先说一下,为什么写这篇文章?
最近在写一个Http协议栈当涉及CRLF控制字符写入时,发现自己对CRLF与\r\n的关系不太了解,因此决定详细学习一下;查阅资料的同时,又遇到UTF-8与ASCII编码的疑问。
一、ASCII 编码
ASCII (American Standard Code for Information Interchange 美国信息交换标准代码) 由128个字符构成,是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语,其对应的国际标准为 ISO/IEC 646。
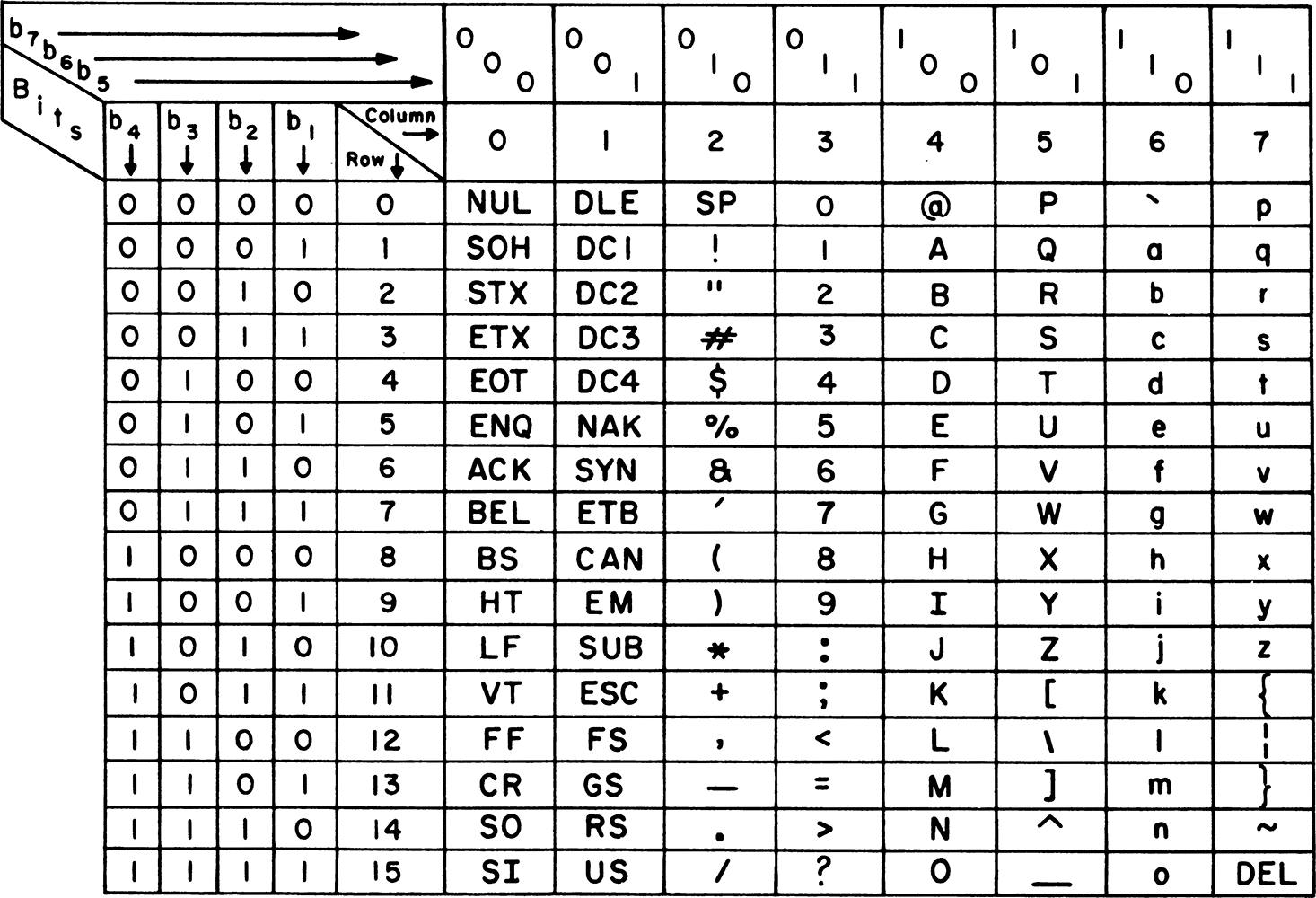
ASCII 由电报码发展而来,第一版标准发布于1963年,最后一次更新则是在1986年,至今为止共128个字符:
- 其中
33个字符为不可显示的控制字符,主要用于控制设备或调整文本格式; - 在33个字符之外是
95个可显示字符:
包含26个英文大小写字母、10个阿拉伯数字以及包含空格在内的33个标点与特殊符号。
1.1 EASCII
EASCII(Extended ASCII)是ASCII码的扩展版本,其将ASCII码由7位扩充为8位,由128个字符扩展为256个字符,因此EASCII可以部分支持西欧语言。
1.2 转义字符
ASCII码表中的转义字符是一种约定写法,是以反斜杠\开头的特殊字符序列,作用是告诉计算机如何显示与输入控制字符。

转义字符的由来可以追溯到电传打字机和电传打字设备的使用。
在这些设备中,许多字符都是由多个部分组成的,需要多次按键才能输入。例如,换行符通常需要按下回车键和换行键,而退格符需要按下后退键。为了简化这个过程,制定了一些简化输入这些字符的规则,这些规则最终成为了ASCII转义字符的标准。
