-
ARMv8内存模型
系列上篇:ARMv8 异常模型
地址空间
虚拟地址空间
内核空间和用户空间有单独的转换表,这意味着它们的映射可以分开保存。EL0/EL1 使用左边的地址空间,EL2/EL3使用右边的。两者 的空间范围如图所示,是可伸缩的。任何超出配置范围的地址在被访问时都会生成异常作为转换错误

Cache

基本概念
PoU是以一个特定的PE(该PE执行了cache相关的指令)为视角。PE需要透过各级cache(涉及instruction cache、data cache和translation table walk)来访问main memory,这些操作在memory hierarchy的某个点上(或者说某个level上)会访问同一个copy,那么这个点就是该PE的Point of Unification。假设一个4核cpu,每个core都有自己的L1 instruction cache和L1 Data cache,所有的core共享L2 cache。在这样的一个系统中,PoU就是L2 cache,只有在该点上,特定PE的instruction cache、data cache和translation table walk硬件单元访问memory的时候看到的是同一个copy。
PoC可以认为是Point of System,它和PoU的概念类似,只不过PoC是以系统中所有的agent(bus master,又叫做observer,包括CPU、DMA engine等)为视角,这些agents在进行memory access的时候看到的是同一个copy的那个“点”。例如上一段文章中的4核cpu例子,如果系统中还有一个DMA controller和main memory(DRAM)通过bus连接起来,在这样的一个系统中,PoC就是main memory这个level,因为DMA controller不通过cache访问memory,因此看到同一个copy的位置只能是main memory了。Cache结构、映射方式
通过使用不同的映射方式,我们的目的是更快的查找cache。
Basic
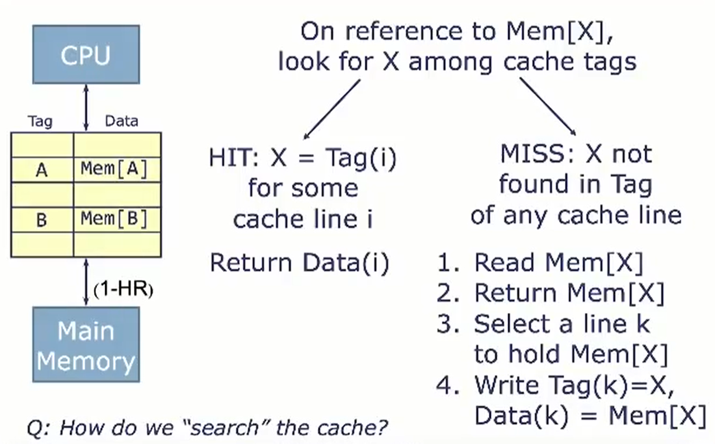
X表示物理地址,我们依次比较x和Tag,如果x = Tag,则说明缓存命中,返回对应的data。
如果没有命中,则从主存中读取Mem[x],然后再把Mem[x]存到cache中。
这种方式需要依次遍历每个cache line,并且比较Tag和X的每一位。肯定是很慢的。Direct-Mapped

增加了一个Valid bit。 Valid = 0:数据无效。 Valid = 1:数据有效
首先通过index为,找到对应的cache line。然后比较Tag段是否相同。如果valid = 1并且Tag段相同,则认为缓存命中。通过offset找到具体位置。优点:硬件设计上会更加简单、成本也较低
缺点: 容易出现cache冲突,影响性能问题
映射冲突问题:
直接映射中,每个index对应一个特定的cache line,主存容量又远大于cache,就会导致访问冲突的问题。
解决方式:若这个位置已有内容,则产生块冲突并将原块无条件的替换出去
可以看到,这样效率很低。举例,解释index

