ACL2022-long paper 原文地址
1. 介绍(Introduction)#
问题: 由PLM编码得到的句子表示在方向上分布不均匀, 在向量空间中占据一个狭窄的锥形区域, 这在很大程度上限制了它们的表达能力.
已有的解决办法: 对比学习. 对于一个原句, 构造他的正例(语义相似的句子)和负例(语义不相似的句子), 拉近语义相近的句子来提高对齐性,同时让语义不同的句子远离来使向量空间中的句子更均匀. 正例通常用数据增强的策略来获得. 由于没有真实标注的数据, 负例一般在一个batch中随机抽样得到. 但这可能会导致抽样偏差, 影响句子表示的学习. 表现在以下两个方面:
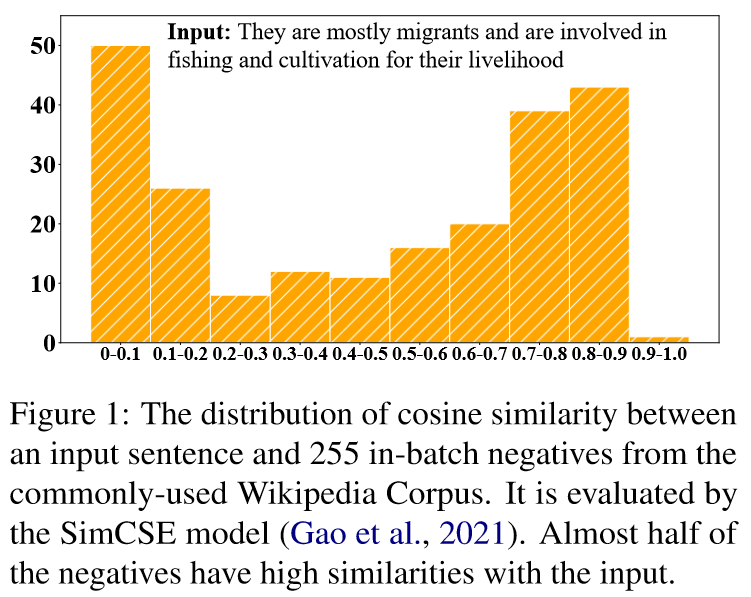
- 抽样的负例很可能是假负例, 他们在语义上其实是接近原句的. 如果简单地拉远些抽样得到的非负例, 很可能会损害句子表示的语义. 如图一所示, 一个batch中有大概一半的样本与原句的余弦相似度高于0.7.
- 由于各向异性问题, 由PLMs得到的句子向量本身就在向量空间中仅占据一个狭窄的锥形区域, 从他们中随机抽取出的负例也不能完全反映表示空间的整体语义.
2. 方法(Approach)#
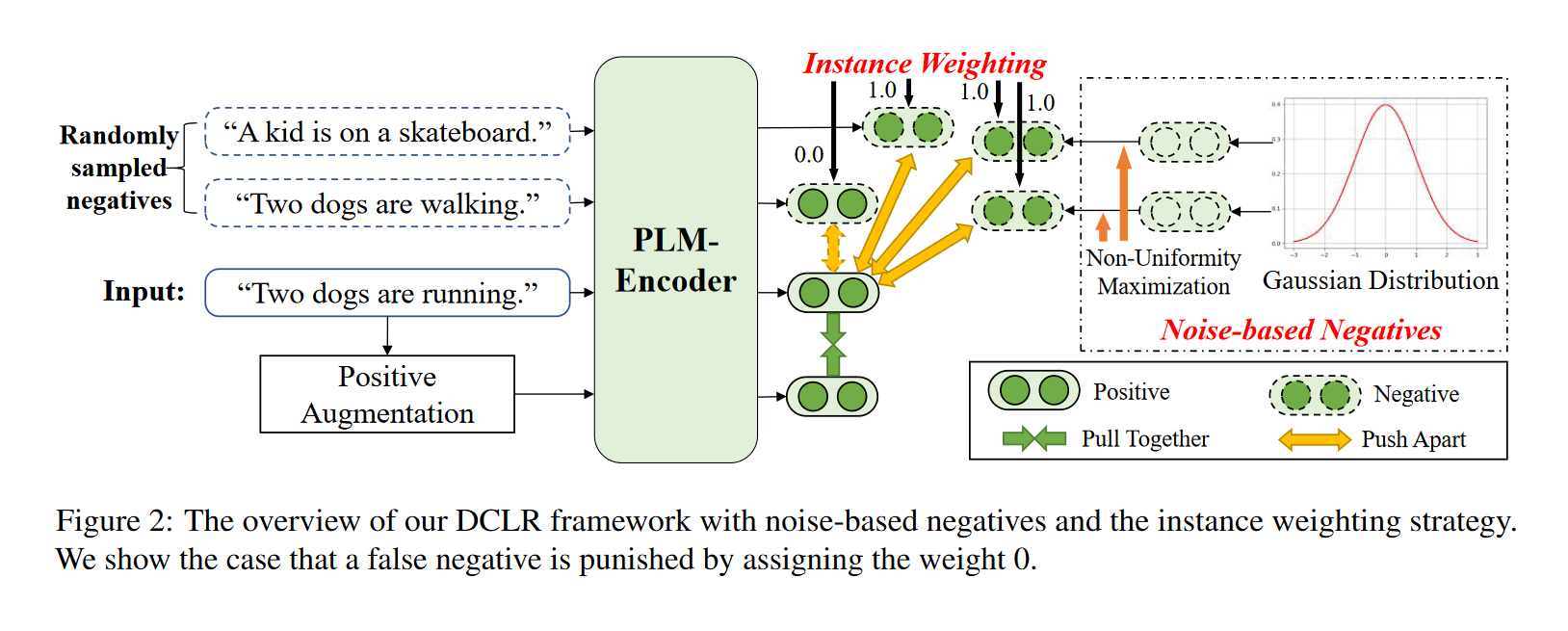
DCLR(a general framework towards Debiased Contrastive Learning of unsupervised sentence Representations), 一种无监督句子表示的去偏向对比学习的一般框架。
