本文将探讨如何使用c#开发基于大语言模型的私域聊天机器人落地。大语言模型(Large Language Model,LLM 这里主要以chatgpt为代表的的文本生成式人工智能)是一种利用深度学习方法训练的能够生成人类语言的模型。这种模型可以处理大量的文本数据,并学习从中获得的模式,以预测在给定的文本上下文中最可能出现的下一个词。 在一般场景下LLM可以理解用户提出的问题并生成相应的回答。然而由于其训练时的数据限制LLM无法处理特定领域的问题。因此我们需要探索一种方法让LLM能够获取并利用长期记忆来提高问答机器人的效果。
这里我们主要是用到了词嵌入向量表示以及对应的向量数据库持久化存储,并且通过相似度计算得到长期记忆用于模型对特定领域的特定问题进行作答。词嵌入是自然语言处理(NLP)中的一个重要概念,它是将文本数据转换成数值型的向量,使得机器可以理解和处理。词嵌入向量可以捕获词语的语义信息,如相似的词语会有相似的词嵌入向量。而向量数据库则是一种专门用来存储和检索向量数据的数据库,它可以高效地对大量的向量进行相似性搜索。
目标:如何利用C#,词嵌入技术和向量数据库,使LLM实现长期记忆,以落地私域问答机器人。基于以上目的,我们需要完成以下几个步骤,从而实现将大语言模型与私域知识相结合来落地问答机器人。
一、私域知识的构建与词嵌入向量的转换
首先我们应该收集私域知识的文本语料,通过清洗处理得到高质量的语意文本。接着我们将这些文本通过调用OpenAI的词嵌入向量接口转化为词嵌入向量表示的数组
这里我们以ChatGLM为例,ChatGLM是清华大学开源的文本生成式模型,其模型开源于2023年。所以在ChatGPT的知识库中并不会包含相关的领域知识。当直接使用ChatGPT进行提问时,它的回答是这样的
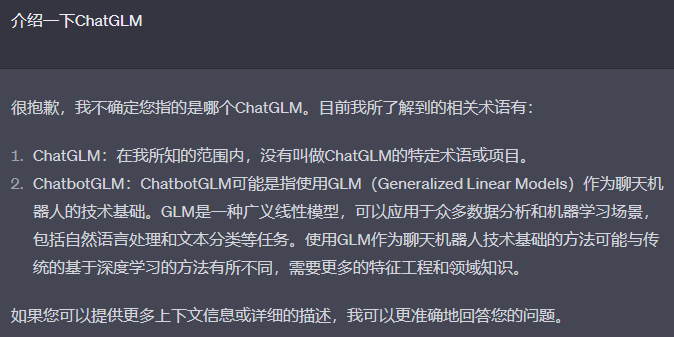
由于只是演示这里我们只准备一条关于chatglm的知识。通过调用openai的接口,将它转化成词嵌入向量
1 | 原始语料:ChatGLM是一个开源的清华技术成果转化的公司智谱AI研发的支持中英双语的对话机器人它支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。 |
接着准备好一个openai的开发者key,我们将这段文本转化成词嵌入,这里我使用Betalgo.OpenAI.GPT3这个Nuget包,具体代码如下:
1 2 3 4 5 6 | var embeddings = await new OpenAiOptions() { ApiKey = key }.Embeddings.CreateEmbedding(new EmbeddingCreateRequest() { InputAsList = inputs.ToList(), Model = OpenAI.GPT3.ObjectModels.Models.TextEmbeddingAdaV2 });return embeddings.Data.Select(x => x.Embedding).ToList(); |
这里的inputs就是你的句子数组,由于这个接口可以一次处理多条句子,所以这里可以传入句子数组来实现批处理。
接着这里会返回词嵌入向量结果,类似如下的list
1 | [-0.0020597207,-0.012355088,0.0037828966,-0.032127112,-0.04815184,0.016633095,-0.01277577,........] |
二、对词嵌入向量的理解和使用
接着我们需要使用一个向量数据库,这里由于只是演示,我就是用elasticsearch这样的支持向量存储的搜索引擎来保存。这里我使用NEST作为操作ES的包
首先我们构建一个对应的实体用于读写ES,这里的向量维度1536是openai的词嵌入向量接口的数组长度,如果是其他词嵌入技术,则需要按需定义维度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | public class ChatGlmVector{ public ChatGlmVector() { Id = Id ?? Guid.NewGuid().ToString(); } [Keyword] public string Id { get; set; } [Text] public string Text { get; set; } [DenseVector(Dimensions = 1536)] public IList<double> Vector { get; set; }} |
接着我们使用NEST创建一个索引名(IndexName)并存储刚才得到的文本和向量表示,这里的item就是上文的ChatGlmVector实例。
