OrientDB API v1.0.0(OrientDB 3.x)
OrientDB介绍
OrientDB是一个开源的NoSQL数据库管理系统,同时也是一款高性能的图数据库,支持ACID事务以及原子操作。
图数据库介绍
图数据库是以点、边为基础存储单元,以高效存储、查询图数据为设计原理的数据管理系统。
图概念对于图数据库的理解至关重要。图是一组点和边的集合,“点”表示实体,“边”表示实体间的关系。在图数据库中,数据间的关系和数据本身同样重要 ,它们被作为数据的一部分存储起来。这样的架构使图[数据库]能够快速响应复杂关联查询,因为实体间的关系已经提前存储到了数据库中。图数据库可以直观地可视化关系,是[存储]、查询、分析高度[互联数据]的最优办法。
图数据库属于非关系型数据库(NoSQL)。图数据库对数据的存储、查询以及数据结构都和关系型数据库有很大的不同。图数据结构直接存储了节点之间的依赖关系,而关系型数据库和其他类型的非关系型数据库则以非直接的方式来表示数据之间的关系。图数据库把数据间的关联作为数据的一部分进行存储,关联上可添加标签、方向以及属性,而其他数据库针对关系的查询必须在运行时进行具体化操作,这也是图数据库在关系查询上相比其他类型数据库有巨大性能优势的原因。
最简单的说,图数据库对于关系型数据库中的join操作具有十分高的效率,每个节点存储了所有边的引用。
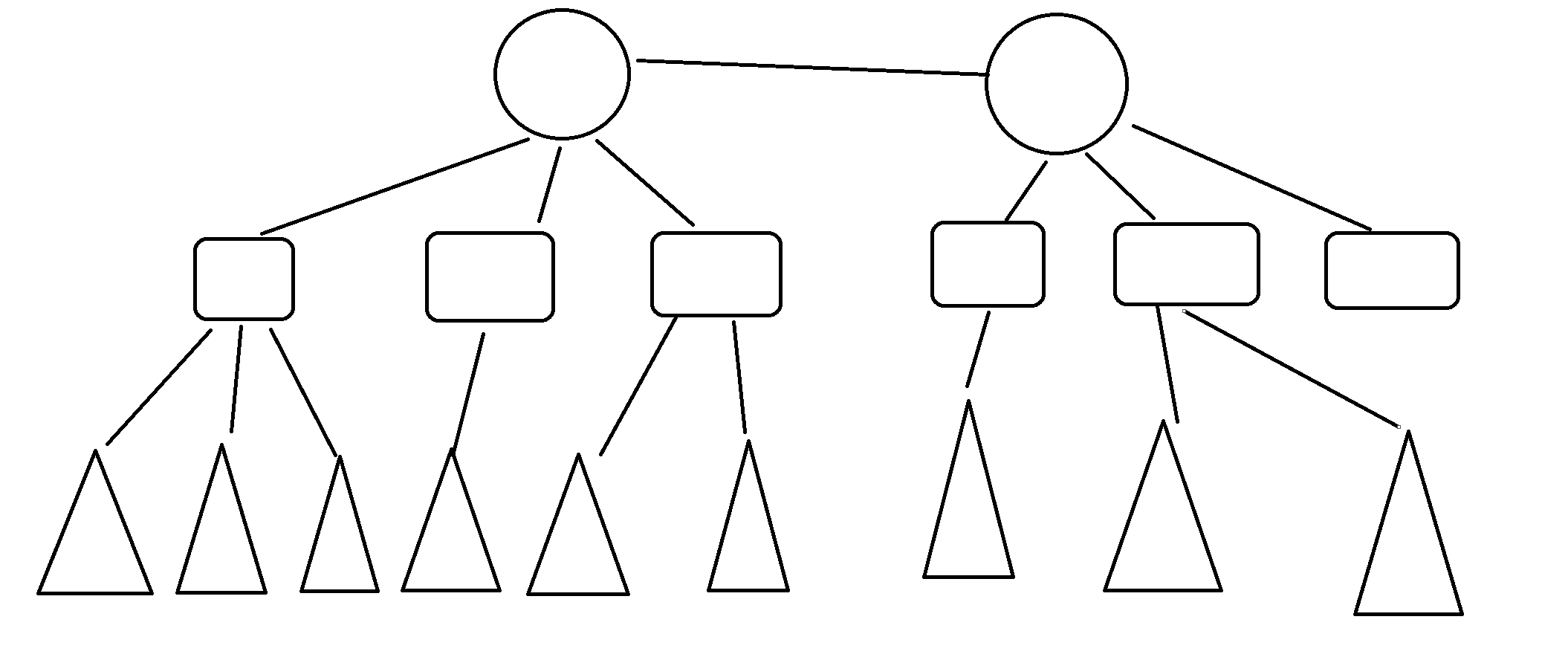
下面我们来看一个示列,加入圆代表一个学校教学楼,圆角矩形代表教学楼下面的教室,三角形代表教室的每一张桌椅,当我们需要获取一个楼宇下面的所有桌椅,在关系型数据库如MySQL中,就需要把教学楼表、教室表以及桌椅表join起来查询,虽然有索引,但当量上去后依然是一个昂贵的操作。而在图数据库如OrientDB中,就可以直接从教学楼出发通过广度优先或者深度优先直接找到桌椅,而且相比关系型数据库具有极高的效率。
OrientDB API
OrientDB是一款高性能的文档、图数据库,在关系查找、遍历方面有很大的速度优势,特别是处理传统关系型数据库中的join操作,图数据库具有无法比拟的优点。虽然OrientDB官方提供了Java的SDK,但是还是有一定的学习成本,需要手撸操作脚本,本仓库对OrientDB的Java SDK进行了二次封装,以更加自然的语言操作OrientDB,降低学习成本,使得项目能更快的集成OrientDB。
一、特性
更简单的API :话不多说上例子感受,假如我们要保存一个People对象到图数据库,先看看原生的SDK例子:
public static void main(String[] args) {
//使用原生JDK保存一个“人”顶点到图数据库
People people1 = new People("张三", "男", 18);
try (ODatabaseSession session = OrientSessionFactory
.getInstance()
.getSession()) {
//在图数据库创建Class:People
if (session.getClass("People") == null) {
session.createVertexClass("People");
}
OVertex vertex = session.newInstance();
vertex.setProperty("name", people1.getName());
vertex.setProperty("age", people1.getAge());
vertex.save();
}
}
原生的SDK将顶点封装成了Overtex对象,首先需要先获取会话ODatabaseSession,并且创建对应的顶点类,然后将实体相关的属性需要调用setProperty方法存入进去,并且保存,还要要留意关闭会话,对于属性多、数量多的实体简直是灾难,下面我们来看看使用OrientDB API:
public static void main(String[] args) {
//创建实体对象
People people2 = new People("李四", "男", 21);
//将实体对象包装成ResourceNode对象,其提供了对顶点的操作,对边的操作在ResourceRelation里
ResourceNode li = new GraphResourceNode<>(people2);