转义字符并非ASCII控制字符的某种编码方式,而是一种约定俗成的写法。当向计算机输入转义字符时(如\r\n),其将自动将转移字符替换为CRLF控制字符。
以下使用Java语言编写了一个测试程序,当计算机遇到\r\n时,计算机自动将其替换为了CRLF控制字符,每个控制字符占一个字节:

二、Unicode 编码
Unicode (The Unicode Standard) 译作万国码、统一字元码、统一字符编码,是信息技术领域的业界标准,其整理、编码了世界上大部分的文字系统,使得电脑能以统一字符集来处理和显示文字,不但减轻在不同编码系统间切换和转换的困扰,更提供了一种跨平台的乱码问题解决方案。
Unicode由非营利机构Unicode联盟(Unicode Consortium)维护,该机构致力让Unicode标准取代既有的字符编码方案,因为既有方案编码空间有限,不适用于多语环境。Unicode伴随着通用字符集ISO/IEC 10646的标准而发展,同时也以书本的形式对外发表。Unicode至今仍在不断增修,每个新版本都加入更多新的字符,目前最新的版本为2022年9月公布的15.0.0,已经收录超过14万个字符。
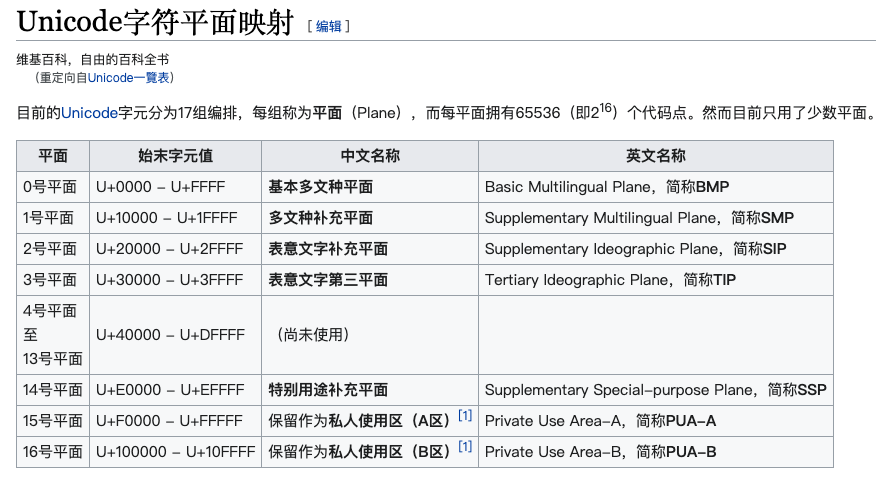
Unicode 编码是一个二进制字符集,其字符占用2~3个字节。目前分为17个组进行编排,每个组称为一个平面,每个平面拥有65536个编码点,且当前只使用了少数平面。
因此,Unicode有足够的编码空间,可以将世界上所有的符号都纳入其中,每一个符号都给予一个独一无二的编码,是名副其实的万国码。
三、UTF-8 编码
UTF-8的英文全称是(8-bit Unicode Transformation Format),其为 Unicode 的实现方式之一,也是目前互联网上使用最广的一种 Unicode 编码的实现方式。
为什么UTF-8成为互联网使用最广泛的一种编码方式?
