-
BEiT: BERT Pre-Training of Image Transformers 论文笔记
BEiT: BERT Pre-Training of Image Transformers 论文笔记
论文名称:BEiT: BERT Pre-Training of Image Transformers
论文地址:2106.08254] BEiT: BERT Pre-Training of Image Transformers (arxiv.org)
代码地址:unilm/beit at master · microsoft/unilm (github.com)
作者讲解:BiLiBiLi
作者PPT:文章资源
文章目录
首先展示的是我基于这个算法搭建的网页
demo,欢迎体验。https://wangqvq-beit-gradio.hf.space/

整体结构图

Visual Tokens
将图像分解为离散的标记
-
离散
variationalautoencoder -
学习通过视觉令牌的条件来重建原始图像
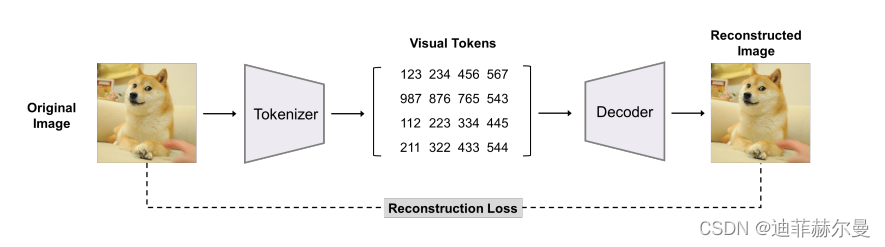
- 图像表示(两个视角)

- 分块遮罩
- 每次都会对图像块进行遮罩处理

- 将受损图像补丁输入到
Transformer中- 最终的隐向量被视为编码表示

- 在给定受损图像的情况下恢复正确的视觉标记
- 视觉标记将细节总结为高层抽象

1.1 总体方法
- 受 BERT 启发,提出了一项预训练任务,即掩码图像建模
(MIM)。 MIM为每个图像使用了两种视图,即图像块(image patches)和视觉标记(visual tokens)。- 图像被分割成一个网格的图像块,这些图像块是骨干
Transformer的输入表示。 - 通过离散变分自编码器
(discrete variational autoencoder),图像被“标记化”(tokenized)为离散的视觉标记,其中离散变分自编码器来自于 DALL·E。
在预训练阶段,图像的一部分图块(image patches)会被随机地遮挡(masked),然后将这些被遮挡的输入提供给Transformer模型。模型会学习如何从遮挡后的输入中恢复原始图像中的视觉标记(visual tokens),而不是从遮挡的图块中恢复原始像素。
换句话说,模型在这个过程中学习了如何通过遮挡和损坏的输入来推断出原始图像的部分内容,这有助于模型学习图像的语义和特征。作者认为这种预训练策略可以增强模型在图像处理任务中的能力,使其能够更好地理解和表示图像。
1.2 图像表示
图像具有两种表示视图,即图像块和视觉标记。这两种类型在预训练期间分别用作输入和输出表示。
1.2.1 图像块 (Image Patches)

- 尺寸为 H × W × C H×W×C H×W×C 的二维图像被分割成大小为 P 2 P^2 P2 的图像块序列 x p x_p xp(其中 p p p 从 1 1 1 到 N N N),其中 p a t c h patch patch 的数量 N N N = H W / P 2 HW/P^2 HW/P2。
- 图像块 x p x_p xp 被展平为向量,并且进行线性投影,这与 BERT 中的词嵌入类似。
具体而言,BEiT 将每个 224 × 224 224×224 224×224 的图像分割成一个 14 × 14 14×14 14×14 的图像块网格,每个图像块大小为 16 × 16 16×16 16×16。
1.2.2 视觉标记 (Visual Tokens)

图像不再以原始像素的形式表示,而是被分解成一系列离散的标记
(tokens),这些标记是通过一个名为“图像分词器”(image tokenizer)获得的。换句话说,图像被转化成了一串由特定标记组成的序列,而不再是像素点的集合。具体而言,尺寸为 H × W × C H×W×C H×W×C 的图像被标记化为 z = [ z 1 , … , z N ] z=[z1, …, zN] z=[z1,…,zN],其中词汇表 V = { 1 , 2 , … , ∣ V ∣ } V=\{1, 2, …, |V|\} V={1,2,…,∣V∣} 包含离散的标记索引。
-
由 DALL·E 学习的离散变分自编码器(dVAE)直接使用了图像标记器。
-
在视觉标记学习过程中,存在两个模块,即标记器(tokenizer)和解码器(decoder)。
-
标记器 q ( z ∣ x ) q(z|x) q(z∣x) 将图像像素 x x x 映射为离散标记 z z z,根据一个视觉码本(即词汇表)。
-
解码器 $p(x|z) $学习基于视觉标记 z z z 重构输入图像 x x x。
-
词汇表大小设置为 ∣ V ∣ = 8192 |V| = 8192 ∣V∣=8192。
1.3 ViT Backbone
-
在
ViT的基础上,使用了 T r a n s f o r m e r Transformer Transformer 骨干网络。 -
T r a n s f o r m e r Transformer Transformer 的输入是图像块序列 x i p x_i^p xip
-
然后,图像块通过线性投影得到块嵌入 E x i p Ex^p_i Exip
-
标准的可学习的一维位置嵌入 E p o s E_{pos} Epos 被添加到块嵌入中:
H 0 = [ e [ S ] , E x i p , … , E x N p ] + E p o s \boldsymbol{H}_{0}=\left[\boldsymbol{e}_{[\mathrm{S}]}, \boldsymbol{E} \boldsymbol{x}_{i}^{p}, \ldots, \boldsymbol{E} \boldsymbol{x}_{N}^{p}\right]+\boldsymbol{E}_{p o s} H0=[e[S],Exip,…,ExNp]+Epos
- 编码器包含 L L L 层 T r a n s f o r m e r Transformer Transformer 块:
H l = Transformer ( H l − 1 ) \boldsymbol{H}^{l}=\text { Transformer }\left(\boldsymbol{H}^{l-1}\right) Hl= Transformer (Hl−1)
- 最后一层的输出向量为:

