前言
不知道大家有没有发现,设计模式学习起来其实不容易,并不是说它难,主要是它表达的是思想层面或者说抽象层面的东西,如果你没有实践经历过,感觉就是看了就懂,过了就忘。
所以本人现在也不多花费时间去专门学习设计模式,而是平时在看一些框架源码时,多留意,多学习别人的设计方法和实现思路,在平时工作中,遇到比较复杂的场景,不好看的代码,或者想要更优雅的写法时,再反过来去翻设计模式,这样学习起来印象更加深刻,出去面试时,有解决场景也比背书要更容易说服别人。
这不最近在review同学代码时就发现如下代码,学习的机会不就来了吗~~~
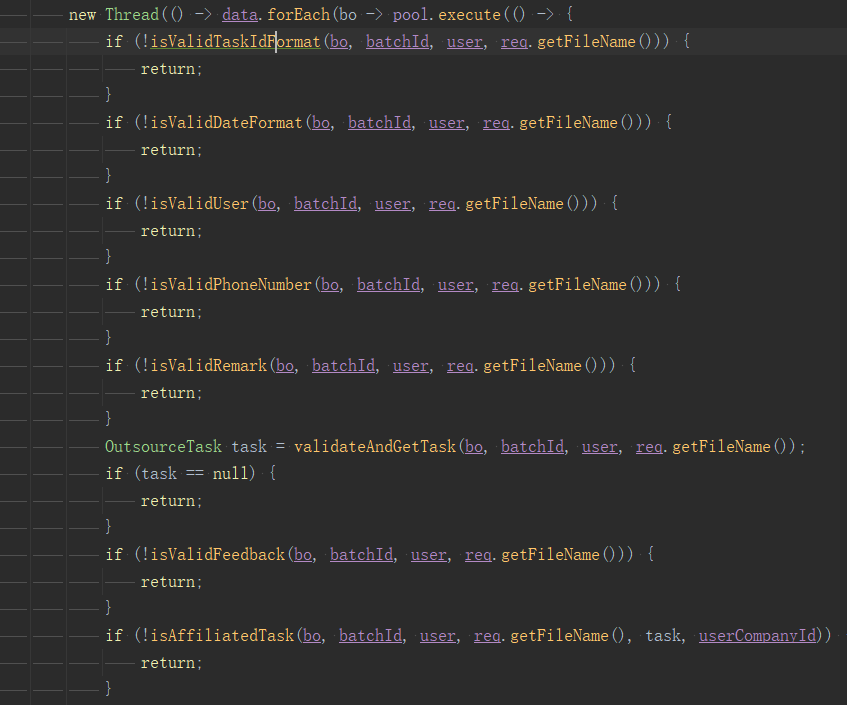
我简单说一下这段代码的逻辑,非常简单,就是要处理客户端上传的一批数据,处理前要校验一下,失败就记录,退出。
从方法命名大概可以看出要校验日期、用户、号码、备注等等,这些校验规则可能会随着业务变化而增减,且它们之前有顺序要求,也就是图中的if不能随意颠倒顺序。
这段代码的缺点很明显,首先它不符合“开闭原则”,每次增减校验都需要来修改主业务流程的代码,没有做到动态扩展。
且在主业务流程里看到如此长的if,真的非常影响阅读体验,if里方法的代码也高度重复,如下:

同时它还会形成“破窗效应”,你说它不好吧,一排if还挺有规则的,以后新加,大概率大家都是继续加if,那这段代码就越来越难看了。
接下来我们就看如何用设计模式中的责任链模式来优化它。
责任链模式
来自百度百科的解释:责任链模式是一种设计模式,在责任链模式里,很多对象由每一个对象对其下家的引用而连接起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。发出这个请求的客户端并不知道链上的哪一个对象最终处理这个请求,这使得系统可以在不影响客户端的情况下动态地重新组织和分配责任。
我们转换成图如下:

在客户端请求与真实逻辑处理之前,请求需要经过一条请求处理链条,其中每个handler可以对请求进行加工、处理、过滤,这与我们上面的业务场景是完全一样的。
网上的uml图都把接口和实现对象定义为XXHandler,但这不是强制,你可以结合实际业务场景来,例如XXInterceotor,XXValidator都可以。
使用责任链模式的优点:(来自chatgpt的回答)
降低耦合度:请求发送者不需要知道哪个对象会处理请求,处理器之间也不需要知道彼此的详细信息,从而降低了系统的耦合度。
动态添加/移除处理器:可以在运行时动态地添加、移除处理器,而不会影响其他部分的代码。
增强灵活性:可以根据具体情况定制处理器的链条,以适应不同的请求处理流程。
遵循开闭原则:当需要新增一种处理方式时,只需创建一个新的具体处理器,并将其添加到链条中,而无需修改现有代码。
案例
本人在看到上面代码,开始想优化思路的时候,实际并不是马上想到责任链模式,这也是开头说的,死记硬背并不牢靠。
我先想到的是一些使用过的工具或组件也有类似的场景,如spring中的拦截器,sentinel中的插槽。
spring拦截器
spring拦截器要实现HandlerInterceptor,它的作用是可以在请求处理前后做一些处理逻辑,如下定义了两个拦截器。


