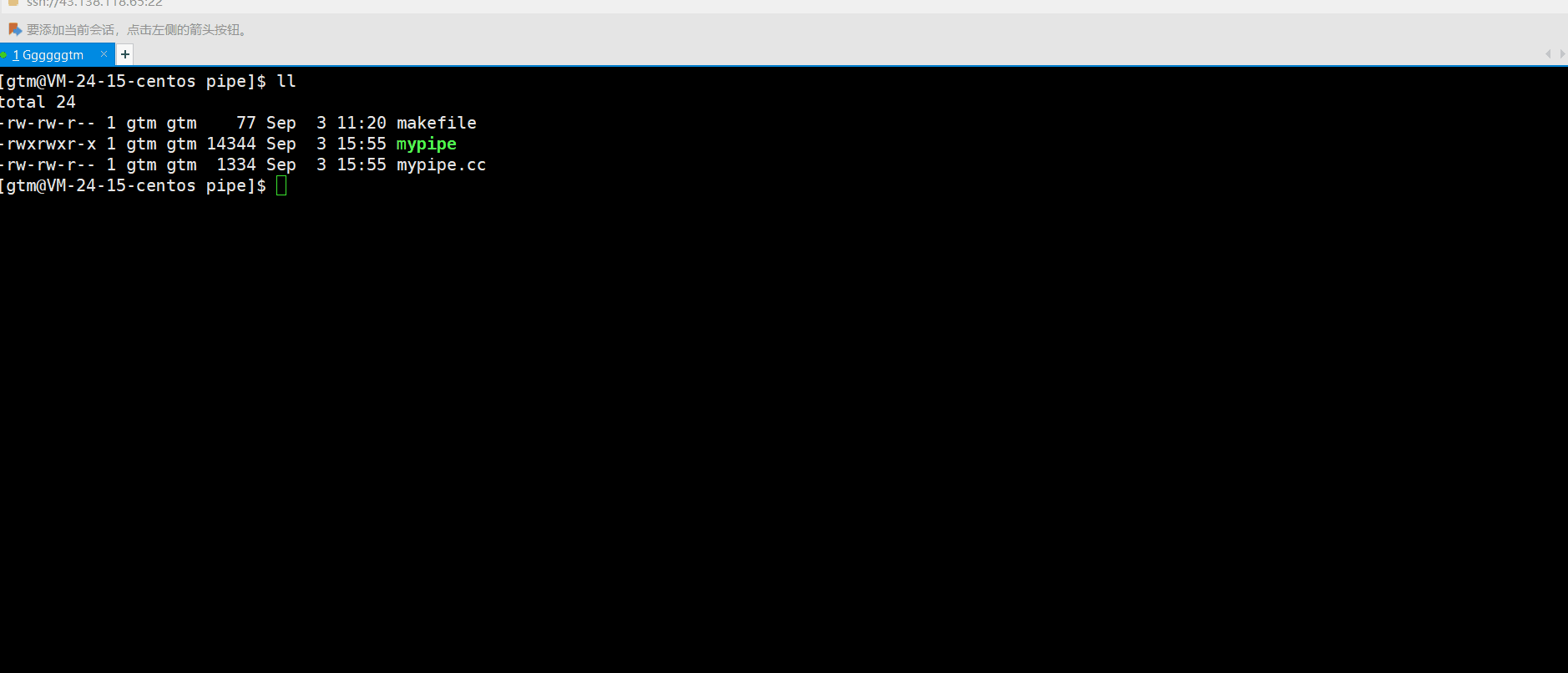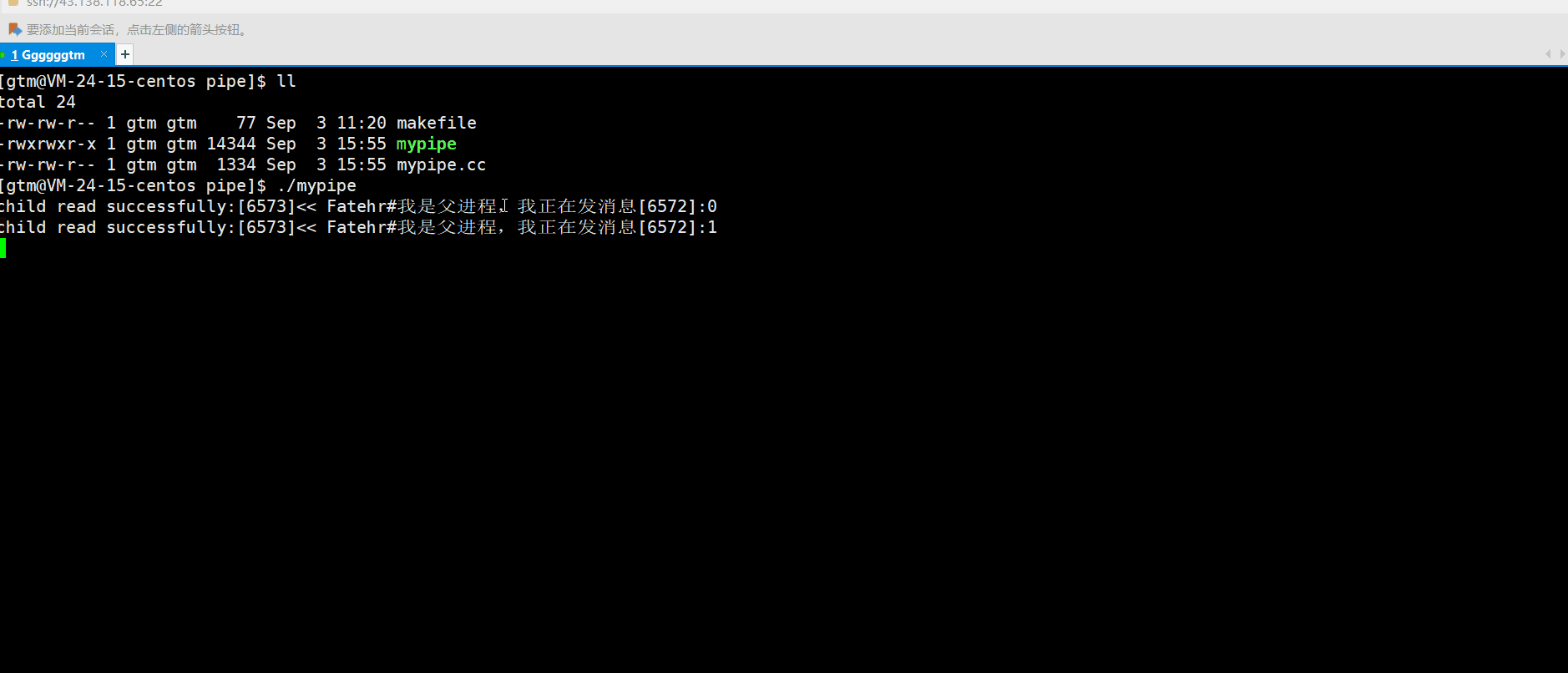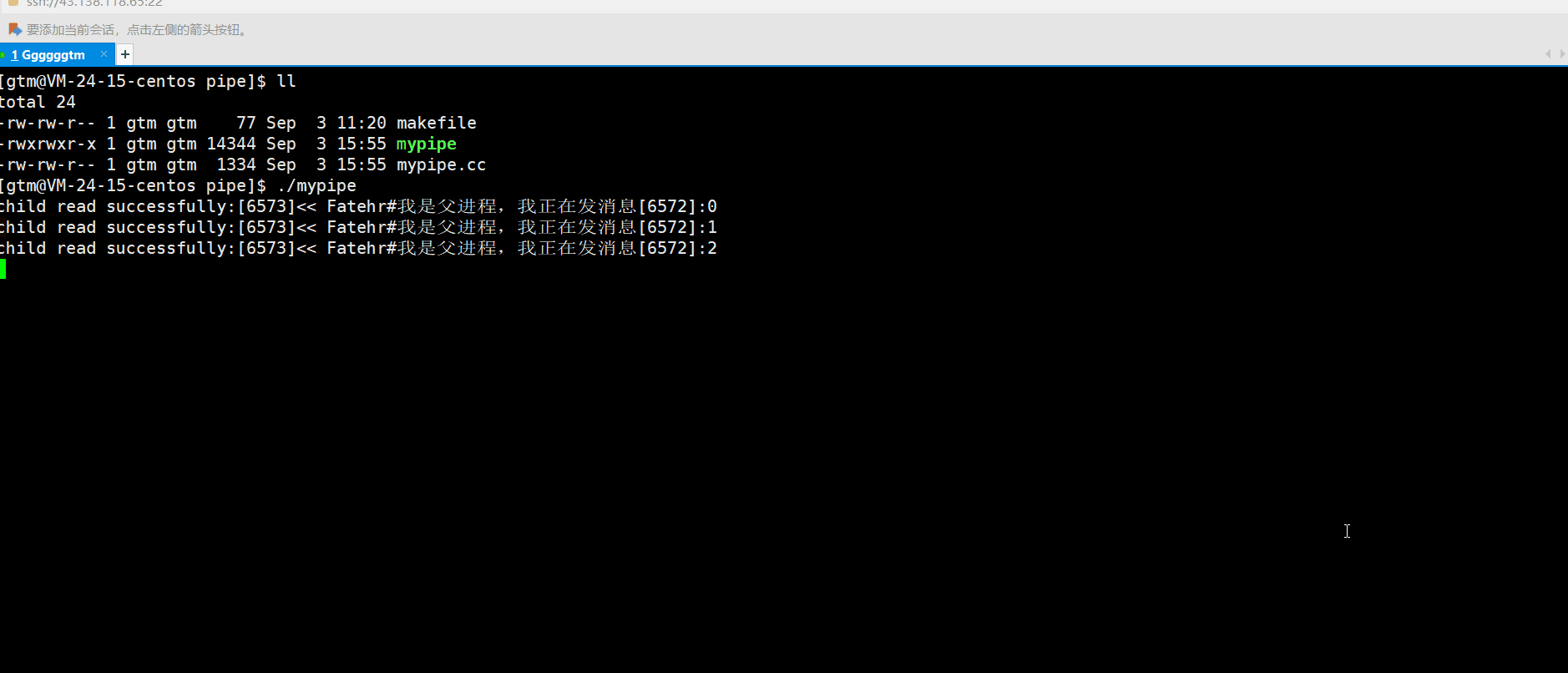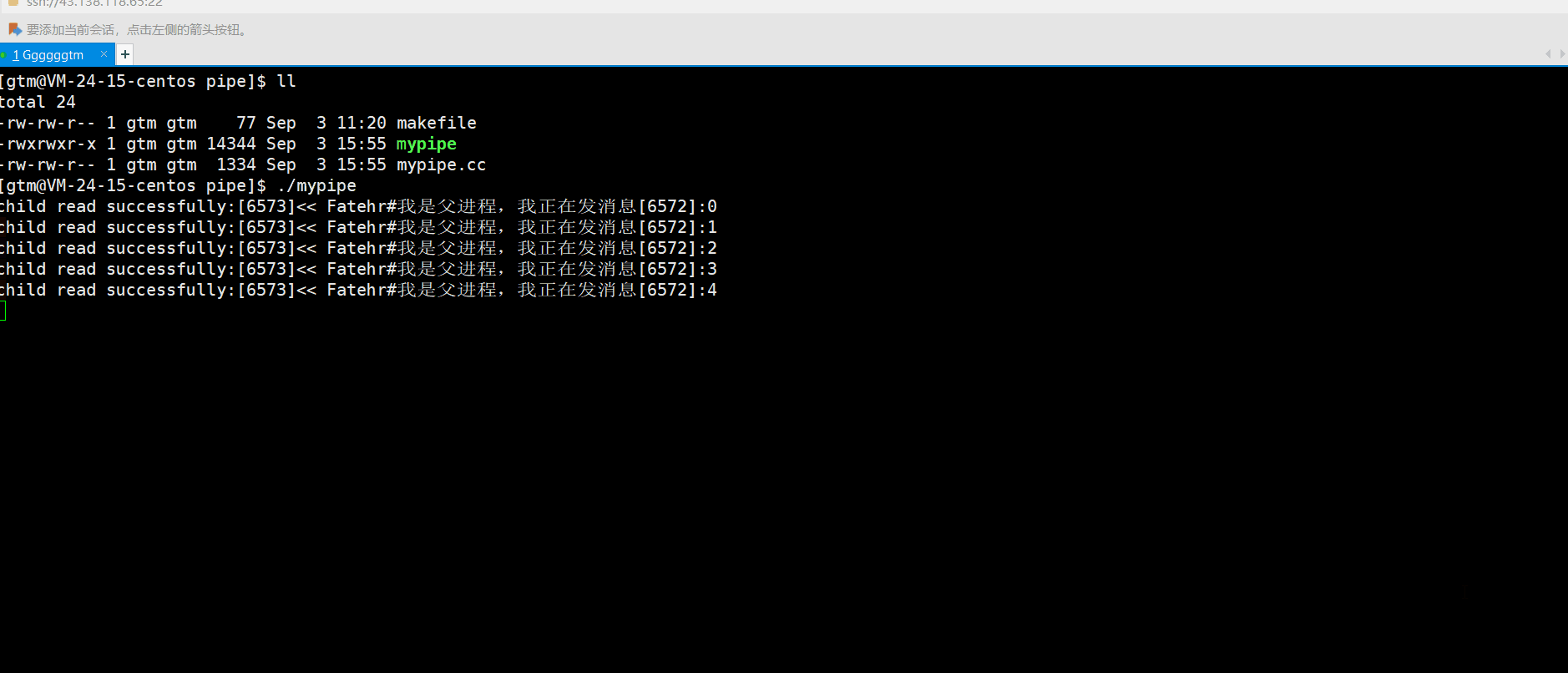
通过观察上述情况,我们也不难发现子进程也是没休眠一秒进程再读取数据,跟父进程的写数据是同步的。这是为什么呢?原因就是管道提供了访问控制。当管道没有数据时,读端就要进行等待,等待写端写入数据后再进行读取!!!我们接下来总结一下管道访问控制的特点:
- 写快,读慢,写满不能在写了;
- 写慢,读快,管道没有数据的时候,读必须等待;
- 写关,读0,标识读到了文件结尾;
- 读关,写继续写,OS终止写进程。
2、5 进程池
此小节是一个扩展,可以加强理解学习。我们知道一个进程可能会处理很多任务。但是一个父进程只能建立与其对应的唯一一个管道吗?其实并不是的。一个父进程可以建立多个子进程,那么对应的是不是就可以创建多个管道了!具体如下图:

那这样的话,我们父进程是不是就可以将任务派发个子进程来处理,这样是不是就可以提高了效率!我们接下来看一下我们上述所讲的 demo 代码。
2、5、1 Tasks.hpp
- #pragma once
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- typedef std::function<void()> func;
- std::vector
callbacks; - std::unordered_map<int, std::string> desc;
- void readMySQL()
- {
- std::cout << "sub process[" << getpid() << " ] 执行访问数据库的任务\n" << std::endl;
- }
- void execuleUrl()
- {
- std::cout << "sub process[" << getpid() << " ] 执行url解析\n" << std::endl;
- }
- void cal()
- {
- std::cout << "sub process[" << getpid() << " ] 执行加密任务\n" << std::endl;
- }
- void save()
- {
- std::cout << "sub process[" << getpid() << " ] 执行数据持久化任务\n" << std::endl;
- }
- void load()
