缓存的重要性
简而言之,缓存的原理就是利用空间来换取时间。通过将数据存到访问速度更快的空间里以便下一次访问时直接从空间里获取,从而节省时间。
我们以CPU的缓存体系为例:
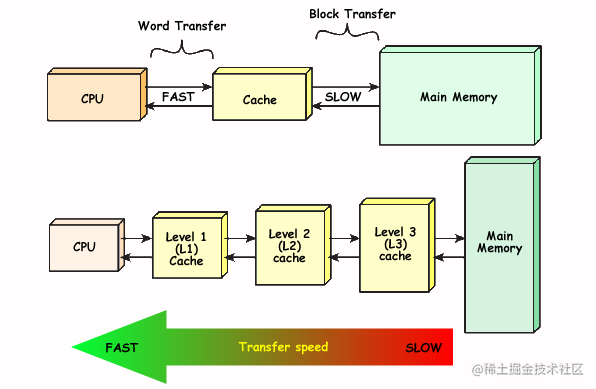
CPU缓存体系是多层级的。分成了CPU -> L1 -> L2 -> L3 -> 主存。我们可以得到以下启示。
- 越频繁使用的数据,使用的缓存速度越快
- 越快的缓存,它的空间越小
而我们项目的缓存设计可以借鉴CPU多级缓存的设计。
关于多级缓存体系实现在开源项目中:https://github.com/valarchie/AgileBoot-Back-End
缓存分层
首先我们可以给缓存进行分层。在Java中主流使用的三类缓存主要有:
- Map(原生缓存)
- Guava/Caffeine(功能更强大的内存缓存)
- Redis/Memcached(缓存中间件)
在一些项目中,会一刀切将所有的缓存都使用Redis或者Memcached中间件进行存取。
使用缓存中间件避免不了网络请求成本和用户态和内核态的切换。 更合理的方式应该是根据数据的特点来决定使用哪个层级的缓存。
Map(一级缓存)
项目中的字典类型的数据比如:性别、类型、状态等一些不变的数据。我们完全可以存在Map当中。
因为Map的实现非常简单,效率上是非常高的。由于我们存的数据都是一些不变的数据,一次性存好并不会再去修改它们。所以不用担心内存溢出的问题。 以下是关于字典数据使用Map缓存的简单代码实现。
/**
* 本地一级缓存 使用Map
*
* @author valarchie
*/
public class MapCache {
private static final Map<String, List<DictionaryData>> DICTIONARY_CACHE = MapUtil.newHashMap(128);
static {
initDictionaryCache();
}
private static void initDictionaryCache() {
loadInCache(BusinessTypeEnum.values());
loadInCache(YesOrNoEnum.values());
loadInCache(StatusEnum.values());
loadInCache(GenderEnum.values());
loadInCache(NoticeStatusEnum.values());
loadInCache(NoticeTypeEnum.values());
loadInCache(OperationStatusEnum.values());
loadInCache(VisibleStatusEnum.values());
}
public static Map<String, List<DictionaryData>> dictionaryCache() {
return DICTIONARY_CACHE;
}
private static void loadInCache(DictionaryEnum[] dictionaryEnums) {
DICTIONARY_CACHE.put(getDictionaryName(dictionaryEnums[0].getClass()), arrayToList(dictionaryEnums));
}
private static String getDictionaryName(Class clazz) {
Objects.requireNonNull(clazz);
Dictionary annotation = clazz.getAnnotation(Dictionary.class);
Objects.requireNonNull(annotation);
return annotation.name();
}
@SuppressWarnings("rawtypes")
private static List<DictionaryData> arrayToList(DictionaryEnum[] dictionaryEnums) {
if(ArrayUtil.isEmpty(dictionaryEnums)) {
return ListUtil.empty();
}
return Arrays.stream(dictionaryEnums).map(DictionaryData::new).collect(Collectors.toList());
}
}
Guava(二级缓存)
项目中的一些自定义数据比如角色,部门。这种类型的数据往往不会非常多。而且请求非常频繁。比如接口中经常要校验角色相关的权限。我们可以使用Guava或者Caffeine这种内存框架作为二级缓存使用。
Guava或者Caffeine的好处可以支持缓存的过期时间以及缓存的淘汰,避免内存溢出。
以下是利用模板设计模式做的GuavaCache模板类。
/**
* 缓存接口实现类 二级缓存
* @author valarchie
*/
@Slf4j
public abstract class AbstractGuavaCacheTemplate {
private final LoadingCache<String, Optional> guavaCache = CacheBuilder.newBuilder()
// 基于容量回收。缓存的最大数量。超过就取MAXIMUM_CAPACITY = 1 << 30。依靠LRU队列recencyQueue来进行容量淘汰
.maximumSize(1024)
// 基于容量回收。但这是统计占用内存大小,maximumWeight与maximumSize不能同时使用。设置最大总权重
// 没写访问下,超过5秒会失效(非自动失效,需有任意put get方法才会扫描过期失效数据。但区别是会开一个异步线程进行刷新,刷新过程中访问返回旧数据)
.refreshAfterWrite(5L, TimeUnit.MINUTES)
// 移除监听事件
.removalListener(removal -> {
// 可做一些删除后动作,比如上报删除数据用于统计
log.info("触发删除动作,删除的key={}, value={}", removal.getKey(), removal.getValue());
})
// 并行等级。决定segment数量的参数,concurrencyLevel与maxWeight共同决定
.concurrencyLevel(16)
// 开启缓存统计。比如命中次数、未命中次数等
.recordStats()
// 所有segment的初始总容量大小
.initialCapacity(128)
// 用于测试,可任意改变当前时间。参考:https://www.geek-share.com/detail/2689756248.html
.ticker(new Ticker() {
@Override
public long read() {
return 0;
}
})
.build(new CacheLoader<String, Optional>() {
@Override
public Optional load(String key) {
T cacheObject = getObjectFromDb(key);
log.debug("find the local guava cache of key: {} is {}", key, cacheObject);
