论文地址:THLNet: 用于单耳语音增强的两级异构轻量级网络
代码:https://github.com/dangf15/THLNet
引用格式:Dang F, Hu Q, Zhang P. THLNet: two-stage heterogeneous lightweight network for monaural speech enhancement[J]. arXiv preprint arXiv:2301.07939, 2023.
博客作者:凌逆战 (引用请注明出处)
摘要
本文提出了一种用于单声道语音增强的两阶段异构轻量级网络。具体地,本文设计了一个两阶段的框架,包括粗粒度的全频带掩码估计阶段和细粒度的低频细化阶段。本文使用一种新的可学习复数矩形带宽(learnable complex-valued rectangular bandwidth,LCRB)滤波器组作为紧凑特征提取器,而不是使用手工设计的实值滤波器。此外,考虑到两阶段任务各自的特点,我们使用了异构结构,即U型子网络作为CoarseNet的主干,单尺度子网络作为FineNet的主干。在VoiceBank + DEMAND和DNS数据集上进行了实验。实验结果表明,所提方法在保持相对较小的模型尺寸和较低的计算复杂度的同时,性能优于当前最先进的方法。
索引项:语音增强,两阶段异构结构,轻量化模型,可学习复数矩形带宽滤波器组
1 引言
语音增强(Speech enhancement, SE)是一种旨在通过去除噪声[1]来提高带噪语音质量和可懂度的语音处理方法。它通常用作自动语音识别、助听器和电信的前端任务。近年来,深度神经网络(deep neural networks, DNNs)在社会工程研究中的应用受到越来越多的关注。
许多基于DNN的方法[2,3,4,5]在SE任务中取得了令人印象深刻的性能,但它们的性能提高伴随着模型开销的增加。因此,最先进的(SOTA)模型通常太大,无法部署在具有实际应用程序的设备上。最近提出了几种方法,通过使用紧凑的特征来解决这个问题。在RNNoise[6]和PercepNet[7]中,分别使用bark滤波器组和三角滤波器组对频谱进行压缩。这些滤波器组保留了对人类感知更重要的频域信息,有效降低了输入特征的维度,从而降低了神经网络模型的复杂性。基于PercepNet的DeepFilterNet[8]算法首先利用ERB尺度增益增强频谱包络,然后利用DeepFilter[9]进一步增强初步增强频谱的周期部分。然而,基于紧凑特征的工作通常使用专家手工设计的滤波器来导出紧凑的实值特征,没有利用相位信息。
多阶段学习(multi-stage learning, MSL)遵循"分而治之"的思想,将一项困难的任务分解为多个简单的子问题,以增量方式获得更好的解,在许多领域表现出比单阶段方法更好的性能,如图像修复[10]和图像去噪[11]。最近,MSL也被应用于语音前端任务,取得了很好的结果[4,12,13]。虽然这些方法也将任务划分为更容易建模的子任务,并取得了良好的性能,但这些模型的每个阶段本质上都是在高维STFT特征上工作的,导致了大量的参数和计算工作量。
在此背景下,本文研究对设计有效的轻量级SE框架有以下贡献:
- 本文提出一种结合两阶段任务和轻量级方法的框架,能够以较低的模型开销实现与SOTA方法相当的性能。具体而言,本文设计了一个两阶段模型,包括粗粒度的全频带掩模估计阶段和细粒度的低频细化阶段。本文使用一种新的可学习复数矩形带宽(LCRB)滤波器组作为紧凑特征提取器,而不是使用手工设计的实值滤波器。
- 采用互补特征处理的思想,并考虑所提出的两阶段任务各自的特点,使用U型子网络作为CoarseNet的主干,使用单尺度子网络作为FineNet的主干。
- 为了验证所提方法的优越性,在两个公开测试集上将所提模型与单阶段backbone模型和其他SOTA系统进行了比较。实验结果表明,该模型在大大减少参数和计算量的情况下取得了与单阶段backbone模型相当的效果,并优于SOTA模型。
2 提出的算法
我们提出的系统示意图如图1所示。它由一个LCRB滤波器组和两个子网络组成。

图1:拟议系统概述
在第一阶段,CoarseNet将LCRB尺度下的紧凑特征作为输入,预测一个LCRB尺度下的复数掩码
在第二阶段,我们使用FineNet进一步细化频谱的低频部分,将原始语音复数谱的低频部分和第一阶段的增强复数频谱的低频部分提供给FineNet。FineNet 输出的是低频部分的补偿复数掩码