假设一个64字节的cache,一共有8行cache line,cache line大小是8 Bytes。所以我们可以利用地址低3 bits(如上图地址蓝色部分)用来寻址8 bytes中某一字节,我们称这部分bit组合为offset。同理,8行cache line,为了覆盖所有行。我们需要3 bits(如上图地址黄色部分)查找某一行,这部分地址部分称之为index。现在我们知道,如果两个不同的地址,其地址的bit3-bit5如果完全一样的话,那么这两个地址经过硬件散列之后都会找到同一个cache line(此时就会产生映射冲突)。所以,当我们找到cache line之后,只代表我们访问的地址对应的数据可能存在这个cache line中,但是也有可能是其他地址对应的数据。所以,我们又引入tag array区域,tag array和data array一一对应。每一个cache line都对应唯一一个tag,tag中保存的是整个地址位宽去除index和offset使用的bit剩余部分(如上图地址绿色部分)。tag、index和offset三者组合就可以唯一确定一个地址了。Why do we chose low order bits for index?
举例,对于地址0x128,其二进制位为0~0001 0010 1000.其高位全是0,如果使用高位作为index,则很多地址都会映射到同一cache line。使用地位可以减少映射冲突
Fully-Associative
与直接映射相比的另一种极端,不实用index(即意味着内存可以映射到cache中的任意一行),只使用Tag来查找数据。

优点:最大程度的降低cache颠簸的频率
缺点: 增加硬件设计复杂读、成本较高(需要比较多个cache line的TAG)N-way Set-Associative (N路组相连映射)
结构介绍:way表示路,set表示组。一个cache可被分为若干个路,每个路有若干组,每个组有若干个cacheline。
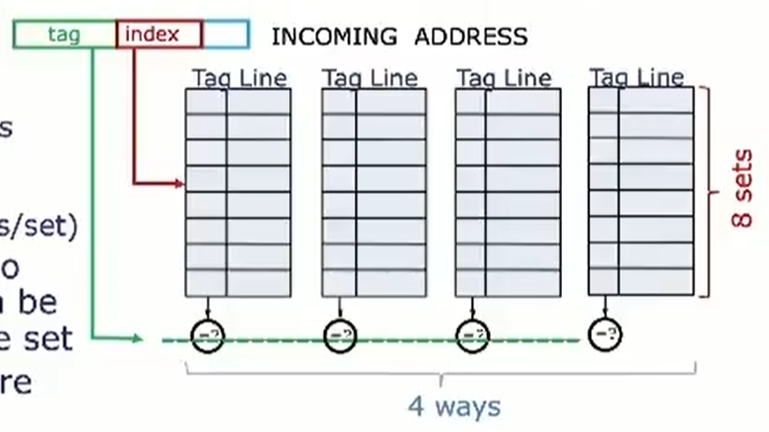
优点:减少cache颠簸出现频率
缺点: 增加硬件设计复杂读、成本较高(需要比较多个cache line的TAG)
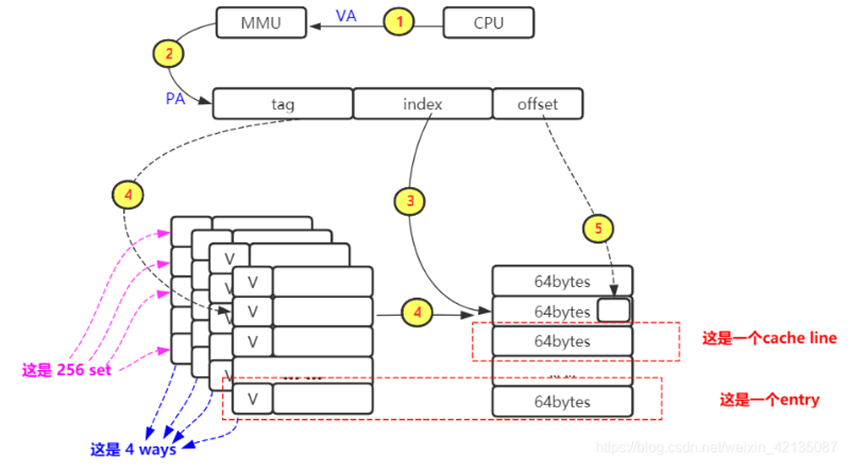
**举例:**L1-dcache :一个大小64KB的cache,4路256组相连,cache line为64bytes
在L1-dcache中的查询过程: cpu发起一个虚拟地址,经过MMU转换为物理地址,根据index去查找cache line(因为是四路相连的cache,所以可以查询到4个并行的cache line),然后对比TAG(先看invalid位,再对比TAG值),然后再根据offset找到具体的bytes取出数据
映射冲突问题:
此时,因为多路是并行的,所以每个index指向两个或者更多 cache line,这些cache line属于不同的set,所以可以有效减少冲突。Write Back
首先,正常写入0x09到0x4818,同时置D位为1.




