经过加载完所有配置之后,继续梳理执行 sql 的过程 public class MybatisTest {
@Test
public void test1 ( ) throws IOException {
. . .
User user = sqlSession. selectOne ( "user.findUserById" , 1 ) ;
. . .
}
}
当调用 selectOne() 时,底层将会调用的是 selectOne(java.lang.String, java.lang.Object) public class DefaultSqlSession implements SqlSession {
. . .
@Override
public < T > T selectOne ( String statement, Object parameter) {
List < T > = this . selectList ( statement, parameter) ;
. . .
}
}
继续调用时,会先装入默认的分页器 RowBounds ,然后继续调用重载的 selectList(java.lang.String, java.lang.Object, org.apache.ibatis.session.RowBounds) public class DefaultSqlSession implements SqlSession {
. . .
@Override
public < E > List < E > selectList ( String statement, Object parameter) {
return this . selectList ( statement, parameter, RowBounds . DEFAULT) ;
}
}
继续调用,也会装入空的 ResultHandler ,继续调用重载的 selectList(java.lang.String, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler) public class DefaultSqlSession implements SqlSession {
. . .
@Override
public < E > List < E > selectList ( String statement, Object parameter, RowBounds rowBounds) {
return selectList ( statement, parameter, rowBounds, Executor . NO_RESULT_HANDLER) ;
}
}
通过传入 statementId 即 “user.findUserById”,然后 configuration 对象拿到 MappedStatement 对象,然后利用执行器来执行查询 public class DefaultSqlSession implements SqlSession {
. . .
private final Configuration configuration;
private final Executor executor;
. . .
private < E > List < E > selectList ( String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
. . .
MappedStatement ms = configuration. getMappedStatement ( statement) ;
return executor. query ( ms, wrapCollection ( parameter) , rowBounds, handler) ;
}
}
在执行器执行的查询时,是调用经过封装后的 CachingExecutor 的 query() 方法。该方法会从 MappedStatement 对象中拿到对应的 BoundSql 对象 public class CachingExecutor implements Executor {
. . .
@Override
public < E > List < E > query ( MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms. getBoundSql ( parameterObject) ;
. . .
}
}
其中,MappedStatement 对象会将参数 parameterObject 传入,然后委托 SqlSource 来获取 BoundSql ,从上面的流程下来是不涉及动态 sql,所以这个 SqlSource 为 StaticSqlSource public final class MappedStatement {
. . .
private SqlSource sqlSource;
. . .
public BoundSql getBoundSql ( Object parameterObject) {
BoundSql boundSql = sqlSource. getBoundSql ( parameterObject) ;
. . .
}
}
StaticSqlSource 会把 configuration 、sql 、parameterMappings 、parameterObject 对象封装到 BoundSql 内并且返回public class StaticSqlSource implements SqlSource {
private final String sql;
private final List < ParameterMapping > ;
private final Configuration configuration;
@Override
public BoundSql getBoundSql ( Object parameterObject) {
return new BoundSql ( configuration, sql, parameterMappings, parameterObject) ;
}
}
拿到 BoundSql 后,先检查参数是不是一个对象映射,需要获取参数对应的映射位,但是现在的映射文件的 sql 输入只是个整形,所以这里执行是空,最后 MappedStatement 对象直接返回 BoundSql 对象,然后 CachingExecutor 就拿到对应的 BoundSql public final class MappedStatement {
. . .
private SqlSource sqlSource;
. . .
public BoundSql getBoundSql ( Object parameterObject) {
BoundSql boundSql = sqlSource. getBoundSql ( parameterObject) ;
List < ParameterMapping > = boundSql. getParameterMappings ( ) ;
if ( parameterMappings == null || parameterMappings. isEmpty ( ) ) {
boundSql = new BoundSql ( configuration, boundSql. getSql ( ) , parameterMap. getParameterMappings ( ) , parameterObject) ;
}
for ( ParameterMapping pm : boundSql. getParameterMappings ( ) ) {
String rmId = pm. getResultMapId ( ) ;
. . .
}
return boundSql;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 总结 问题 CacheKey 是由几部分构成的,怎么生成的?怎么完成的 CacheKey 比较,怎么保证 CacheKey 的唯一性? 对于 SqlSession 而言,它会把实际执行交给 Executor ,而我们知道在 MyBatis 中会话级别是有缓存的,那么这个缓存 Key 是怎么构造,就是在 CachingExecutor 当中,根据 MappedStatement 、parameterObject 实际参数、rowBounds 分页对象以及 BoundSql 来构造的 public class CachingExecutor implements Executor {
. . .
@Override
public < E > List < E > query ( MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms. getBoundSql ( parameterObject) ;
CacheKey key = createCacheKey ( ms, parameterObject, rowBounds, boundSql) ;
. . .
