-
VSLAM视觉里程计总结
相机模型是理解视觉里程计之前的基础。视觉里程计(VIO)主要分为特征法和直接法。如果说特征点法关注的是像素的位置差,那么,直接法关注的则是像素的颜色差。特征点法通常会把图像抽象成特征点的集合,然后去缩小特征点之间的重投影误差;而直接法则通过warp function直接计算像素点在另一张图像上的颜色差,这样就省去了特征提取的步骤。
特征点:关键点(位姿)+描述子(向量)
直接法:根据像素的亮度信息估计相机运动
1特征点提取与匹配
2定位和建图
知道了特征点以及他们之间的匹配后,就相当于在两张图中知道了同一个点。然后根据这个点来反推两张图之间的旋转和平移。就是根据两组匹配好的点集,计算相机是如何运动的(运动估计),同时根据视觉定位出机器人的位置。
基础知识,下面这篇文章讲得很清楚:
对极几何
本质矩阵E、基本矩阵F和八点法在普通的单目成像中,我们只知道这两组点的像素坐标。而在双目和RGBD相机中,我们还知道该特征点离相机的距离。因此,该问题就出现了多种形式:
- 2D-2D形式(对极几何):通过两个2D图像的像素位置来估计相机的运动。单目相机
- 3D-2D形式(PNP):假设已知其中一组点的3D坐标,以及另一组点的2D坐标,求相机运动。
- 3D-3D形式(ICP):两组点的3D坐标均已知,估计相机的运动。
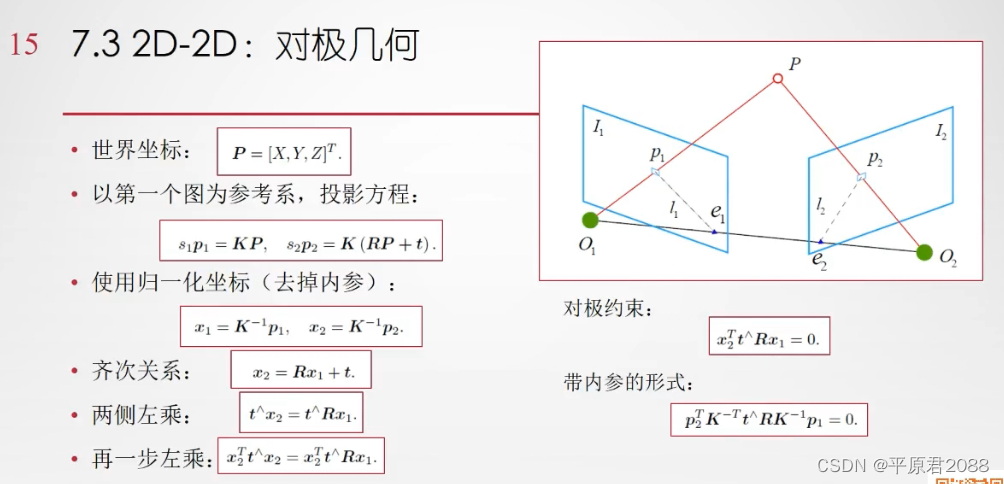
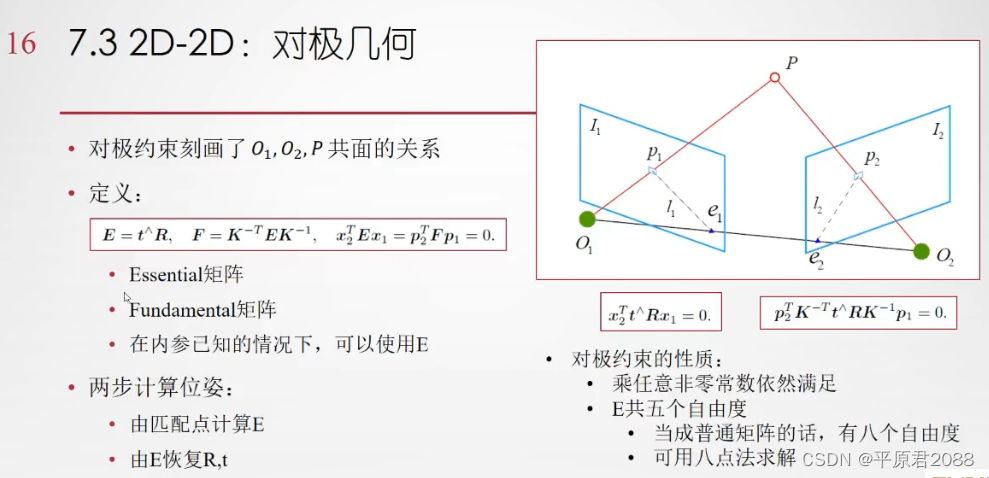

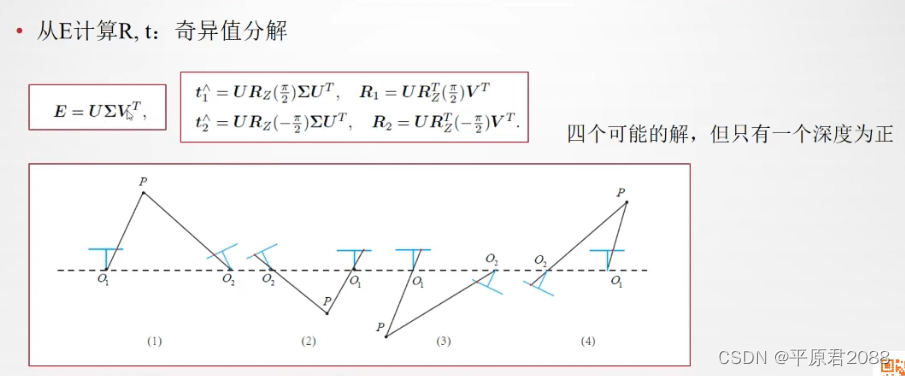

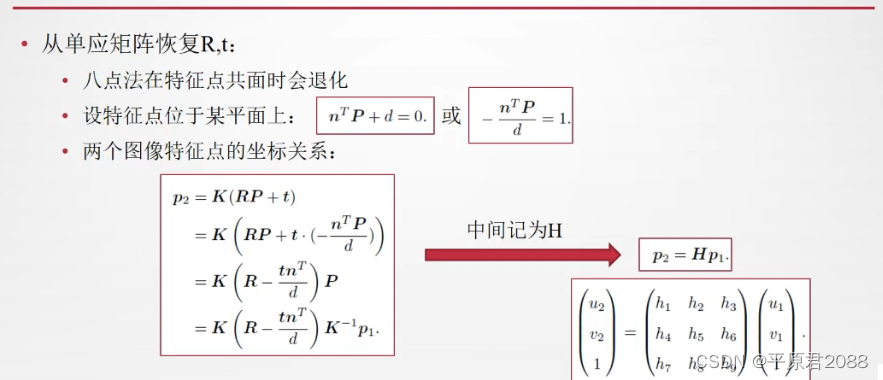
八点法就是在这种前提下产生的,只要获得了8个匹配点,那么就能根据八点法的套路求出基本矩阵 [公式] 。如下所示:
八点法的讨论
- 用于单目SLAM的初始化
- 尺度不确定性:归一化t或特征点的平均深度
- 纯旋转问题:t=0时无法求解
- 多于八对点时:最小二乘或RANSAC
初始化阶段通常用对极几何,所以对极几何主要用于单目SLAM的初始化。等建立图之后,就有了3D的信息了,则可以用3d-2d的PNP方法来解了。
通过opencv可以计算基础矩阵和本质矩阵
PNP
PLP
P3P
那么问题就来了:是否需要为这三种情况设计不同的计算方法呢?答案是:既可以单独做,也可以统一到一个大框架里去做。
单独做的时候,2D-2D使用对极几何的方法,3D-2D使用PnP求解算法,而3D-3D则称为ICP方法(准确地说,ICP不需要各点的配对关系)。
统一的框架,就是指把所有未知变量均作为优化变量,而几何关系则是优化变量之间的约束。由于噪声的存在,几何约束通常无法完美满足。于是,我们把与约束不一致的地方写进误差函数。通过最小化误差函数,来求得各个变量的估计值。这种思路也称为Bundle Adjustment(BA,中文亦称捆集优化或光束法平差)。