此时发现D位为1,并且Tag位不同,发生了映射冲突。需要先将cache line写回到主存中(起始位置即 Tag + index + block off + Byte off,,),然后从主存的0x48位置读取一行数据到cache中,此时cache line变成了第二张图。然后再将0x09写到对应位置。

缓存一致性:MESI协议
MESI分别代表缓存行数据所处的四种状态,通过对这四种状态的切换,来达到对缓存数据进行管理的目的。
- M:表示当前CPU的高速缓存中的变量副本是独占的,而且和主存中的变量值不一致,而且别的CPU的flag不可能是这个状态。如果别的CPU想要读取变量的值,不能直接读主内存中的值,而是需要将处于M状态的变量刷新回主内存才可以。
- E:表示当前CPU的高速缓存中的变量副本是独占的,别的CPU高速缓存中该变量的副本不能处于该状态,但是,处于E状态的高速缓存变量的值和主内存中的变量值是一致的。
- S:处于S状态表示CPU中的变量副本和主存中数据一致,而且多个CPU都可以处于S状态,举例,当多个CPU读取主内存的值的时候高速缓存的flag就处于S状态。
- I:表示当前CPU的高速缓存的变量副本处于不合法状态,不可以直接使用,需要从主内存重新读取,flag的初始状态就是I。
备注:
MESI协议在以下两种情况中也会失效:
a. CPU不支持缓存一致性协议。
b. 该变量超过一个缓存行的大小,缓存一致性协议是针对单个缓存行进行加锁,此时
缓存一致性协议无法再对该变量进行加锁,只能改用总线加锁的方式。MESI工作原理
缓存一致性协议通过监控独立的loads和stores指令来监控缓存同步冲突,并确保不同的处理器对于共享内存的状态有一致性的看法。当一个处理器loads或stores一个内存地址a时,它会在bus总线上广播该请求,其他的处理器和主内存都会监听总线(也称为snooping)。
1、CPU1从内存中将变量a加载到缓存中,并将变量a的状态改为E(独享),并通过总线嗅探机制对内存中变量a的操作进行嗅探
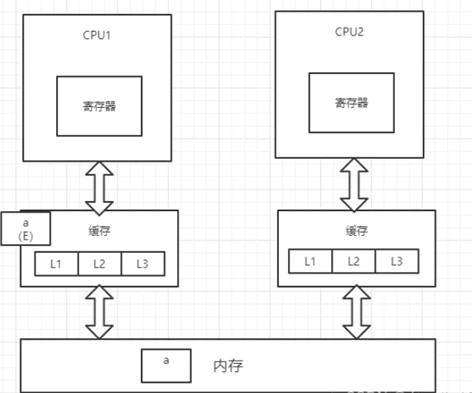
2、此时,CPU2读取变量a,总线嗅探机制会将CPU1中的变量a的状态置为S(共享),并将变量a加载到CPU2的缓存中,状态为S

3、CPU1对变量a进行修改操作,此时CPU1中的变量a会被置为M(修改)状态,而CPU2中的变量a会被通知,改为I(无效)状态,此时CPU2中的变量a做的任何修改都不会被写回内存中(高并发情况下可能出现两个CPU同时修改变量a,并同时向总线发出将各自的缓存行更改为M状态的情况,此时总线会采用相应的裁决机制进行裁决,将其中一个置为M状态,另一个置为I状态,且I状态的缓存行修改无效)