核心思想是改进随机负抽样策略, 以缓解抽样偏差问题:
- 设计了一种加权方法来惩罚训练过程中采样的假负例。用一个辅助模型(complementary model)来评估每个负例与原句之间的相似性,为相似性得分较高的负例分配较低的权重。
- 用基于高斯噪声随机初始化的向量作为负例来模拟在整个语义空间内进行采样,并通过梯度下降算法,将这些负例优化到最不均匀的点。
步骤:
- 从高斯分布初始化基于噪声的负例,并利用梯度下降来优化他们: 通过考虑表示空间的均匀性来更新这些负例。
- 用辅助模型对这些基于噪声的负例和在batch中随机抽样的负例进行加权, 惩罚其中的假负例.
- 通过SimCSE中dropout的方式来获得正例, 并将其与上述加权负例相结合进行对比学习.
基于高斯噪声的负例的构建与优化:
- 构建: 对于每个输入句子
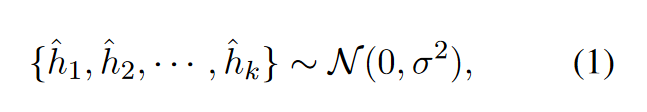
- 非均匀性损失(non-uniformity loss)来优化这些负例向量:
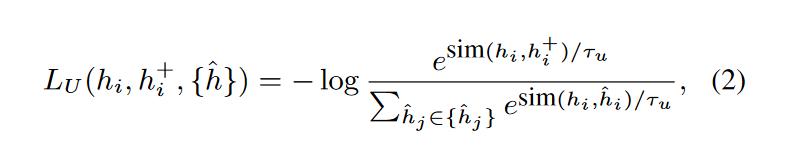
梯度下降:
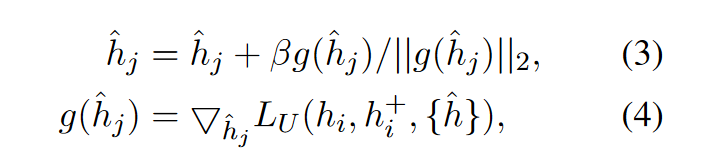
这样,基于噪声的负例将朝着句子表示空间的非均匀点进行优化. 通过学习对比这些负例, 可以进一步提高表征空间的均匀性, 这对于得到更有效的句子表示至关重要.