- {
- desc.insert({callbacks.size(), "readMySQL: 读取数据库"});
- callbacks.push_back(readMySQL);
- desc.insert({callbacks.size(), "execuleUrl: 进行url解析"});
- callbacks.push_back(execuleUrl);
- desc.insert({callbacks.size(), "cal: 进行加密计算"});
- callbacks.push_back(cal);
- desc.insert({callbacks.size(), "save: 进行数据的文件保存"});
- callbacks.push_back(save);
- }
- void showHandler()
- {
- for(const auto &iter : desc )
- {
- std::cout << iter.first << "\t" << iter.second << std::endl;
- }
- }
- int handlerSize()
- {
- return callbacks.size();
- }
2、5、2 ProcessPool.cpp
- #include "Task.hpp"
- #define PROCESS_NUM 5
- using namespace std;
- int waitCommand(int waitFd, bool &quit) //如果对方不发,我们就阻塞
- {
- uint32_t command = 0;
- ssize_t s = read(waitFd, &command, sizeof(command));
- if (s == 0)
- {
- quit = true;
- return -1;
- }
- assert(s == sizeof(uint32_t));
- return command;
- }
- void sendAndWakeup(pid_t who, int fd, uint32_t command)
- {
- write(fd, &command, sizeof(command));
- cout << "main process: call process " << who << " execute " << desc[command] << " through " << fd << endl;
- }
- int main()
- {
- // 代码中关于fd的处理,有一个小问题,不影响我们使用,但是你能找到吗??
