欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 作为《Java扩展Nginx》系列的第七篇,咱们来了解一个实用工具共享内存,正式开始之前先来看一个问题
- 在一台电脑上,nginx开启了多个worker,如下图,如果此时我们用了nginx-clojure,就相当于有了四个jvm进程,彼此相互独立,对于同一个url的多次请求,可能被那四个jvm中的任何一个处理:
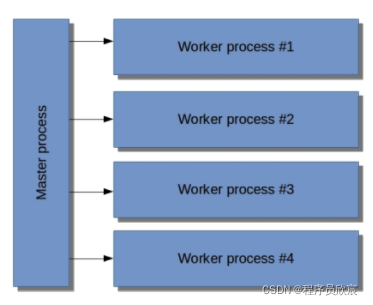
- 现在有个需求:统计某个url被访问的总次数,该怎么做呢?在java内存中用全局变量肯定不行,因为有四个jvm进程都在响应请求,你存到哪个上面都不行
- 聪明的您应该想到了redis,确实,用redis可以解决此类问题,但如果不涉及多个服务器,而只是单机的nginx,还可以考虑nginx-clojure提供的另一个简单方案:共享内存,如下图,一台电脑上,不同进程操作同一块内存区域,访问总数放入这个内存区域即可:
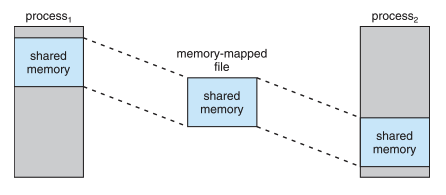
- 相比redis,共享内存的好处也是显而易见的:
- redis是额外部署的服务,共享内存不需要额外部署服务
- redis请求走网络,共享内存不用走网络
-
所以,单机版nginx如果遇到多个worker的数据同步问题,可以考虑共享内存方案,这也是咱们今天实战的主要内容:在使用nginx-clojure进行java开发时,用共享内存在多个worker之间同步数据
-
本文由以下内容组成:
- 先在java内存中保存计数,放在多worker环境中运行,验证计数不准的问题确实存在
- 用nginx-clojure提供的Shared Map解决问题
用堆内存保存计数
- 写一个content handler,代码如下,用UUID来表明worker身份,用requestCount记录请求总数,每处理一次请求就加一:
package com.bolingcavalry.sharedmap;
import nginx.clojure.java.ArrayMap;
import nginx.clojure.java.NginxJavaRingHandler;
import java.io.IOException;
import java.util.Map;
import java.util.UUID;
import static nginx.clojure.MiniConstants.CONTENT_TYPE;
import static nginx.clojure.MiniConstants.NGX_HTTP_OK;
public class HeapSaveCounter implements NginxJavaRingHandler {
/**
* 通过UUID来表明当前jvm进程的身份
*/
private String tag = UUID.randomUUID().toString();
private int requestCount = 1;
@Override
public Object[] invoke(Map map) throws IOException {
String body = "From "
+ tag
+ ", total request count [ "
+ requestCount++
+ "]";
return new Object[] {
NGX_HTTP_OK, //http status 200
ArrayMap.create(CONTENT_TYPE, "text/plain"), //headers map
body
};
}
}
- 修改nginx.conf的worker_processes配置,改为auto,则根据电脑CPU核数自动设置worker数量:
worker_processes auto;
- nginx增加一个location配置,服务类是刚才写的HeapSaveCounter:
location /heapbasedcounter {
content_handler_type 'java';
content_handler_name 'com.bolingcavalry.sharedmap.HeapSaveCounter';
}