//直接调用save方法进行保存
li.save();
}
@Getter
@Setter
@ToString
//实现Vertex语义接口,表明该实体是一个图数据库的顶点对象
public class People implements Vertex {
private String name;
private String sex;
private Integer age;
public People(String name, String sex, Integer age) {
this.name = name;
this.sex = sex;
this.age = age;
}
public People() {
}
}

如上图,通过上面的语句就将实体对象People1存入了OrientDB。
更优雅的查询 :原生SDK的查询难免会跟OrientDB的SQL语句或者Match语句打交道,而且国内的中文文档很少和相关博客也很少,学习成本进一步加大,因此OrientDB API对常用查询操作进行了封装,做到完全透明化,下面我们来看一个示列:使用原生SDK进行查询:
public static void main(String[] args) {
try (ODatabaseSession session = OrientSessionFactory
.getInstance()
.getSession()) {
OResultSet resultSet = session.query("select * from People where name = ?", "李四");
People people=new People();
while(resultSet.hasNext()){
OResult result= resultSet.next();
people.setName(result.getProperty("name"));
people.setAge(result.getProperty("age"));
}
resultSet.close();
}
}
原生JDK使用起来跟JDBC差不多,体验差,下面看看OrientDB API查询:
public static void main(String[] args) {
//创建资源图对象,其提供了很多对图的直接操作。使用OrientDB存储库(后续可以拓展Neo4j等存储库)
ResourceGraph graph = new ResourceGraph(new OrientDBRepository());
//调用extractNode方法取出指定节点
ResourceNode peopleResourceNode = graph.extractNode(QueryParamsBuilder
.newInstance()
.addParams("name", "李四")
.getParams());
//获取节点对应的属性实体
People people = peopleResourceNode.getSource();
}
更人性化的遍历 : 单一的查询肯定不能满足实际的需要,OrientDB提供了图的遍历,支持更复杂的查询,通过遍历我们能找到与任意一个节点有某种关系的其他节点,使用原生SDK如下:
public static void main(String[] args) {
try (ODatabaseSession session = OrientSessionFactory
.getInstance()
.getSession()) {
//从顶点#74:0出发,深度优先遍历7层以内的同学,并且进行分页
OResultSet resultSet = session.query("select * from (traverse * from #74:0 MAXDEPTH 7 STRATEGY DEPTH_FIRST) where (@class = \"Classmate\") skip 0 limit 10");
List classMates=new ArrayList<>();
while(resultSet.hasNext()){
ClassMates classMate=new ClassMates(null);
OResult result= resultSet.next();
classMate.setDate(result.getProperty("date"));
//...
