传统目标分类器主要包括Viola Jones Detector、HOG Detector、DPM Detector,本文主要介绍HOG Detector与SVM分类器的组合实现行人检测。
HOG(Histograms of Oriented Gradients:定向梯度直方图)是一种基于图像梯度的特征提取方法,被广泛应用于计算机视觉和机器学习领域。由Navneet Dalal和Bill Triggs在2005年提出。
HOG特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,是与SIFT、SURF、ORB属于同一类型的描述符。HOG不是基于颜色值而是基于梯度来计算直方图的,它通过计算和统计图像局部区域的梯度方向直方图来构建特征。HOG特征结合SVM分类器已经被广泛应用到图像识别中,尤其在行人检测中获得了极大的成功。
1. HOG概述
1.1. 主要思想
此方法的基本观点是:局部目标的外表和形状可以被局部梯度或边缘方向的分布很好的描述,即使我们不知道对应的梯度和边缘的位置。(本质:梯度的统计信息,梯度主要存在于边缘的地方)
1.2. 算法实现
首先,将图像分成很多小的连通区域,我们把它叫做cell,然后采集cell中各像素点的梯度大小和方向,然后在每个cell中通过某种方式绘制一个一维的梯度方向直方图。
其次,为了对光照和阴影有更好的不变性,需要对直方图进行对比度归一化,这可以通过把这些直方图在图像的更大的范围内(我们把它叫做区间或者block)进行对比度归一化。我们把归一化的块描述符叫作HOG描述子。
1.3. 目标检测
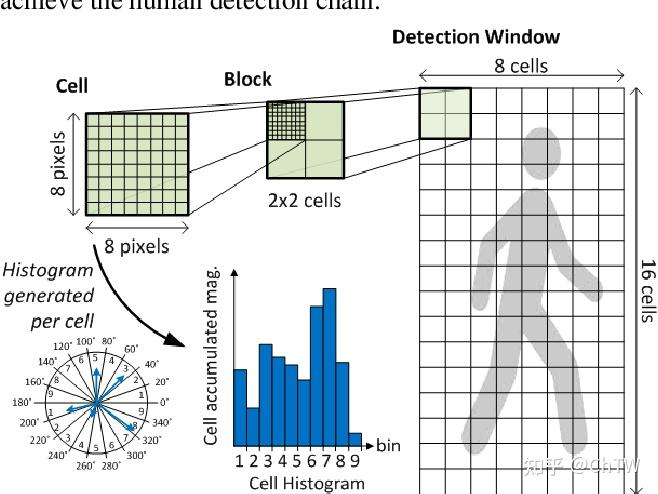
将检测窗口中的所有块的HOG描述子组合起来就形成了最终的特征向量,然后使用SVM分类器进行行人检测。下图描述了特征提取和目标检测流程。检测窗口划分为重叠的块,对这些块计算HOG描述子,形成的特征向量放到线性SVM中进行目标/非目标的二分类。检测窗口在整个图像的所有位置和尺度上进行扫描,并对输出的金字塔进行非极大值抑制来检测目标。(检测窗口的大小一般为128×64128×64)
2. HOG原理
2.1. 图像预处理
- 在与分类器一起使用时,我们需要对图像训练集进行变换大小的处理,大小视情况而定,但不宜过大。在这里我们按照64*128考虑。
- 图像一般为灰度图。但并不要求是灰度图,这是因为彩色图也可以计算梯度图,对于彩色图像,先对三通道颜色值分别计算梯度,然后取梯度值最大的那个作为该像素的梯度。
- Gamma校正。Gamma校正可以理解为提高图像中偏暗或者偏亮部分的图像对比效果,能够有效地降低图像局部的阴影和光照变化。换言之,Gamma校正可以让图片的局部的梯度更“明显”。
Gamma校正公式为:
f(I)=Iγ
其中I为图像像素值,γ为Gamma校正系数。γ系数设定影响着图像的调整效果,结合下图,我们来看一下Gamma校正的作用: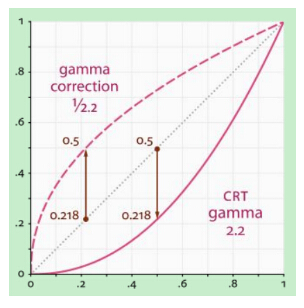
γ<1在低灰度值区域内,动态范围变大,图像对比度增加强;在高灰度值区域,动态范围变小,图像对比度降低,同时,图像的整体灰度值变大;
γ>1在低灰度值区域内,动态范围变小,图像对比度降低;在高灰度值区域,动态范围变大,图像对比度提高,同时,图像的整体灰度值变小;
