本文由葡萄城技术团队于博客园原创并首发
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
前端表格控件SpreadJS 推出了新的功能集算表功能。集算表 (Table Sheet)是一个具备高性能渲染、数据绑定功能、公式计算能力的数据表格,通过全新构建的关系型数据管理器结合结构化公式,在高性能表格的基础上提供排序、筛选、样式、行列冻结、自动更新、单元格更新等功能。

什么是集算表(Table Sheet)?
集算表是一个具有网络状行为和电子表格用户界面的快速数据绑定表的视图。
众所周知Excel的工作表(Work Sheet)是一个自由式布局,基于单元格(Cell Base)的表格,适用于一些松散式的数据布局展示,布局上来说非常灵活,但对于固定格式的大批量数据展示,不具备优势。
集算表不同于Excel的工作表,它是一个基于列(Column Base)的网状表格(Grid),适用于展示规则数据。同时它还具备了Excel工作表(Work Sheet)的用户界面和部分常见操作。并且支持Excel的部分计算功能。同时结合SpreadJS数据绑定的功能,对于大量固定格式的数据(例如数据库的表格)可以快速在前端进行展示。
集算表的特点正如它的名字的三个字:集,算,表:
集(Data Manager):
集的意思就是数据集记和管理。集算表在前端构建了一个叫做Data Manager的数据管理模块。该模块可以简单理解为一个前端的数据库,Data Manager负责与远端的数据中心进行通信,拉取远端的数据。在前端处理数据,例如数据表的定义,表间关系等。同时Data Manager还负责处理数据的变形,例如分组,切片,排序,过滤等。
算(Calculation Engine):
集算表本身基于SpreadJS网络结构化数据的计算引擎Calculation Engine。Calculation Engine定义不同的上下文计算层级,不同与SpreadJS中工作表(Work Sheet)基于单元格或者区域(Range)的计算层级,集算表(Table Sheet)的上下文层级是基于行级,组级,数据级。
同时通过Calculation Engine的计算串联,使得集算表(Table Sheet)与工作表(Work Sheet)之间可以进行数据串联。这使得计算表不是一个独立存在,它可以与工作表结合使用,相互配合以适应更多的需求。
表(Table Sheet):
整个Table Sheet分为三层:渲染层,数据层,功能层。
渲染层复用了工作表(Work Sheet)的渲染引擎,具备双缓冲画布等高性能的优势。
数据层直连Data Manger,无需建立数据模型,相交SpreadJS更加快速。
功能层不同于传统表格(Grid),将底层结构化数据进行改造,在支持增删改查等基本功能的基础上,还额外支持了大部分工作表(Work Sheet)的对应功能,如样式,条件格式,数据验证,计算列等。
在数据底层,保证上述功能支持的基础上,还能保证数据的结构化,而非松散的数据结构。
集算表的架构:

Data Manager负责拉取远端数据,远端数据源可以是Rest API、OData、GraphQL、Local。Data Manager在拉取数据源之后会根据其中的定义构建数据表(Data Source),该表结构与数据库中的表结构类似。之后通过这些表来定义对应的数据视图(View),视图中定义了展示的结构以及计算列,关系列的添加。最终将不同的视图(View)绑定在不同的Table Sheet上。Table Sheet负责对所有的视图进行展示和操作。Calc Engine在Data Manager上工作,而非直接工作在Table Sheet上,这是为了更方便的去支持集算表与普通工作表之间的公式引用。这使得集算表与普通工作表之间产生“化学效应“,例如下面的示例:
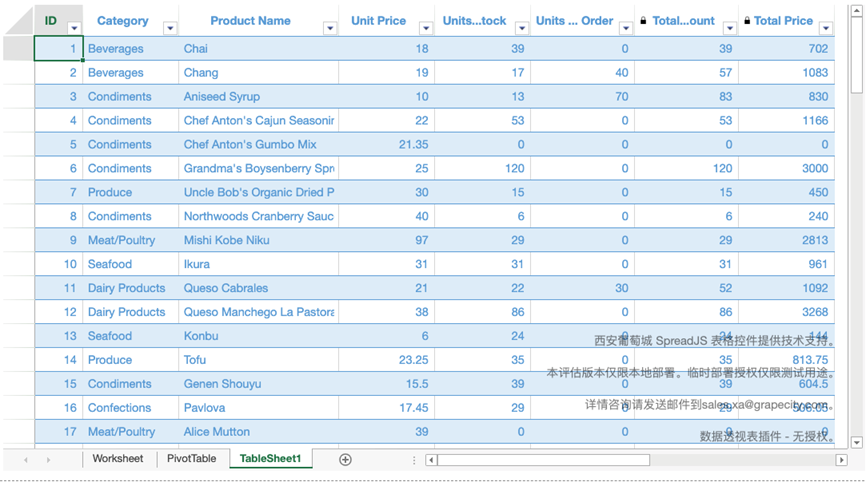
在创建了集算表之后可以在普通的工作表中直接通过公式引入集算表的表格中的数据。这样可以做到通过集算表对数据进行展示,同时通过工作表的功能,对展示的结果进行数据分析。
 |
|
 |
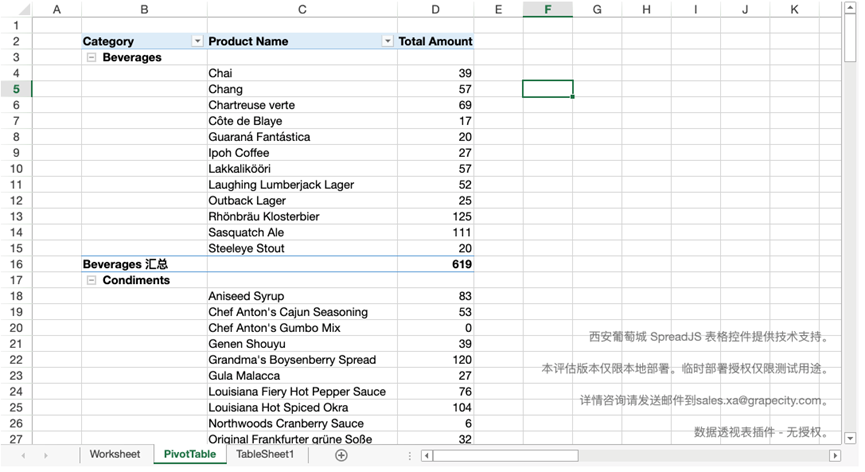
甚至可以直接引用集算表中的数据当做数据数据源,创建数据透视表。
集算表的性能:
集算表是基于Column进行数据存储,相较于基于Row的存储结构,在筛选和计算方面有很大的优势。
通过性能测试,我们可以了解到,对于100W行级别的数据,集算表
从发送请求加载数据到将表格绘制完毕总共的耗时是大约5秒钟。

筛选数据花费时间在50ms左右(Filter country == "UK")。
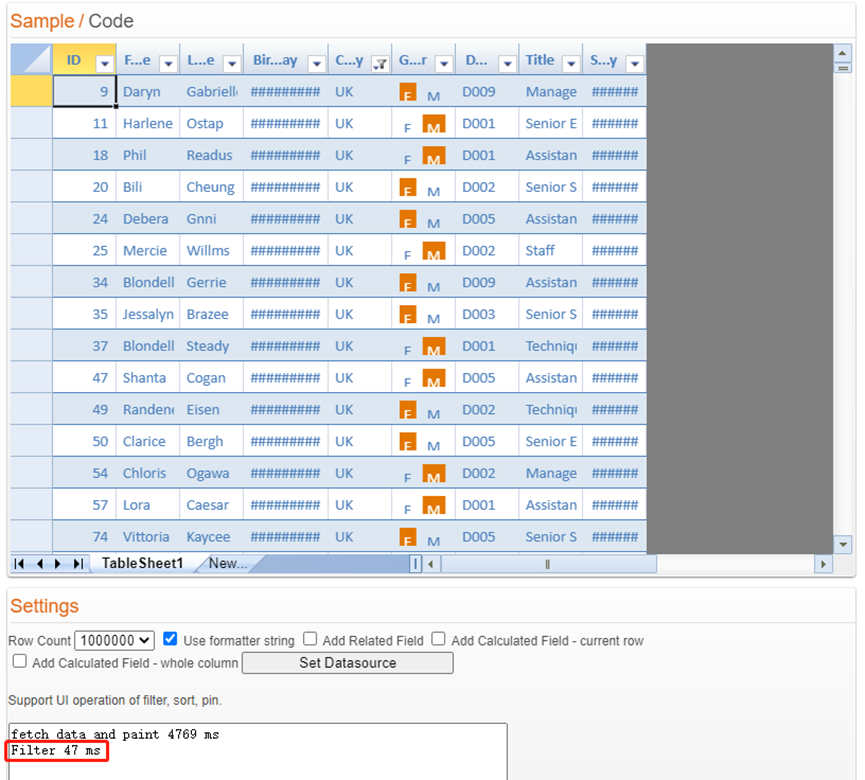
100W行数据排序花费时间在5S左右(Sort birthday == "Ascending")。

对100W行数据添加计算列,对每行数据进行计算,花费时间不明显(总计时间4807ms,但该事件包含了数据加载,绘制的总时间,对比之前的测试结果基本在4800ms左右。故添加计算列计算花费的时间不明显,可忽略不计)。

如果想要了解更多SpreadJS产品特性或者查看性能测试示例,可访问下方地址。
https://en.onboarding.grapecitydev.com/spreadjs/feature-demo/web/tableSheet/performance.html