- 编译构建部署,再启动nginx,先看jvm进程有几个,如下可见,除了jps自身之外有8个jvm进程,等于电脑的CPU核数,和设置的worker_processes是符合的:
(base) willdeMBP:~ will$ jps
4944
4945
4946
4947
4948
4949
4950
4968 Jps
4943
-
先用Safari浏览器访问/heapbasedcounter,第一次收到的响应如下图,总数是1:

-
刷新页面,UUID不变,总数变成2,这意味着两次请求到了同一个worker的JVM上:

-
改用Chrome浏览器,访问同样的地址,如下图,这次UUID变了,证明请求是另一个worker的jvm处理的,总数变成了1:

-
至此,问题得到证明:多个worker的时候,用jvm的类的成员变量保存的计数只是各worker的情况,不是整个nginx的总数
-
接下来看如何用共享内存解决此类问题
关于共享内存
- nginx-clojure提供的共享内存有两种:Tiny Map和Hash Map,它们都是key&value类型的存储,键和值均可以是这四种类型:int,long,String, byte array
- Tiny Map和Hash Map的区别,用下表来对比展示,可见主要是量化的限制以及使用内存的多少:
| 特性 | Tiny Map | Hash Map |
|---|---|---|
| 键数量 | 2^31=2.14Billions | 64位系统:2^63 32位系统:2^31 |
| 使用内存上限 | 64位系统:4G 32位系统:2G |
受限于操作系统 |
| 单个键的大小 | 16M | 受限于操作系统 |
| 单个值的大小 | 64位系统:4G 32位系统:2G |
受限于操作系统 |
| entry对象自身所用内存 | 24 byte | 64位系统:40 byte 32位系统:28 byte |
- 您可以基于上述区别来选自使用Tiny Map和Hash Map,就本文的实战而言,使用Tiny Map就够用了
- 接下来进入实战
使用共享内存
- 使用共享内存一共分为两步,如下图,先配置再使用:
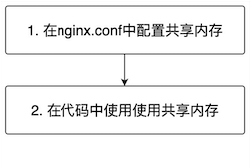
- 现在nginx.conf中增加一个http配置项shared_map,指定了共享内存的名称是uri_access_counters:
# 增加一个共享内存的初始化分配,类型tiny,空间1M,键数量8K
shared_map uri_access_counters tinymap?space=1m&entries=8096;
- 然后写一个新的content handler,该handler在收到请求时,会在共享内存中更新请求次数,总的代码如下,有几处要重点注意的地方,稍后会提到:
package com.bolingcavalry.sharedmap;
import nginx.clojure.java.ArrayMap;
import nginx.clojure.java.NginxJavaRingHandler;
import nginx.clojure.util.NginxSharedHashMap;
import java.io.IOException;
import java.util.Map;
import java.util.UUID;
import static nginx.clojure.MiniConstants.CONTENT_TYPE;
import static nginx.clojure.MiniConstants.NGX_HTTP_OK;
public class SharedMapSaveCounter implements NginxJavaRingHandler {
/**
* 通过UUID来表明当前jvm进程的身份
*/
private String tag = UUID.randomUUID().toString();
private NginxSharedHashMap smap = NginxSharedHashMap.build("uri_access_counters");
@Override
public Object[] invoke(Map map) throws IOException {
String uri = (String)map.get("uri");
// 尝试在共享内存中新建key,并将其值初始化为1,
// 如果初始化成功,返回值就是0,