左边的图像为原图,中间图像的γ=12.2,右图γ=2.2。
作者在他的博士论文里有提到,对于涉及大量的类内颜色变化,如猫,狗和马等动物,没标准化的RGB图效果更好,而牛,羊的图做gamma颜色校正后效果更好。是否用gamma校正需要分析具体的训练集情况。
- 图像模糊,视情况而定。当图像中的噪声过多,且位于非感兴趣区域,那么会导致特征向量的无用信息增多,此时就需要使用图像模糊(一般是高斯模糊);但噪声位于图像的边缘特征位置时(HOG特征是基于边缘的),若使用图像平滑,平滑会降低边缘信息的对比度,从而减少图像中的有用信息。
2.2. cell梯度直方图
像素点的幅值和幅度
首先,利用中心差分近似计算每个像素点对x、y的偏导:
Gx(x,y)=I(x+1,y)−I(x−1,y)
Gy(x,y)=I(x,y+1)−I(x,y−1)
上式中Gx(x,y)、Gy(x,y)分别表示输入图像在像素点(x,y)处的水平方向梯度和垂直方向梯度,该点处的幅值和幅度为:
G(x, y) = √Gx(x, y)2+Gy(x, y)2
α = arctan(Gy(x,y)/Gx(x,y))
cell梯度直方图
为什么要将图像按cell尺寸分割呢?将图像分成cell单元是为了可以用多个cell组合成block,通过block获得较好的特征和抗光照影响。
我们先把整个图像划分为若干个8x8的小单元,称为cell,并计算每个cell的梯度直方图。这个cell的尺寸也可以是其他值,根据具体的特征而定。一个8x8的cell包含了882=128个值,因为每个像素包括梯度的大小和方向。
将cell单元中的幅度作为横轴,幅度对应像素点的幅度的累加值作为相应纵轴值,组成一个梯度直方图。论文作者,将幅度分成9份取得了较为理想的行人检测效果。我们将横轴的角度分成9份,也就是9个bins,每20°为一份(有符号角度是40°为一份),横轴坐标为0, 20, 40, ..., 160。那么横轴值对应的纵轴值该如何计算呢,我们用一个例子来学习: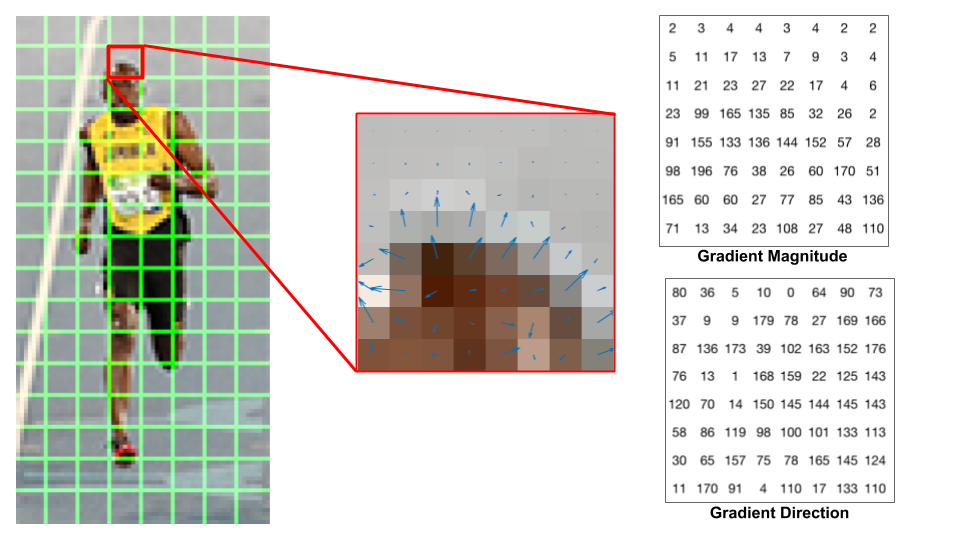
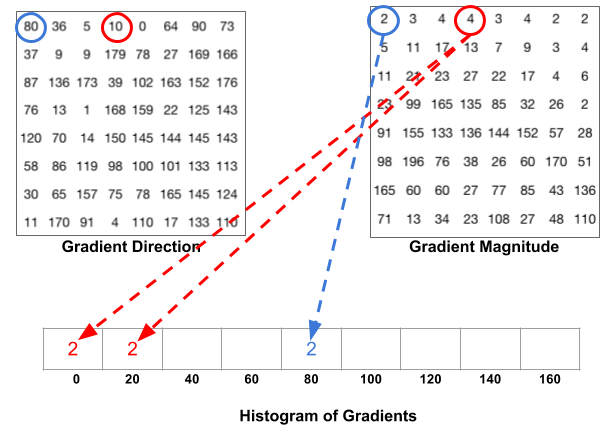
比如上面方向图中蓝圈包围的像素,角度为80度,这个像素对应的幅值为2,所以在直方图80度对应的bin加上2。红圈包围的像素,角度为10度,介于0度和20度之间,其幅值为4,那么这个梯度值就被按比例分给0度和20度对应的bin,也就是各加上2。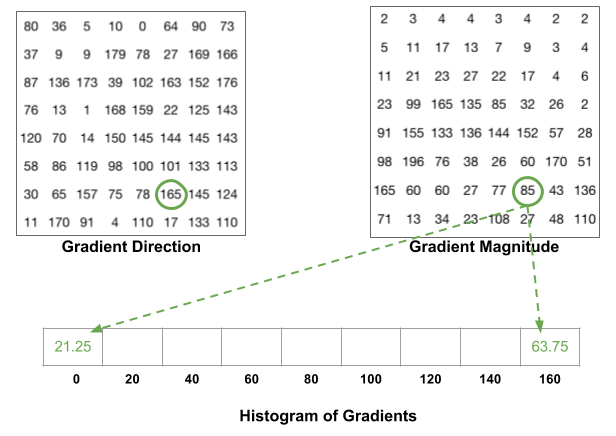
还有一个细节需要注意,如果某个像素的梯度角度大于160度,也就是在160度到180度之间,那么把这个像素对应的梯度值按比例分给0度和160度对应的bin。将这 8x8 的cell中所有像素的梯度值加到各自角度对应的bin中,就形成了长度为9的直方图: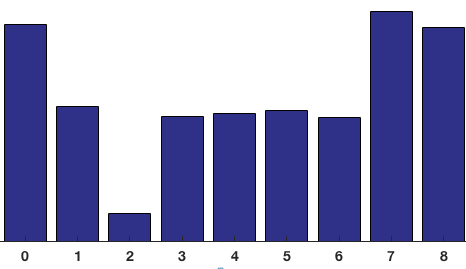
可以看到直方图中,0度和160附近有很大的权重,说明了大多数像素的梯度向上或者向下,也就是这个cell是个横向边缘。现在我们就可以用这9个数的梯度直方图来代替原来很大的三维矩阵,即代替了8x8x2个值。
2.3. Block归一化