前边说过Unicode 编码是一个二进制字符集,其只规定了字符的二进制代码,却没有规定这些二进制代码应该如何存储。
比如:
- 大写英文字母A,其对应的ASCII二进制编码为8位 ( 01000001 ),也就是说表示ASCII字符需1个字节 ;
- 汉字
夏的 Unicode 十六进制标识为590F,二进制表示有16位(0101100100001111),也就是说采用Unicode表示这个字符至少需要2个字节; - 而对于Unicode编码第14~16平面的字符,可能需要3个字节表示。
因此,在计算机中如何进行Unicode编码的存储,出现了以下两个问题:
若所有的字符均按3个字节进行表示:由于计算机存储空间有限,将造成不小的空间浪费;若按1~3字节对所有字符进行表示:计算机该如何区分ASCII 与 Unicode(计算机如何知道是一个字节表示一个字符,还是三个字节表示一个字符)?
在这种情况下UTF-8应运而生,UTF-8 最大的特点是一种可变长的编码方式,其使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。
因此,对于英语字母UTF-8 编码和 ASCII 码是相同的。 - 对于
n字节的符号(n > 1):
第一个字节的前n位都设为1,第n + 1位设为0;
后面字节的前两位一律设为10;
剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位:
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------+----------------------------------
0000 0000 ~ 0000 007F | 0xxxxxxx
0000 0080 ~ 0000 07FF | 110xxxxx 10xxxxxx
0000 0800 ~ 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000 ~ 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8编码为什么最多占用4个字节?
前边我们了解到 Unicode 编码的17个平面,最多使用3个字节可全部表示。但为什么 UTF-8 编码最多却是要使用4个字节呢?
这是由 UTF-8 编码的编码规则决定的,对于编码点 U+10000 到 U+10FFFF 范围内的字符,UTF-8 编码使用了 4 个字节来表示。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------+----------------------------------
0001 0000 ~ 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
其中:
- 前面的字节以“11110”开始,用于标识使用了 4 个字节来表示一个字符。
- 后面的 3 个字节的前两个字节以“10”开始,用于标识这是一个多字节字符的后续字节。
使用四个字节的好处还在于,可以为未来的 Unicode 字符预留更多的编码空间。这是因为,Unicode 是一个持续发展的标准,每年都有新的字符被添加到其中。如果所有的字符都只使用三个字节表示,那么当 Unicode 标准新增更多字符时,就会出现编码空间不足的问题。因此,使用四个字节来表示这些字符可以保证未来的字符也能够被正确编码。
参考
wikipedia ASCII:
https://zh.wikipedia.org/zh-hans/ASCII
wikipedia Unicode:
https://zh.wikipedia.org/zh-cn/Unicode
wikipedia Unicode字符平面映射:
https://zh.wikipedia.org/zh-hans/Unicode%E5%AD%97%E7%AC%A6%E5%B9%B3%E9%9D%A2%E6%98%A0%E5%B0%84
wikipedia UTF-8:
https://zh.wikipedia.org/wiki/UTF-8
ISO/IEC 646 ASCII:
http://www.kostis.net/charsets/iso646.irv.htm
ISO/IEC 10646 Unicode:
http://www.kostis.net/charsets/iso10646.htm
ascii-code:
https://www.ascii-code.com/
Unicode 编码表:
http://www.chi2ko.com/tool/CJK.htm
ASCII Unicode 和 UTF-8:
https://blog.csdn.net/qq_38310578/article/details/78433726
= THE END =
文章首发于公众号”CODING技术小馆“,如果文章对您有帮助,欢迎关注我的公众号。