辅助模型(complementary model):
使用SOTA模型SimCSE作为辅助模型, 用于判断句子间的语义相似度. 具体的:
对于一个句子
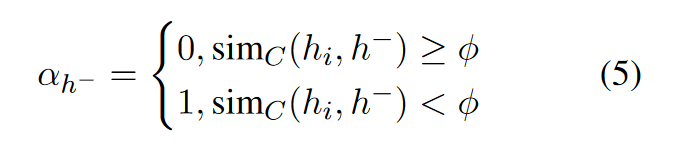
其中
对比学习的损失
最后, 对比学习的损失函数如下:
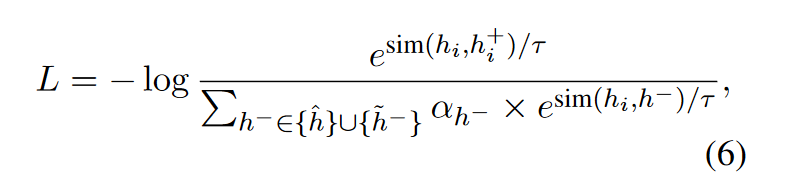
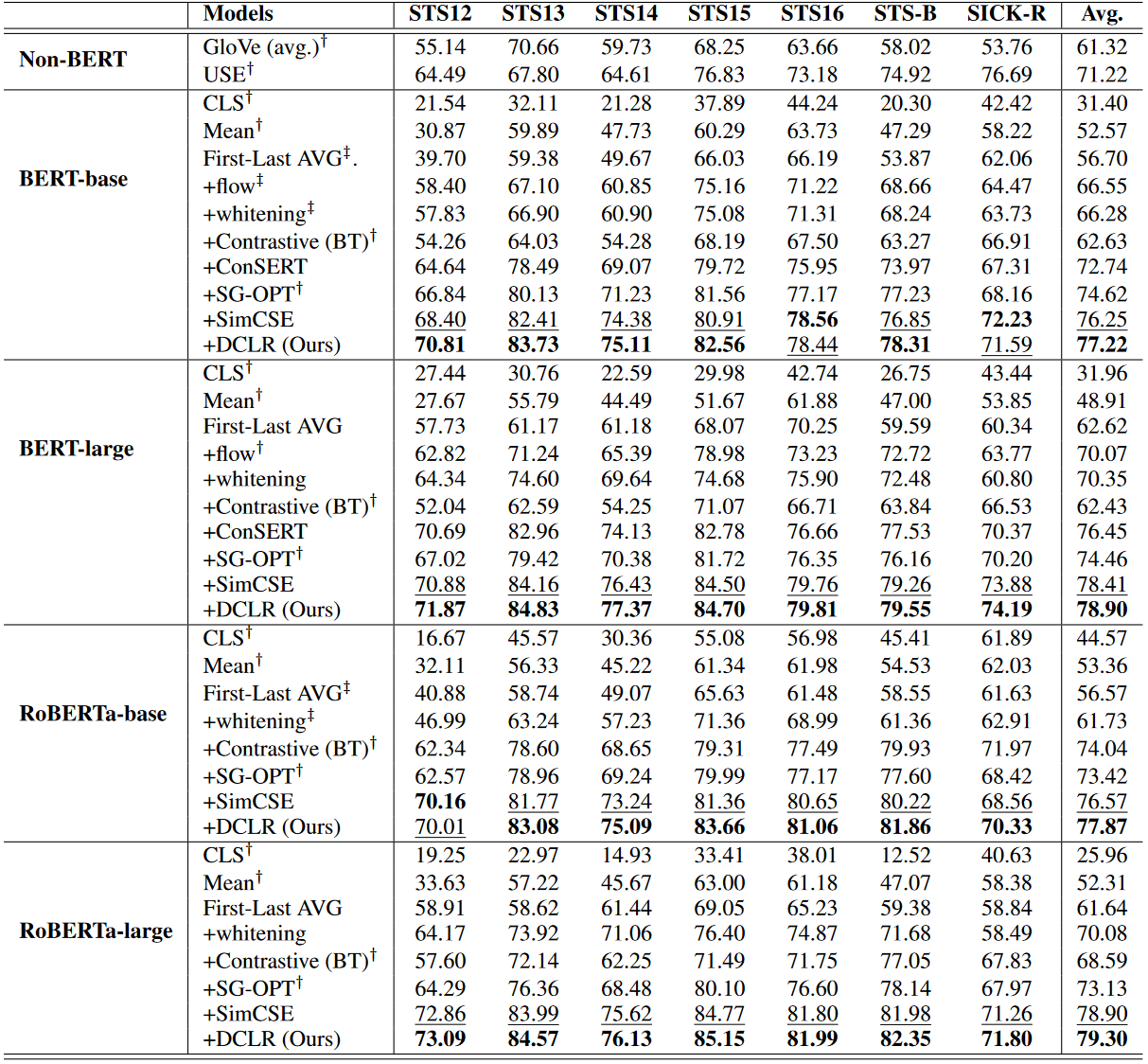
3. 性能(Performance)#
4. 分析(Analysis)#
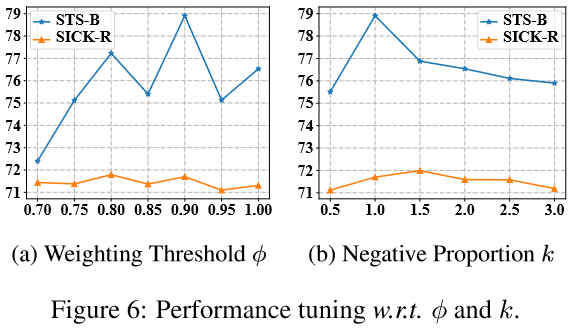
4.1 超参数分析(Hyper-parameters Analysis)#
4.2 均匀性分析(Uniformity Analysis)#
用一下损失来评估句子表示的均匀性:
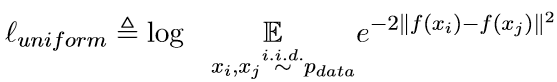
该损失值越小说明分布越均匀.