classMates.add(classMate);
}
resultSet.close();
}
}
使用OrientDB API
public static void main(String[] args) {
//创建资源图对象,其提供了很多对图的直接操作。使用OrientDB存储库(后续可以拓展Neo4j等存储库)
ResourceGraph graph = new ResourceGraph(new OrientDBRepository());
//直接调用traverse方法,参数分别是,出发节点、深度、遍历策略、分页配置、目标实体类型
PagedResultextends Vertex>> result = graph.traverse(graph.extractNode("#74:0"),
QueryParamsBuilder
.newInstance()
.getParams(), 7, TraverseStrategy.DEPTH_FIRST, new PageConfig(1, 10, true), ClassMates.class);
result
.getSources()
.forEach(item -> System.out.println(item.getSource()));
}
无需语句,透明化,更人性化。
二、详细用法
图的元素分为顶点和边两类,在使用图数据库时我们一定要想好以前在关系型数据库中存的数据如何在建立模型,如介绍中的教学楼-教室-桌椅模型。创建好模型后就需要定义顶点实体类,如特性中的People类,以及关系类顶点实体类需要实现Vertex接口,关系类需要实现Edge接口。
图数据库的相关配置在orientdb-config.yml中下面是一个配置示列:
orientDB:
# 图数据库IP地址
url: "localhost"
# 图数据库库名
database: "testDB"
# 访问用户名
username: "root"
# 访问密码
password: "0000"
# 连接池配置
pool:
min: 5
max: 30
acquireTimeout: 30
2.1 创建顶点
public static void main(String[] args) {
//创建实体对象
People people2 = new People("李四", "男", 21);
//将实体对象包装成ResourceNode对象,其提供了对顶点的操作,对边的操作在ResourceRelation里
ResourceNode li = new GraphResourceNode<>(people2);
//直接调用save方法进行保存
li.save();
}
2.2 创建边
public static void main(String[] args) {
//创建实体对象
People people1 = new People("张三", "男", 18);
People people2 = new People("李四", "男", 21);
//创建关系对象
FriendOf friendOf = new FriendOf();
//封装成ResourceNode对象
ResourceNode zhang = new GraphResourceNode<>(people1);
ResourceNode li = new GraphResourceNode<>(people2);
//封装成ResourceRelation对象
ResourceRelation friend = new GraphResourceRelation<>(friendOf);
//直接调用ResourceRelation的link方法创建有向边,如果顶点还未创建会先创建顶点
friend.link(zhang, li);
//或者调用linkUndirected创建无向边,即会创建两条互相指向的边
friend.linkUndirected(zhang,li)
}
2.3 分页查询
public static void main(String[] args){
//通过指定PageCofig来实现分页查询,构造函数参数列表分别代表:页号、页大小、是否查询总数
PagedResultextends Vertex>> pagedResult = graph.extractNodes(QueryParamsBuilder
.newInstance()
.addParams("sex", "男")
.getParams(), new PageConfig(1, 5, true));
System.out.println("分页结果:"+pagedResult.getSources());
System.out.println("总条数:"+pagedResult.getTotal());
}
2.4 关系查找
public static void main(String[] args){
//创建资源图对象,其提供了很多对图的直接操作。使用OrientDB存储库(后续可以拓展Neo4j等存储库)
ResourceGraph graph = new ResourceGraph(new OrientDBRepository());
//查找张三的朋友的朋友
graph
//获取关系匹配器
.getGraphResourceNodeMatcher()
//张三作为起始节点
.asStart(zhang)
//查找张三的朋友
.findUndirected(FriendOf.class)
//查找张三的朋友的朋友
.findUndirected(FriendOf.class)
//将结果收集成People对象
.collect(People.class)
//遍历打印
.forEach(item -> System.out.println(item.getSource()));
}
2.5 最短路径搜索
public static void main(String[] args){
//查询张到李的最短路径,参数列表分别是:起始顶点、终止顶点、关系方向,无向边任意方向都可、路径最大深度、路径要经过的边类型
Listextends Vertex>> find4 = graph.shortestPath(zhang, li, RelationDirection.OUT, 3, FriendOf.class);
find4.forEach(item -> System.out.println(item.getSource()));
}
2.6 属性修改
public static void main(String[] args){
//修改张的年龄为15岁
zhang.update(QueryParamsBuilder
.newInstance()
.addParams("age", 15)
.getParams())
}
2.7 元素删除
public static void main(String[] args){
//移除张
zhang.remove();
}
2.8 关系重定向
关系重定向意思是将原来的A->B的关系变更成A->C。
public static void main(String[] args){
ResourceRelation friend = graph.extractRelation(QueryParamsBuilder
.newInstance()
.addParams("date", new Date())
.getParams());
//参数列表分别是:要重定向的关系,重定向到的目标
graph.relink(friend, li);
}
2.9 批量创建关系和顶点
public static void main(String[] args){
//构建参数key是连接的关系,value是目标顶点
Map> toMap = new HashMap<>();
toMap.put(new FriendOf(), li);
toMap.put(new FriendOf(), wang);
toMap.put(new FriendOf(), huang);
toMap.put(new FriendOf(), hu);
//调用linksUndirected方法,返回所有的关系
Listextends Edge>> relations = zhang.linksUndirected(toMap);
relations.forEach(item -> System.out.println(item.getInEdgeId() + "," + item.getOutEdgeId()));
}
其他更多API正在更新中......