- load();
- // pid: pipefd
- vector
- // 先创建多个进程
- for (int i = 0; i < PROCESS_NUM; i++)
- {
- // 创建管道
- int pipefd[2] = {0};
- int n = pipe(pipefd);
- assert(n == 0);
- (void)n;
- pid_t id = fork();
- assert(id != -1);
- // 子进程我们让他进行读取
- if (id == 0)
- {
- // 关闭写端
- close(pipefd[1]);
- // child
- while (true)
- {
- // pipefd[0]
- // 等命令
- bool quit = false;
- // 等待任务派发
- int command = waitCommand(pipefd[0], quit); //如果对方不发,我们就阻塞
- if (quit)
- break;
- // 执行对应的命令
- if (command >= 0 && command < handlerSize())
- {
- callbacks[command]();
- }
- else
- {
- cout << "非法command: " << command << endl;
- }
- }
- exit(1);
- }
- // father,进行写入,关闭读端
- close(pipefd[0]); // pipefd[1]
- slots.push_back(pair<pid_t, int>(id, pipefd[1]));
- }
- // 父进程派发任务
- srand((unsigned long)time(nullptr) ^ getpid() ^ 23323123123L); // 让数据源更随机
- while (true)
- {
- // 自动派发任务
- // 选择一个任务
- int command = rand() % handlerSize();
- // 选择一个进程 ,采用随机数的方式,选择进程来完成任务,随机数方式的负载均衡
- int choice = rand() % slots.size();
- // 把任务给指定的进程
- sendAndWakeup(slots[choice].first, slots[choice].second, command);
- sleep(1);
- // 手动选择派发任务
- // int select;
- // int command;
- // cout << "############################################" << endl;
- // cout << "# 1. show funcitons 2.send command #" << endl;
- // cout << "############################################" << endl;
- // cout << "Please Select> ";