}
}
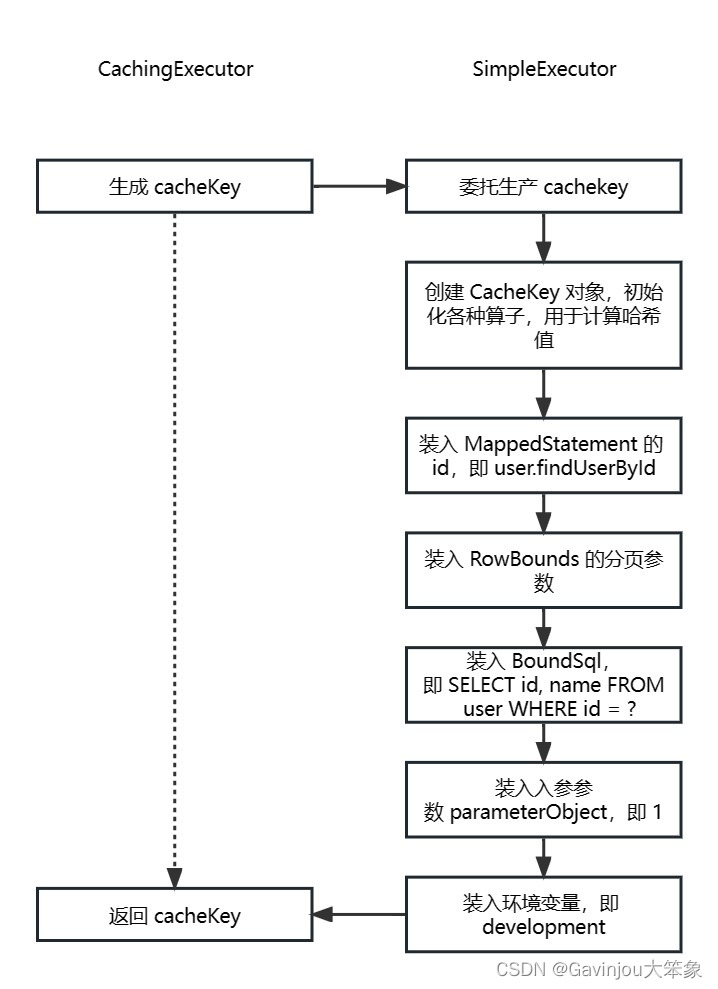
在 CachingExecutor 中,它会委派 SimpleExecutor 来创建缓存建 public class CachingExecutor implements Executor {
private final Executor delegate;
. . .
@Override
public CacheKey createCacheKey ( MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
return delegate. createCacheKey ( ms, parameterObject, rowBounds, boundSql) ;
}
}
SimpleExecutor 首先会创建一个 CacheKey 对象,这个对象会初始化各种算子参数,用于后面的缓存计算,缓存 Key 的组成部分如下public class CacheKey implements Cloneable , Serializable {
private static final int DEFAULT_MULTIPLIER = 37 ;
private static final int DEFAULT_HASHCODE = 17 ;
. . .
private final int multiplier;
private int hashcode;
private long checksum;
private int count;
private List < Object > ;
public CacheKey ( ) {
this . hashcode = DEFAULT_HASHCODE;
this . multiplier = DEFAULT_MULTIPLIER;
this . count = 0 ;
this . updateList = new ArrayList < > ( ) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 回到 SimpleExecutor ,它其实调用的是父类 BaseExecutor 的 createCacheKey() 方法,会根据 MappedStatement 、parameterObject 实际参数、rowBounds 分页对象以及 BoundSql 来计算 CacheKey 内的哈希值 public abstract class BaseExecutor implements Executor {
. . .
@Override
public CacheKey createCacheKey ( MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if ( closed) {
throw new ExecutorException ( "Executor was closed." ) ;
}
CacheKey cacheKey = new CacheKey ( ) ;
cacheKey. update ( ms. getId ( ) ) ;
cacheKey. update ( rowBounds. getOffset ( ) ) ;
cacheKey. update ( rowBounds. getLimit ( ) ) ;
cacheKey. update ( boundSql. getSql ( ) ) ;
List < ParameterMapping > = boundSql. getParameterMappings ( ) ;
TypeHandlerRegistry typeHandlerRegistry = ms. getConfiguration ( ) . getTypeHandlerRegistry ( ) ;
for ( ParameterMapping parameterMapping : parameterMappings) {
if ( parameterMapping. getMode ( ) != ParameterMode . OUT) {
Object value;
String propertyName = parameterMapping. getProperty ( ) ;
if ( boundSql. hasAdditionalParameter ( propertyName) ) {
value = boundSql. getAdditionalParameter ( propertyName) ;
} else if ( parameterObject == null ) {
value = null ;
} else if ( typeHandlerRegistry. hasTypeHandler ( parameterObject. getClass ( ) ) ) {
value = parameterObject;
} else {
MetaObject metaObject = configuration. newMetaObject ( parameterObject) ;
value = metaObject. getValue ( propertyName) ;
}
cacheKey. update ( value) ;
}
}
if ( configuration. getEnvironment ( ) != null ) {
cacheKey. update ( configuration. getEnvironment ( ) . getId ( ) ) ;
}
return cacheKey;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 其中 CacheKey 的 update() 方法会把输入的各种参数计算一次哈希,然后把值也存到里面去 public class CacheKey implements Cloneable , Serializable {
. . .