2.1 LCRB滤波器组
采用一种新型的LCRB滤波器组提取压缩特征。LCRB滤波器组 是 压缩FFT频谱以获取紧凑高效特征 的 band merging module 和用于将压缩后的特征恢复为FFT频谱 的band splitting module组成。
在频带合并模块(BM,band merging module)中,首先将FFT频谱
其中
频带分隔模块(BS,band splitting module)是 band merging module的逆运算。band splitting module 将粗糙网络解码器预测的
其中
我们利用PyTorch[14]来实现我们的模块。使用复数分组Conv1d来实现LCRB滤波器组。LCRB滤波器组的band merging模块如图2所示。由于LCRB滤波器组的band splitting module和band merging module具有相同的结构,只需要修改group real (imag) Conv1d的输入输出通道数。

图2:LCRB滤波器组带合并模块示意图
2.2 互补特征处理
现有的多阶段语音增强方法通常在每个阶段使用相同的结构,大致可以分为两类:1)U型结构和 2) Single-scale 结构。U型网络[4,15,16]首先逐步将输入映射到低分辨率表示,然后逐步应用逆映射来恢复原始分辨率。尽管这些模型有效地编码了多尺度信息,但由于反复使用下采样操作,它们往往会牺牲空间细节。相比之下,在单尺度特征管道上操作的方法在生成具有精细谐波结构的谱方面是可靠的[5,17]。然而,由于有限的感受野或难以对长序列进行建模,它们的输出在语义上不太鲁棒。这表明了上述架构设计选择的内在局限性,它们只能生成空间准确或上下文可靠的输出,而不能同时生成两者。受上述问题的启发,本文采用互补特征处理的思想,并考虑了所提出的两阶段任务各自的特点,U型子网络用于CoarseNet,单尺度子网络用于FineNet。
图3(a)和(b)分别是我们使用的U型子网络和单尺度子网络。对于U型子网络,我们将由U型编解码器和多个两路LSTM块组成的DPCRN[15]修改为轻量级版本作为backbone网络。对于单尺度子网络,将DPT-FSNet[5](简称DFNet)修改为轻量级版本作为backbone,该网络由一个单尺度扩张卷积编解码器和多个双路径transformer块组成。

图3 (a) U型子网示意图。(b)单尺度子网络
2.3 损失函数
我们联合训练CoarseNet和FineNet,总损失如下:
其中λ为两种损失之间的加权系数,定义CoarseNet和FineNet的损失函数Lc、Lf为:
其中
3 实验
3.1 数据集
使用小规模和大规模数据集来评估所提出的模型。对于小规模数据集,我们使用了在SE研究中广泛使用的VoiceBank+ DEMAND数据集[18]。该数据集包含预混合的带噪语音和配对的纯净语音。纯净语音数据集是从VoiceBank语料库[19]中选择的,其中训练集包含来自28个说话人的11572条话语,测试集包含来自2个说话人的872条话语。对于噪声集,训练集包含40种不同的噪声条件,10种类型的噪声(8种来自需求[20],2种人为生成),信噪比分别为0、5、10和15 dB。测试集包含20种不同的噪声条件,其中5种类型的未见噪声来自DEMAND数据库,信噪比分别为2.5,7.5,12.5,17.5 dB。
对于大规模数据集,我们使用DNS数据集[21]。DNS数据集包含来自2150个说话人的500多个小时的纯净剪辑和来自150个类的180多个小时的噪音剪辑。在训练阶段,通过动态混合来模拟噪声-纯净对。具体来说,在每个训练周期开始之前,将50%的纯净语音与[22]提供的随机选择的房间脉冲响应(RIR)混合。通过将纯净的语音(其中50%是混响)和信噪比在-5到20 dB之间的随机噪声混合,我们生成了语音-噪声混合物。为了进行评估,我们使用了第3次DNS挑战的盲测试集,包括有和没有混响的600段音频录音。
3.2 实验步骤
所有话语都以16khz采样,并分块到4秒以保持训练稳定性。该算法采用32 ms的Hanning窗,相邻帧重叠率为50%,并采用512点FFT(快速傅里叶变换)。我们移除了频谱中的直流分量,得到了256-D(维数)的谱特征用于模型输入。输入CoarseNet的紧凑特征的箱子数P和输入FineNet的低频特征的箱子数Q分别设置为32和128。
