在前面的章节中相信读者已经学会了使用Metasploit工具生成自己的ShellCode代码片段了,本章将继续深入探索关于ShellCode的相关知识体系,ShellCode 通常是指一个原始的可执行代码的有效载荷,攻击者通常会使用这段代码来获得被攻陷系统上的交互Shell的访问权限,而现在用于描述一段自包含的独立的可执行代码片段。ShellCode代码的编写有多种方式,通常会优先使用汇编语言实现,这得益于汇编语言的可控性。
ShellCode 通常会与漏洞利用并肩使用,或是被恶意代码用于执行进程代码的注入,通常情况下ShellCode代码无法独立运行,必须依赖于父进程或是Windows文件加载器的加载才能够被运行,本章将通过一个简单的弹窗(MessageBox)来实现一个简易版的弹窗功能,并以此来加深读者对汇编语言的理解。
1.4.1 寻找DLL库函数地址
在编写ShellCode之前,我们需要查找一个函数地址,由于我们需要调用MessageBoxA()这个函数,所以需要获取该函数的内存动态地址,根据微软的官方定义可知,该函数默认放在了User32.dll库中,为了能够了解压栈时需要传入参数的类型,我们还需要查询一下函数的原型;
在微软定义中MessageBoxA函数的原型如下:
int MessageBoxA(
HWND hWnd,
LPCSTR lpText,
LPCSTR lpCaption,
UINT uType
);
参数说明:
- hWnd:消息框的父窗口句柄。
- lpText:消息框中显示的文本。
- lpCaption:消息框的标题栏文本。
- uType:消息框的类型,可以指定消息框包含的按钮以及图标等。
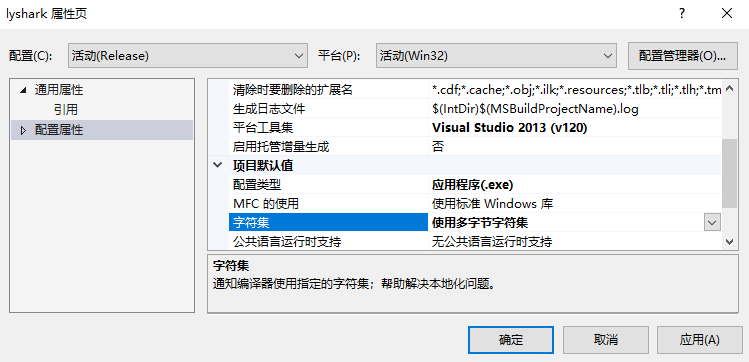
需要注意的是,由于我们调用的是MessageBoxA,而此函数为ASCII模式,需要读者自行修改解决方案,在配置属性的常规选项卡,修改字符集(使用多字节字符集)即可,如下图所示;
读者可以通过编写一段简单的代码来获取所需数据,首先通过LoadLibrary函数加载名为user32.dll的动态链接库,并将其基地址存储在HINSTANCE类型的变量LibAddr中。然后,使用GetProcAddress函数获取 MessageBoxA函数的地址,并将其存储在MYPROC类型的变量ProcAddr中。最后输出所需结果;
#include 上方的代码经过编译运行后会得到两个返回结果,如下图所示,其中User32.dll的基地址是0x75a40000而该模块内的MessageBoxA函数在当前系统中的地址为0x75ac0ba0,当然这两个模块地址在每次系统启动时都会发生幻化,读者电脑中的地址肯定与笔者不相同,这都是正常现象,之所以会出现这种情况是因为,系统中存在一种ASLR机制。
扩展知识:ASLR(Address Space Layout Randomization)机制的核心是用于随机化系统中程序和数据的内存地址分布,从而增加攻击者攻击系统的难度,在启用了ASLR机制的系统下,每次运行程序时,程序和系统组件(例如DLL、驱动程序等)都会被分配不同的内存地址,而不是固定的内存地址。这样可以使得攻击者难以利用已知的内存地址漏洞进行攻击,因为攻击者需要先找到正确的内存地址才能利用漏洞。ASLR的随机化是根据操作系统的一些随机因素进行计算的,例如启动时间、进程 ID 等等。
由于如上机制的存在,导致user32.dll模块地址不确定,也就会导致其地址内部的API函数地址也会发生一定的变化,下图仅作为参考图;

在获取到MessageBoxA函数的内存地址以后,我们接着需要获取一个ExitProecess函数的地址,这个API函数的作用是让程序正常退出,这是因为我们注入代码以后,原始的堆栈地址会被破坏,堆栈失衡后会导致程序崩溃,所以为了稳妥起见我们还是添加一行正常退出为好。函数ExitProcess的原型如下:
VOID WINAPI ExitProcess(
UINT uExitCode
);
其中参数uExitCode指定了进程的退出代码,表示进程成功退出或者发生了错误。如果uExitCode为0,表示进程成功退出,其他的非0值则表示进程发生了错误,不同的非0值可以用于表示不同的错误类型。
1.4.2 探讨STDCALL调用约定
既然获取到了相应的内存地址,那么接下来就需要通过汇编来编写可执行代码片段了,在编写这段代码之前,先来了解一下汇编语言的调用约定,在汇编语言中,要想调用某个函数,需要使用CALL语句,而在CALL语句的后面,要跟上该函数在系统中的地址,前面我们已经获取到了相应的内存地址了,所以在这里就可以通过CALL相应的地址来调用相应的函数。
我们以32位应用程序为例,在32位应用程序内通常使用STDCALL调用约定,它定义了函数在被调用时,参数传递、返回值传递以及栈的使用等方面的规则,该调用约定的规则如下所示:
- 参数传递:参数从右向左依次压入栈中,由被调用者在返回前清理栈。
- 返回值传递:函数返回时将返回值存储在EAX寄存器中。
- 栈的使用:函数被调用前,调用者将参数压入栈中;被调用者在返回前清理栈,以确保栈的平衡。
- 函数调用:在调用函数之前,调用者将返回地址(Return Address)和EBP寄存器的值保存在栈中,并将ESP寄存器指向参数列表的最后一个元素;在函数返回之后,调用者通过将之前保存的EBP和返回地址弹出栈中,并将ESP寄存器恢复到最初的位置来恢复栈的状态。
总之,stdcall调用约定将参数按照从右到左的顺序压入栈中,由被调用者清理栈,返回值存储在EAX寄存器中,函数调用者和被调用者都需要遵循一定的栈使用规则。这种约定的好处是参数传递简单,可读性高,并且在函数返回时栈已经被清理,不需要额外的清理工作。