上面只是定义,还是注册到spring中,如下
@Configuration
public class MyInterceptorConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor1());
registry.addInterceptor(new MyInterceptor2());
}
}
接着请求接口就会发现请求依次经过MyInterceptor1,MyInterceptor2,顺序就是我们注册时写的顺序。我们可以猜测spring肯定在请求过程会有一个循环,把所有的拦截器都拿出来依次执行,答案就是HandlerExecutionChain这个类中,从名字就可以看出它是一个Handler执行链,它内部有一个集合保存了本次请求要经过的拦截器,可以看到我们的拦截器也在集合当中。
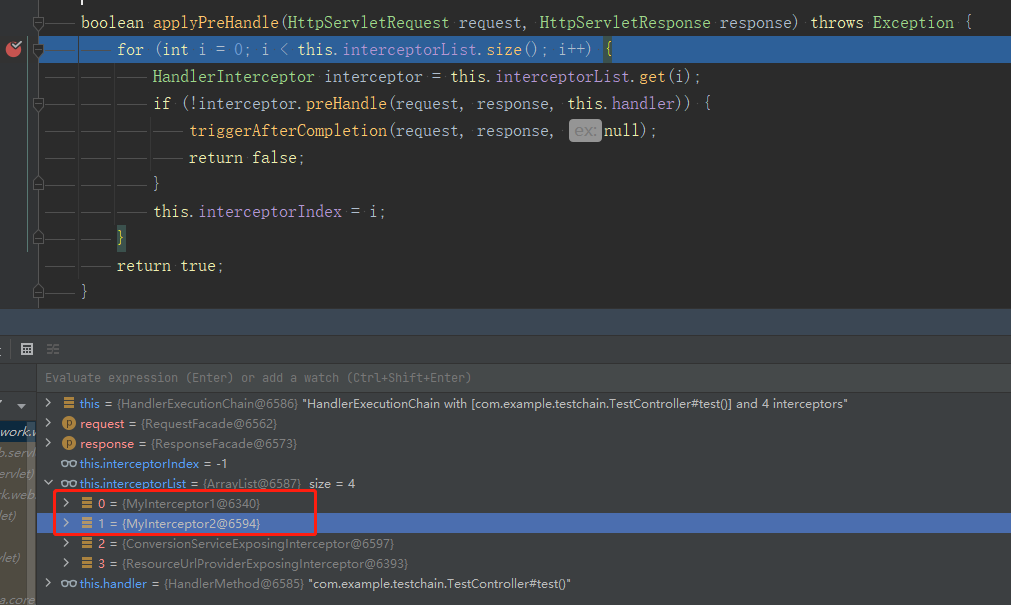
比较类似的servlet Filter也是类似原理,有兴趣的可以对比一下。
sentinel solt
sentinel是阿里的一个流量管理中间件,它的架构图如下:
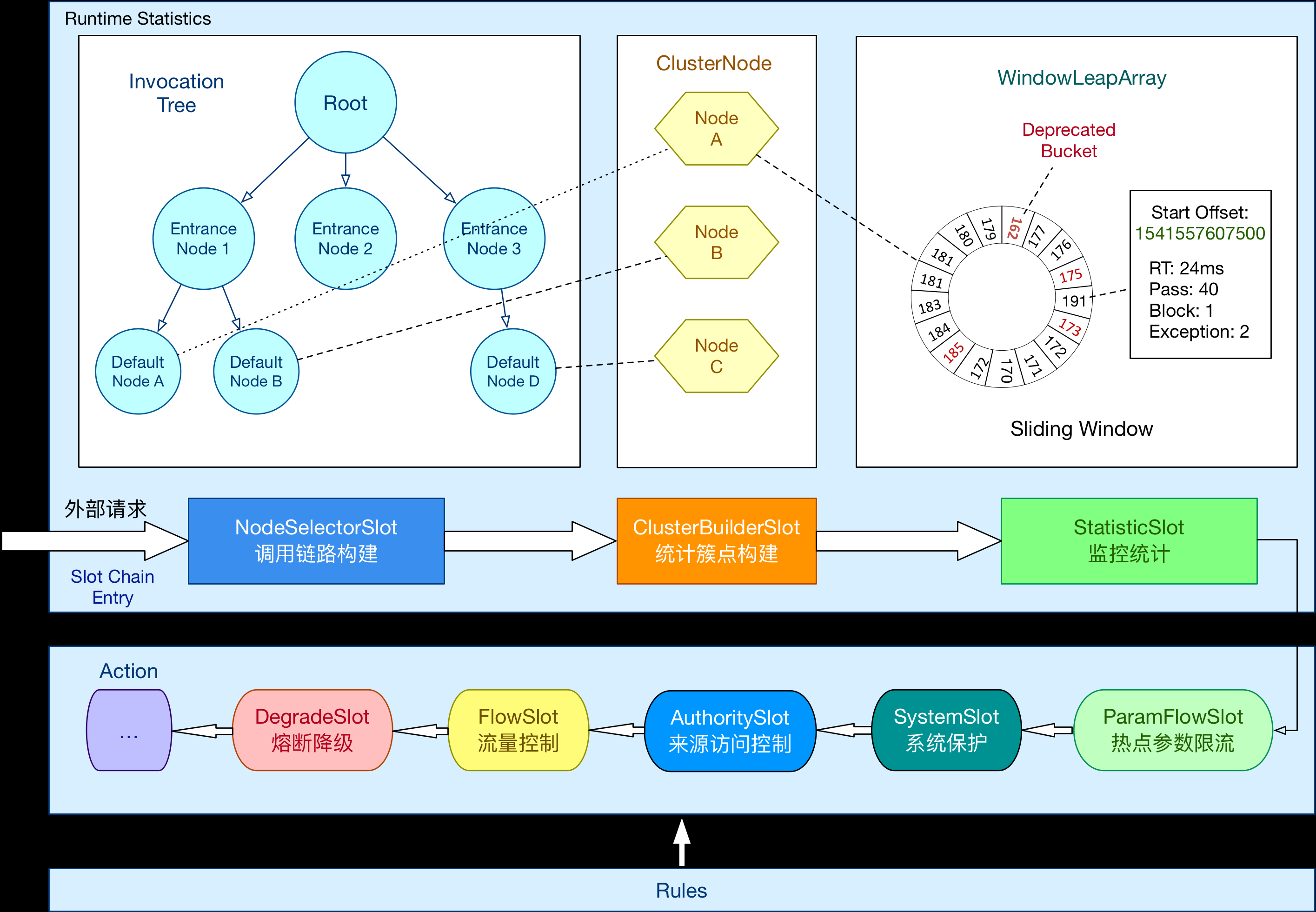
请求会经过一系列称为“功能插槽”的对象,这些对象会对请求进行判断,统计,限流,降级等。
这些对象在sentinel中是实现ProcessorSlot接口的对象,默认为我们提供了8种slot,使用SPI的机制加载,具体配置在sentinel包的META-INF目录下。

从上面架构图可以看出,sentinel的solt会组成一个链表,在它们的基类AbstractLinkedProcessorSlot中的next属性就指向下一个节点,这些solt的顺序就是配置的顺序,也定义在Constants中,可以看到它是以1000为步长,以后想在中间新增一个就比较方便。

/**
* Order of default processor slots
*/
public static final int ORDER_NODE_SELECTOR_SLOT = -10000;
public static final int ORDER_CLUSTER_BUILDER_SLOT = -9000;
public static final int ORDER_LOG_SLOT = -8000;
public static final int ORDER_STATISTIC_SLOT = -7000;
public static final int ORDER_AUTHORITY_SLOT = -6000;
public static final int ORDER_SYSTEM_SLOT = -5000;
public static final int ORDER_FLOW_SLOT = -2000;
public static final int ORDER_DEGRADE_SLOT = -1000;
代码改造
从上面的案例可以看出,设计模式的实现并没有固定的套路,只要设计思想一致就行了,实现方式可以有很多种,spring拦截器使用集合保存,sentinel使用链表,适合才是最好的。