DPCRN:我们使用[15]中的配置来重新实现DPCRN,作为单阶段Ushaped网络的基线,称为DPCRN(base)。对于改进的轻量级版本(记为DPCRN),编码器中卷积层的通道数为64,64,64,在频率和时间维度上分别设置核大小和步长为(5,2)、(3,2)、(3,2)和(2,1)、(2,1)、(1,1),双路径LSTM的隐藏大小为64。
DFNet:我们使用[5]中的配置重新实现DFNet,并进行一些修改以满足因果设置,作为单阶段、单尺度网络的基线,称为DFNet(base)。使用了因果卷积、GRU和注意力。此外,在inter transformer模块(建模子带时间信息)中,删除了注意力,只保留了GRU。对于修改后的轻量级版本(记为DFNet),与DFNet(base)的区别在于T-F频谱的特征图C的数量被设置为48,并删除了编解码器中的密集连接。
在训练阶段,对所提出的模型进行100个epoch的训练。我们使用Adam[23]作为优化器,并使用最大l2范数为5的梯度裁剪来避免梯度爆炸。初始学习率(LR)设置为0.0004,然后每两个周期衰减0.98倍。本文的目标是设计轻量级的实时在线模型,其中模型中的所有操作(如卷积和LSTM)都是因果关系。
3.3 评估度量
对于VoiceBank+DEMAND数据集,使用宽带PESQ(记为WB-PESQ)、STOI、CSIG、CBAK和COVL作为评估指标。对于DNS数据集,采用DNSMOS P. 835[24]预测的主观结果。将3个预测得分分别记为nOVL、nSIG、nBAK,分别预测语音失真的总体主观得分、语音失真的质量得分和去噪的质量得分。
4 评估结果
4.1 烧蚀分析
表1:VoiceBank+DEMAND数据集上的消融分析结果
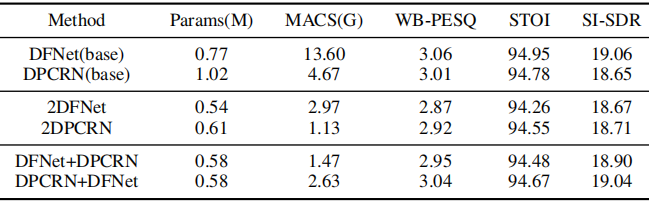
表2:DNS数据集的消融分析结果

表1和表2分别给出了在VoiceBank+DEMAND数据集和DNS数据集上的消融实验结果。将这些模型分为3类:1)单阶段模型,即DFNet(base)和DPCRN(base);2)两阶段同质模型,即2DFNet和2DPCRN;3)两阶段异构模型,即DFNet+DPCRN和DPCRN+DFNet。每个阶段的子模型进一步分为单尺度子网络和U型子网络,简称S和U,如表2所示。从表1和表2可以得到以下观察结果。
- 通过比较2DFNet/2DPCRN和DFNet(base)/DPCRN (base)可以看出,将任务分解为两个阶段并使用两个结构相同的轻量级子网络,在使用相同拓扑结构的单阶段模型上的性能下降是可以接受的,但大大减少了乘累加操作的数量。
- 通过比较DFNet+DPCRN/DPCRN+DFNet和2DFNet/ 2DPCRN,可以看出使用异构子网络的两个阶段的性能比使用同构子网络的两个阶段有明显的提高。
- 通过对比DFNet+DPCRN/DPCRN+DFNet和DFNet(base) /DPCRN(base)可知,当两阶段模型使用异构子网络时,可以取得与最佳单阶段基线模型(DFNet(base))相当的性能,但大大减少了乘累加操作的次数。
表现最好的两阶段模型是DPCRN+DFNet,这可能是因为第一阶段模型建模的是粗粒度的全频带信息,即主要需要建模整个频谱的上下文信息,这使得DPCRN更适合UNet结构的多尺度特性。第二阶段主要发挥细粒度低频频谱恢复的作用,使用不涉及下采样(即不失真谐波信息)的单尺度子网络DFNet更为合适。与DFNet(base)相比,DPCRN+DFNet在客观指标WB-PESQ、STOI、SI-SDR和主观指标nSIG、nBAK、nOVL上均取得了相当的分数,而参数数量(Params)和mac分别是DFNet(base)的75.3%和19.3%。
4.2 与其他SOTA因果方法的比较
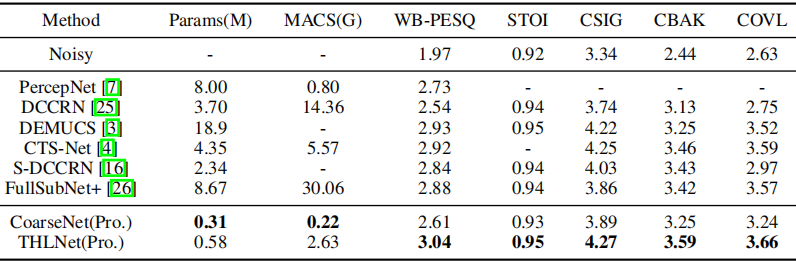
表3显示了我们提出的模型与其他SOTA因果系统在VoiceBank+DEMAND数据集上的比较。从表中可以看出,在这些先进的因果系统中,THLNet在WB-PESQ、STOI、CSIG、CBAK和COVL中得分最高,参数和mac相对较小。
表3:VoiceBank+DEMAND数据集上与其他最先进的因果系统的比较
5 讨论

图4:使用所提出模型的增强结果的说明。
