一、 torch.nn中Pool layers的介绍#
官网链接:
1. nn.MaxPool2d介绍#
nn.MaxPool2d是在进行图像处理时,Pool layers最常用的函数
(1)torch.nn.MaxPool2d类#
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
(2)参数介绍#
-
kernel_size(int or tuple): 用于设置一个取最大值的窗口,如设置为3,那么会生成一个3×3的窗口
-
stride(int or tuple): 默认值为kernel_size,步幅,和卷积层中的stride一样
-
padding(int or tuple): 填充图像,默认填充的值为0
-
dilation(int): 空洞卷积,即卷积核之间的距离。如卷积核的尺寸为3×3,dilation为1,那么返回一个大小为5×5的卷积核,卷积核每个元素与上下左右的元素之间空一格
-
return_indices(bool): 一般用的很少,不做介绍
-
ceil_mode(bool): 默认为False。为True时,输出的shape使用ceil格式(向上取整,即进一);为False时,输出的shape使用floor格式(向下取整)。
二、最大池化操作#
1. 最大池化操作举例(理论介绍)#
假设有一个5×5的图像和一个3×3的池化核(kenel_size=3),如下图。池化过程就是将池化核与图像进行匹配。下面介绍最大池化的具体操作。
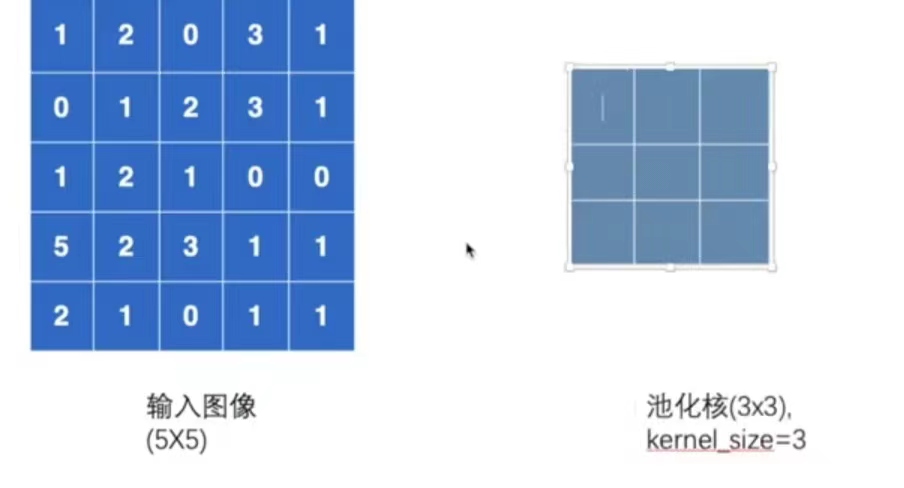
-
首先用池化核覆盖图像,如下图。然后取到最大值,作为一个输出。

-
上图为第一次最大池化操作,最大值为2。将2作为一个输出,如下图。

-
由于本例未对stride进行设置,故stride采取默认值,即stride=kernel_size=3,池化核移动如下图(移动方式与上上文中提到的卷积核移动方式相同,不再赘述)。由于池化核移动已超出范围,要不要取这3×2部分的最大值,取决于call_mode的值,若ceil_mode=True,则取最大值,即输出3;若ceil_mode=False,则不取这部分的值,即这一步不进行池化操作。

-
假设ceil_mode=True,经过最大池化操作后,输出的结果如下图。

-
假设ceil_mode=False,经过最大池化操作后,输出的结果如下图。

-
2. 操作前后的图像大小计算公式#
跟卷积操作的计算公式一样。具体如下:
参数说明:
-
N: 图像的batch_size
-
C: 图像的通道数
-
H: 图像的高
-
W: 图像的宽
计算过程:
-
Input:
-
Output:
-
其中有:
-
看论文的时候,有些比如像padding这样的参数不知道,就可以用这条公式去进行推导
3. 最大池化操作代码举例#
依然选取上面的例子,进行编程。
import torch
from torch import nn
from torch.nn import MaxPool2d
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32) #输入图像数据;与卷积操作不同的是,最大池化操作要求输入的图像数据是浮点数,而不是整数(为整数第23行会报错)
input=torch.reshape(input,(-1,1,5,5)) #构造图像数据,使其符合输入标准,即分别为(输入batch_size待定,1通道,大小为5×5)
print(input.shape) #[Run] torch.Size([1, 1, 5, 5]);数据格式符合输入标准
#构造神经网络
class Demo(nn.Module):
def __init__(self):
super(Demo,self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True) #设置最大池化函数,这里以ceil_mode=True为例
def forward(self,input):
output=self.maxpool1(input) #将输入的数据(input)进行最大池化草子哦
return output
demo=Demo() #创建神经网络
output=demo(input)
print(output)
"""
[Run]
tensor([[[[2., 3.],
[5., 1.]]]])
符合前面ceil_mode=True例子的输出结果一致
"""
4. 为什么要进行最大池化(最大池化的作用)#
-
最大程度地保留输入特征,并使数据量减小
-
上述例子中输入图像为5×5,经过最大池化操作之后变成了3×3,甚至为1×1。使得图像特征得以保留,而数据量大大减少了,对整个网络来说参数减少了,运算速度也变快了
-
打个比方,这就像看视频的时候,高清(输入图像)变(经过最大池化操作)标清(输出数据)
使用具体图片示例,介绍最大池化的作用:
from torch import nn
from torch.nn import MaxPool2d
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloder=DataLoader(dataset,batch_size=64)
#构造神经网络
class Demo(nn.Module):
def __init__(self):
super(Demo,self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True) #设置最大池化函数,这里以ceil_mode=True为例
def forward(self,input):
output=self.maxpool1(input) #将输入的数据(input)进行最大池化草子哦
return output
demo=Demo() #创建神经网络
writer=SummaryWriter("logs_maxpool")
step=0
for data in dataloder:
imgs,targets=data
writer.add_images("input",imgs,step)
output=demo(imgs)
writer.add_images("output",output,step)
step+=1
writer.close()
对比输入输出,可以看出图像更糊了