public void update ( Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil . hashCode ( object) ;
count++ ;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList. add ( object) ;
}
}
生成的哈希值如下 总结 最后生成的 Key 找缓存值流程如下 生成 CacheKey 流程 问题 如果开启了一二级缓存,究竟是调用一级缓存优先还是二级缓存? 首先配置文件中,开启二级缓存 < mappernamespace = " user" > < cache> cache > mapper >
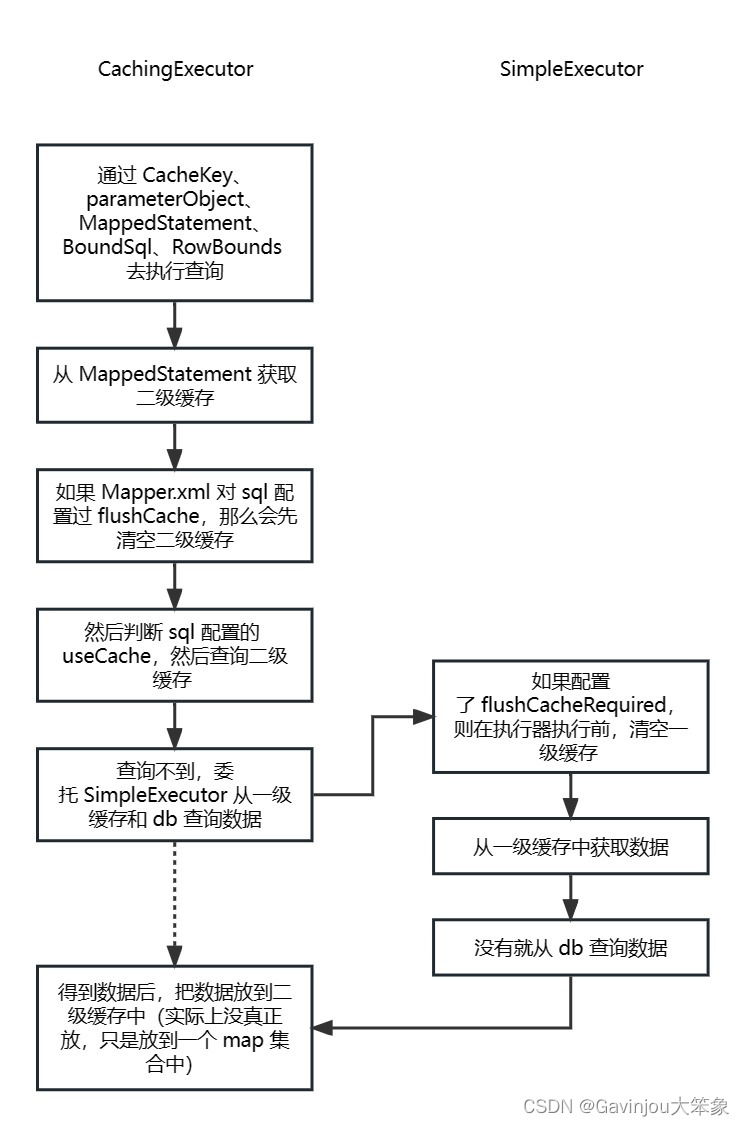
拿到 CacheKey 、parameterObject 、MappedStatement 、BoundSql 、RowBounds 时候,开始执行真正的查询 public class CachingExecutor implements Executor {
. . .
@Override
public < E > List < E > query ( MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
. . .
return query ( ms, parameterObject, rowBounds, resultHandler, key, boundSql) ;
}
}
query() 方法首先会从 MappedStatement 拿到二级缓存,然后检查对应的 sql 是否配置了 flushCache=true,是的话,先把二级缓存清空了 然后判断对应语句是否使用缓存 useCache,默认是开启的 然后根据 StatementType 确定是否处理出参参数,这里是 PREPARED 类型,不是存储过程(CALLABLE 类型),所以不处理 再从二级缓存中查询数据,没有委托给 SimpleExecutor 查询一级缓存和数据库,最后把查出来的数据放回到二级缓存(暂时是存到 map 集合,实际还没存到二级缓存) public class CachingExecutor implements Executor {
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager ( ) ;
. . .
