-
向量嵌入:AutoGPT的幻觉解法?

来源|Eye on AI
OneFlow编译
翻译|贾川、杨婷、徐佳渝“一本正经胡说八道”的幻觉问题是ChatGPT等大型语言模型(LLM)亟需解决的通病。虽然通过人类反馈的强化学习(RLHF),可以让模型对错误的输出结果进行调整,但在效率和成本上不占优势,况且仅通过RLHF并不能彻底解决问题,由此也限制了模型的实用性。
由于大型语言模型的本质是基于语言的“统计概率”,幻觉现象表明,LLM并没有真正理解它所生成的内容,也不具备对错的概念。
此前,OpenAI首席科学家Ilya Sutskever谈到,他希望通过改进强化学习反馈步骤来阻止神经网络产生“幻觉”,他对解决这一问题非常自信,但只说了一句“让我们拭目以待”。
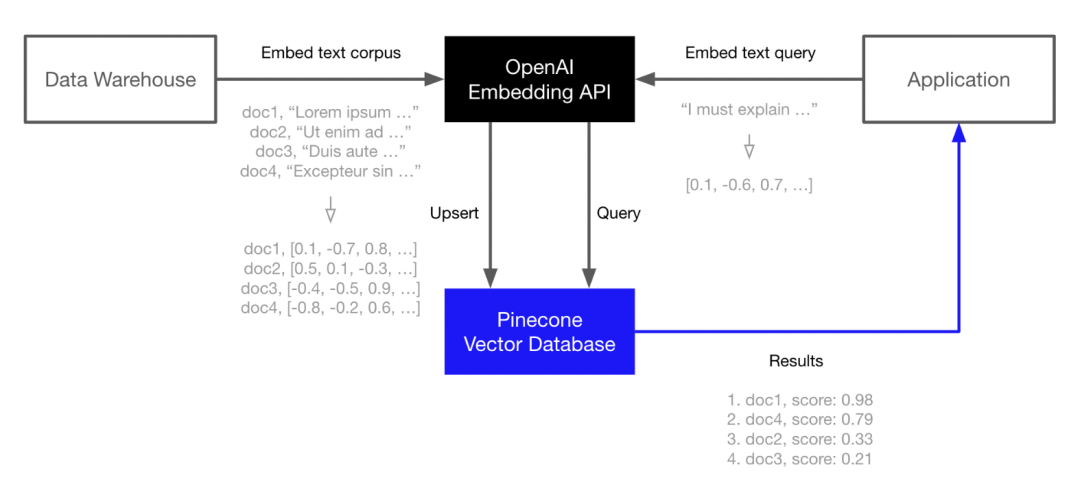
不过,向量嵌入(vector embeddings)看上去是解决这一挑战的更为简单有效的方法,它可以为LLM创建一个长期记忆的数据库。通过将权威、可信的信息转换为向量,并将它们加载到向量数据库中,数据库能为LLM提供可靠的信息源,从而减少模型产生幻觉的可能性。
最近,爆火的AutoGPT就集成了向量数据库Pinecone,可以让它进行长期内存存储,支持上下文保存并改进决策。
Pinecone是OpenAI、Cohere等LLM生成商的合作方。现在,用户可以通过OpenAI的Embedding API生成语言嵌入,然后在Pinecone中为这些嵌入建立索引,以实现快速且可扩展的向量搜索。
“嵌入(embedding)”一词最初由Yoshua Bengio于2003年提出。捷克计算机科学家Tomas Mikolov在2013年提出了文本向量表示的工具包word2vec,可用于下游深度学习任务。
Pinecone创始人Edo Liberty在亚马逊工作期间就负责向量嵌入,在离开亚马逊后开始研发Pinecone向量数据库。他是耶鲁大学计算机科学博士学位,曾担任雅虎的技术总监,并负责管理AI实验室。随后在AWS构建了包括SageMaker机器学习平台和服务。2019年年中,他意识到大型语言模型具有特殊意义,通过深度学习模型表示数据的新方法将成为数据和AI的基本组成部分。
近期,在Eye on AI播客的主持人Craig S. Smith与Edo Liberty的对话中,他介绍了如何通过向量嵌入解决LLM的幻觉问题,并分享了技术细节和构建流程。
(以下内容经授权后由OneFlow编译发布,译文转载请联系OneFlow获得授权。原文: https://www.eye-on.ai/podcast-117;sponsored by Netsuite,netsuite.com/eyeonai
-
相关阅读:
重温 JavaScript 系列(3):Set、Map、内存泄露情况、json和xml数据、delete能删除什么、defer和async区别
《opencv学习笔记》-- 亚像素角点检测
校园综合服务平台V3.9.2 源码修复大部分已知BUG
Python-tracemalloc-跟踪内存分配
i5 12490f用什么主板 酷睿i5 12490f配什么显卡
HttpClient发送MultipartFile多文件及多参数请求
MySQL备份与恢复
sso 四种授权模式
基于ELK搭建的本地社工库
Csdn文章编写参考案例
- 原文地址:https://blog.csdn.net/OneFlow_Official/article/details/130377304