-
【大数据实训】基于Hive的北京市天气系统分析报告(二)
博主介绍:✌全网粉丝6W+,csdn特邀作者、博客专家、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于大数据技术领域和毕业项目实战✌
🍅文末获取项目联系🍅
目录
- 参考文献 16
1. 引言
1.1 项目背景
近年来随着我国计算机水平的发展,如今的天气网站信息多,想要获取有效的信息需要的时间太长。为了解决社会人员和专业气象人员获取符合自己的并符合自己意向的天气信息,利用Hive对这些天气信息进行收集和分析势在必行。所以需要一种能够具有分析天气系统,可供用户利用自身优势,分析天气信息,从而尽快找到心仪的天气。
通过综合采集北京2005-2022年的天气数据进行了相关统计分析,从温度、每月降水量、每个时间段天气情况、天气词云图等方面进行综合分析。从而帮助专业气象人员想从事气象人员了解相关领域的天气情况。从而为相关人员的快速选择所需天气,在何处选择提供参考,对未来的天气预测等明确方向。
1.2 项目意义
本项目通过对于即将从事天气预报的人员来说,上网快速找到合适的天气系统,无疑是急需的。而如今的天气网站信息多,面对着网上形形色色的天气网站和参差不齐的天气信息,想要获取有效的信息需要的时间太长,这给就业者根据自身的情况选择自己适合的天气系统带来了困难。针对以上不足,有必要通过Hive技术,帮助用户在杂乱无序的数据中寻找有用的数据,科学分析,缩短用户找工作的时间成本,帮助用户快速分析。
本系统采集了北京市2005-2021天气数据,同学们可以通过来选择查看相应的天气信息。同时将这些信息可视化,可以方便同学们快速了解天气分析需求情况,这些可视化的部分包括温度、每月降水量、每个时间段天气情况、天气词云图等。
2.需求分析
本项目共分为五大模块,分别是数据清洗模块,数据存储模块,MapReduce数据分析模块,Hive数据查询模块以及数据可视化模块。
2.1 数据清洗需求分析
数据集存在重复项,数据不规范(如:评分为空,价格为负,价格在三倍标准差之外)等问题。数据集在使用之前需要进行清洗,将重复的数据删除,不规范的数据删除或填补为合理的数据。
2.2 数据存储需求分析
本项目将数据集上传到虚拟机上并存储到HIVE表中。
2.3 MapReduce需求分析
MapReduce数据分析模块,自行设计分析任务并编写MR程序处理这些统计分析任务。本项目主要有以下MR统计分析任务:
1.统计每月降水量占全年的比例; 2.统计每月温度占全年的比例; 3.统计天气情况的比例; 4.统计每个时间段天气占全天的比例; 5.统计每个时间段风向占全天的比例; 2.4 Hive查询需求分析
Hive数据查询模块,自行设计查询条件并编写HQL语句完成查询任务。在虚拟机上编写hql语句并保存为hql文件,使用外部命令执行hql文件,将查询结果打印在控制台或存储到hive表中或存储到指定的txt文件中。本项目设计的Hive查询任务主要有:
1.统计19年-21年每月降水量对比 2.统计19年-21年每月温度情况 3.统计2005年-2022年天气情况词云图 4.统计每个时间段天气情况 5.统计每个时间段风向 2.5 数据可视化需求分析
项目的可视化部分需要包含北京市气象数据分析柱状图和北京市天气比例的饼状图及部分其他可视化图表。数据需要先编写MR或者HQL对原始数据集进行统计分析得出,再通过Flume将统计分析后的数据传入MySql,通过Flask将MySql中的数据传入前端,利用bootstrap框架以及echarts等工具完成可视化。完成模块如下:
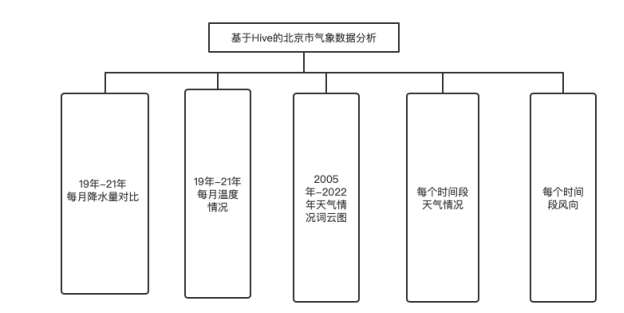
图2.1 数据可视化模块
\3. 开发流程图
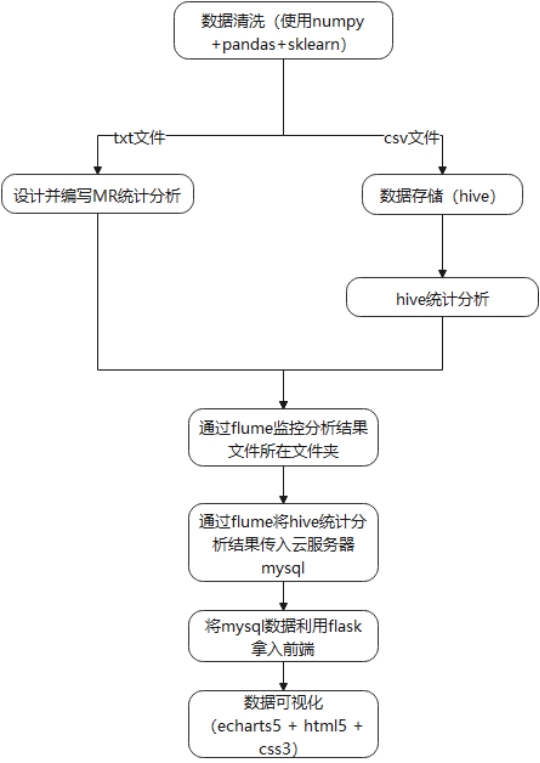
图3.1 流程图
4.项目开发环境
4.1 IntelliJ IDEA 概述
本系统使用IntelliJ IDEA作为程序开发工具。IntelliJ IDEA是java语言开发的集成环境,是基于对象的快速应用程序开发工具,是当今最强大、最灵活的应用程序开发工具之一,具有良好的可视化应用程序开发环境和强大的可扩展数据库功能。IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、 创新的GUI设计等方面的功能可以说是超常的。JAVA语言的特点是面向对象设计的程序语言,具有代码稳定、可读性好、编译速度快等优点,并通过面向对象的概念,使这种基础语言有了新的发展空间。
开发软件通常要经过修改源代码、编译、测试、再修改、再编译、再测试等操作,这些操作形成了一个开发循环,所以快速的编译器可以大大地降低开发周期。JAVA具有强大的整合能力,这也是本系统开发使用IntelliJ IDEA作为程序设计开发语言的重要原因。

