前言
像写代码一样管理基础设施。
Terraform 使用较为高级的配置文件语法来描述基础设施,这个特性让你对配置文件进行版本化管理后,就等于对生产环境的基础设施进行类似于代码一样的版本化管理,而且这些基础设施的配置文件可以复用或者分享。
介绍
Terraform(https://www.terraform.io/)是 HashiCorp 旗下的一款开源(Go 语言开发)的 DevOps 基础架构资源管理运维工具。他的本质是基于版本化的管理能力上,安全、高效地创建和修改用户生产环境的基础设施。
Terraform 有很多非常强大的特性值得我们参考:
- 基础设施即代码:Infrastructure as Code。基础设施可以使用高级配置语法进行描述,使得基础设施能够被代码化和版本化,从而可以进行共享和重复使用。
- 执行计划:Execution Plans。Terraform有一个 "计划 "步骤,在这个步骤中,它会生成一个执行计划。执行计划显示了当你调用apply时,Terraform会做什么,这让你在Terraform操作基础设施时避免任何意外。
- 资源图谱:Resource Graph。Terraform建立了一个所有资源的图,并行创建和修改任何非依赖性资源。从而使得Terraform可以尽可能高效地构建基础设施,操作人员可以深入了解基础设施中的依赖性。
- 自动化变更:Change Automation。复杂的变更集可以应用于您的基础设施,而只需最少的人工干预。有了前面提到的执行计划和资源图,你就可以准确地知道Terraform将改变什么,以及改变的顺序,从而避免了许多可能的人为错误。
Terraform 术语
| 术语 | 基本介绍 |
|---|---|
| Provider | 又称为Plugin,主要用来跟其他的服务进行交互从而实现资源管理,服务安装等 |
| Module | Module是一个将多种资源整合到一起的一个容器,一个module由一些列的.tf或者.tf.json后缀文件组成 |
| Resource | 主要用来定义各种资源或者服务,而这些服务就组成了我们的基础设施架构 |
| Registry | Provider仓库,主要用来存储各种的provider,同时我们也会从Registry下载本地定义的provider到本地 |
Terraform 如何工作
Terraform 采用了插件模式的运行机制。Terraform 使用 RPC(远程接口调用) 跟 Terraform Plugins 进行通信,同时也提供了多种方式来发现和加载 Plugins;而 Terraform Plugins 会和具体的 Provider 进行对接,例如:AWS、Kubernates、Azure 等等,封装各种资源操作的接口供 Terraform Core 使用。
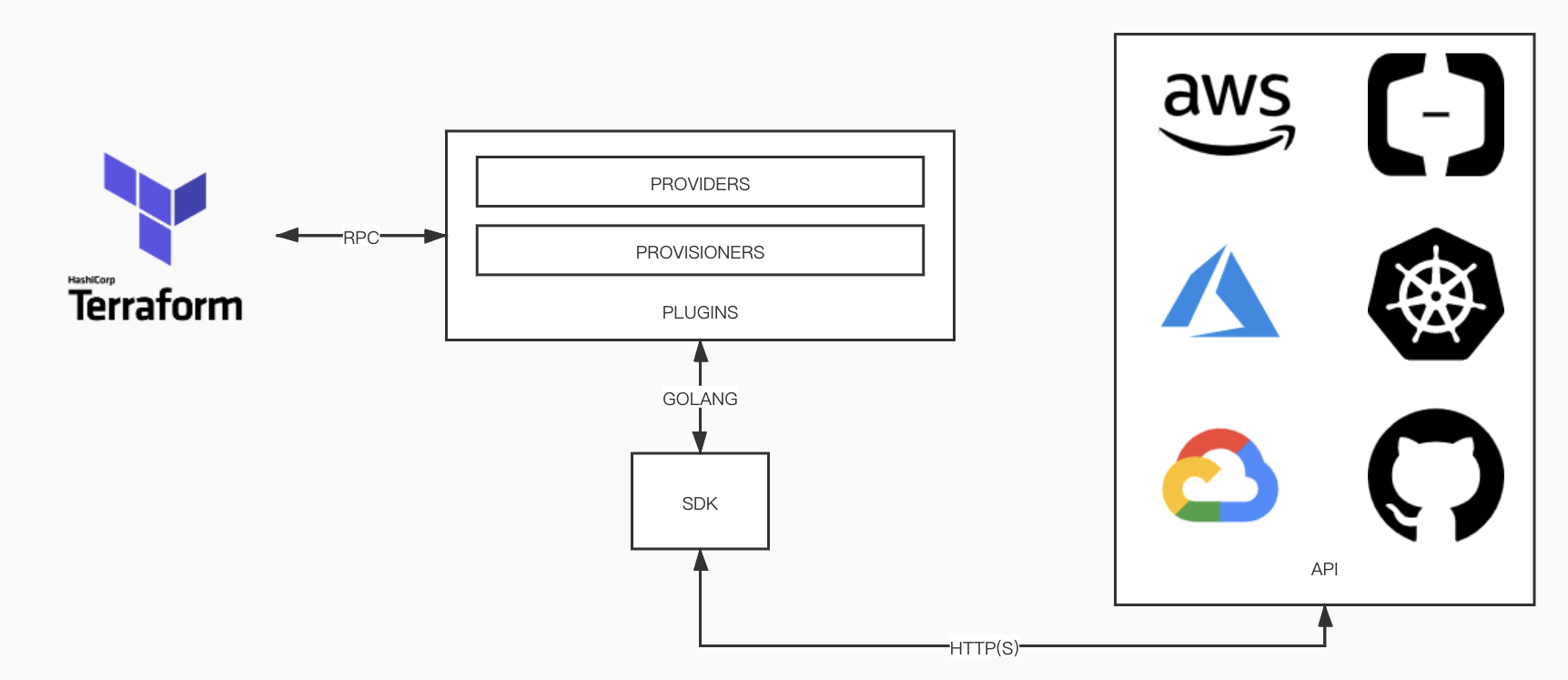
Terraform使用的是HashiCorp自研的go-plugin库(https://github.com/hashicorp/go-plugin),本质上各个Provider插件都是独立的进程,与Terraform进程之间通过rpc进行调用。Terraform引擎首先读取并分析用户编写的Terraform代码,形成一个由data与resource组成的图(Graph),再通过rpc调用这些data与resource所对应的Provider插件;Provider插件的编写者根据Terraform所制定的插件框架来定义各种data和resource,并实现相应的CRUD方法;在实现这些CRUD方法时,可以调用目标平台提供的SDK,或是直接通过调用Http(s) API来操作目标平台。
关于provider
默认情况下Terraform从官方Provider Registry下载安装Provider插件。Provider在Registry中的原始地址采用类似registry.terraform.io/hashicorp/aws 的编码规则。通常为了简便,Terraform允许省略地址中的主机名部分registry.terraform.io,所以我们可以直接使用地址hashicorp/aws。
有时无法直接从官方Registry下载插件,例如我们要在一个与公网隔离的环境中运行Terraform时。为了允许Terraform工作在这样的环境下,有一些可选方法允许我们从其他地方获取Provider插件。
安装
Terraform是以二进制可执行文件发布,只需下载terraform,然后将terraform可执行文件所在目录添加到系统环境变量PATH中即可。
登录Terraform官网,下载对应操作系统的安装包。