于局部光照的变化,以及前景背景对比度的变化,使得梯度强度的变化范围非常大,这就需要对梯度做局部对比度归一化。归一化能够进一步对光照、阴影、边缘进行压缩,使得特征向量对光照、阴影和边缘变化具有鲁棒性。
具体的做法:将细胞单元组成更大的空间块(block),然后针对每个块进行对比度归一化。最终的描述子是检测窗口内所有块内的细胞单元的直方图构成的向量。事实上,块之间是有重叠的,也就是说,每个细胞单元的直方图都会被多次用于最终的描述子的计算。块之间的重叠看起来有冗余,但可以显著的提升性能 。如下动图所示。
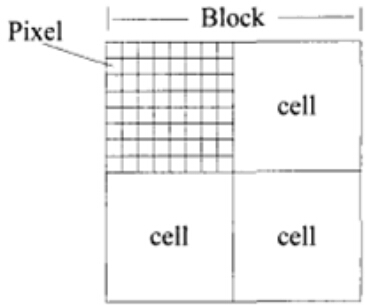
如上图所示,每个block由2×2个cell组成,每一个cell包含8×8个像素点,每个cell提取9个直方图通道,因此一个块的特征向量长度为2×2×9=36。
假设v是未经归一化的特征向量。||v||k是v的k范数,k=1,2,对块的特征向量进行归一化,一般有以下四种方法:
在人体检测系统中进行HOG计算时一般使用L2−norm,Dalal的文章也验证了对于人体检测系统使用L2−norm的时候效果最好。
2.4. 提取HOG特征
最后一步就是对一个样本中所有的块进行HOG特征的提取,并将它们结合成最终的特征向量送入分类器。
那么一个样本可以提取多少个特征呢?之前我们已经说过HOG特征的提取过程:
- 首先把样本图片分割为若干个像素的单元,然后把梯度方向划分为9个区间,在每个单元里面对所有像素的梯度方向在各个方向区间进行直方图统计,得到一个9维的特征向量;
- 每相邻4个单元构成一个块,把一个块内的特征向量串联起来得到一个36维的特征向量;
- 用块对样本图像进行扫描,扫描步长为一个单元的大小,最后将所有的块的特征串联起来,就得到一个样本的特征向量;
例如:对于128×64128×64的输入图片(后面我所有提到的图像大小指的是h×w),每个块由2×2个cell组成,每个cell由8×8个像素点组成,每个cell提取9个bin大小的直方图,以1个cell大小为步长,那么水平方向有15个扫描窗口,垂直方向有7个扫描窗口,也就是说,一共有15∗7∗2∗2∗9=3780个特征。
2.5. 行人检测HOG+SVM
这里我们介绍一下Dalal等人的训练方法:
- 提取正负样本的HOG特征;
- 用正负样本训练一个初始的分类器,然后由分类器生产检测器;
- 然后用初始分类器在负样本原图上进行行人检测,检测出来的矩形区域自然都是分类错误的负样本,这就是所谓的难例(hard examples);
- 提取难例的HOG特征并结合第一步中的特征,重新训练,生成最终的检测器 ;
这种二次训练的处理过程显著提高了每个检测器的表现,一般可以使得每个窗口的误报率(FPPW False Positives Per Window)下降5%。
3. HOG Detector
前面虽然介绍了HOG特征的提取,但是想把HOG特征应用到目标检测上,我们还需考虑两个问题:
- 尺度:对于这个问题可以通过举例说明:假如要检测的目标(比如人)是较大图像中的一部分,要把要检测的图像和训练图像比较。如果在比较中找不到一组相同的梯度,则检测就会失败(即使两张图像都有人)。
- 位置:要检测的目标可能位于图像上的任一个地方,所以需要扫描图像的每一个地方,以取保找到感兴趣的区域,并且尝试在这些区域检测目标。即使待检测的图像中的目标和训练图像中的目标一样大,也需要通过某种方式让opencv定位该目标。