return Optional.ofNullable(cacheObject);
}
});
public T get(String key) {
try {
if (StrUtil.isEmpty(key)) {
return null;
}
Optional optional = guavaCache.get(key);
return optional.orElse(null);
} catch (ExecutionException e) {
log.error("get cache object from guava cache failed.");
e.printStackTrace();
return null;
}
}
public void invalidate(String key) {
if (StrUtil.isEmpty(key)) {
return;
}
guavaCache.invalidate(key);
}
public void invalidateAll() {
guavaCache.invalidateAll();
}
/**
* 从数据库加载数据
* @param id
* @return
*/
public abstract T getObjectFromDb(Object id);
}
我们将getObjectFromDb方法留给子类自己去实现。以下是例子:
/**
* @author valarchie
*/
@Component
@Slf4j
@RequiredArgsConstructor
public class GuavaCacheService {
@NonNull
private ISysDeptService deptService;
public final AbstractGuavaCacheTemplate<SysDeptEntity> deptCache = new AbstractGuavaCacheTemplate<SysDeptEntity>() {
@Override
public SysDeptEntity getObjectFromDb(Object id) {
return deptService.getById(id.toString());
}
};
}
Redis(三级缓存)
项目中会持续增长的数据比如用户、订单等相关数据。这些数据比较多,不适合放在内存级缓存当中,而应放在缓存中间件Redis当中去。Redis是支持持久化的,当我们的服务器重新启动时,依然可以从Redis中加载我们原先存储好的数据。
但是使用Redis缓存还有一个可以优化的点。我们可以自己本地再做一个局部的缓存来缓存Redis中的数据来减少网络IO请求,提高数据访问速度。 比如我们Redis缓存中有一万个用户的数据,但是一分钟之内可能只有不到1000个用户在请求数据。我们便可以在Redis中嵌入一个局部的Guava缓存来提供性能。以下是RedisCacheTemplate.
/**
* 缓存接口实现类 三级缓存
* @author valarchie
*/
@Slf4j
public class RedisCacheTemplate {
private final RedisUtil redisUtil;
private final CacheKeyEnum redisRedisEnum;
private final LoadingCache<String, Optional> guavaCache;
public RedisCacheTemplate(RedisUtil redisUtil, CacheKeyEnum redisRedisEnum) {
this.redisUtil = redisUtil;
this.redisRedisEnum = redisRedisEnum;
this.guavaCache = CacheBuilder.newBuilder()
// 基于容量回收。缓存的最大数量。超过就取MAXIMUM_CAPACITY = 1 << 30。依靠LRU队列recencyQueue来进行容量淘汰
.maximumSize(1024)
.softValues()
// 没写访问下,超过5秒会失效(非自动失效,需有任意put get方法才会扫描过期失效数据。
// 但区别是会开一个异步线程进行刷新,刷新过程中访问返回旧数据)
.expireAfterWrite(redisRedisEnum.expiration(), TimeUnit.MINUTES)
// 并行等级。决定segment数量的参数,concurrencyLevel与maxWeight共同决定
.concurrencyLevel(64)
// 所有segment的初始总容量大小
.initialCapacity(128)
.build(new CacheLoader<String, Optional>() {
@Override
public Optional load(String cachedKey) {
T cacheObject = redisUtil.getCacheObject(cachedKey);
log.debug("find the redis cache of key: {} is {}", cachedKey, cacheObject);
return Optional.ofNullable(cacheObject);
}
});
}
/**
* 从缓存中获取对象 如果获取不到的话 从DB层面获取
* @param id
* @return
*/
public T getObjectById(Object id) {
String cachedKey = generateKey(id);
try {
Optional optional = guavaCache.get(cachedKey);
// log.debug("find the guava cache of key: {}", cachedKey);
if (!optional.isPresent()) {
T objectFromDb = getObjectFromDb(id);
set(id, objectFromDb);
return objectFromDb;
}
return optional.get();
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
/**
* 从缓存中获取 对象, 即使找不到的话 也不从DB中找
* @param id
* @return
*/
public T getObjectOnlyInCacheById(Object id) {
String cachedKey = generateKey(id);
try {
Optional optional = guavaCache.get(cachedKey);
log.debug("find the guava cache of key: {}", cachedKey);
return optional.orElse(null);
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
/**
* 从缓存中获取 对象, 即使找不到的话 也不从DB中找
* @param cachedKey 直接通过redis的key来搜索
* @return
*/
public T getObjectOnlyInCacheByKey(String cachedKey) {
try {