有了上面的知识储备,现在我们可以开始改造代码了,以下代码都经过简写。
首先定义一个校验接口,有一个校验方法,由于原来代码的参数比较多,所以我们定义一个context来包装。
public interface MyValidator {
/**
* 校验
*
* @param context 上下文
* @return 校验失败时的错误码,成功返回null
*/
FeedbackUploadCode valid(ValidateContext context);
}
接着我们定义一个抽象类作为基类,来实现一些代码的复用,其中getNext用于指示下一个校验器,也是我们构建顺序的方式。
public abstract class AbstractMyValidator implements MyValidator {
public abstract AbstractMyValidator getNext();
}
由于校验比较多,我们就拿前两个校验作为两个例子,其中添加一个头节点,作为起始节点,后面每一个校验器只需要实现valid校验逻辑,和说明它的下一个校验器是谁即可,最后一个的next就是null。
class HeadValidator extends AbstractMyValidator {
@Override
public AbstractMyValidator getNext() {
return new TaskIdValidator();
}
@Override
public FeedbackUploadCode valid(ValidateContext context) {
return null;
}
}
class TaskIdValidator extends AbstractMyValidator {
@Override
public AbstractMyValidator getNext() {
return new DateFormatValidator();
}
@Override
public FeedbackUploadCode valid(ValidateContext context) {
try {
Long.parseLong(context.getFileBo().getTaskId());
return null;
} catch (NumberFormatException e) {
return FeedbackUploadCode.ERROR_TASK_ID_FORMAT;
}
}
}
class DateFormatValidator extends AbstractMyValidator {
private static final String DATE_TIME_PATTERN = "yyyy-MM-dd HH:mm:ss";
private static final DateTimeFormatter DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern(DATE_TIME_PATTERN);
@Override
public AbstractMyValidator getNext() {