// 如果返回值不是0,表示共享内存中该key已经存在
int rlt = smap.putIntIfAbsent(uri, 1);
// 如果rlt不等于0,表示这个key在调用putIntIfAbsent之前已经在共享内存中存在了,
// 此时要做的就是加一,
// 如果relt等于0,就把rlt改成1,表示访问总数已经等于1了
if (0==rlt) {
rlt++;
} else {
// 原子性加一,这样并发的时候也会顺序执行
rlt = smap.atomicAddInt(uri, 1);
rlt++;
}
// 返回的body内容,要体现出JVM的身份,以及share map中的计数
String body = "From "
+ tag
+ ", total request count [ "
+ rlt
+ "]";
return new Object[] {
NGX_HTTP_OK, //http status 200
ArrayMap.create(CONTENT_TYPE, "text/plain"), //headers map
body
};
}
}
- 上述代码已经添加了详细注释,相信您一眼就看懂了,我这里挑几个重点说明一下:
- 写上述代码时要牢一件事:这段代码可能运行在高并发场景,既同一时刻,不同进程不同线程都在执行这段代码
- NginxSharedHashMap类是ConcurrentMap的子类,所以是线程安全的,我们更多考虑应该注意跨进程读写时的同步问题,例如接下来要提到的第三和第四点,都是多个进程同时执行此段代码时要考虑的同步问题
- putIntIfAbsent和redis的setnx类似,可以当做跨进程的分布式锁来使用,只有指定的key不存在的时候才会设置成功,此时返回0,如果返回值不等于0,表示共享内存中已经存在此key了
- atomicAddInt确保了原子性,多进程并发的时候,用此方法累加可以确保计算准确(如果我们自己写代码,先读取,再累加,再写入,就会遇到并发的覆盖问题)
- 关于那个atomicAddInt方法,咱们回忆一下java的AtomicInteger类,其incrementAndGet方法在多线程同时调用的场景,也能计算准确,那是因为里面用了CAS来确保的,那么nginx-clojure这里呢?我很好奇的去探寻了一下该方法的实现,这是一段C代码,最后没看到CAS有关的循环,只看到一段最简单的累加,如下图:
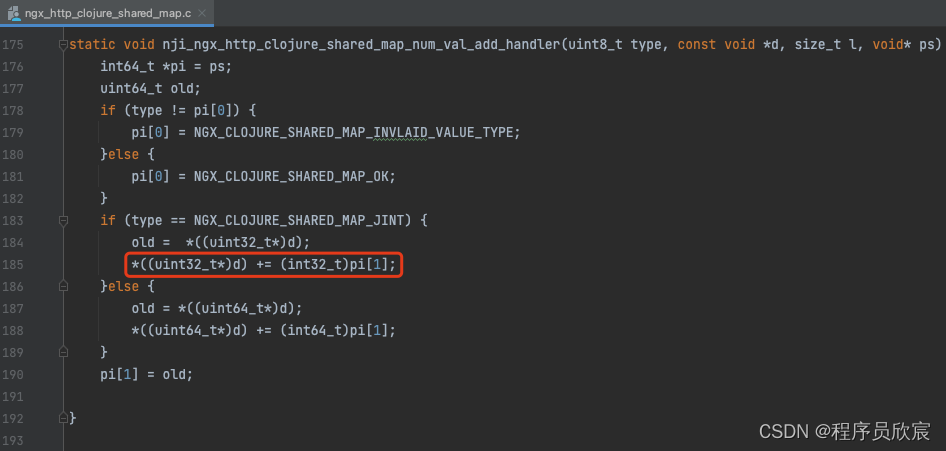
- 很明显,上图的代码,在多进程同时执行时,是会出现数据覆盖的问题的,如此只有两种可能性了,第一种:即便是多个worker存在,执行底层共享内存操作的进程也只有一个
- 第二种:欣宸的C语言水平不行,根本没看懂JVM调用C的逻辑,自我感觉这种可能性很大:如果C语言水平可以,欣宸就用C去做nginx扩展了,没必要来研究nginx-clojure呀!(如果您看懂了此段代码的调用逻辑,还望您指点欣宸一二,谢谢啦)
- 编码完成,在nginx.conf上配置一个location,用SharedMapSaveCounter作为content handler:
location /sharedmapbasedcounter {
content_handler_type 'java';
content_handler_name 'com.bolingcavalry.sharedmap.SharedMapSaveCounter';
}
- 编译构建部署,重启nginx
- 先用Safari浏览器访问/sharedmapbasedcounter,第一次收到的响应如下图,总数是1:

- 刷新页面,UUID发生变化,证明这次请求到了另一个worker,总数也变成2,这意味着共享内存生效了,不同进程使用同一个变量来计算数据:
- 改用Chrome浏览器,访问同样的地址,如下图,UUID再次变化,证明请求是第三个worker的jvm处理的,但是访问次数始终正确:

- 实战完成,前面的代码中只用了两个API操作共享内存,学到的知识点有限,接下来做一些适当的延伸学习
一点延伸
- 刚才曾提到NginxSharedHashMap是ConcurrentMap的子类,那些常用的put和get方法,在ConcurrentMap中是在操作当前进程的堆内存,如果NginxSharedHashMap直接使用父类的这些方法,岂不是与共享内存无关了?