@Override
public < E > List < E > query ( MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms. getCache ( ) ;
if ( cache != null ) {
flushCacheIfRequired ( ms) ;
if ( ms. isUseCache ( ) && resultHandler == null ) {
ensureNoOutParams ( ms, boundSql) ;
List < E > = ( List < E > ) tcm. getObject ( cache, key) ;
if ( list == null ) {
list = delegate. query ( ms, parameterObject, rowBounds, resultHandler, key, boundSql) ;
tcm. putObject ( cache, key, list) ;
}
return list;
}
}
return delegate. query ( ms, parameterObject, rowBounds, resultHandler, key, boundSql) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 委托给 SimpleExecutor 父类的 query() 方法 首先判断 sql 是否配置了 flushCacheRequired,是的话会在执行器执行之前,清空本地以及缓存 然后从一级缓存中获取数据 如果有缓存结果,再判断是否是存储过程类型(CALLABLE 类型),是的话处理输出参数,否则的话直接从数据库里面查询结果 public abstract class BaseExecutor implements Executor {
protected PerpetualCache localCache;
. . .
@Override
public < E > List < E > query ( MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext . instance ( ) . resource ( ms. getResource ( ) ) . activity ( "executing a query" ) . object ( ms. getId ( ) ) ;
if ( closed) {
throw new ExecutorException ( "Executor was closed." ) ;
}
if ( queryStack == 0 && ms. isFlushCacheRequired ( ) ) {
clearLocalCache ( ) ;
}
List < E > ;
try {
queryStack++ ;
list = resultHandler == null ? ( List < E > ) localCache. getObject ( key) : null ;
if ( list != null ) {
handleLocallyCachedOutputParameters ( ms, key, parameter, boundSql) ;
} else {
list = queryFromDatabase ( ms, parameter, rowBounds, resultHandler, key, boundSql) ;
}
} finally {
queryStack-- ;
}
. . .
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 总结 SimpleExecutor 从缓存中拿不到到数据,就需要从 db 中获取public abstract class BaseExecutor implements Executor {
. . .
public < E > List < E > query ( MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
. . .
try {
. . .
} else {
list = queryFromDatabase ( ms, parameter, rowBounds, resultHandler, key, boundSql) ;
}
}
}
然后执行 SimpleExecutor 的 doQuery() ,这是由 SimpleExecutor 实现的。其中查询前会在本地缓存中,添加占位符,拿到数据后再移除 public abstract class BaseExecutor implements Executor {
. . .
private < E > List < E > queryFromDatabase ( MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List < E > ;
localCache. putObject ( key, EXECUTION_PLACEHOLDER) ;
try {
list = doQuery ( ms, parameter, rowBounds, resultHandler, boundSql) ;
} finally {
localCache. removeObject ( key) ;
}
localCache. putObject ( key, list) ;
if ( ms. getStatementType ( ) == StatementType . CALLABLE) {
localOutputParameterCache. putObject ( key, parameter) ;
}
return list;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 SimpleExecutor 先从 MappedStatement 拿到 Configuration 对象,然后通过 Configuration 对象创建 StatementHandler 语句处理器public class SimpleExecutor extends BaseExecutor {
protected Executor wrapper;
. . .
@Override
public < E > List < E > doQuery ( MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null ;
try {
Configuration configuration = ms. getConfiguration ( ) ;
StatementHandler handler = configuration. newStatementHandler ( wrapper, ms, parameter, rowBounds, resultHandler, boundSql) ;
. . .
} finally {
closeStatement ( stmt) ;
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 StatementHandler 创建很关键,它会先通过 RoutingStatementHandler 以及插件拦截装饰后返回 StatementHandler 对象【重点】: 这里的插件机制是 MyBatis 扩展的关键地方之一public class Configuration {
. . .
protected final InterceptorChain interceptorChain = new InterceptorChain ( ) ;
. . .
public StatementHandler newStatementHandler ( Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler ( executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql) ;
statementHandler = ( StatementHandler ) interceptorChain. pluginAll ( statementHandler) ;
return statementHandler;
}
}
其中 StatementHandler 组织如下BaseStatementHandler : 基础语句处理器(抽象类),它基本把语句处理器接口的核心部分都实现了,包括配置绑定、执行器绑定、映射器绑定、参数处理器构建、结果集处理器构建、语句超时设置、语句关闭等,并另外定义了新的方法 instantiateStatement() 供不同子类实现以便获取不同类型的语句连接,子类可以普通执行 SQL 语句,也可以做预编译执行,还可以执行存储过程等SimpleStatementHandler :普通语句处理器,继承 BaseStatementHandler 抽象类,对应 java.sql.Statement 对象的处理,处理普通的不带动态参数运行的 SQL,即执行简单拼接的字符串语句,同时由于 Statement 的特性,SimpleStatementHandler 每次执行都需要编译 SQL (注意:我们知道 SQL 的执行是需要编译和解析的)PreparedStatementHandler :预编译语句处理器,继承 BaseStatementHandler 抽象类,对应 java.sql.PrepareStatement 对象的处理,相比上面的普通语句处理器,它支持可变参数 SQL 执行,由于 PrepareStatement 的特性,它会进行预编译,在缓存中一旦发现有预编译的命令,会直接解析执行,所以减少了再次编译环节,能够有效提高系统性能,并预防 SQL 注入攻击(所以是系统默认也是我们推荐的语句处理器)CallableStatementHandler :存储过程处理器,继承 BaseStatementHandler 抽象类,对应 java.sql.CallableStatement 对象的处理,很明了,它是用来调用存储过程的,增加了存储过程的函数调用以及输出/输入参数的处理支持RoutingStatementHandler :路由语句处理器,直接实现了 StatementHandler 接口,作用如其名称,确确实实只是起到了路由功能,并把上面介绍到的三个语句处理器实例作为自身的委托对象而已,所以执行器在构建语句处理器时,都是直接 new 了 RoutingStatementHandler 实例 RoutingStatementHandler 会根据 sql 的 statementType 选择对应处理的 handlerpublic class RoutingStatementHandler implements StatementHandler {
private final StatementHandler delegate;
public RoutingStatementHandler ( Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch ( ms. getStatementType ( ) ) {
case STATEMENT:
delegate = new SimpleStatementHandler ( executor, ms, parameter, rowBounds, resultHandler, boundSql) ;
break ;
case PREPARED:
delegate = new PreparedStatementHandler ( executor, ms, parameter, rowBounds, resultHandler, boundSql) ;
break ;
case CALLABLE:
delegate = new CallableStatementHandler ( executor, ms, parameter, rowBounds, resultHandler, boundSql) ;
break ;
default :
throw new ExecutorException ( "Unknown statement type: " + ms. getStatementType ( ) ) ;
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 获取到 StatementHandler 之后,就需要执行第 3 步创建 Statement 对象 public class SimpleExecutor extends BaseExecutor {
. . .