- // cin >> select;
- // if (select == 1)
- // showHandler();
- // else if (select == 2)
- // {
- // cout << "Enter Your Command> ";
- // // 选择任务
- // cin >> command;
- // // 选择进程
- // int choice = rand() % slots.size();
- // // 把任务给指定的进程
- // sendAndWakeup(slots[choice].first, slots[choice].second, command);
- // }
- // else
- // {
- // }
- }
- // 关闭fd, 所有的子进程都会退出
- for (const auto &slot : slots)
- {
- close(slot.second);
- }
- // 回收所有的子进程信息
- for (const auto &slot : slots)
- {
- waitpid(slot.first, nullptr, 0);
- }
- }
2、5、3 demo 代码解释
给定的代码是一个C++程序,它创建多个子进程,并使用管道进行进程间通信来分配任务。让我们逐步了解代码:
- `waitCommand` 函数用于等待通过文件描述符(`waitFd`)发送的命令。它从文件描述符中读取一个无符号32位整数,并返回命令值。如果读操作返回0,意味着另一端已关闭连接,将设置 `quit` 标志为 true,退出程序。
- `sendAndWakeup` 函数负责通过文件描述符(`fd`)向由进程ID(`who`)标识的进程发送命令。它将命令值写入文件描述符,并显示指示正在执行的进程和命令的消息。
- 在 `main` 函数中,调用了 `load` 函数,该函数加载程序所需的一些必要数据(上述代码就是加在加载我们所需要的任务)。
- 创建了一个名为 `slots` 的pair vector,用于存储子进程的进程ID和文件描述符。
- 程序进入循环以创建多个子进程。在每次迭代中,使用 `pipe` 函数创建一个管道,提供一个数组 `pipefd` 以保存读端和写端的文件描述符。然后调用 `fork` 函数来创建一个子进程,并通过检查返回的ID是否为0来区分子进程。在子进程中,关闭管道的写端,并进入一个无限循环以等待命令并执行它们。如果收到无效命令,显示一条消息。最后,子进程退出。
- 在父进程中,关闭管道的读端,并将进程ID和写端文件描述符添加到 `slots` 向量中。
- 父进程进入另一个循环来分配任务给子进程。在每次迭代中,使用 `rand` 函数生成从0到 `handlerSize()` 的随机命令索引。然后,从 `slots` 向量中选择一个随机子进程,使用 `sendAndWakeup` 函数将选择的命令发送给该进程。发送命令后,程序暂停1秒钟,然后进行下一次迭代。
- 上述循环不断地将任务分配给子进程,确保它们执行各自的任务。还有被注释掉的代码,可以手动选择要发送给子进程的命令,但目前未激活。