图4.1 IntelliJ IDEA community 2021.2
4.2 WebStorm
本次项目使用WebStorm作为前端开发工具。WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。已经被广大中国JS开发者誉为"Web前端开发神器"、“最强大的HTML5编辑器”、"最智能的JavaScript IDE"等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。

图4.2 WebStorm
4.3 PyCharm
PyCharm是一种Python IDE(Integrated Development Environment,集成开发环境),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。

图4.3 PyCharm 2020.01
4.4 Navicat Premium
Navicat Premium 是一套数据库开发工具,可以从单一应用程序中同时连接MySQL、MariaDB、MongoDB、SQL Server、Oracle、PostgreSQL 和 SQLite 数据库。它与 Amazon RDS、Amazon Aurora、Amazon Redshift、Microsoft Azure、Oracle Cloud、MongoDB Atlas、阿里云、腾讯云和华为云等云数据库兼容。可以快速轻松地创建、管理和维护数据库。

图4.4 Navicat Premium 15.0.20
4.5 MySQL 概述
MySQL是一个关系型数据库管理系统。MySQL 使用的 SQL语言是用于访问数据 库的最常用的标准化语言。由于MySQL数据库体积小、速度快、总体拥有成本低、开放源代码,其有着广泛的应用,一般中小型网站的开发都选择 MySQL 作为网站数据库。由于其社区版的性能卓越,因此搭配PHP和Apache服务器可组成良好的开发环境。MySQL API中提供了对Java语言的支持可以让Java写出来的程序直接连接MySQL,并且编程和执行效率都比较高。

图 4.5 Mysql 8.0.27
5.系统实现
5.1 数据清洗
本项目数据清洗于Jupyter Lab中通过python中Numpy、Pandas、Skearn库完成。
此处省略。。。
5.2 数据存储
本项目数据存储于Hive中,通过Hive完成相应数据分析后,将分析结果存储于MySql中,MySql表设计根据任务需求变化。
将数据导入hive
load data local inpath ‘/opt/module/hive-1.1.0/data/usebebehavior.csv’ overwrite into table ods.appRawData;
Hive表设计
此处省略。。。
5.3 MapReduce数据分析
本项目主要使用IDEA编写MR程序,根据需求分析完成MR数据分析任务。本项目设计并完成了以下MR统计分析任务:
1. 统计每月降水量占全年的比例;对于第一个任务统计每个北京市每月降水量占全年比例,在Mapper中对每次读入的字符串进行分割,将北京市作为key,每月作为value传入Reducer,通过重写clean_up函数,统计出全市总降水量,在reduce函数中将每个北京市的每月降水量除以全年得到比例。 2.统计每月温度占全年的比例; 3.统计天气情况的比例;对于第二三个任务统计不同在各自大类中的比例,在Mapper种对每次的字符串进行分割,将作为key,天气温度作为限定条件,将作为value传入Redurcer,通过重写clean_up函数,统计出全,在reduce函数中将每个北京市的各时间段的天气除以全天得到比例。 4.统计每个时间天气占全天的比例; 5.统计每个时间段风向占一天的比例;对于第四五个任务统计不同时间占全天的比例,将北京市作为key,北京市范围选择作为限定条件,将风向作为value传入Rudecer,通过重写clean_up函数,统计出全天,在reduce函数中将各时间段除以全天的比例。 5.4 Hive数据查询
本项目主要在Linux虚拟机上使用Hive进行建表、查询等操作,根据需求分析完成Hive数据查询任务。本项目设计的Hive查询任务主要有:
1. 统计天气情况数据库天气情况的部分分别展示的是气象局对天气的要求数据。天气的要求是从数据库中查询所有的天气类别并返回所有结果,循环这些天气,每次都查询并返回所有天气气象需求天气的结果,对工作要求的数据也是这样的方法进行查询。代码如下。代码:SELECT * FROM airdata.air_temperature;  图5.11
图5.112. 统计词云情况数据库查询以下是词云各天气城市,及天气城市天气天气数,各天气气象台规模的气象台数,执行数据库结果,词云情况数据。代码:SELECT * FROM airdata.airwords 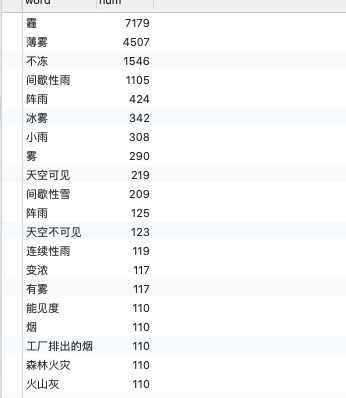 图5.12
图5.123. 统计气象风向情况数据库查询通过对气象风向情况的部分分别查询数据库的气象风向代码:SELECT * FROM airdata.annual_precipitation; 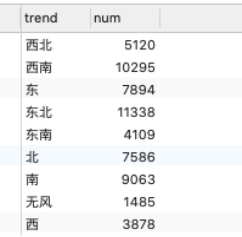 图5.13
图5.134. 气象风向情况数据库查询通过气象风向情况。代码:SELECT * FROM airdata.trend;  图5.14
图5.145. 气象可见度情况数据库查询通过气象可见度情况的部分。代码:SELECT * FROM airdata.visibility; 
图5.15 5.5 数据可视化
数据可视化是最后的步骤,也是最重要的步骤之一,通过数据可视化操作,可以将后端处理的得到的数据通过柱状图、折线图和饼状图等展示在前端界面。
5.5.1 前端设计
通过前端设计,将Hive和MapReduce处理得到的数据展现在web页面中,便于用户直接观察分析结果,将抽象的数据图形化、界面化。
图5.17
5.5.1.1 数据展示模块设计
统计19年-21年每月降水量,如下图所示。