@Override
public < E > List < E > doQuery ( MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null ;
try {
Configuration configuration = ms. getConfiguration ( ) ;
StatementHandler handler = configuration. newStatementHandler ( wrapper, ms, parameter, rowBounds, resultHandler, boundSql) ;
stmt = prepareStatement ( handler, ms. getStatementLog ( ) ) ;
. . .
} finally {
closeStatement ( stmt) ;
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 SimpleExecutor 获取 Statement 对象前,会通过 JDBCTransaction 先获取 Connection 对象,即通过 DataSource 返回 Connection 对象。如果开启了日志调试模式,返回的 Connection 对象是经过代理的。然后 RoutingStatementHandler 做预处理得到预编译的 Statement 对象,并参数化后返回 Statement 对象public class SimpleExecutor extends BaseExecutor {
protected Transaction transaction;
. . .
protected Connection getConnection ( Log statementLog) throws SQLException {
Connection connection = transaction. getConnection ( ) ;
if ( statementLog. isDebugEnabled ( ) ) {
return ConnectionLogger . newInstance ( connection, statementLog, queryStack) ;
} else {
return connection;
}
}
. . .
private Statement prepareStatement ( StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection ( statementLog) ;
stmt = handler. prepare ( connection, transaction. getTimeout ( ) ) ;
handler. parameterize ( stmt) ;
return stmt;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 RoutingStatementHandler 再次委派 PreparedStatmentHandler 来处理public class RoutingStatementHandler implements StatementHandler {
private final StatementHandler delegate;
. . .
@Override
public Statement prepare ( Connection connection, Integer transactionTimeout) throws SQLException {
return delegate. prepare ( connection, transactionTimeout) ;
}
}
PreparedStatmentHandler 会通过拿到 BoundSql 中的 sql 之后,通过 Connection 对 sql 进行预编译,得到 PrepareStatement 并返回public class PreparedStatementHandler extends BaseStatementHandler {
. . .
protected BoundSql boundSql;
@Override
public Statement prepare ( Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext . instance ( ) . sql ( boundSql. getSql ( ) ) ;
Statement statement = null ;
try {
statement = instantiateStatement ( connection) ;
. . .
return statement;
} catch ( SQLException e) {
. . .
}
}
. . .
@Override
protected Statement instantiateStatement ( Connection connection) throws SQLException {
String sql = boundSql. getSql ( ) ;
if ( mappedStatement. getKeyGenerator ( ) instanceof Jdbc3KeyGenerator ) {
. . .
} else if ( mappedStatement. getResultSetType ( ) == ResultSetType . DEFAULT) {
return connection. prepareStatement ( sql) ;
} else {
. . .
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 总结 Statement 参数化设置上面已经阐述到 SimpleExecutor 获取预编译 Statement 对象,下面继续看看参数化的过程,下面会继续交由 RoutingStatementHandler 来 Statement 对象参数化处理 public class SimpleExecutor extends BaseExecutor {
. . .
private Statement prepareStatement ( StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
. . .
handler. parameterize ( stmt) ;
return stmt;
}
}
RoutingStatementHandler 委派 PreparedStatementHandler 来执行参数设置,内部调用的是 ParameterHandler 来处理参数化public class PreparedStatementHandler extends BaseStatementHandler {
protected final ParameterHandler parameterHandler;
. . .