含义: 希望来自数据分布的句子之间欧氏距离的期望尽可能大.
与SimCSE的对比:
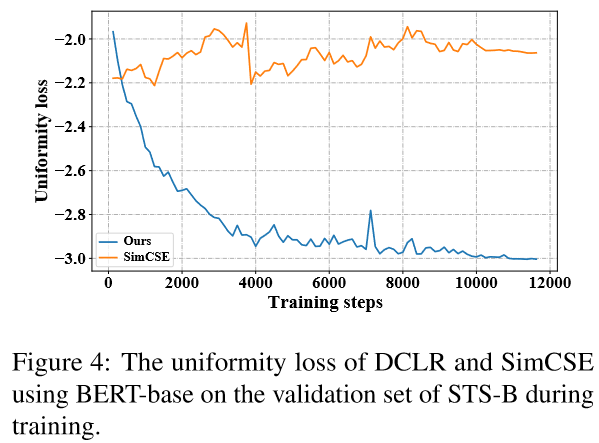
因为DCLR在表示空间之外对基于噪声的负例进行了采样, 这样可以更好地提高句子表示的均匀性.
有个问题, 文章没有对对齐性(Alignment)进行分析.
4.3 消融实验(Ablation Study)#
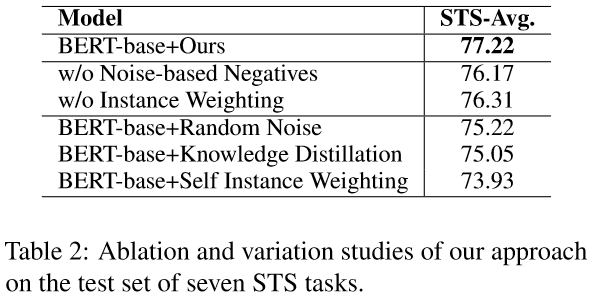
随机噪声(Random Noise): 直接生成基于噪声的负例, 不进行基于梯度的优化.
知识蒸馏(Knowledge Distillation): 利用SimCSE作为教师模型,在训练时将知识蒸馏到学生模型中.
自加权(Self Instance Weighting): 采用模型本身作为辅助模型来生成权重.
4.4 少样本下的性能(Performance under Few-shot Settings)#
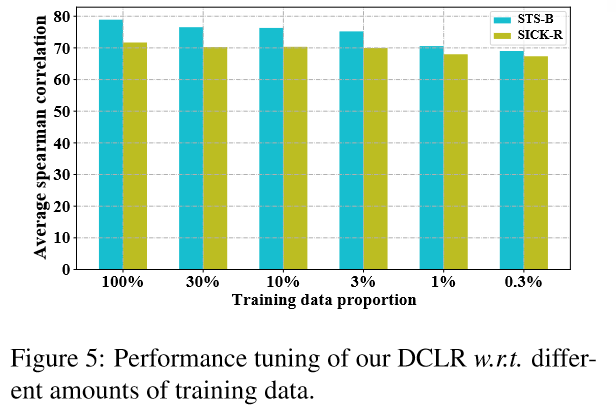
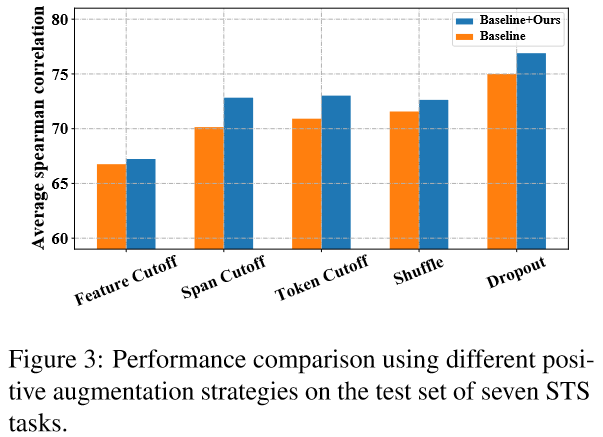
4.5 采用其他正例生成策略(Debiased Contrastive Learning on Other Methods)#
DCLR主要关注的是对比学习中的负例采样策略, 因此在构建正例时, 有多种数据增强策略可选. 文中测试了3种:
- 乱序(Token Shuffing): 随机打乱输入序列中token的顺序
- 删词(Feature/Token/Span Cutoff): 随机去掉输入中的features/tokens/token spans.
- Dropout: 即SimCSE中正例的生成方式.