解压安装包,并将terraform可执行文件所在目录添加到系统环境变量PATH中。
在命令行中执行如下命令验证配置路径是否正确。
terraform version
开启本地缓存
有的时候下载某些Provider会非常缓慢,或是在开发环境中存在许多的Terraform项目,每个项目都保有自己独立的插件文件夹非常浪费磁盘,这时我们可以使用插件缓存。
Windows下是在相关用户的%APPDATA%目录(如C:\Users\Administrator\AppData\Roaming)下创建名为"terraform.rc"的文件,Macos和Linux用户则是在用户的home下创建名为".terraformrc"的文件。在文件中配置如下:
plugin_cache_dir = "$HOME/.terraform.d/plugin-cache"
当启用插件缓存之后,每当执行terraform init命令时,Terraform引擎会首先检查期望使用的插件在缓存文件夹中是否已经存在,如果存在,那么就会将缓存的插件拷贝到当前工作目录下的.terraform文件夹内。如果插件不存在,那么Terraform仍然会像之前那样下载插件,并首先保存在插件文件夹中,随后再从插件文件夹拷贝到当前工作目录下的.terraform文件夹内。为了尽量避免同一份插件被保存多次,只要操作系统提供支持,Terraform就会使用符号连接而不是实际从插件缓存目录拷贝到工作目录。
需要特别注意的是,Windows 系统下plugin_cache_dir的路径也必须使用/作为分隔符,应使用C:/somefolder/plugin_cahce而不是C:\somefolder\plugin_cache
demo1(docker+nginx)
可以用阿里云等做demo,但云资源一次执行要好几分钟,而且很多操作都是要收费的,学习的时候很不方便,就在本地用docker进行学习吧,第一次下载provider慢一点,后面就是几秒钟就可以测试一个例子了。
所以看下面的demo,需要先下载并安装docker。可以使用菜鸟教程
demo来自官方,但做了适当的简化。
使用docker,并在里面安装一个nginx。
provider 的使用文档,见 https://registry.terraform.io/browse/providers
新建一个文件,文件名随便,就叫main.tf,内容如下
terraform {
required_providers {
// 声明要用的provider
docker = {
source = "kreuzwerker/docker"
// 要用的版本,不写默认拉取最新的
//version = "~> 2.13.0"
}
}
}
// 语法 resource resource_type name
// 声明docker_image的镜像,nginx只是一个名字,只要符合变量命名规则即可
resource "docker_image" "nginx" {
// 使用的是镜像名,https://hub.docker.com/layers/nginx/library/nginx/latest/images/sha256-3536d368b898eef291fb1f6d184a95f8bc1a6f863c48457395aab859fda354d1?context=explore
name = "nginx:latest"
}
resource "docker_container" "nginx" {
image = docker_image.nginx.name
name = "nginx_test"
ports {
internal = 80 // docker 内部的端口
external = 8000 // 对外访问的端口
}
volumes {
container_path = "/usr/share/nginx/html"
host_path = "/Users/jasper/data/nginx_home"
}
}
新建目录/Users/jasper/data/nginx_home,windows去VirtualBox那操作,里面新建一个文件index.html,内容随便来点,就“Hello Terraform”吧。
terraform init
下载需要的provider,第一次可能有点慢
terraform plan
查看执行计划
terraform apply
输入yes即可
最后就可以在浏览器进行访问了
http://127.0.0.1:8000/index.html
demo2(docker+zookeeper+kafka)
kafka的安装是需要依赖zookeeper的,这个例子就展示terraform是如何处理依赖的,并且展示在多资源的情况下,模块编写的推荐方式。