3.1. 图像金字塔
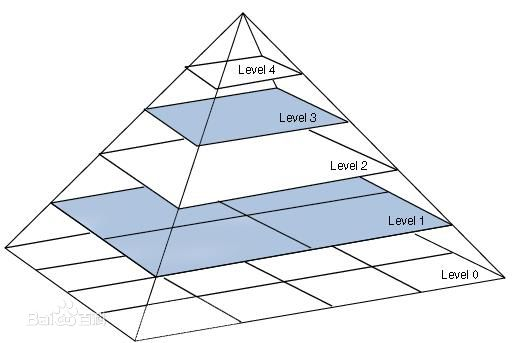
图像金字塔有助于解决不同尺度下的目标检测问题,图像金字塔使图像的多尺度表示,如上图所示。构建图像金字塔一般包含以下步骤:
- 获取图像;
- 使用任意尺度的参数缩放图像;
- 高斯模糊平滑图像(这是由于缩放图像可能会产出噪声);
- 若图像比检测窗口大,则回到第一步开始重复以上过程。
上一节---Viola Jones Detector中我们使用的detectMultiScale()函数就涉及到了图像金字塔,该函数利用scaleFactor参数缩放图像(或检测窗口)实现图像金字塔,scaleFactor越小,金字塔的层数就越多,计算就越慢,计算量也会更大,但是计算结果相对更精确。
3.2. 滑动窗口
滑动窗口是用在计算机视觉的一种技术,它包括图像中要移动部分(滑动窗口)的检查以及使用图像金字塔对各部分进行检测,这是为了在多尺度下检测对象。滑动窗口通过扫描较大图像的较小区域来解决定位问题,进而在同一图像的不同尺度下重复扫描。
使用这种方法进行目标检测会出现一个问题:区域重叠,针对区域重叠问题,我们可以利用非极大值抑制,来消除重叠的窗口。
4. opencv中的行人检测器
opencv附带一个预训练的 HOG + 线性 SVM 模型,可用于在图像和视频流中执行行人检测
首先,使用cv2.HOGDescriptor()实例化HOG特征描述符类;然后再用cv2.HOGDescriptor_getDefaultPeopleDetector()静态函数获取行人检测训练的分类器的系数x;再之后将系数x传入cv2.HOGDescriptor.setSVMDetector()函数,用于激活默认的SVM分类器;最后使用cv2.HOGDescriptor.detectMultiScale()函数实现行人检测,它返回检测到的对象的矩形框和权重值。
语法:cv2.HOGDescriptor(),无需传参
将opencv内置的HOG描述符实例化。
语法:cv2.HOGDescriptor_getDefaultPeopleDetector(),无需传参
获取opencv内置的行人检测训练的分类器的系数x
语法:cv2.HOGDescriptor.setSVMDetector(svmdetector)
参数:svmdetector---svm分类器的系数
用于激活默认的SVM分类器。
语法:cv2.HOGDescriptor.detectMultiScale(img[, foundLocations[, foundWeights[, hitThreshold[, winStride[, padding[, scale[, groupThreshold[, useMeanshiftGrouping]]]]]]]])--->rects, weights
参数:
img---输入的检测图像。
wimStride---表示 HOG 检测窗口移动步幅,它必须是块步幅的倍数。
scale---表示构造金字塔结构图像时使用的缩放因子,默认值为 1.05。
useMeanshiftGrouping---表示是否消除重叠的检测结果。
返回检测到的对象的矩形框和权重值。
import cv2
import tkinter as tk
from tkinter import filedialog