总之,此代码使用管道进行进程间通信创建多个子进程,并随机将任务分配给这些子进程。子进程不断等待命令并执行它们,而父进程则选择随机命令并将其发送给一个子进程。
三、命名管道
3、1 什么是命名管道
命名管道(Named Pipe),也被称为FIFO(First In, First Out)管道,是一种特殊类型的文件,用于实现不同进程之间的通信。它允许两个或多个进程在系统中通过一个公共的命名管道进行双向通信。
命名管道有一个在文件系统中可见的唯一名称,而匿名管道没有。在创建命名管道时,需要指定一个路径和名称;而创建匿名管道时,不需要提供名称。
我们在Linux下进行测试,使用命令进行创建一个命名管道。具体如下:
- 首先,我们需要使用系统调用函数mkfifo来创建一个命名管道。通过指定一个路径和一个唯一的名称,可以创建一个新的命名管道文件。指令如下:
- //mkfifo 路径+文件名称
- mkfifo ./mypipe
创建的结果如下图所示:

-
接下来我们再打开命名管道。当然我们可以使用代码进行打开管道(下文会对此讲解),也可以直接向管道输入内容。具体如下图:
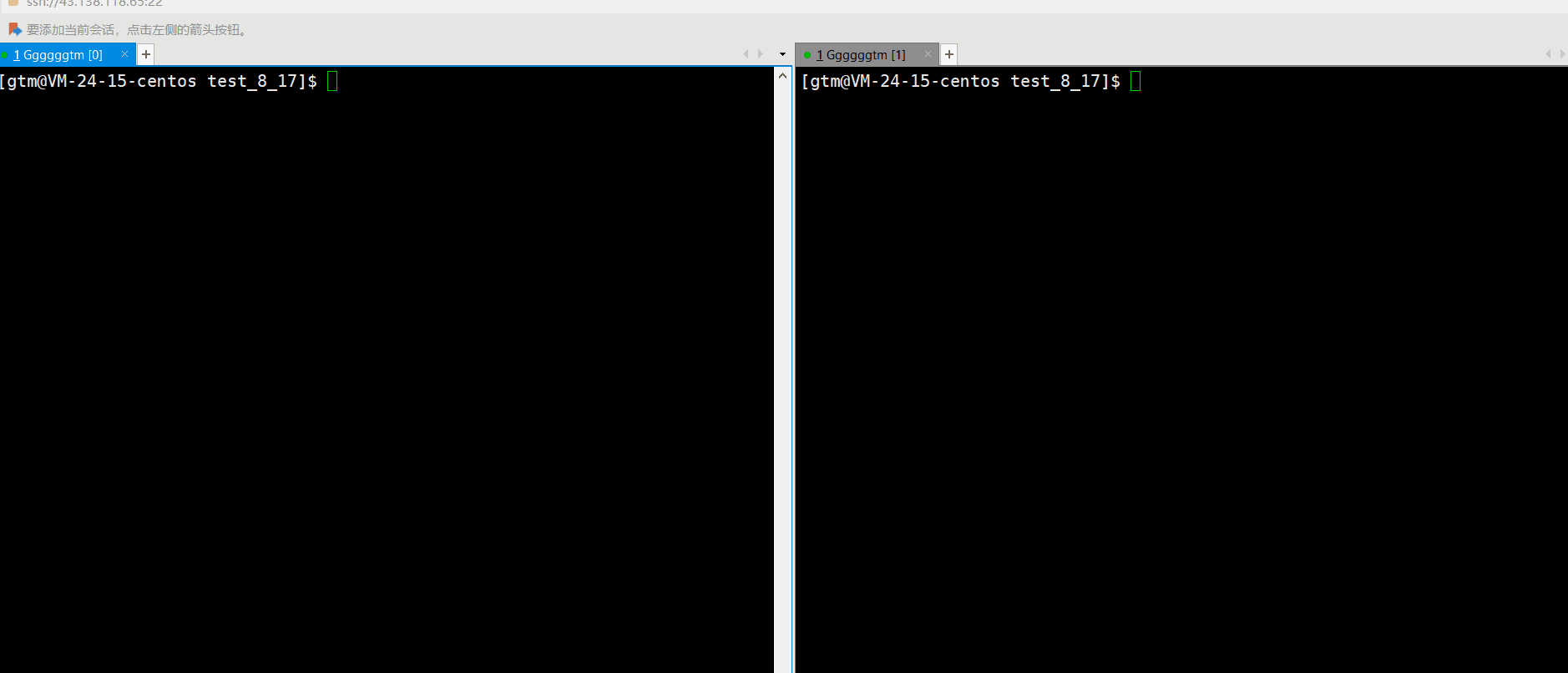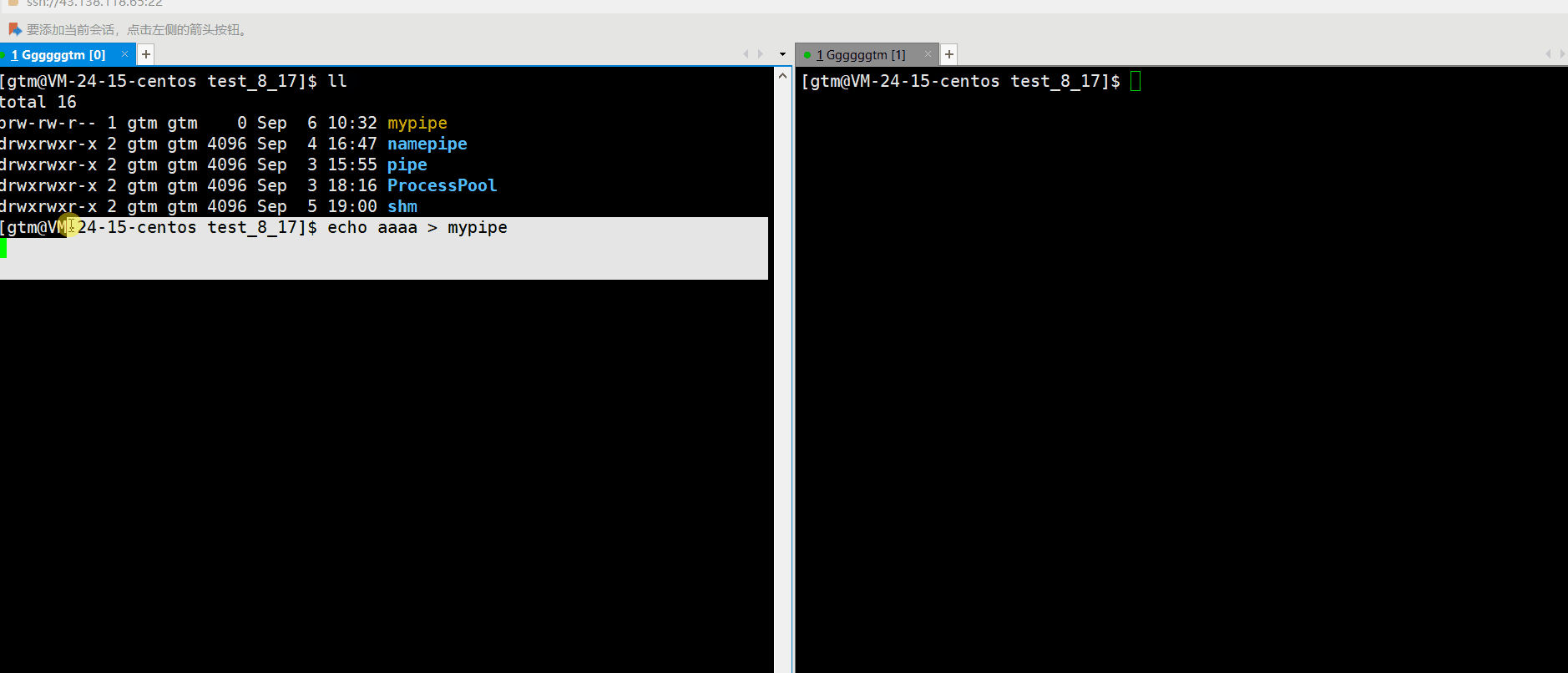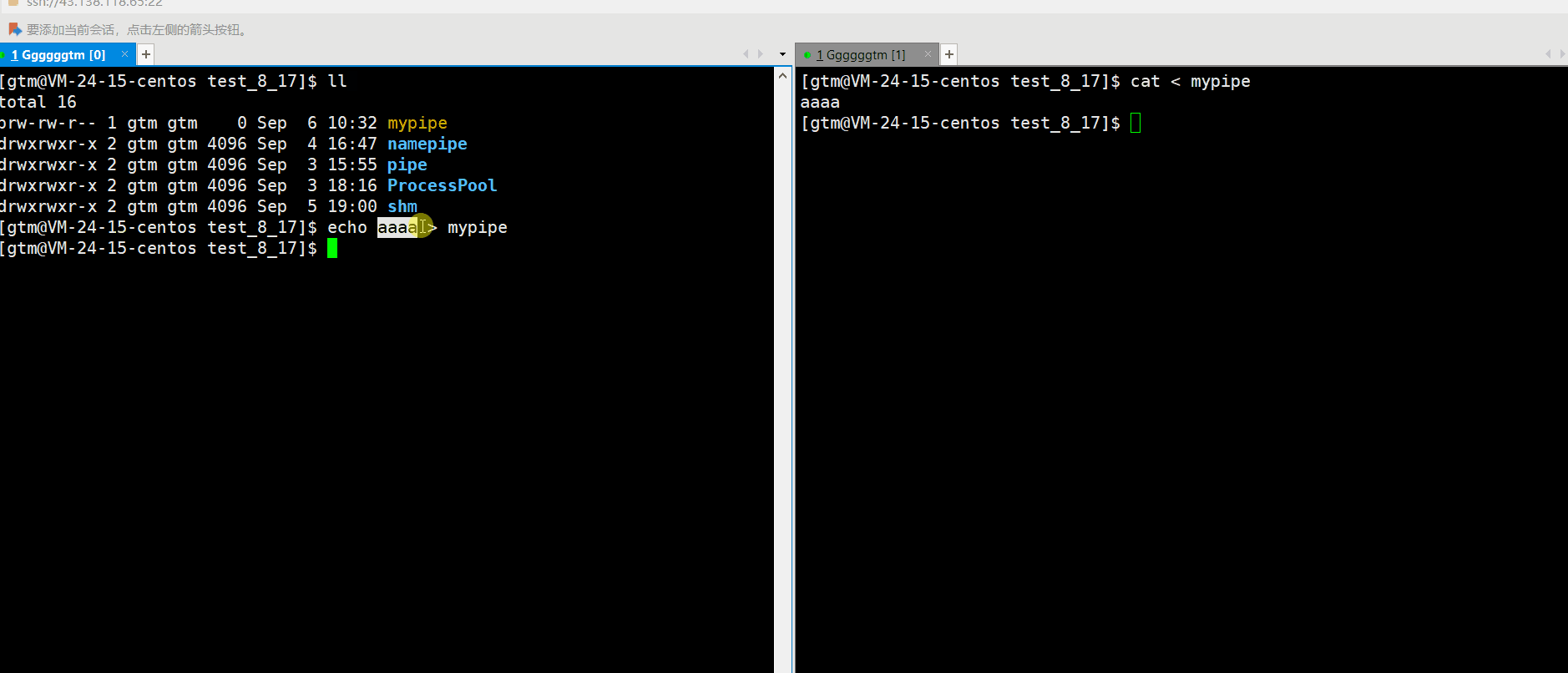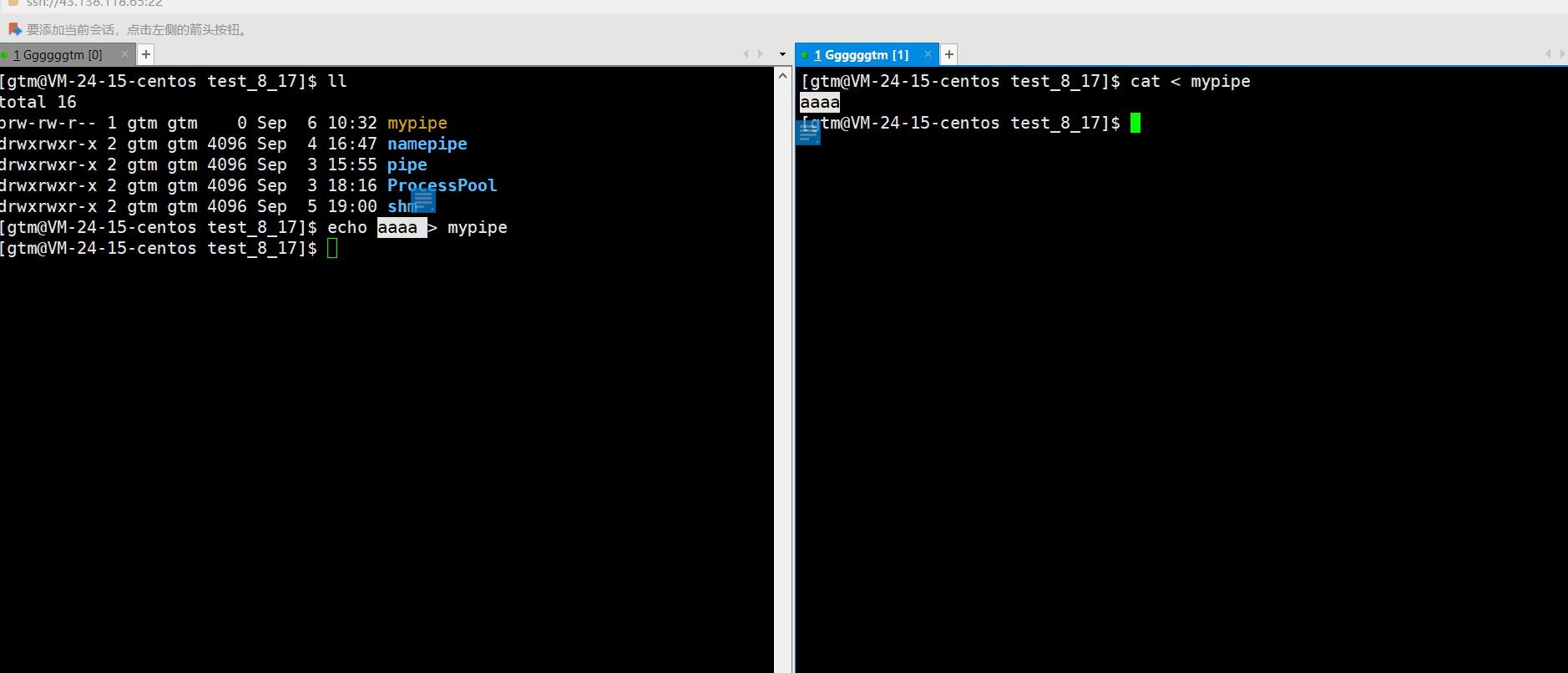
通过上述情况,我们发现当向管道输入内容后,相当于就是打开了管道的写端。这是我们必须打开管道的读端进行读取。否则写端就会认为该操作(进程)一直在运行,并未结束。
3、2 命名管道通信
命名管道的通信与匿名管道的通信基本相同。都需要看到同一块资源。但是匿名管道并不需要在磁盘上建立文件。命名管道是有一个唯一的路径和名称的。那进行通信的时候,会不会要进行磁盘I/O呢?命名管道通信会不会效率很慢呢?我们接着往下看。
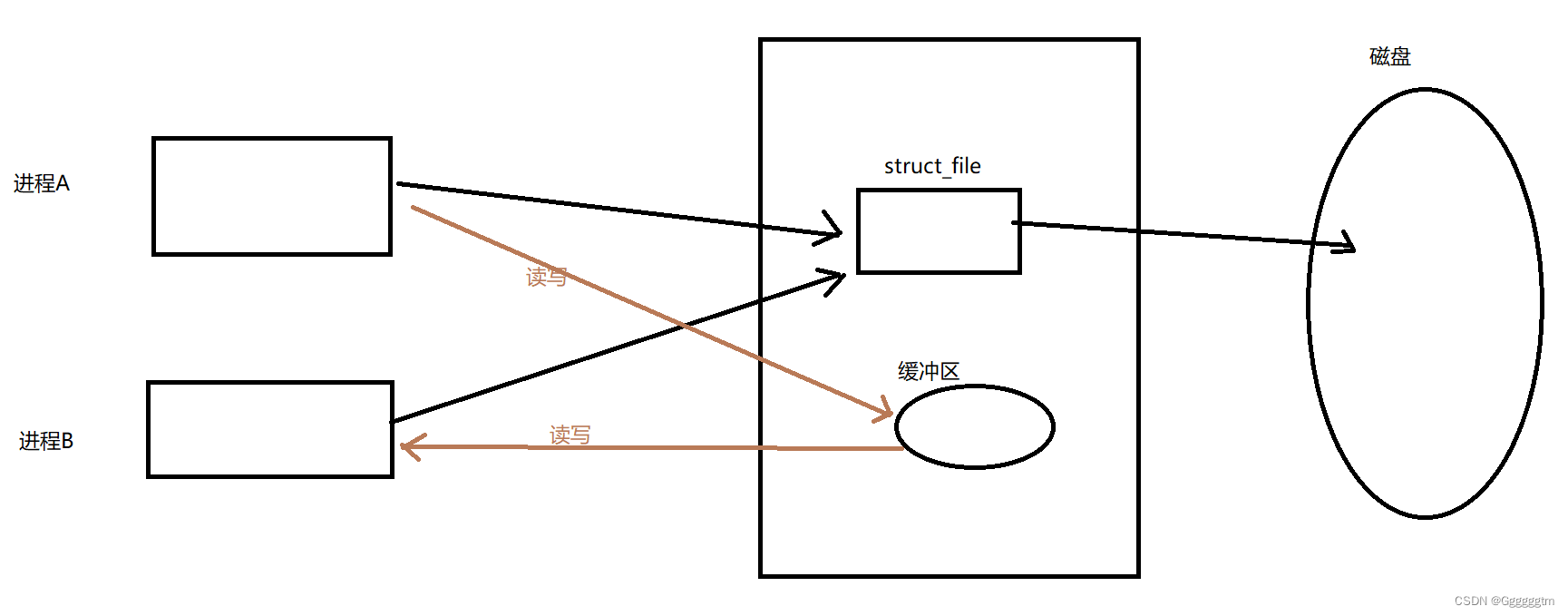
我们之前学习中,C语言模拟实现进度条小程序中提到了输出缓冲区。 同时在上述的匿名管道的demo代码中,也定义了我们自己的缓冲区(buffer[ ])。当然,因为这时的磁盘文件时用来通信的。是一个进程的数据让另一个进程看到,并不需要把数据刷新到磁盘。数据传输是通过内存缓冲区完成的,进程之间直接交换数据,不需要写入硬盘。命名管道的数据传输缓冲区位于内存中。当进程向命名管道写入数据时,数据会被暂存在内存缓冲区中。接收进程从该缓冲区中读取数据。因此实际上并不会效率很低。
3、3 命名管道 demo 代码
3、3、1 mkfifo
我们了解了利用指令创建命名管道。那么我们想通过接口来创建命名管道就可以使用mkfifo函数。具体使用如下图:

我们看一下mkfifo的具体使用方法。函数原型:
int mkfifo(const char *pathname, mode_t mode);这个函数接受两个参数,
pathname表示要创建的管道的路径名,mode表示设置文件权限的模式。下面我们看一个举例的例子:- #include
- #include