4、CPU1将修改后的数据写回内存,并将变量a置为E(独占)状态

5、此时,CPU2通过总线嗅探机制得知变量a已被修改,会重新去内存中加载变量a,同时CPU1和CPU2中的变量a都改为S状态

在上述过程第3步中,CPU2的变量a被置为I(无效)状态后,只是保证变量a的修改不会被写回内存,但CPU2有可能会在CPU1将变量a置为E(独占)状态之前重新读取内存中的变量a,这个取决于汇编指令是否要求CPU2重新加载内存。
伪共享
可能会把多个变量存放到一个Cache行中。如果此时有另一个处理器也想访问临近的数组成员,这就回导致这个cache line被频繁的导入导出,造成很大的性能问题。所以这就是cache伪共享。
处理伪共享的两种方式:- 字节填充:增大元素的间隔,使得不同线程存取的元素位于不同的cache line上,典型的空间换时间。
- 在每个线程中创建对应元素的本地拷贝,结束后再写回。
DMA和Cache的一致性
DMA(Direct Memory Access)直接内存访问,它在传输过程中是不需要CPU干预的,可以直接从内存中读写数据。负责搬移内存的任务。可以将内存从一些繁杂的数据搬移任务中解放出来。
但当DMA和cache在一起时,会发现使用DMA获得的数据和cache中的数据不一致。出现这个问题的原因是:DMA修改的内存,在 cache中有缓存,但是CPU并不知道内存数据被修改了,CPU依然去访问cache的旧数据,导致Cache一致性问题。从内存到设备FIFO
传输路径:内存->设备FIFO (设备例如网卡,通过DMA读取内存数据到设备FIFO)
这种场景下,通常都是CPU的软件来产生了新的数据,然后通过DMA数据搬到设备的FIFO里。
在DMA传输之前,可能这块内存在cache中有缓存,那内存中的这部本其实有可能就是过时的数据,所以需要调用cache clean/flush操作,把cache内容写入到内存中。然后再启动DMA传输数据,把DMA buffer的数据传输到设备的FIFO。

从设备FIFO到内存
传输路径:设备FIFO -> 内存 (设备把数据写入到内存中)
设备的FIFO产生了新数据,需要把数据写入到内存里,然后CPU就可以读到设备的数据,类似网卡的收包的过程。
在DMA传输之前,最新的数据是在设备的FIFO里,此时cache里的数据就是旧的无效数据,我们要先将其invalid,然后再启动DMA传输。

相关指令
Armv8里定义的Cache的管理的操作有三种:
-
无效(Invalidate) 整个高速缓存或者某个高速缓存行。高速缓存上的数据会被丢弃。- 1
-
清除(Clean) 整个高速缓存或者某个高速缓存行。相应的高速缓存行会被标记为脏,数据会写回到下一级高速缓存中或者主存储器中。- 1
-
清零(Zero) 在某些情况下,对高速缓存进行清零操作起到一个预取和加速的功效,比如当程序需要使用一大块临时内存,在初始化阶段对这个内存进行清零操作,这时高速缓存控制器会主动把这些零数据写入高速缓存行中。若程序主动使用高速缓存的清零操作,那么将大大减少系统内部总线的带宽。- 1
对高速缓存的操作可以指定不同的范围。
- 整块高速缓存。
- 某个虚拟地址。
- 特定的高速缓存行或者组和路。
当对一个高速缓存行进行操作时,我们需要知道高速缓存操作的范围。ARMv8架构中从处理器到所有内存的角度分成如下几个视角。
- PoC(Point of Coherency,全局缓存一致性角度):从全局角度,保证同一数据在所有相同cache内存位置,保持一致性
- PoU(Point of Unification,处理器缓存一致性角度:从单个处理器角度,保证数据一致性