(a)干净的发音的语谱图。(b)嘈杂的声音
(c) CoarseNet的增强表达。(d) THLNet增强的话语
从图4可以看出,CoarseNet可以有效地抑制噪声成分,并恢复数频谱高频部分的主要几何结构。例如,CoarseNet在背景噪声条件下取得了良好的性能,如图4 (b)和(c)中红色标记区域所示,并恢复了频谱高频部分的主要几何结构,如图4 (a)和(c)中黄色标记区域所示。但是,CoarseNet在处理频谱低频部分谐波结构细节方面表现较差。幸运的是,FineNet可以有效地恢复低频谐波结构,如图4 (c)和(d)中的绿色标记区域所示。通过使用CoarseNet和FineNet两阶段处理,得到了质量相当好的语音。
6 结论
本文提出THLNet,一种用于单声道语音增强的两阶段异构轻量级网络。该网络由一个LCRB滤波器组和两个基于掩码的子网络CoarseNet和FineNet组成,分别负责粗粒度的全频带掩码估计和细粒度的低频细化。我们使用一种新颖的LCRB滤波器组作为紧凑特征提取器。进一步,考虑到所提两阶段任务的不同特点,使用异构结构,即Ushaped子网络(DPCRN)作为CoarseNet的主干,使用单尺度子网络(DFNet)作为FineNet的主干,进一步提升了所提算法的性能。在VoiceBank + DEMAND数据集上的实验结果表明,该方法优于当前SOTA方法,同时保持了相对较小的模型大小和较低的计算复杂度。
7 参考文献
[1] Philipos C Loizou, Speech enhancement: theory and practice, CRC press, 2013.
[2] Ke Tan and DeLiang Wang, “Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 380–390, 2019.
[3] Alexandre D´efossez, Gabriel Synnaeve, and Yossi Adi, “Real Time Speech Enhancement in the Waveform Domain,” in Proc. Interspeech 2020, 2020, pp. 3291–3295.
[4] Andong Li, Wenzhe Liu, Chengshi Zheng, Cunhang Fan, and Xiaodong Li, “Two heads are better than one: A two-stage complex spectral mapping approach for monaural speech enhancement,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1829–1843, 2021.
[5] Feng Dang, Hangting Chen, and Pengyuan Zhang, “Dpt-fsnet: Dual-path transformer based full-band and sub-band fusion network for speech enhancement,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6857–6861.
[6] Jean-Marc Valin, “A hybrid dsp/deep learning approach to realtime full-band speech enhancement,” in 2018 IEEE 20th international workshop on multimedia signal processing (MMSP). IEEE, 2018, pp. 1–5.
[7] Jean-Marc Valin, Umut Isik, Neerad Phansalkar, Ritwik Giri, Karim Helwani, and Arvindh Krishnaswamy, “A PerceptuallyMotivated Approach for Low-Complexity, Real-Time Enhancement of Fullband Speech,” in Proc. Interspeech 2020, 2020, pp. 2482–2486.