def img_test():
# 获取选择文件路径,人机交互式的选择要测试的图片
# 实例化
root = tk.Tk()
root.withdraw()
# 获取文件的绝对路径路径
return filedialog.askopenfilename()
def is_inside(o, i):
# 判断矩形o是否在矩形i中
ox, oy, ow, oh = o
ix, iy, iw, ih = i
return ox > ix and oy > iy and ox + ow < ix + iw and oy + oh < iy + ih
def detect_test():
img = cv2.imread(img_test())
img_gray = cv2.cvtColor(img, cv2.COLOR_BGRA2GRAY)
# 使用默认的HOG特征描述符
hog = cv2.HOGDescriptor()
# cv2.HOGDescriptor_getDefaultPeopleDetector函数返回为行人检测训练的分类器的系数
detector = cv2.HOGDescriptor_getDefaultPeopleDetector()
# 使用默认的行人分类器(检测窗口64x128)
hog.setSVMDetector(detector)
# 使用detecMultiScale函数检测图像中的行人,返回值为行人对应的矩形框和权重值
found, weight = hog.detectMultiScale(img_gray, scale=1.02)
found_filtered = []
for ri, r in enumerate(found):
for qi, q in enumerate(found):
# r在q内?
if ri != qi and is_inside(r, q):
break
else:
found_filtered.append(r)
for person in found_filtered:
x, y, w, h = person
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 255), 2)
return img
if __name__ == '__main__':
image = cv2.imread('image\\icon.jpg')
cv2.namedWindow('image', cv2.WINDOW_NORMAL)
cv2.imshow('image', image)
while 1:
k = cv2.waitKey()
if k == ord('q'):
break
elif k == ord('n'):
image = detect_test()
cv2.imshow('image', image)
cv2.destroyAllWindows()

5. 参考内容
- 第十九节、基于传统图像处理的目标检测与识别(HOG+SVM附代码) - 大奥特曼打小怪兽 - 博客园
- Gamma校正原理及实现_伽马校正公式_零钱币的博客-CSDN博客
- 一文讲解方向梯度直方图(hog)
- OpenCV: cv::HOGDescriptor Struct Reference
__EOF__