Cache on Reset
MMU


Page fault:延时分配内存(bss段),写时拷贝TLB(Translation Lookaside Buffers)
TLB也是一种cache,其保存虚拟地址对应的物理地址,从而节省查表的过程。
如图所示,V:有效位。D:脏位。通过比较Tag,得到正确的PPN。R/W:表示读写权限位
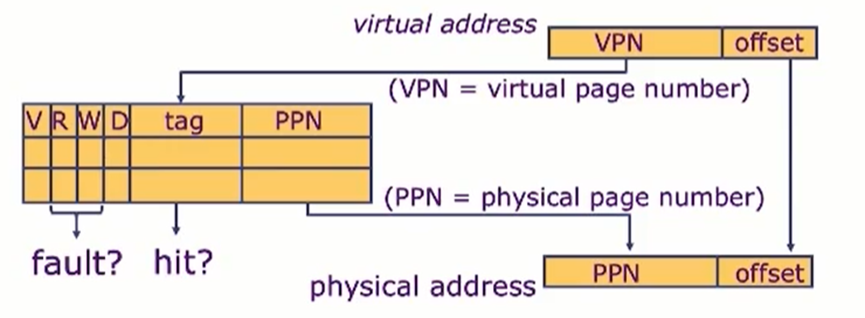
注意1:
当进程切换时,不仅需要切换页表,还需要刷新TLB。所谓刷新就是讲V位置0,表示翻译无效。注意2:TLB和cache的访问顺序
有三种访问顺序:物理高速缓存,虚拟高速缓存,并行
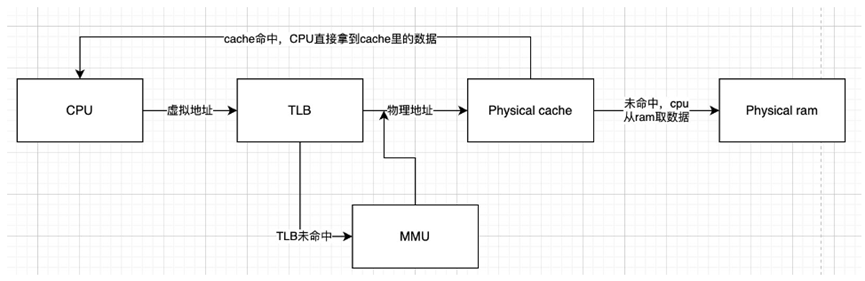
物理高速缓存不会导致重名问题,但是加大了芯片设计复杂度
虚拟高速缓存会导致重名和同名问题。重名就是映射冲突问题。同名问题是一个虚拟地址可能由于进程切换等原因映射到不同物理地址(页表也切换了,可能虚拟地址是一样的,只有转换成物理地址后才知道真正要访问的数据,)而引发的问题。
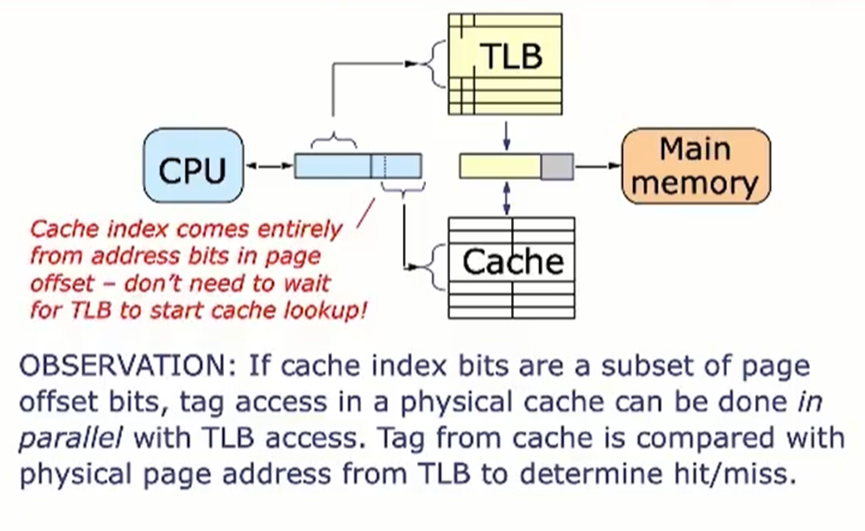
如果cache的index完全包含于虚拟地址的page offset,则两者可以并行访问,讲来自cache的Tag与来自TLB的物理页地址比较,相同则命中,不同则miss,访问主存。VMSA
I. VMSAv8-64转换表描述符格式
有三种页表描述符
描述符类型 bit[1] bit[0] 说明 Invalid - 0 无效描述符,任何访问该地址的尝试都会生成转换错误 Block 0 1 提供内存块的基地址和该内存区域的属性 Table 1 1 提供下一级转换表的地址,对于阶段1的转换,提供该转换的一些属性 
A. 如何确定page table level?

从这个宏定义可以看出,两个输入参数就可以确定page table level。其中一个参数就是PAGE_SHIFT(索引一个page所需的位数,也就是offset),另外一个va_bits,也就是虚拟地址的bit数目。用最经典的4K page为例来描述。一旦确定了4K的page size,那么页偏移所占用的bit数就确定了,即[11:0]这12个地位bit用来确定页内偏移。此时即可确定使用几级页表。此外,一个Translation table往往占用一个page的size,由于ARM64中,一个page table中的描述符是8个字节,因此4K中有512个描述符,因此各级index(指向PGD/PUD/PMD/PT)占用的bit数都是9个,综上所述,48bit的虚拟地址在4K page的情况下,4级映射的地址分配如下:
中间的bit被平均分成4个9-bit的段,分别用来索引到PGD/PUD/PMD/PT中的具体的描述符。II. 内存属性memory attributes

