-
连Producer端的主线程模块运行原理都不清楚,就敢说自己精通Kafka?
前言
在介绍Producer端原理之前,大家先对其整体架构有一个大致的了解,图示如下所示:
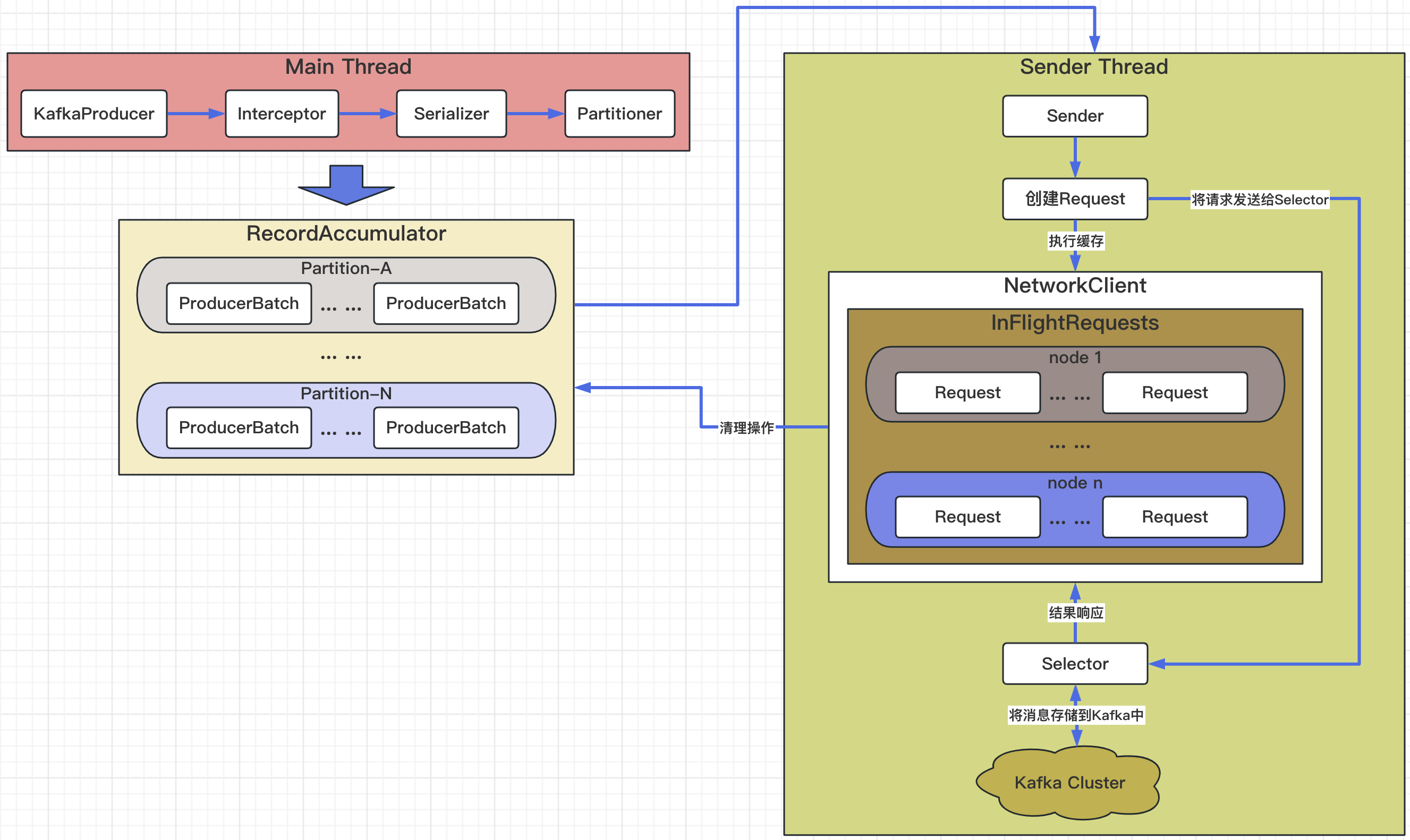
这个图看不懂没有关系,我们会在介绍Producer端原理时一一介绍每个部分的含义及其所复杂的功能。
Main Thread(主线程)
在Main Thread中,一共分为四个步骤,分别是:
KafkaProducer(Kafka生产端)、Interceptor(拦截器)、Serializer(序列化器)和Partitioner(分区器);那么在上个章节中,我们介绍了KafkaProducer端的一些重要参数和使用方式。
本章,就主要针对剩余的3个部分:Interceptor(拦截器)、Serializer(序列化器)和Partitioner(分区器)进行讲解。
1> Interceptor拦截器
Kafka中一共存在两种拦截器,分别是:生产者拦截器(
ProducerInterceptor)和消费者拦截器(ConsumerInterceptor)我们来看一下生产者拦截器的接口定义了哪些方法,如下所示:
- public interface ProducerInterceptor<K, V> extends Configurable {
- /** KafkaProducer会在【将消息序列化】和【计算分区】之前调用该方法,来对消息进行相应的定制化操作 */
- ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
- /** KafkaProducer会在【消息被应答之前/消息发送失败】时调用该方法 */
- void onAcknowledgement(RecordMetadata metadata, Exception exception);
- /** 关闭拦截器(由于此方法可能被KafkaProducer调用多次,所以必须是幂等的)*/
- void close();
- }
在ProducerRecord类中,包含了我们发送消息所需要和信息,这些信息我们都可以在 onSend(ProducerRecord
value值,从而改变消息内容。但是,要注意最好不要修改topic、key和partition等信息,如果要修改,则需确保对其有准确的判断,否则会与预想的效果出现偏差。如下就是ProducerRecord类中包含的待发送消息的属性列表;- public class ProducerRecord<K, V> {
- private final String topic;
- private final Integer partition;
- private final Headers headers;
- private final K key;
- private final V value;
- private final Long timestamp;
- ... ...
- }
那么在ProducerRecord类的 onAcknowledgement(RecordMetadata metadata, Exception exception) 方法中,有如下规律:
【消息发送成功】metadate
不为null,exception为null;
【消息发送失败】metadate为null,exception不为null;所以,我们可以根据上面的规律来判断有哪些消息发送成功,有哪些消息是发送失败了。对于RecordMetadata类中,包含的发送成功后的“回执”信息,如果想要在源码及注释如下所示:
- public final class RecordMetadata {
- public static final int UNKNOWN_PARTITION = -1;
- private final long offset; // 消息的偏移量
- private final long timestamp; // 时间戳
- private final int serializedKeySize; // key的序列化长度
- private final int serializedValueSize; // value的序列化长度
- private final TopicPartition topicPartition; // 主题所在分区
- ... ...