代数方法简洁优美,但是它们对于噪声的容忍性较差。存在误匹配,或者像素坐标存在较大误差时,它给出的解会不可靠。而在优化方法中,我们先猜测一个初始值,然后根据梯度方向进行迭代,使误差下降。Bundle Adjustment非常通用,适用于任意可以建模的模型。但是,由于优化问题本身非凸、非线性,使得迭代方法往往只能求出局部最优解,而无法获得全局最优解。也就是说,只有在初始值足够好的情况下,我们才能希望得到一个满意的解。在实际的VO中,我们会结合这两种方法的优点。先使用代数方法估计一个粗略的运动,然后再用Bundle Adjustment进行优化,求得可精确的值。
————————————————
版权声明:本文为CSDN博主「平原君2088」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jiankangyq/article/details/125556643对极几何处理两张2d图片之间的关系,通产用在SLAM初始化阶段。
我们用两个摄像头可以同时观测到一个特征点,利用匹配的特征点,我们将可以建立对极约束,当匹配的特征点足够多时,我们将可以求解本质矩阵,比如使用常用的八点法,当求解完成后,我们就可以从本质矩阵中分解得到两个相机位置相对的位移和旋转。值得注意的是本质矩阵的自由度是5,因为在位移上,我们丢失了一个自由度的尺度信息。
3、视觉里程计存在问题
以下再说说视觉里程计存在的问题和困难。
3.1、单目SLAM存在的问题
单目的优点是成本低,最大的局限性是测不到空间物体的距离,只有一个图像。没有距离信息,我们不知道一个东西的远近——所以也不知道它的大小。它可能是一个近处但很小的东西,也可能是一个远处但很大的东西。只有一张图像时,你没法知道物体的实际大小——我们称之为尺度(Scale)。3.1.1、尺度不确定问题
3.1.2、结构问题
只有在相机运动起来以后,才可能通过三角测量,估计特征点的距离。
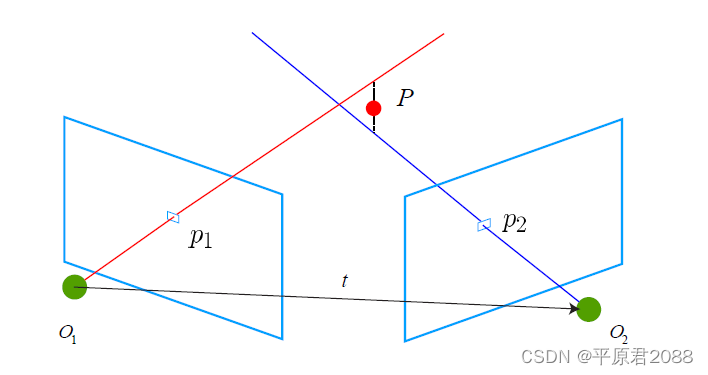
在单目情形下,你必须移动相机之后,才可能去估计空间点的3D位置。换句话说,如果相机摆在那儿不动——就没有三角了。这导致单目在机器人避障中应用存在困难,不过既然在谈AR我们就先不说机器人吧。
3.1.3、尺度漂移
用单目估计出来的位移,与真实世界相差一个比例,叫做尺度。这个比例在初始化时确定,但单纯靠视觉无法确定这个比例到底有多大。进而,由于SLAM过程中噪声的影响,这个比♂例还不是固定不变的。当你用单目SLAM,会发现,咦怎么跑着跑着地图越来越小了……?

这种现象在当前state-of-the-art的单目开源方案出亦会出现,修正方法是通过回环检测。但是有没有出现回环,则要看实际的运动方式。3.2、视觉SLAM的困难
双目相机和RGBD相机能够测量深度数据,于是就不存在初始化和尺度上的问题了。但是,整个视觉SLAM的应用中,存在一些共同的困难,主要包括以下几条:
- 相机运动太快
- 相机视野不够
- 计算量太大
- 遮挡
- 特征缺失
- 动态物体或光源干扰
3.2.1、运动太快