每个translation table entry都被称为块或页描述符。在大多数情况下,属性来自这个描述符。
一些重要的属性:- UXN and PXN - Execution permissions
- DBM - The dirty bit modifier。表示内存中数据是否被修改,如果修改,则必要时刻需要写回磁盘,否则直接删除即可
- AF - Access flag。
- AP - Access permission
- AttrIndx - Selector for memory type and attributes
- NS:Non-secure bit非安全位。对于从安全状态访问内存,指定输出地址是在安全地址映射中还是在非安全地址映射。对于非安全状态下的内存访问,此位将被忽略。
A. 内存类型memory type
在Armv8-A, and Armv9-A中内存分为普通内存和设备内存两种。

内存类型并没有直接编码进PTE中,转换表条目中的AttrIndex字段用于从MAIR_ ELx(内存属性间接寄存器)中选择条目。MAIR_EL1寄存器


使用PTE中的AttrIndx位选择MAIR寄存器中的某一个Attr域。每个Attr为八位。前四位和后四位合起来表示完整的内存类型。
对于device type,其总是non cacheable的,而且是outer shareable,因此它的attribute不多,主要有下面几种附加的特性:
(1)Gathering 或者non Gathering (G or nG)。这个特性表示对多个memory的访问是否可以合并,如果是nG,表示处理器必须严格按照代码中内存访问来进行,不能把两次访问合并成一次。例如:代码中有2次对同样的一个地址的读访问,那么处理器必须严格进行两次read transaction。
(2)Re-ordering (R or nR)。这个特性用来表示是否允许处理器对内存访问指令进行重排。nR表示必须严格执行program order。
(3)Early Write Acknowledgement (E or nE)。PE访问memory是有问有答的(更专业的术语叫做transaction),对于write而言,PE需要write ack操作以便确定完成一个write transaction。为了加快写的速度,系统的中间环节可能会设定一些write buffer。nE表示写操作的ack必须来自最终的目的地而不是中间的write buffer。对于normal memory,可以是non-cacheable的,也可以是cacheable的,这样就需要进一步了解Cacheable和shareable atrribute,具体如下:
(1)是否cacheable
(2)write through or write back
(3)Read allocate or write allocate
(4)transient or non-transient cache
最后一点要说明的是由于cache hierararchy的存在,memory的属性可以针对inner和outer cache分别设定,具体如何区分inner和outer cache是和具体实现相关,但通俗的讲,build in在processor内的cache是inner的,而outer cache是processor通过bus访问的。
对于ARM64处理器,linux kernel定义了下面的index:

对于初始化阶段的页表都是被设定成NORMAL。AP(access permissions)
直接权限

访问权限可以使用直接权限方案或间接权限方案进行编码。
这里暂时只讨论直接权限
如果访问破坏了指定的权限,例如对只读区域的写入,则会生成异常。间接权限
描述符中的Permission Indirection Index (PIIndex)可用, PIIndex字段索引到适当异常级别的权限间接寄存器(PIR)中,从而设置权限
对非特权数据的特权访问
正常情况下,高特权级别是有权利访问低特权级别的,但有些时候这种形式可能被恶意利用。所以ARM使用PSTATE.PAN (Privileged Access Never)位来控制特权访问。

但有时确实需要访问,所以ARM又提供了LDTR指令
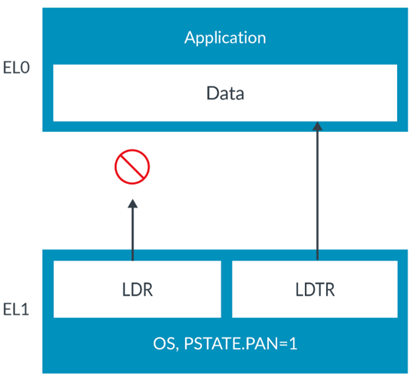
Access Flag访问标志
可以使用访问标志(AF)位来跟踪翻译表条目所覆盖的区域是否已被访问。
- AF=0. Region not accessed.
- AF=1. Region accessed.
-
相关阅读:
数字图像处理 03
SpringBoot之使用Redis和注解实现接口幂等性
消息队列这么多,用哪个哟?
three.js创建基础模型
卖家如何搭上独立站这趟快车
Android入门第39天-系统设置Configuration类
【多态】【虚表指针与虚表】【多继承中的多态】
《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(15)-Fiddler弱网测试,知否知否,应是必知必会
基于微信小程序的新冠疫苗预约系统 uinapp
【Python】第九课 类和对象
- 原文地址:https://blog.csdn.net/qq_52353238/article/details/131752625