- }
2> Serializer序列化器
由于Producer端发送消息给Kafka之后,待传输的消息对象obj是需要被转换成 字节数组byte[] 之后才能在网络中传送,所以,此处必不可少的一个步骤就是
序列化器Serializer了。而在Consumer端,需要将接收到的字节数组byte[] 再转换成对象obj,那么这个步骤就是反序列化器Deserializer了。Kafka在
org.apache.kafka.common.serialization目录下提供了多种类型预置的序列化器/反序列化,具体如下所示:Deserializer、Serializer、ByteArrayDeserializer、ByteArraySerializer
ByteBufferDeserializer、ByteBufferSerializer、BytesDeserializer、BytesSerializer
DoubleDeserializer、DoubleSerializer、FloatDeserializer、FloatSerializer
IntegerDeserializer、IntegerSerializer、ListDeserializer、ListSerializer
LongDeserializer、LongSerializer、ShortDeserializer、ShortSerializer
StringDeserializer、StringSerializer、UUIDDeserializer、UUIDSerializer
VoidDeserializer、VoidSerializer那么由于本章主要介绍的是Producer端的执行原理,所以我们此时只需关注序列化器
Serializer,该接口如下所示:- public interface Serializer<T> extends Closeable {
- /** 配置当前类 */
- default void configure(Map<String, ?> configs, boolean isKey) {
- }
- /** 将对象data转换为字节数组 */
- byte[] serialize(String topic, T data);
- /** 将对象data转换为字节数组 */
- default byte[] serialize(String topic, Headers headers, T data) {
- return serialize(topic, data);
- }
- /** 关闭序列化器(由于此方法可能被KafkaProducer调用多次,所以必须是幂等的)*/
- @Override
- default void close() {
- }
- }
对于需要实现序列化操作,只需要实现Serialize接口中的方法接口,我们以
StringSerializer为例,看一下它是如何实现的,代码如下所示:- public class StringSerializer implements Serializer<String> {
- private String encoding = StandardCharsets.UTF_8.name(); // 默认编码为UTF-8
- @Override
- public void configure(Map<String, ?> configs, boolean isKey) {
- String propertyName = isKey ? "key.serializer.encoding" : "value.serializer.encoding";
- // 首先尝试从configs中获得"key.serializer.encoding"或"value.serializer.encoding"所配置的值
- Object encodingValue = configs.get(propertyName);
- if (encodingValue == null)
- // 如果没配置,则尝试从configs中获得"serializer.encoding"所配置的值
- encodingValue = configs.get("serializer.encoding");
- if (encodingValue instanceof String)
- encoding = (String) encodingValue; // 如果配置了自定义编码,则赋值给encoding;否则为默认的UTF-8
- }
- @Override
- public byte[] serialize(String topic, String data) {
- try {
- if (data == null) return null;
- else
- return data.getBytes(encoding); // 通过调用String的getBytes方法获得字节数组
- } catch (UnsupportedEncodingException e) {
- throw new SerializationException(...);
- }
- }
- }
在
StringSerializer类中,序列化方式非常简单,就是通过调用String的getBytes方法获得字节数组;除此之外,也可以配置自定义编码。配置方式可以通过向configs中设置key为:"key.serializer.encoding"、"value.serializer.encoding"、"serializer.encoding"这三种,其中serializer.encoding的优先级最低。如果没有配置这3个key,则 默认编码类型就是"UTF-8" ;如果Kafka内置的这几种序列化器都不满足需求,则可以自己实现自定义序列化器(例如:MuseSerializer),然后使用时,在
properties配置中指定即可:Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,MuseSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,MuseSerializer.class.getName());3> Partitioner分区器
构造
ProducerRecord实例对象时,如果在构造方法中指定了partition字段,那么就不需要分区器了;否则,就需要Partitioner分区器来根据key字段计算分区值。ProducerRecord的构造函数如下所示:
当我们没有在
ProducerRecord的构造函数中指定partition字段的时候,就需要分区器起作用了,所有的分区器都需要实现接口Partitioner,该接口有如下三个方法:- public interface Partitioner extends Configurable, Closeable {
- /** 计算给定记录的分区 */
- int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
- /** 关闭分区器(由于此方法可能被KafkaProducer调用多次,所以必须是幂等的)*/
- void close();
- /** 通知分区器即将创建一个新的批处理。当使用sticky分区器时,此方法可以为新批更改选择的sticky分区 */
- default void onNewBatch(String topic, Cluster cluster, int prevPartition) {
- }
- }
在Kafka中默认的分区器是DefaultPartitioner。这里有两条逻辑判断分支,即:keyBytes是否为null(
keyBytes就是key的字节数组)【keyBytes不为null】对keyBytes进行
murmur2哈希计算,然后再基于指定Topic下的所有分片总数进行取余寻址计算。
【keyBytes为null】需要调用StickyPartitionCache的partition(...)方法进行计算。分区逻辑如下所示:
- public class DefaultPartitioner implements Partitioner {
- private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();
- ... ...