[8] Hendrik Schroter, Alberto N Escalante-B, Tobias Rosenkranz, and Andreas Maier, “Deepfilternet: A low complexity speech enhancement framework for full-band audio based on deep filtering,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7407–7411.
[9] Wolfgang Mack and Emanuel AP Habets, “Deep filtering: Signal extraction and reconstruction using complex timefrequency filters,” IEEE Signal Processing Letters, vol. 27, pp. 61–65, 2019.
[10] Mohamed Abbas Hedjazi and Yakup Genc, “Efficient textureaware multi-gan for image inpainting,” Knowledge-Based Systems, vol. 217, pp. 106789, 2021.
[11] Xia Li, Jianlong Wu, Zhouchen Lin, Hong Liu, and Hongbin Zha, “Recurrent squeeze-and-excitation context aggregation net for single image deraining,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 254– 269.
[12] Tian Gao, Jun Du, Li-Rong Dai, and Chin-Hui Lee, “SNRBased Progressive Learning of Deep Neural Network for Speech Enhancement,” in Proc. Interspeech 2016, 2016, pp. 3713–3717.
[13] Xiang Hao, Xiangdong Su, Shixue Wen, Zhiyu Wang, Yiqian Pan, Feilong Bao, and Wei Chen, “Masking and inpainting: A two-stage speech enhancement approach for low snr and non-stationary noise,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6959–6963.
[14] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer, “Automatic differentiation in pytorch,” 2017.
[15] Xiaohuai Le, Hongsheng Chen, Kai Chen, and Jing Lu, “Dpcrn: Dual-path convolution recurrent network for single channel speech enhancement,” arXiv preprint arXiv:2107.05429, 2021.
[16] Shubo Lv, Yihui Fu, Mengtao Xing, Jiayao Sun, Lei Xie, Jun Huang, Yannan Wang, and Tao Yu, “S-dccrn: Super wide band dccrn with learnable complex feature for speech enhancement,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7767–7771.
[17] Xiang Hao, Xiangdong Su, Radu Horaud, and Xiaofei Li, “Fullsubnet: A full-band and sub-band fusion model for realtime single-channel speech enhancement,” in ICASSP 2021- 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6633–6637.
[18] Cassia Valentini-Botinhao, Xin Wang, Shinji Takaki, and Junichi Yamagishi, “Investigating rnn-based speech enhancement methods for noise-robust text-to-speech.,” in SSW, 2016, pp. 146–152.
[19] Christophe Veaux, Junichi Yamagishi, and Simon King, “The voice bank corpus: Design, collection and data analysis of a large regional accent speech database,” in 2013 international conference oriental COCOSDA held jointly with 2013 conference on Asian spoken language research and evaluation (OCOCOSDA/CASLRE). IEEE, 2013, pp. 1–4.
[20] Joachim Thiemann, Nobutaka Ito, and Emmanuel Vincent, “The diverse environments multi-channel acoustic noise database (demand): A database of multichannel environmental noise recordings,” in Proceedings of Meetings on Acoustics ICA2013. Acoustical Society of America, 2013, vol. 19, p. 035081.
[21] Chandan K.A. Reddy, Vishak Gopal, Ross Cutler, et al., “The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results,” in Proc. Interspeech 2020, 2020, pp. 2492–2496.
[22] Chandan KA Reddy, Dubey, et al., “Icassp 2021 deep noise suppression challenge,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6623–6627.
[23] Diederik P Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
[24] Chandan KA Reddy, Vishak Gopal, and Ross Cutler, “Dnsmos p. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in ICASSP 2022- 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 886–890.
[25] Yanxin Hu, Yun Liu, Shubo Lv, Mengtao Xing, Shimin Zhang, Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie, “DCCRN: Deep Complex Convolution Recurrent Network for PhaseAware Speech Enhancement,” in Proc. Interspeech 2020, 2020, pp. 2472–2476.
[26] Jun Chen, Zilin Wang, Deyi Tuo, Zhiyong Wu, Shiyin Kang, and Helen Meng, “Fullsubnet+: Channel attention fullsubnet with complex spectrograms for speech enhancement,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7857–7861.
作者:凌逆战
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。
本文章不做任何商业用途,仅作为自学所用,文章后面会有参考链接,我可能会复制原作者的话,如果介意,我会修改或者删除。