这些向量被用作图像块的编码表示,其中 h i L h^L_i hiL 是第 i i i 个图像块的向量。
- 使用了ViTBase,它是一个包含 12 12 12 层 T r a n s f o r m e r Transformer Transformer 的模型,每层有 768 768 768 的隐藏大小和 12 12 12 个注意力头。前馈网络的中间大小为 3072 3072 3072。
2. BEiT的预训练:掩码图像建模
2.1. Masked Image Modeling (MIM)

-
将图像分割成图像块后,如上所述,大约 40 % 40\% 40% 的图像块会被随机遮蔽,遮蔽的位置标记为
M。被遮蔽的块会被可学习的嵌入e[M]所取代。在 BEiT 中,最多会遮蔽 75 75 75 个图像块。 -
然后,好的和被遮蔽的图像块被输入到 L L L 层 T r a n s f o r m e r Transformer Transformer 中。
-
使用
softmax分类器来预测相应的视觉标记:

预训练目标是最大化给定受损图像情况下正确视觉标记 z i z_i zi 的对数似然:

-
BEiT在ImageNet-1K的训练集上进行预训练。 -
预训练大约运行了
500k步(即800个epoch),使用了2k的批大小。这500k个训练步骤使用了16张Nvidia Tesla V100 32GB GPU卡,大约花费了五天的时间。
2.2. Blockwise Masking 分块遮蔽

补丁块是随机遮蔽的,如上图和算法所示,而不是以随机方式逐个遮蔽每个补丁。
2.3. From VAE Perspective 从VAE的角度
-
BEiT 的预训练可以看作是变分自编码器的训练:
原始图像: x x x
当前图像: x ~ \widetilde{x} x
视觉标记: z z z

- 在第一阶段,图像标记器作为一个离散变分自编码器获得。具体来说,第一阶段最小化重构损失,使用均匀先验。
- 在第二阶段,保持 q φ q_φ qφ 和 p ψ p_ψ pψ 固定的同时学习先验 p θ p_θ pθ。
- 因此,上述方程被重写为:

其中第二项是提出的 BEiT 预训练目标。
3. 实验结果
3.1. ImageNet-1K 和 ImageNet-22K 预训练,以及在 ImageNet-1K 上的图像分类

- 一个简单的线性分类器被用作任务层。平均池化被用来聚合表示,并将全局表示输入到一个
softmax分类器中。 - 预训练的 BEiT 显著提高了在这两个数据集上的性能。
BEiT 在 ImageNet 上提高了性能,显示了在资源丰富的设置下的有效性。
- 更高的分辨率在
ImageNet上将 BEiT 的结果提高了1+个百分点。
更重要的是,即使在使用相同输入分辨率时,预训练于
ImageNet-1K的BEiT384甚至在性能上超越了使用ImageNet-22K进行监督预训练的ViT384。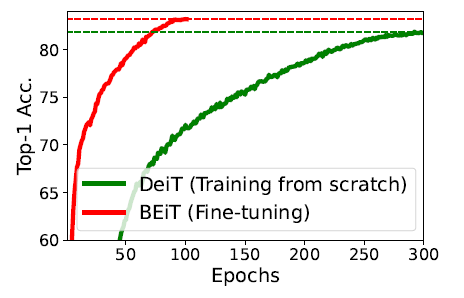
对 BEiT 进行微调不仅实现了更好的性能,而且收敛速度比从零开始训练的 DeiT 快得多。
3.2. ADE20K的语义分割

-
使用了
SETR-PUP中使用的任务层 -
具体来说,将预训练的 BEiT 用作骨干编码器,并结合几个反卷积层作为解码器来产生分割。
BEiT 比监督式预训练具有更好的性能,尽管 BEiT 不需要手动注释进行预训练。
- 在 ImageNet上对 BEiT 进行中间微调,即首先在ImageNet上对预训练的 BEiT 进行微调,然后在ADE20K上对模型进行微调。
中间微调进一步改善了语义分割的 BEiT。
3.3. 消融研究

-
块屏蔽
(Blockwise masking)对这两个任务都是有益的,尤其是在语义分割方面 -
所提出的掩蔽图像建模
(MIM)任务明显优于朴素像素级自动编码。结果表明,视觉代币的预测是 BEiT 的关键要素。 -
恢复所有视觉对象令牌会损害下游任务的性能。
-
对模型进行更长时间的预训练(800 个 epoch)可以进一步提高下游任务的性能
3.4. 自注意力图分析

-
BEiT 中的自我注意机制可以分离物体。
经过预训练后,BEiT 学会使用自我注意头来区分语义区域,而无需任何特定于任务的监督。BEiT 获得的这些知识有可能提高微调模型的泛化能力,特别是在小规模数据集上。
-
-
相关阅读:
C++自增/减运算符的原理以及前后缀形式的本质区别
安全两方推理问题
Markdown语法
递归、搜索与回溯算法——穷举vs暴搜vs深搜
选择题汇总5(括号里填的答案都是对的,不用管下面那个答案正确与错误,因为作者懒得删了)
【笔记-OrCAD】WARNING(ORCAP-36038)解决办法
价值几十亿美金的名字,Microsoft Windows的由来
pyinstaller最简单教程
作业 day4
Leecode热题100---128:最长连续数列
- 原文地址:https://blog.csdn.net/weixin_43694096/article/details/132368492