return null;
}
@Override
public FeedbackUploadCode valid(ValidateContext context) {
try {
LocalDateTime.parse(context.getFileBo().getCollectionTime(), DATE_TIME_FORMATTER);
return null;
} catch (DateTimeParseException e) {
return FeedbackUploadCode.ERROR_DATE_FORMAT;
}
}
}
新增一个Service,对外提供校验方法,核心就是持有校验器的头节点,外部调用只需要组装好上下文,校验方法会通过头节点遍历所有的校验器完成校验。
@Service
public class ValidateService {
@Autowired
private FileDbService fileDbService;
private AbstractMyValidator feedbackValidator = new HeadValidator();
public Boolean valid(ValidateContext context) {
AbstractMyValidator currentValidator = feedbackValidator.getNext();
while (currentValidator != null) {
if (currentValidator.valid(context) != null) {
FeedbackFile file = buildOutsourceFeedbackFile(context.getFileBo(), context.getBatchId(), context.getUser(), context.getFileName());
fileDbService.insert(file);
return false;
}
currentValidator = currentValidator.getNext();
}
return true;
}
private FeedbackFile buildOutsourceFeedbackFile(FileBo fileBo, long batchId, LoginUser user, String fileName) {
FeedbackFile file = new FeedbackFile();
// set value
return file;
}
}
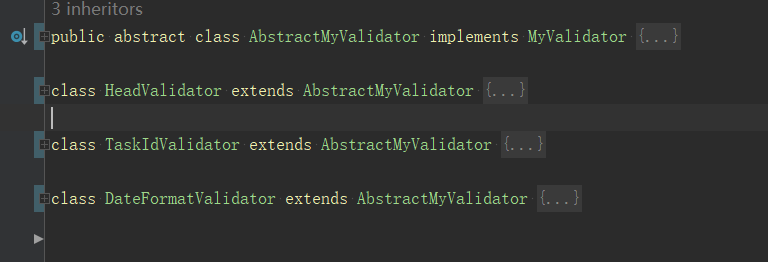
由于校验的规则都比较简单,我们可以把所有的校验器都写到同一个类中,并且代码顺序就是校验的顺序,当然也可以像sentinel一样维护一个顺序值,或者像spring拦截器一样把它们按照顺序添加到集合中。
这样以后新增一个校验规则,就只需要新增一个校验器,并且把它放到链表合适的位置即可,真正做到对扩展开放,对修改封闭。
更多分享,欢迎关注我的github:https://github.com/jmilktea/jtea