下面显示了一个遵循标准结构的模块的完整示例。这个例子包含了所有可选的元素。
$ tree complete-module/
.
├── README.md
├── main.tf
├── variables.tf
├── outputs.tf
├── ...
├── modules/
│ ├── nestedA/
│ │ ├── README.md
│ │ ├── variables.tf
│ │ ├── main.tf
│ │ ├── outputs.tf
│ ├── nestedB/
│ ├── .../
├── examples/
│ ├── exampleA/
│ │ ├── main.tf
│ ├── exampleB/
│ ├── .../
- README文件用来描述模块的用途。
- examples文件夹用来给出一个调用样例(可选)
- variables.tf文件,包含模块所有的输入变量。输入变量应该有明确的描述说明用途
- outputs.tf文件,包含模块所有的输出值。输出值应该有明确的描述说明用途
- modules子目录,嵌入模块文件夹,出于封装复杂性或是复用代码的目的,我们可以在modules子目录下建立一些嵌入模块。
- main.tf,它是模块主要的入口点。对于一个简单的模块来说,可以把所有资源都定义在里面;如果是一个比较复杂的模块,我们可以把创建的资源分布到不同的代码文件中,但引用嵌入模块的代码还是应保留在main.tf里
代码见:https://gitee.com/zhongxianyao/terraform-demo/tree/master/demo-zk-kafka
main.tf
terraform {
required_providers {
docker = {
source = "kreuzwerker/docker"
}
}
}
module "zookeeper" {
// 一个本地路径必须以./或者../为前缀来标明要使用的本地路径,以区别于使用Terraform Registry路径。
source = "./modules/zk"
}
module "kafka" {
source = "./modules/kafka"
// 由于依赖了zk模块是输出参数,terraform能够分析出来依赖关系,这里无需depends_on参数
# depends_on = [
# module.zookeeper
# ]
zk_port = module.zookeeper.zk_port
}
modules/zk/main.tf
terraform {
required_providers {
docker = {
source = "kreuzwerker/docker"
}
}
}
resource "docker_image" "zookeeper" {
name = "ubuntu/zookeeper:latest"
}
resource "docker_container" "zookeeper" {
image = docker_image.zookeeper.name
name = "zookeeper_test"
ports {
internal = 2181
external = 12181
}
}
modules/zk/outputs.tf
output "zk_port" {
// 在表达式中引用资源属性的语法是..。
value = docker_container.zookeeper.ports[0].external
}
modules/kafka/main.tf
terraform {
required_providers {
docker = {
source = "kreuzwerker/docker"
}
}
}
resource "docker_image" "kafka" {
name = "ubuntu/kafka:latest"
}
resource "docker_container" "kafka" {
image = docker_image.kafka.name
name = "kafka_test"
// zk的端口传递
env = [
"ZOOKEEPER_PORT=${var.zk_port}"
]
ports {
internal = 9092
external = 19092
}
}
modules/kafka/inputs.tf
variable "zk_port" {
default = 2181
description = "zookeeper的端口"
}
最后terraform命令
terraform init
terraform plan
terraform apply