-
理解深度可分离卷积
1、常规卷积
常规卷积中,连接的上一层一般具有多个通道(这里假设为n个通道),因此在做卷积时,一个滤波器(filter)必须具有n个卷积核(kernel)来与之对应。一个滤波器完成一次卷积,实际上是多个卷积核与上一层对应通道的特征图进行卷积后,再进行相加,从而输出下一层的一个通道特征图。在下一层中,若需要得到多个通道的特征图(这里假设为m个通道),那么对应的滤波器就需要m个。
用通俗的话来概括卷积,他起到的作用就是两个:一个是对上一层的特征图进行尺寸调整,另一个是则是对上一层的特征图数量进行调整,也就是通道数的调整。对于一张5×5像素、三通道(shape为5×5×3),经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4,最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3
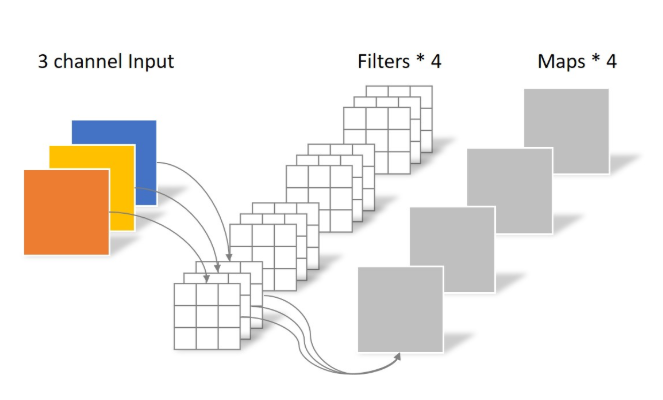
普通卷积 卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
N s t d = 4 × 3 × 3 × 3 = 108 N_std = 4 × 3 × 3 × 3 = 108 Nstd=4×3×3×3=1082、深度可分离卷积
深度可分离卷积其实只对常规卷积做了一个很小的改动,但是带来的确实参数量的下降,这无疑为网络的轻量化带来了好处。
深度可分离卷积分为两步,第一,对于来自上一层的多通道特征图,将其全部拆分为单个通道的特征图,分别对他们进行单通道卷积,然后重新堆叠到一起。这被称之为逐通道卷积(Depthwise Convolution)。这个拆分的动作十分关键,在这一步里,它只对来自上一层的特征图做了尺寸的调整,而通道数没有发生变化。第二,将前面得到的特征图进行第二次卷积,这是采取的卷积核都是1×1大小的,滤波器包含了与上一层通道数一样数量的卷积核。一个滤波器输出一张特征图,因此多个通道,则需要多个滤波器。这又被称之为逐点卷积(Pointwise Convolution)。2.1 逐通道卷积
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。
一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
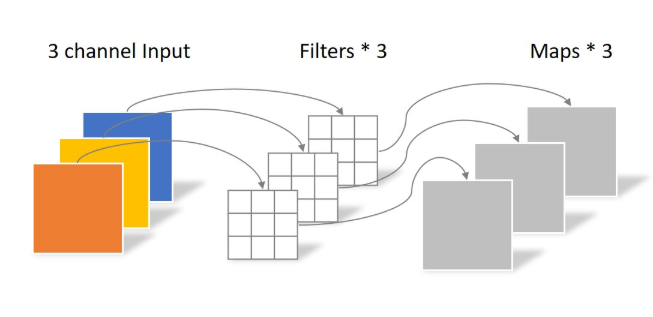
逐通道卷积(Depthwise Convolution) 其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N d e p t h w i s e = 3 × 3 × 3 = 27 N_depthwise = 3 × 3 × 3 = 27 Ndepthwise=3×3×3=27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map2.2 逐点卷积
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map
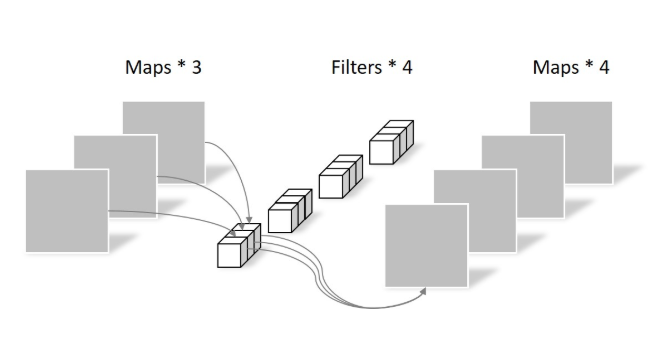
逐点卷积(Pointwise Convolution) 由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N p o i n t w i s e = 1 × 1 × 3 × 4 = 12 N_pointwise = 1 × 1 × 3 × 4 = 12 Npointwise=1×1×3×4=12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同3、参数对比
回顾一下,常规卷积的参数个数为:
N s t d = 4 × 3 × 3 × 3 = 108 N_std = 4 × 3 × 3 × 3 = 108 Nstd=4×3×3×3=108
Separable Convolution的参数由两部分相加得到:
N d e p t h w i s e = 3 × 3 × 3 = 27 N p o i n t w i s e = 1 × 1 × 3 × 4 = 12 N s e p a r a b l e = N d e p t h w i s e + N p o i n t w i s e = 39Ndepthwise=3×3×3=27Npointwise=1×1×3×4=12Nseparable=Ndepthwise+Npointwise=39N d e p t h w i s e = 3 × 3 × 3 = 27 N p o i n t w i s e = 1 × 1 × 3 × 4 = 12 N s e p a r a b l e = N d e p t h w i s e + N p o i n t w i s e = 39 相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
-
相关阅读:
HCIP-datacom
“追梦长三角 智汇赢未来” 嘉兴经济技术开发区第四届创新创业大赛城市海选赛圆满收官
基于WOA算法的SVDD参数寻优matlab仿真
Vue3 + Quasar系列-代码配置以及报错汇总记录(不断更新中)
论文的框架和逻辑如何把握?
MySQL8.0优化 - 优化MySQL服务器、优化MySQL的参数、优化数据类型
Vue3.2+TypeScript管理模块记录1-登录模块
基于SpringBoot的教学资源库系统的设计与实现
linux部署minio对象存储、docker部署minio象存储、k8s部署minio象存储
windows onlyoffice教程
- 原文地址:https://blog.csdn.net/qq_43522889/article/details/130889229