在实际的编程中,一般还是先将地址赋值给eax寄存器,然后再CALL调用相应的寄存器实现调用,比如现在笔者有一个lyshark(a,b,c,d)函数,如果我们想要调用它,那么它的汇编代码就应该编写为:
push d
push c
push b
push a
mov eax,AddressOflyshark // 获取偏移地址
call eax // 间接调用
根据上方的调用方式,我们可以写出ExitProcess()函数的汇编版调用结构,如下;
xor ebx, ebx
push ebx
mov eax, 0x76c84100
call eax
接着编写MessageBox()这个函数调用。与ExitProcess()函数不同的是,这个API函数包含有四个参数,当然第一和第四个参数,我们可以赋给0值,但是中间两个参数都包含有较长的字符串,这个该如何解决呢?我们不妨先把所需要用到的字符串转换为ASCII码值,转换的方式有许多,如下代码则是通过Python实现的转换模式;
import os,sys
from LyScript32 import MyDebug
# 字符串转ascii
def StringToAscii(string):
ref = []
for index in range(0,len(string)):
hex_str = str(hex(ord(string[index])))
ref.append(hex_str.replace("0x","\\x"))
return ref
if __name__ == "__main__":
# 输出MsgBox标题
title = StringToAscii("alert")
for index in range(0,len(title)):
print(title[index],end="")
print()
# 输出MsgBox内容
box = StringToAscii("hello lyshark")
for index in range(0,len(box)):
print(box[index],end="")
当Python程序被运行,则用户即可得到两串通过编码后的字符串数据。
MsgBox标题:alert \x61\x6c\x65\x72\x74\x21
MsgBox内容:hello lyshark \x68\x65\x6c\x6c\x6f\x20\x6c\x79\x73\x68\x61\x72\x6b
由于我们使用的是32位汇编,所以上方的字符串需要做一定的处理,我们分别将每四个字符为一组,进行分组,将不满四个字符的,以空格0x20进行填充,这是因为我们采用的存储字符串模式为栈传递,而一个寄存器为32位,所以就需要填充满4字节才可以平衡;
-------------------------------------------------------------
填充 alert
-------------------------------------------------------------
\x61\x6c\x65\x72
\x74\x21\x20\x20
-------------------------------------------------------------
填充 hello lyshark
-------------------------------------------------------------
\x68\x65\x6c\x6c
\x6f\x20\x6c\x79
\x73\x68\x61\x72
\x6b\x20\x20\x20
上方的空位置之所以需要以0x20进行填充,而不是0x00进行填充,是因为strcpy这个字符串拷贝函数,默认只要一遇到0x00就会认为我们的字符串结束了,就不会再拷贝0x00后的内容了,所以这里就不能使用0x00进行填充了,这里要特别留意一下。
接着我们需要将这两段字符串分别压入堆栈存储,这里需要注意,由于我们的计算机是小端序排列的,因此字符的入栈顺序是从后往前不断进栈的,上面的字符串压栈参数应该写为:
小提示:小端序(Little Endian)是一种数据存储方式,在汇编语言中,小端序的表示方式与高位字节优先(Big Endian)相反。例如,对于一个16位的整数0x1234,它在小端序的存储方式下,将会被存储为0x340x12(低位字节先存储);而在高位字节优先的存储方式下,将会被存储为0x120x34(高位字节先存储)。
-------------------------------------------------------------
压入字符串 alert
-------------------------------------------------------------
push 0x20202174
push 0x72656c61
-------------------------------------------------------------
压入字符串 hello lyshark
-------------------------------------------------------------
push 0x2020206b
push 0x72616873
push 0x796c206f
push 0x6c6c6568
既然字符串压入堆栈的功能有了,那么下面问题来了,我们如何获取这两个字符串的地址,从而让其成为MessageBox()的参数呢?