1 2 3 | if (!elasticClient.Indices.Exists(IndexName).Exists) elasticClient.Indices.Create(IndexName, c => c.Mapawait elasticClient.IndexAsync(item, idx => idx.Index(IndexName)); |
三、用户问题的处理与相似度计算
用户问题的处理和知识处理相似,将用户问题转化成词嵌入向量。这里主要讲一下如何基于ES做相似度搜索,以下是原始的请求es的json表示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | POST /my_index/_search{ "size": 3, // 返回前3个最相似的文档 "query": { "function_score": { "query": { "match_all": {} }, "functions": [ { "script_score": { "script": { "source": "def cosineSim = cosineSimilarity(params.queryVector, 'vector'); if (cosineSim > 0.8) return cosineSim; else return 0;", "params": { "queryVector": [1.0, 2.0, 3.0] // 要查询的向量 } } } } ], "boost_mode": "replace" } }} |
我们在c#中使用NEST的表示可以通过如下代码来完成,这里我们以0.8作为一个阈值来判断相似度最低必须高于这个数字,否则可以判断用户问题与知识没有关联性。当然这个值可以根据实际情况调整。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | var scriptParams = new Dictionary<string, object>{ {"queryVector", new double[]{1.0, 2.0, 3.0}}};var script = new InlineScript("def cosineSim = cosineSimilarity(params.queryVector, 'vector'); if (cosineSim > 0.8) return cosineSim; else return 0;"){ Params = scriptParams};var searchResponse = client.Search<object>(s => s .Size(3) .Query(q => q .FunctionScore(fs => fs .Query(qq => qq .MatchAll() ) .Functions(fu => fu .ScriptScore(ss => ss .Script(sc => script) ) ) .BoostMode(FunctionBoostMode.Replace) ) )); |
四、构建精巧的prompt与OpenAI的chat接口的使用
这里我们就可以通过一些混合一些提示+长记忆+用户问题作为完整的prompt喂给chatgpt得到回答
1 2 3 4 5 6 7 8 9 | return (await GetOpenAIService().ChatCompletion.CreateCompletion(new ChatCompletionCreateRequest() { Messages=new List ChatMessage.FromUser("你是一个智能助手,你需要根据下面的事实依据回答问题。如果用户输入不在事实依据范围内,请说\"抱歉,这个问题我不知道。\""),ChatMessage.FromUser($"事实依据:{这里需要从ES查询出相似度最高的文本作为LLM的长期记忆}"),ChatMessage.FromUser($"用户输入:{这里是用户的原始问题}") }, Model = OpenAI.GPT3.ObjectModels.Models.ChatGpt3_5Turbo })).Choices.FirstOrDefault().Message; |
当我们使用新的提示词提问后,chatgpt就可以准确的告诉你相关的回答:

写在最后
ChatGPT的出现已经彻底改变了这个世界,作为一个开发人员,我们能做的只能尽量跟上技术的脚步。在这个结合C#、词嵌入技术和向量数据库将大语言模型成功应用到私域问答机器人的案例中只是大语言模型落地的冰山一角,这仅仅是开始,我们还有许多可能性等待探索........