- #include
- int main() {
- umask(0); // 设置文件权限掩码为0,确保创建的管道拥有指定的权限
- int result = mkfifo("/tmp/myfifo", 0666);
- if (result == 0) {
- printf("命名管道创建成功\n");
- } else {
- perror("命名管道创建失败");
- }
- return 0;
- }
具体运行结果如下:
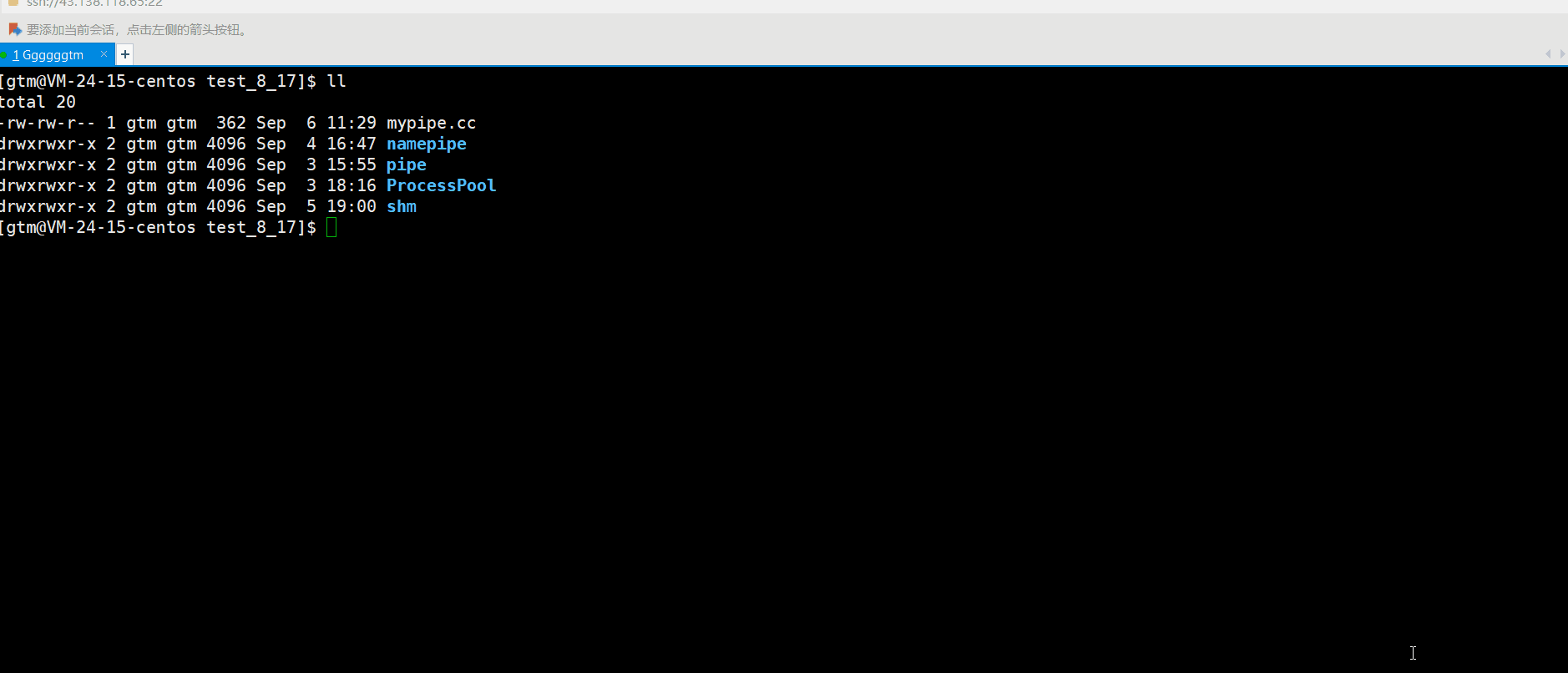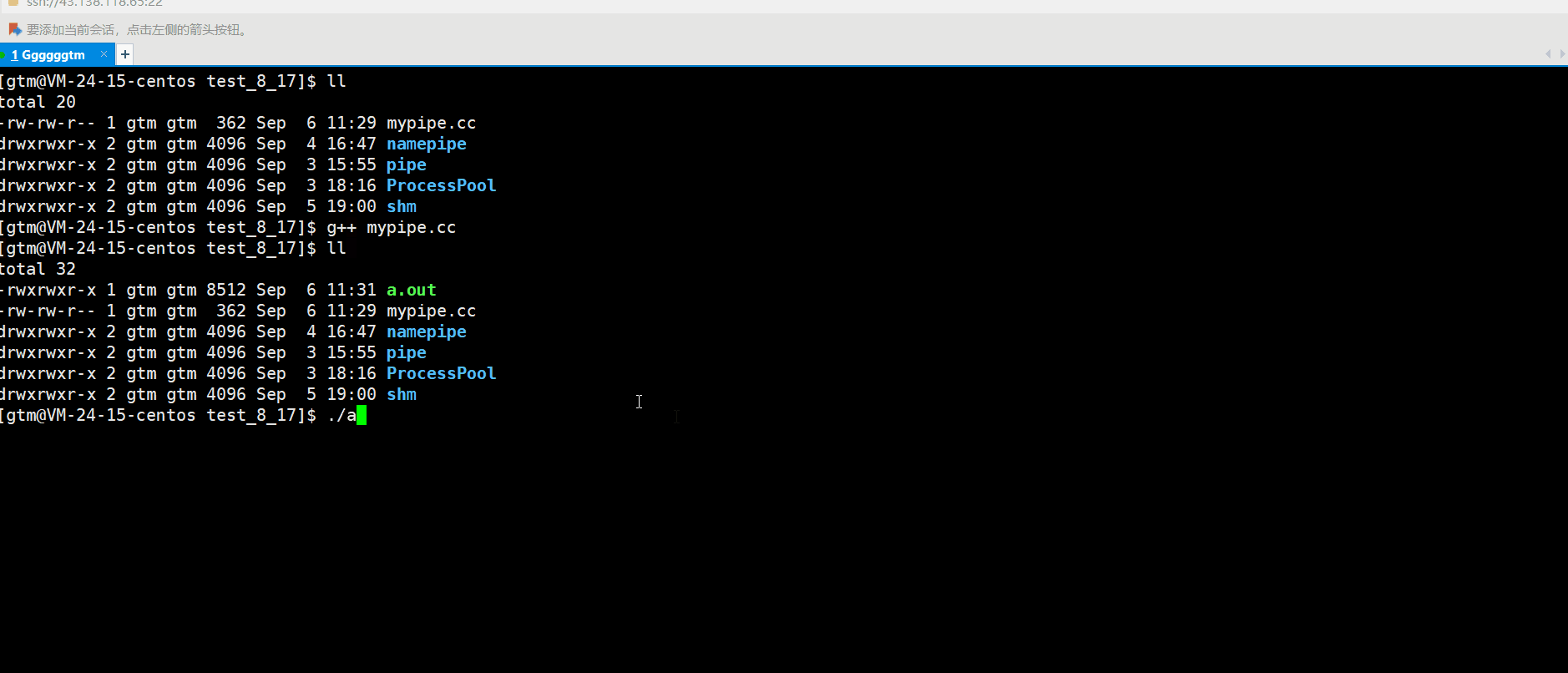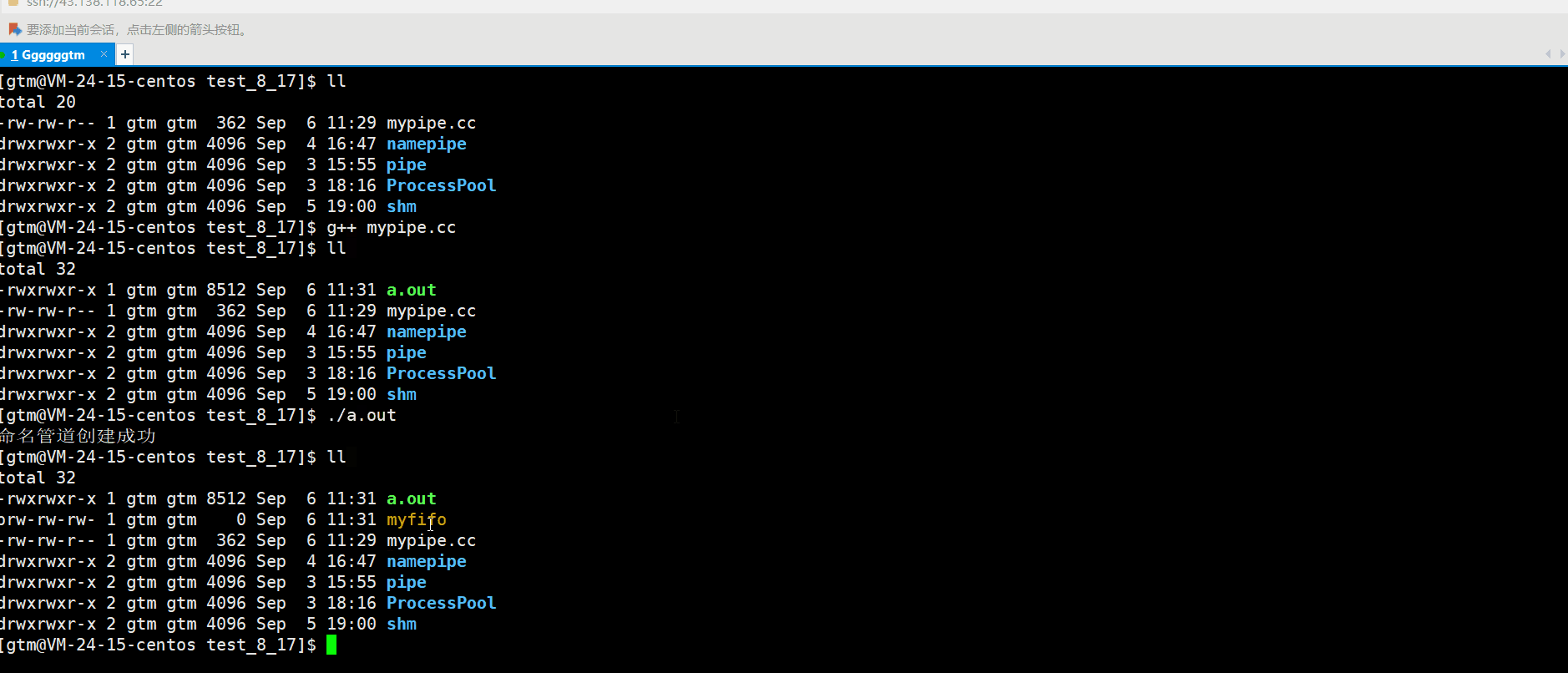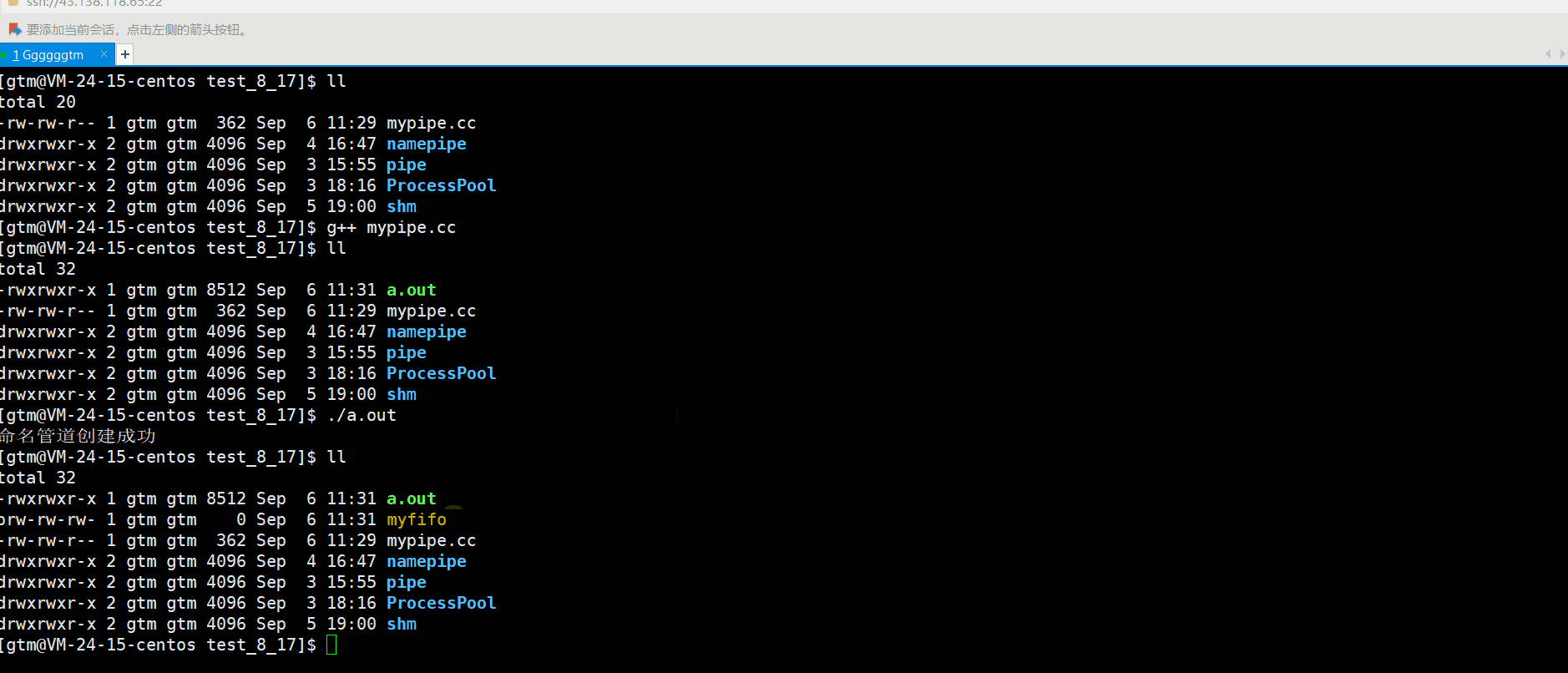 然后,另一个进程就可以打开此文件进行通信了!命名管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。下面我们来模拟一下命名管道通信的方式。
然后,另一个进程就可以打开此文件进行通信了!命名管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。下面我们来模拟一下命名管道通信的方式。3、3、2 demo 代码
- // comm.hpp
- #pragam once
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include "Log.hpp"
- using namespace std;
- #define MODE 0666
- #define SIZE 128
- string ipcPath = "./fifo.ipc";
- // Log.hpp
- #define Debug 0
- #define Notice 1
- #define Warning 2
- #define Error 3
- const std::string msg[] = {
- "Debug",
- "Notice",
- "Warning",
- "Error"
- };
- std::ostream &Log(std::string message, int level)
- {
- std::cout << " | " << (unsigned)time(nullptr) << " | " << msg[level] << " | " << message;
- return std::cout;
- }
- // client.cpp
- #include "comm.hpp"
- int main()
- {
- // 1. 获取管道文件
- int fd = open(ipcPath.c_str(), O_WRONLY);
- if(fd < 0)
- {
- perror("open");
- exit(1);
- }
- // 2. ipc过程
- string buffer;
- while(true)
- {
- cout << "Please Enter Message Line :> ";