- 带着这个疑问,去看NginxSharedHashMap的源码,如下图,真相大白:get、put这些常用方法,都被重写了,红框中的nget和nputNumber都是native方法,都是在操作共享内存:
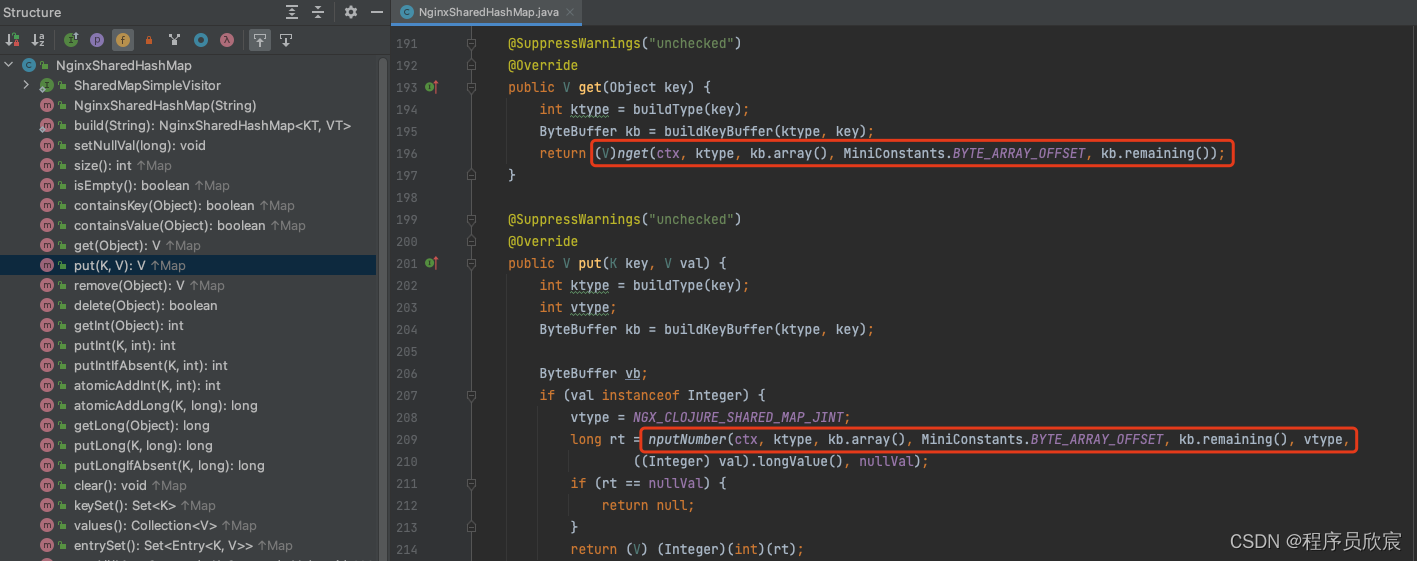
- 至此,nginx-clojure的共享内存学习完成,高并发场景下跨进程同步数据又多了个轻量级方案,至于用它还是用redis,相信聪明的您心中已有定论
源码下载
- 《Java扩展Nginx》的完整源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
- 这个git项目中有多个文件夹,本篇的源码在nginx-clojure-tutorials文件夹下的shared-map-demo子工程中,如下图红框所示:
- 本篇涉及到nginx.conf的修改,完整的参考在此:https://raw.githubusercontent.com/zq2599/blog_demos/master/nginx-clojure-tutorials/files/nginx.conf