Optional optional = guavaCache.get(cachedKey);
log.debug("find the guava cache of key: {}", cachedKey);
return optional.orElse(null);
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
public void set(Object id, T obj) {
redisUtil.setCacheObject(generateKey(id), obj, redisRedisEnum.expiration(), redisRedisEnum.timeUnit());
guavaCache.refresh(generateKey(id));
}
public void delete(Object id) {
redisUtil.deleteObject(generateKey(id));
guavaCache.refresh(generateKey(id));
}
public void refresh(Object id) {
redisUtil.expire(generateKey(id), redisRedisEnum.expiration(), redisRedisEnum.timeUnit());
guavaCache.refresh(generateKey(id));
}
public String generateKey(Object id) {
return redisRedisEnum.key() + id;
}
public T getObjectFromDb(Object id) {
return null;
}
}
以下是使用方式:
/**
* @author valarchie
*/
@Component
@RequiredArgsConstructor
public class RedisCacheService {
@NonNull
private RedisUtil redisUtil;
public RedisCacheTemplate<SysUserEntity> userCache;
@PostConstruct
public void init() {
userCache = new RedisCacheTemplate<SysUserEntity>(redisUtil, CacheKeyEnum.USER_ENTITY_KEY) {
@Override
public SysUserEntity getObjectFromDb(Object id) {
ISysUserService userService = SpringUtil.getBean(ISysUserService.class);
return userService.getById((Serializable) id);
}
};
}
}
缓存Key以及过期时间
我们可以通过一个枚举类来统一集中管理各个缓存的Key以及过期时间。以下是例子:
/**
* @author valarchie
*/
public enum CacheKeyEnum {
/**
* Redis各类缓存集合
*/
CAPTCHAT("captcha_codes:", 2, TimeUnit.MINUTES),
LOGIN_USER_KEY("login_tokens:", 30, TimeUnit.MINUTES),
RATE_LIMIT_KEY("rate_limit:", 60, TimeUnit.SECONDS),
USER_ENTITY_KEY("user_entity:", 60, TimeUnit.MINUTES),
ROLE_ENTITY_KEY("role_entity:", 60, TimeUnit.MINUTES),
ROLE_MODEL_INFO_KEY("role_model_info:", 60, TimeUnit.MINUTES),
;
CacheKeyEnum(String key, int expiration, TimeUnit timeUnit) {
this.key = key;
this.expiration = expiration;
this.timeUnit = timeUnit;
}
private final String key;
private final int expiration;
private final TimeUnit timeUnit;
public String key() {
return key;
}
public int expiration() {
return expiration;
}
public TimeUnit timeUnit() {
return timeUnit;
}
}
统一的使用门面
一般来说,我们在项目中设计好缓存之后就可以让其他同事写业务时直接调用了。但是让开发者去判断这个属于二级缓存还是三级缓存的话,存在心智负担。我们应该让开发者自然地从业务角度去选择某个缓存。比如他正在写部门相关的业务逻辑,就直接使用deptCache。
此时我们可以新建一个CacheCenter来统一按业务划分缓存。以下是例子:
/**
* 缓存中心 提供全局访问点
* @author valarchie
*/
@Component
public class CacheCenter {
public static AbstractGuavaCacheTemplate<String> configCache;
public static AbstractGuavaCacheTemplate<SysDeptEntity> deptCache;
public static RedisCacheTemplate<String> captchaCache;
public static RedisCacheTemplate<LoginUser> loginUserCache;
public static RedisCacheTemplate<SysUserEntity> userCache;
public static RedisCacheTemplate<SysRoleEntity> roleCache;
public static RedisCacheTemplate<RoleInfo> roleModelInfoCache;
@PostConstruct
public void init() {
GuavaCacheService guavaCache = SpringUtil.getBean(GuavaCacheService.class);
RedisCacheService redisCache = SpringUtil.getBean(RedisCacheService.class);
configCache = guavaCache.configCache;
deptCache = guavaCache.deptCache;
captchaCache = redisCache.captchaCache;
loginUserCache = redisCache.loginUserCache;
userCache = redisCache.userCache;
roleCache = redisCache.roleCache;
roleModelInfoCache = redisCache.roleModelInfoCache;
}
}
以上就是关于项目中多级缓存的实现。 如有不足恳请评论指出。