- std::getline(std::cin, buffer);
- write(fd, buffer.c_str(), buffer.size());
- }
- // 3. 关闭
- close(fd);
- return 0;
- }
- //server.cpp
- #include "comm.hpp"
- static void getMessage(int fd)
- {
- char buffer[SIZE];
- while (true)
- {
- memset(buffer, '\0', sizeof(buffer));
- ssize_t s = read(fd, buffer, sizeof(buffer) - 1);
- if (s > 0)
- {
- cout <<"[" << getpid() << "] "<< "client say> " << buffer << endl;
- }
- else if (s == 0)
- {
- // end of file
- cerr <<"[" << getpid() << "] " << "read end of file, clien quit, server quit too!" << endl;
- break;
- }
- else
- {
- // read error
- perror("read");
- break;
- }
- }
- }
- int main()
- {
- // 1. 创建管道文件
- if (mkfifo(ipcPath.c_str(), MODE) < 0)
- {
- perror("mkfifo");
- exit(1);
- }
- Log("创建管道文件成功", Debug) << " step 1" << endl;
- // 2. 正常的文件操作
- int fd = open(ipcPath.c_str(), O_RDONLY);
- if (fd < 0)
- {
- perror("open");
- exit(2);
- }
- Log("打开管道文件成功", Debug) << " step 2" << endl;
- int nums = 3;
- for (int i = 0; i < nums; i++)
- {
- pid_t id = fork();
- if (id == 0)
- {
- // 3. 编写正常的通信代码了
- getMessage(fd);
- exit(1);
- }
- }
- for(int i = 0; i < nums; i++)
- {
- waitpid(-1, nullptr, 0);
- }
- // 4. 关闭文件
- close(fd);
- Log("关闭管道文件成功", Debug) << " step 3" << endl;
- unlink(ipcPath.c_str()); // 通信完毕,就删除文件
- Log("删除管道文件成功", Debug) << " step 4" << endl;
- return 0;
- }