- public int partition(String topic, Object key, byte[] keyBytes,
- Object value, byte[] valueBytes, Cluster cluster) {
- return partition(topic, key, keyBytes, value, valueBytes, cluster,
- cluster.partitionsForTopic(topic).size()); // 获得Topic下【所有分片】总数
- }
- public int partition(String topic, Object key, byte[] keyBytes, Object value,
- byte[] valueBytes, Cluster cluster, int numPartitions) {
- // 如果不存在key的序列化值
- if (keyBytes == null)
- return stickyPartitionCache.partition(topic, cluster);
- // 对keyBytes进行哈希计算,并在获得Topic下【所有分片】中寻址
- return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
- }
- ... ...
- }
如果
keyBytes==null,在StickyPartitionCache中如何计算出分区值呢?首先,以主题topic为key,去缓存indexCache中获取分区值part,如果part不为空,则直接返回part,搞定!!如果
part等于null,则说明缓存中没有缓存该topic的分区值,那么就需要计算了,计算步骤如下所示:【步骤1】获得
topic下所有分片集合partitions;
【步骤2】获得topic下所有有效分片集合availablePartitions;
【步骤3】如果不存在有效分片,则获得一个随机数,基于partitions中取余寻址;
【步骤4】如果存在1个有效分片,则获取此分片值;
【步骤5】如果存在多个有效分片,则获得一个随机数,基于availablePartitions中取余寻址;
【步骤6】将topic和分区值维护到缓存indexCache中,并返回分区值;如下则是partition方法的源码及注释,请见如下所示:
- public int partition(String topic, Cluster cluster) {
- Integer part = indexCache.get(topic); // 尝试去缓存中获取,如果获取到,则直接返回
- if (part == null)
- return nextPartition(topic, cluster, -1); // 获得某主题topic的分区号,并将其维护到缓存indexCache中
- return part;
- }
- public int nextPartition(String topic, Cluster cluster, int prevPartition) {
- // 获得topic下所有分片集合
- List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
- Integer oldPart = indexCache.get(topic); // 尝试去缓存中获取分片号,作为旧分片oldPart
- Integer newPart = oldPart;
- if (oldPart == null || oldPart == prevPartition) {
- // 获得Topic下所有【有效分片】集合
- List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
- // 如果不存在有效分片,则获得一个随机数,基于partitions中取余寻址
- if (availablePartitions.size() < 1) {
- Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
- newPart = random % partitions.size();
- }
- // 如果存在1个有效分片,则分配到此处
- else if (availablePartitions.size() == 1) {
- newPart = availablePartitions.get(0).partition();
- }
- // 如果存在多个有效分片,则获得一个随机数,基于availablePartitions中取余寻址
- else {
- while (newPart == null || newPart.equals(oldPart)) {
- int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
- newPart = availablePartitions.get(random % availablePartitions.size()).partition();
- }
- }
- // 维护到缓存indexCache中,主题Topic为key
- if (oldPart == null) indexCache.putIfAbsent(topic, newPart);
- else indexCache.replace(topic, prevPartition, newPart);
- return indexCache.get(topic); // 获得主题Topic的分区号
- }
- return indexCache.get(topic); // 获得主题Topic的分区号
- }
今天的文章内容就这些了:
写作不易,笔者几个小时甚至数天完成的一篇文章,只愿换来您几秒钟的 点赞 & 分享 。
更多技术干货,欢迎大家关注公众号“爪哇缪斯” ~ \(^o^)/ ~ 「干货分享,每天更新」
-
相关阅读:
大数据必学Java基础(十):标识符和关键字
03.OpenWrt-系统固件烧录
停止使用 Storyboards 和 Interface Builder
西安交通大学软件学院学习指南:XJTUSE-GUIDE
Linux常用的调试工具
利用PHP开发具有注册、登陆、文件上传、发布动态功能的网站
R语言简介|你对R语言了解多少?
Towards End-to-End Unified Scene Text Detection and Layout Analysis(2022)
测试工具Requestly
Python Excel 操作 Openpyxl 模块笔记
- 原文地址:https://blog.csdn.net/qq_26470817/article/details/132686395