@Override
public void parameterize ( Statement statement) throws SQLException {
parameterHandler. setParameters ( ( PreparedStatement ) statement) ;
}
}
ParameterHandler 参数化处理流程首先从 BoundSql 中,拿到参数化映射列表 ParameterMappings ,这个列表是有序的,因为都是从原来的 sql 中按序提取的,然后遍历这个表 拿到这个表之后,取到属性名后,进行一系列校验,包括查看 parameterObject 是不是为空,TypeHandlerRegistry 有没有对应参数的处理方法 从 ParameterMapping 拿到对应 TypeHandler 、JdbcType ,然后通过 TypeHandler 来参数化 最后把参数化后的 Statement 对象返回到 SimpleExecutor public class DefaultParameterHandler implements ParameterHandler {
private final TypeHandlerRegistry typeHandlerRegistry;
private final MappedStatement mappedStatement;
private final Object parameterObject;
private final BoundSql boundSql;
private final Configuration configuration;
. . .
@Override
public void setParameters ( PreparedStatement ps) {
ErrorContext . instance ( ) . activity ( "setting parameters" ) . object ( mappedStatement. getParameterMap ( ) . getId ( ) ) ;
List < ParameterMapping > = boundSql. getParameterMappings ( ) ;
if ( parameterMappings != null ) {
for ( int i = 0 ; i < parameterMappings. size ( ) ; i++ ) {
ParameterMapping parameterMapping = parameterMappings. get ( i) ;
if ( parameterMapping. getMode ( ) != ParameterMode . OUT) {
Object value;
String propertyName = parameterMapping. getProperty ( ) ;
if ( boundSql. hasAdditionalParameter ( propertyName) ) {
. . .
} else if ( typeHandlerRegistry. hasTypeHandler ( parameterObject. getClass ( ) ) ) {
value = parameterObject;
} else {
MetaObject metaObject = configuration. newMetaObject ( parameterObject) ;
value = metaObject. getValue ( propertyName) ;
}
TypeHandler typeHandler = parameterMapping. getTypeHandler ( ) ;
JdbcType jdbcType = parameterMapping. getJdbcType ( ) ;
if ( value == null && jdbcType == null ) {
jdbcType = configuration. getJdbcTypeForNull ( ) ;
}
try {
typeHandler. setParameter ( ps, i + 1 , value, jdbcType) ;
} catch ( TypeException | SQLException e) {
throw new TypeException ( "Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e) ;
}
}
}
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 拿到参数化的 Statement 对象后,通过 RoutingStatementHandler 真正执行查询 public class SimpleExecutor extends BaseExecutor {
. . .
@Override
public < E > List < E > doQuery ( MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null ;
try {
. . .
StatementHandler handler = configuration. newStatementHandler ( wrapper, ms, parameter, rowBounds, resultHandler, boundSql) ;
. . .
return handler. query ( stmt, resultHandler) ;
} finally {
closeStatement ( stmt) ;
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 RoutingStatementHandler 再次委派 PreparedStatementHandler 执行查询。PreparedStatementHandler 拿到 PreparedStatement 后,直接执行查询。然后通过 ResultSetHandler 处理结果集,最后返回查询结果public class PreparedStatementHandler extends BaseStatementHandler {
protected final ResultSetHandler resultSetHandler;
. . .
@Override
public < E > List < E > query ( Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = ( PreparedStatement ) statement;
ps. execute ( ) ;
return resultSetHandler. handleResultSets ( ps) ;
}
}
总结 问题 继续回到 PreparedStatementHandler 查询执行,经过执行查询获得结果集之后,需要 ResultSetHandler 对查询结果进行处理 public abstract class BaseStatementHandler implements StatementHandler {
protected final ResultSetHandler resultSetHandler;
. . .
@Override
public < E > List < E > query ( Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = ( PreparedStatement ) statement;
ps. execute ( ) ;
return resultSetHandler. handleResultSets ( ps) ;
}
}
ResultSetHandler 实际的实现是 DefaultResultSetHandler ,处理的流程如下首先对 Statement 获取第一个结果集,并且把结果集包装成 ResultSetWrapper ,它会把结果集的 columnNames、classNames、jdbcTypes 属性包装到里面 通过 MappedStatement 拿到 Mapper.xml 在 sql 语句中配置的、所有要映射的 ResultMap 然后遍历所有的 ResultMap ,根据 ResultSetWrapper 映射的所有结果集存放到 multipleResults 局部变量集合中 最后返回 multipleResults ,如果只有一个结果集,就从 multipleResults 取出第一个 public class DefaultResultSetHandler implements ResultSetHandler {
private final MappedStatement mappedStatement;
private final Configuration configuration;
. . .