运动太快可能导致相机图像出现运动模糊,成像质量下降。传统卷帘快门式的相机,在运动较快时将产生明显的模糊现象。不过现在我们有全局快门的相机了,即使动起来也不会模糊的相机,只是价格贵一些。
(全局快门相机在拍摄高速运动的物体仍是清晰的,图片来自网络)运动过快的另一个结果就是两个图像的重叠区(Overlap)不够,导致没法匹配上特征。所以视觉SLAM中都会选用广角、鱼眼、全景相机,或者干脆多放几个相机。
3.2.2、相机视野不够
如前所述,视野不够可能导致算法易丢失。毕竟特征匹配的前提是图像间真的存在共有的特征。
3.2.3、计算量太大
基于特征点的SLAM大部分时间会花在特征提取和匹配上,所以把这部分代码写得非常高效是很有帮助的。这里就有很多奇技淫巧可以用了,比如选择一些容易计算的特征/并行化/利用指令集/放到硬件上计算等等,当然最直接的就是减少特征点啦。这部分很需要工程上的测试和经验。总而言之特征点的计算仍然是主要瓶颈所在。要是哪天相机直接输出特征点就更好了。
3.2.4、遮挡
相机可能运动到一个墙角,还存在一些邪恶的开发者刻意地用手去挡住你的相机。他们认为你的视觉SLAM即使不靠图像也能顺利地工作。这些观念是毫无道理的,所以直接无视他们即可。3.2.5、特征缺失、动态光源和人物的干扰
老实说SLAM应用还没有走到这一步,这些多数是研究论文关心的话题(比如直接法)。现在AR能够稳定地在室内运行就已经很了不起了。
3.2.6、可能的解决思路
既然视觉解决不了,那就靠别的来解决吧。毕竟一台设备上又不是只有一块单目相机。更常见的方案是,用视觉+IMU的方式做SLAM。当前广角单目+IMU被认为是一种很好的解决方案。它价格比较低廉,IMU能在以下几点很好地帮助视觉SLAM:IMU能帮单目确定尺度IMU能测量快速的运动IMU在相机被遮挡时亦能提供短时间的位姿估计所以不管在理论还是应用上,都出现了一些单目+IMU的方案[2,3,4]。众所周知的Tango和Hololens亦是IMU+单目/多目的定位方式。
————————————————
版权声明:本文为CSDN博主「平原君2088」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jiankangyq/article/details/125556643 -
相关阅读:
Linux发展史&目录结构&Vim编辑器
【Unity3D赛车游戏制作】开始界面场景搭建
Android自定义控件(六) Andriod仿iOS控件Switch开关
【ENOVIA 服务包】知识重用解决方案 | 达索系统百世慧®
【算法】链表常见算法3
ACL 2022 RE两篇
GIT入门与Gitee的使用
springmvc入门
设计模式|状态机模式(State Machine Pattern)
(已解决) MINet 进行测试时报错如下 raise NotImplementedError
- 原文地址:https://blog.csdn.net/Yangy_Jiaojiao/article/details/127663549