月降水量对比图
统计19年-21年每月温度,如下图所示。

每月降水量对比图
统计2005年-2022年天气情况词云图,如下图所示。

每月降水量对比图
6.项目总结与展望
本次项目对我来说在编程能力以及自学能力上是一个锻炼。通过完成本项目,个人编写MR程序的能力得到了一定的提高;通过网上学习Hive的hql语句,我能够写语法较为复杂的查询语句,通过课外学习echarts,我了解了echarts制图的基本步骤,会使用echarts制作一些简单的图表。第一次接触echarts,原来数据可视化是这么好玩的东西,它不像后端只有冷冰冰的数据显示在控制台,它以绚丽多彩、通俗易懂的方式将数据呈现在你的面前。除了使用echarts制作图表,还学习了CSS和JS语言的基本使用,将其应用到网页界面的设计,结合echarts图表制作数据可视化大屏。
本次项目可以说是数据可视化入了个门,毕竟之前没怎么接触过。更深的学习就需要自己去钻研了。本次实训项目是一人一组,通过本次项目的制作,也使我们更懂得独立开发时,要清楚项目的脉络,自己应该做的各个方面的功能实现。
7. 参考文献
[1] 孟小峰, 慈祥. 大数据管理:概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(001):146-169.
[2] 王珊, 王会举, 覃雄派,等. 架构大数据:挑战、现状与展望[J]. 计算机学报, 2011, 034(010):1741-1752.
[3] 李建中, 刘显敏. 大数据的一个重要方面:数据可用性[J]. 计算机研究与发展, 2013.
[4] 朱建平, 章贵军, 刘晓葳. 大数据时代下数据分析理念的辨析[J]. 统计研究, 2014, 031(002):10-19.
[5] 李国杰, 程学旗. 大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J]. 中国科学院院刊, 2012, 27(6):647-657.
[6] 陶雪娇, 胡晓峰, 刘洋. 大数据研究综述[J]. 系统仿真学报, 2013(S1):145-146.
[7] 任磊, 杜一, 马帅,等. 大数据可视分析综述[J]. 软件学报, 2014, 000(009):1909-1936.
[8] 孙大为, 张广艳, 郑纬民. 大数据流式计算:关键技术及系统实例[J]. 软件学报, 2014(04):839-862.
[9] 袁昌权, 胡益群, 许光,等. 基于Hadoop的高可用数据采集与存储方案[J]. 电子技术与软件工程, 2019, No.164(18):185-186.
[10] Dean J . MapReduce : Simplified Data Processing on Large Clusters[C]// Symposium on Operating System Design & Implementation. 2004.
-
相关阅读:
Java8 BiConsumer<T, U> 函数接口浅析分享(含示例,来戳!)
商城多语言改造方案
BeanFactory和ApplicationContext有什么区别
【考研数学】一. 极限与导数
如何封装js来调用各开放平台打印组件,实现同步效果
【3D建模全流程教学】在 ZBrush、Maya 和 Marvelous Designer 中制作一位逼真的女孩
Vue太难啦!从入门到放弃day06——Vue前端路由
PHP写一个电商 Api接口需要注意哪些?考虑哪些?
PWM控制舵机
Linux中jar包实现自动重启、开机自启方案
- 原文地址:https://blog.csdn.net/xianyu120/article/details/132651233