private ResultSetWrapper getFirstResultSet ( Statement stmt) throws SQLException {
ResultSet rs = stmt. getResultSet ( ) ;
while ( rs == null ) {
if ( stmt. getMoreResults ( ) ) {
rs = stmt. getResultSet ( ) ;
} else {
if ( stmt. getUpdateCount ( ) == - 1 ) {
break ;
}
}
}
return rs != null ? new ResultSetWrapper ( rs, configuration) : null ;
}
@Override
public List < Object > handleResultSets ( Statement stmt) throws SQLException {
ErrorContext . instance ( ) . activity ( "handling results" ) . object ( mappedStatement. getId ( ) ) ;
final List < Object > = new ArrayList < > ( ) ;
int resultSetCount = 0 ;
ResultSetWrapper rsw = getFirstResultSet ( stmt) ;
List < ResultMap > = mappedStatement. getResultMaps ( ) ;
int resultMapCount = resultMaps. size ( ) ;
validateResultMapsCount ( rsw, resultMapCount) ;
while ( rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps. get ( resultSetCount) ;
handleResultSet ( rsw, resultMap, multipleResults, null ) ;
rsw = getNextResultSet ( stmt) ;
cleanUpAfterHandlingResultSet ( ) ;
resultSetCount++ ;
}
String [ ] resultSets = mappedStatement. getResultSets ( ) ;
if ( resultSets != null ) {
. . .
}
return collapseSingleResultList ( multipleResults) ;
}
@SuppressWarnings ( "unchecked" )
private List < Object > collapseSingleResultList ( List < Object > ) {
return multipleResults. size ( ) == 1 ? ( List < Object > ) multipleResults. get ( 0 ) : multipleResults;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 继续深挖根据映射规则进行结果集,首先通过 ObjectFactory 初始化 DefaultResultHandler ,然后对结果集进行映射,转换的结果存入 DefaultResultHandler 中,最后把结果放入 multipleResults public class DefaultResultSetHandler implements ResultSetHandler {
private final ResultHandler < ? > ;
private final ObjectFactory objectFactory;
private final RowBounds rowBounds;
. . .
private void handleResultSet ( ResultSetWrapper rsw, ResultMap resultMap, List < Object > , ResultMapping parentMapping) throws SQLException {
try {
if ( parentMapping != null ) {
handleRowValues ( rsw, resultMap, null , RowBounds . DEFAULT, parentMapping) ;
} else {
if ( resultHandler == null ) {
DefaultResultHandler defaultResultHandler = new DefaultResultHandler ( objectFactory) ;
handleRowValues ( rsw, resultMap, defaultResultHandler, rowBounds, null ) ;
multipleResults. add ( defaultResultHandler. getResultList ( ) ) ;
} else {
handleRowValues ( rsw, resultMap, resultHandler, rowBounds, null ) ;
}
}
} finally {
closeResultSet ( rsw. getResultSet ( ) ) ;
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 接下来开始对结果集进行映射,首先判断是否有内置嵌套的结果映射,如果不是,则执行简单结果映射 public class DefaultResultSetHandler implements ResultSetHandler {
. . .
public void handleRowValues ( ResultSetWrapper rsw, ResultMap resultMap, ResultHandler < ? > , RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
if ( resultMap. hasNestedResultMaps ( ) ) {
ensureNoRowBounds ( ) ;
checkResultHandler ( ) ;
handleRowValuesForNestedResultMap ( rsw, resultMap, resultHandler, rowBounds, parentMapping) ;
} else {
handleRowValuesForSimpleResultMap ( rsw, resultMap, resultHandler, rowBounds, parentMapping) ;
}
}
}
执行简单结果映射,先获取结果集信息,然后根据分页信息只提取部分数据,然后遍历 resultSet 的每一行数据转化成 POJO,再保存映射结果 public class DefaultResultSetHandler implements ResultSetHandler {
. . .
private void handleRowValuesForSimpleResultMap ( ResultSetWrapper rsw, ResultMap resultMap, ResultHandler < ? > , RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext < Object > = new DefaultResultContext < > ( ) ;
ResultSet resultSet = rsw. getResultSet ( ) ;
skipRows ( resultSet, rowBounds) ;
while ( shouldProcessMoreRows ( resultContext, rowBounds) && ! resultSet. isClosed ( ) && resultSet. next ( ) ) {
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap ( resultSet, resultMap, null ) ;
Object rowValue = getRowValue ( rsw, discriminatedResultMap, null ) ;
storeObject ( resultHandler, resultContext, rowValue, parentMapping, resultSet) ;
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 执行查询结果封装到 POJO。首先通过 ObjectFactory 创建结果映射的 PO 类对象,然后通过 Configuration 创建 MetaObject 对象,并把 PO 类(即代码里的 rowValue ,其实相当于给 PO 多加了点元信息)存到里面去,然后根据 resultMap 结果映射、ResultSetWrapper 封装好的结果集,把值映射到创建到的 PO 类里面去。这三者的关系可以看作 ResultSetWrapper 是 JDBC 对象值,resultMap 是 JDBC 与 Java PO 属性关系映射表,MetaObject 包含元信息的 PO 类对象 public class DefaultResultSetHandler implements ResultSetHandler {
. . .
