-
【hadoop】部署hadoop的伪分布模式
hadoop的伪分布模式
伪分布模式的特点
- 在单机上,模拟一个分布式的环境
- 具备Hadoop的所有的功能
- 用于开发和测试
-
HDFS:NameNode、DataNode、SecondaryNameNode- 1
-
Yarn:ResourceManager、NodeManager- 1
部署伪分布模式
前提:部署好hadoop的本地模式
点击设置hadoop的本地模式伪分布模式的部署主要是将下面的参数文件的配置参数进行更改。
hadoop-env.sh
注:如果在本地模式已经配置完成,这个文件则不需要重复配置。
路径:/root/training/hadoop-2.7.3/etc/hadoop($HADOOP_HOME/etc/hadoop)
更改第25行 export JAVA_HOME=/root/training/jdk1.8.0_181
hdfs-site.xml
进入 /root/training/hadoop-2.7.3/etc/hadoop/ 路径找到 hdfs-site.xml 文件进行编辑。

vi hdfs-site.xml- 1
将下面xml代码添加该文件
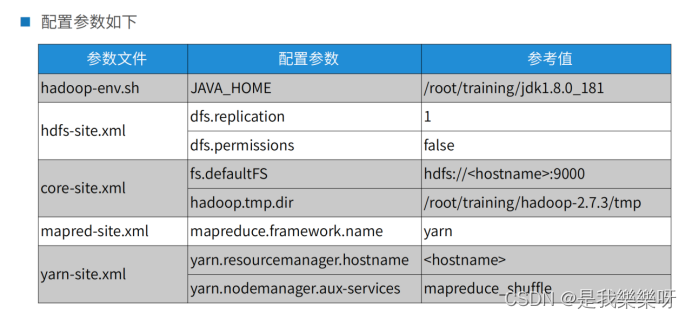
<property> <name>dfs.replicationname> <value>1value> property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
core-site.xml
需要在hadoop目录下,先创建出tmp文件,作为HDFS对应的操作系统目录。
mkdir /root/training/hadoop-2.7.3/tmp- 1
编辑操作与上面文件相同,则不演示。
<property> <name>fs.defaultFSname> <value>hdfs://bigdata111:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/root/training/hadoop-2.7.3/tmpvalue> property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
mapred-site.xml
这个文件默认没有,需要我们先复制
cp mapred-site.xml.template mapred-site.xml- 1
<property> <name>mapreduce.framework.namename> <value>yarnvalue> property>- 1
- 2
- 3
- 4
- 5
yarn-site.xml
<property> <name>yarn.resourcemanager.hostnamename> <value>bigdata111value> property> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对NameNode进行格式化
执行下面这条命名
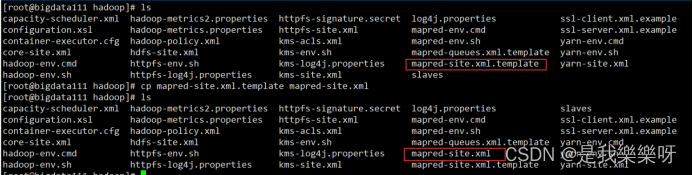
hdfs namenode -format- 1
成功则出现下面这句话。
启动Hadoop
start-all.sh- 1
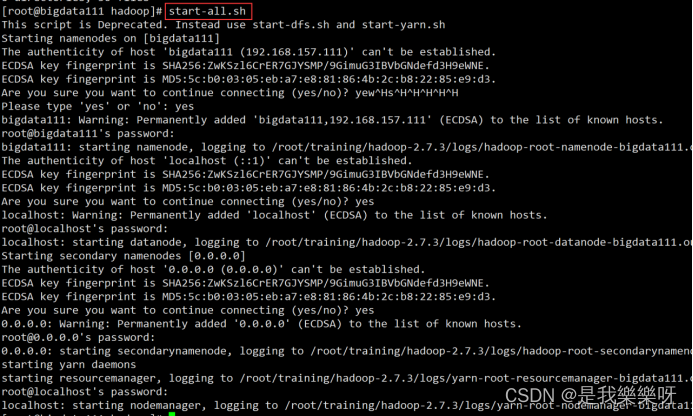
需要输入4次密码和yes。
至此部署完成,下面进行测试!
对部署是否完成进行测试
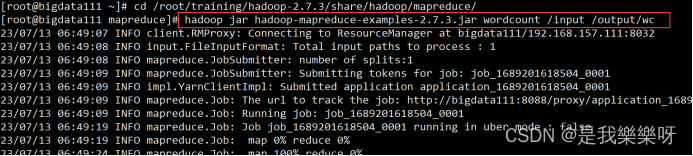
将本地文件上传到hdfs

进入/root/training/hadoop-2.7.3/share/hadoop/mapreduce/hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output/wc- 1
停止集群
stop-all.sh- 1
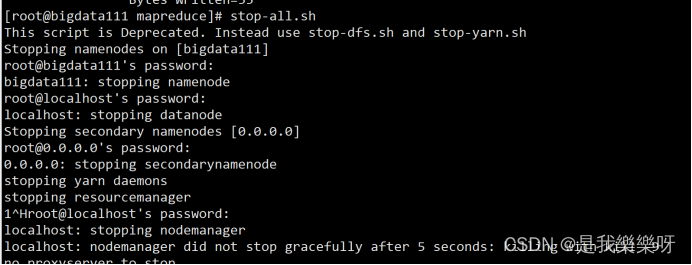
也需要输入4次密码,输入密码太麻烦,所以我们还需要配置免密码模式。
免密码模式
免密码模式的原理(重要)
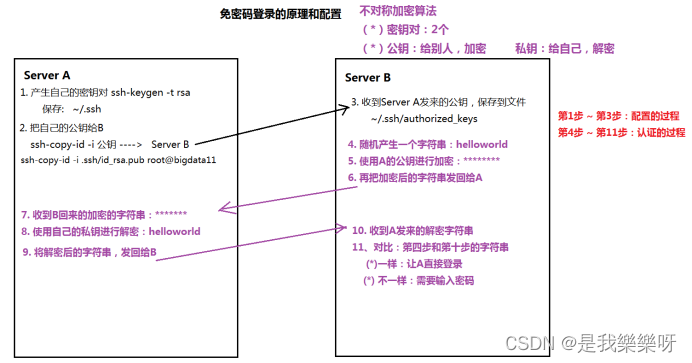
免密码模式的配置
ssh-keygen -t rsa- 1
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata111- 1
注:root@bigdata111 是你当前的主机名


免密码模式配置完成!
-
相关阅读:
游戏服务器价格对比分析,2024高主频高性能服务器租用价格
Java:谁是Java开发人员?这个职业现在很抢手吗?
【Linux 网络编程 】
百度边止血边扩张
STM32之HAL开发——CubeMX配置串行Flash文件系统
C#开发的OpenRA游戏之世界存在的属性RenderDebugState(5)
项目进度网络图
牛客网刷题篇
以“防方视角”观Shiro反序列化漏洞
智慧校园数字孪生三维可视化综合解决方案:PPT全83页,附下载
- 原文地址:https://blog.csdn.net/qq_43495411/article/details/131734434