这段代码是一个简单的进程间通信(IPC)示例,使用命名管道(FIFO)实现。下面对代码进行详细解释:
comm.hpp:
- 定义了ipcPath字符串变量,表示管道文件的路径。
- 定义了MODE和SIZE常量,分别表示管道文件的权限和缓冲区的大小。
Log.hpp:
- 定义了Debug、Notice、Warning和Error四个级别的日志常量。
- 定义了msg数组,存储了每个级别的日志名称。
- 实现了Log函数,用于打印日志信息。
client.cpp:
- 主函数中首先打开管道文件(以只写方式)。
- 然后通过循环从标准输入读取用户输入的消息,并将消息写入管道中。
server.cpp:
- 首先通过mkfifo函数创建一个管道文件。
- 然后打开管道文件(以只读方式)。
- 创建了3个子进程,每个子进程通过getMessage函数读取管道文件中的消息,并打印到标准输出。
- 父进程通过waitpid函数等待所有子进程退出。
- 最后关闭管道文件,删除管道文件。
该代码演示了父进程和多个子进程之间通过命名管道进行通信的过程。父进程创建了一个管道文件,并打开该文件以便读取子进程写入的消息,同时创建多个子进程来同时处理不同的客户请求。每个子进程通过读取管道文件中的消息来获取客户端发送的数据,并打印到标准输出。父进程等待所有子进程退出后,关闭管道文件并删除管道文件。这样就完成了进程间的通信。
四、总结
命名管道(named pipe)和匿名管道(anonymous pipe)是用于进程间通信的机制,它们在某些方面相同但也有一些区别。
相同点:
- 用途:两种管道都可以用于进程间的通信。进程可以通过管道在同一台计算机上进行数据交换。
- 工作原理:管道都提供了一个单向的、先进先出(FIFO)的数据流。进程通过写入端将数据写入管道,在读取端从管道中读取数据。
- 实现方式:管道通常由操作系统提供支持,通过在内核中创建一个缓冲区来实现。
区别:
- 命名管道有一个在文件系统中可见的唯一名称,而匿名管道没有。在创建命名管道时,需要指定一个路径和名称;而创建匿名管道时,不需要提供名称。
- 命名管道可以允许无关的进程之间进行通信,而匿名管道通常只用于相关的父子进程间通信。
- 命名管道使用文件系统的权限和属性,可以像普通文件一样进行操作(如权限控制、查看文件大小等),而匿名管道没有关联的文件系统属性。
- 命名管道可以由多个进程同时读取或写入,而匿名管道只能由在创建时有亲属关系的进程之间进行通信。
本篇文章的内容就将接到这里,下篇内容会讲解到共享内存(System V)和信号量。感谢阅读。
- 相关阅读:
软件开发模型与软件测试模型
Java刷题day37
【Linux基础】3.4 Linux的进程,服务,防火墙等
Node学习三 —— 事件发生器
Feign通过自定义注解实现路径的转义
【QNX Hypervisor 2.2用户手册】目录
C语言学习概览(五)
公共命名空间和输入法
rman导入时reading的路径与注册备份集的路径不一致
硬件设计——关于Type-C 口的讲解和设计
- 原文地址:https://blog.csdn.net/weixin_67596609/article/details/132676731
-