private Object getRowValue ( ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap ( ) ;
Object rowValue = createResultObject ( rsw, resultMap, lazyLoader, columnPrefix) ;
if ( rowValue != null && ! hasTypeHandlerForResultObject ( rsw, resultMap. getType ( ) ) ) {
final MetaObject metaObject = configuration. newMetaObject ( rowValue) ;
boolean foundValues = this . useConstructorMappings;
if ( shouldApplyAutomaticMappings ( resultMap, false ) ) {
foundValues = applyAutomaticMappings ( rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
foundValues = applyPropertyMappings ( rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader. size ( ) > 0 || foundValues;
rowValue = foundValues || configuration. isReturnInstanceForEmptyRow ( ) ? rowValue : null ;
}
return rowValue;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 创建对象过程其实就是委派给 ObjectFactory 来创建的,也就是上面第 1 步 public class DefaultResultSetHandler implements ResultSetHandler {
. . .
private final ObjectFactory objectFactory;
. . .
private Object createResultObject ( ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
this . useConstructorMappings = false ;
final List < Class < ? > > = new ArrayList < > ( ) ;
final List < Object > = new ArrayList < > ( ) ;
Object resultObject = createResultObject ( rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix) ;
if ( resultObject != null && ! hasTypeHandlerForResultObject ( rsw, resultMap. getType ( ) ) ) {
final List < ResultMapping > = resultMap. getPropertyResultMappings ( ) ;
for ( ResultMapping propertyMapping : propertyMappings) {
if ( propertyMapping. getNestedQueryId ( ) != null && propertyMapping. isLazy ( ) ) {
resultObject = configuration. getProxyFactory ( ) . createProxy ( resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs) ;
break ;
}
}
}
this . useConstructorMappings = resultObject != null && ! constructorArgTypes. isEmpty ( ) ;
return resultObject;
}
private Object createResultObject ( ResultSetWrapper rsw, ResultMap resultMap, List < Class < ? > > , List < Object > , String columnPrefix)
throws SQLException {
final Class < ? > = resultMap. getType ( ) ;
final MetaClass metaType = MetaClass . forClass ( resultType, reflectorFactory) ;
final List < ResultMapping > = resultMap. getConstructorResultMappings ( ) ;
if ( hasTypeHandlerForResultObject ( rsw, resultType) ) {
. . .
} else if ( resultType. isInterface ( ) || metaType. hasDefaultConstructor ( ) ) {
return objectFactory. create ( resultType) ;
} else if ( shouldApplyAutomaticMappings ( resultMap, false ) ) {
return createByConstructorSignature ( rsw, resultType, constructorArgTypes, constructorArgs) ;
}
. . .
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 由于因为这次测试源码的 case 在 Mapper.xml 中定义的 sql 的返回映射属性是 resultType 所以 shouldApplyAutomaticMappings() 返回 true,所以会通过 applyAutomaticMappings 执行 columnName 和 type 属性名映射赋值,存到 rowValue 中
首先会通过 createAutomaticMappings() 得到属性映射列表 然后遍历这个属性映射列表,通过 TypeHandler 从 ResultSet 拿出属性值 最后通过 MetaObject 将属性值设置到 rowValue public class DefaultResultSetHandler implements ResultSetHandler {
. . .
private boolean applyAutomaticMappings ( ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
List < UnMappedColumnAutoMapping > = createAutomaticMappings ( rsw, resultMap, metaObject, columnPrefix) ;
boolean foundValues = false ;
if ( ! autoMapping. isEmpty ( ) ) {
for ( UnMappedColumnAutoMapping mapping : autoMapping) {
final Object value = mapping. typeHandler. getResult ( rsw. getResultSet ( ) , mapping. column) ;
if ( value != null ) {
foundValues = true ;
}
if ( value != null || ( configuration. isCallSettersOnNulls ( ) && ! mapping. primitive) ) {
metaObject. setValue ( mapping. property, value) ;
}
}
}
return foundValues;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 得到解析后的结果,返回给 DefaultResultSetHandler 之后,就可以把值映射值拿到,得到最终结果 总结 通过 Sqlsession 拿到结果之后,执行完业务流程,就会将 Sqlsession 进行 close() public class MybatisTest {
@Test
public void test1 ( ) throws IOException {
. . .
sqlSession. close ( ) ;
}
}
Sqlsession 关闭,其实就是对 Executor 进行一个关闭清理处理public class DefaultSqlSession implements SqlSession {
private final Executor executor;
. . .
@Override
public void close ( ) {
try {
executor. close ( isCommitOrRollbackRequired ( false ) ) ;
closeCursors ( ) ;
dirty = false ;
} finally {
ErrorContext . instance ( ) . reset ( ) ;
}
}
}
然后 CachingExecutor 会对事务管理器进行最后的数据 commit 或者 rollback,然后关闭会话 public class CachingExecutor implements Executor {
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager ( ) ;
. . .
@Override
public void close ( boolean forceRollback) {
try {
if ( forceRollback) {
tcm. rollback ( ) ;
} else {
tcm. commit ( ) ;
}
} finally {
delegate. close ( forceRollback) ;
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19