其实这个问题也不难,我们可以利用esp指针,因为它始终指向的是栈顶的位置,我们将字符压入堆栈后,栈顶位置就是我们所压入的字符的位置,于是在每次字符压栈后,可以加入如下指令,依次将第一个字符串基地址保存至eax寄存器中,将第二个基地址保存至ecx寄存器中。
xor ebx,ebx // 清空寄存器
push 0x20202174 // 字符串 alert
push 0x72656c61
mov eax,esp // 获取第一个字符串的地址
push ebx // 压入00为了将两个字符串分开
push 0x2020206b // 字符串 hello lyshark
push 0x72616873
push 0x796c206f
push 0x6c6c6568
mov ecx,esp // 获取第二个字符串的地址
上方汇编指令完成压栈以后,接下来我们就可以调用MessageBoxA函数了,其调用代码如下。
push ebx // push 0
push eax // push "alert"
push ecx // push "hello lyshark !"
push ebx // push 0
mov eax,0x75ac0ba0 // 将MessageBox地址赋值给EAX
call eax // 调用 MessageBox
1.4.3 ShellCode提取与应用
通过上方的实现流程,我们的ShellCode就算开发完成了,接下来读者只需要将上方ShellCode整理成一个可执行文件并编译即可。
#include 接下来就是需要手动提取此处汇编指令的特征码,本案例中我们可以通过x64dbg中的LyScript插件实现提取,首先载入被调试进程,然后寻找到如下所示的特征位置,当遇到Call时,则通过F7进入到内部,如下图所示;
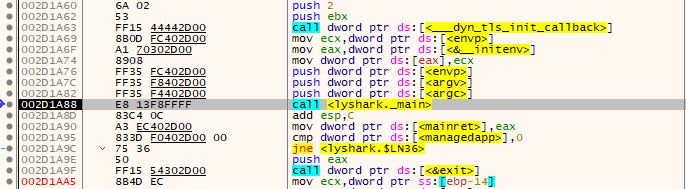
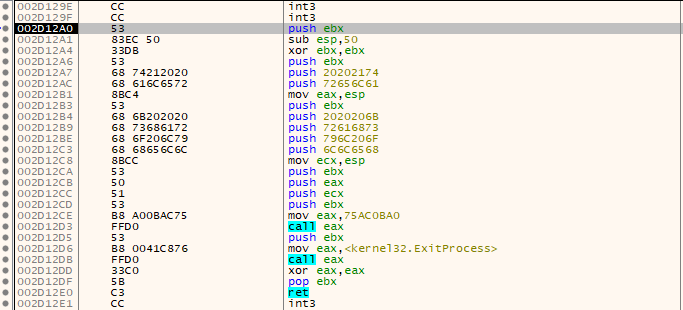
如下图中所示,就是我们所需要的汇编指令集,也就是我们自己的ShellCode代码片段,内存地址为0x002D12A0转换为十进制为2953888
通过LyScript插件并编写如下脚本,并将EIP位置设置为eip = 2953888运行这段代码;
from LyScript32 import MyDebug
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
ShellCode = []
eip = 2953888
for index in range(0, 100 - 1):
read_code = dbg.read_memory_byte(eip + index)
ShellCode.append(str(hex(read_code)))
for index in ShellCode:
print(index.replace("0x","\\x"),end="")
dbg.close()
则可输出如下图所示的完整特征码,读者可自行将此处特征码格式化;

当然读者通过在_asm指令位置设置F9断点,并通过F5启动调试,如下图所示;

当调试器被断下时,通过按下Ctrl+Alt+D跳转至反汇编代码位置,并点击显示代码字节,同样可以实现提取,如下图所示;

我们直接将上方的这些机器码提取出来,从而编写出完整的ShellCode,最终测试代码如下。
#include 上方代码经过编译以后,运行会弹出一个我们自己DIY的MessageBox提示框,输出效果图如下所示;
