1. 介绍
事情是这样的,UAT 环境的测试小伙伴向我扔来一个小 bug,说是一个放大镜的查询很慢,转几分钟才出数据,我立马上开发环境试了一下,很快啊我说😏,放大镜的数据立马就出来了,然后我登录 UAT 环境一看,诶是有些慢😕 ,于是开始了我的排查之旅...
2. 过程
首先我立马拿到了执行的 SQL 在开发环境的数据库执行了下,很快,都在 1s 左右,感觉没啥问题啊,然后我就在页面上点点点,发现好像上面有一个相关联的下拉框,如果选中的有数据,再点击这个放大镜就会慢一点,然后我登录 UAT 环境一试,哦不是这个问题,于是只能开始排查 SQL 了。
百度了一圈 Oracle 性能调优,大多很空泛,没有一个通用的、具体的、可执行的步骤。但是找到了排查前必备的查看执行计划explain plan。
以下是正儿八经的优化过程👇:
2.1 查看该条 SQL 的执行计划
2.1.1 生成执行计划
在要排查的SQL前面加上explain plan for,例如以下的例子:
explain plan for
SELECT
*
FROM
SOURCE_LISTEX_202101
WHERE
pass_id = '012101200123001025061320201201002852';
2.1.2 查看执行计划
推荐使用该 SQL 去查询执行计划👍 (为什么?因为简短好记😂)
select * from table(dbms_xplan.display)
或者
SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE'));
查出来的应该是这个样子:
Plan hash value: 1335523602
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 44479 | 38M| 17411 (1)| 00:03:29 |
| 1 | TABLE ACCESS BY INDEX ROWID | SOURCE_LISTEX_202101 | 44479 | 38M| 17411 (1)| 00:03:29 |
|* 2 | INDEX RANGE SCAN | LISTEX_202101_PASS_ID | 17792 | | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("PASS_ID"='012101200123001025061320201201002852')
而且如果你的 SQL 长了之后会发现,Operation 列是会有缩进的,缩进代表层级关系,就很乱😥,这里我推荐 Datagrip👍的右键可视化Explain plan。
使用方法为:选中SQL,右键Explain Plan,就可以查看啦,大概长这个样子:
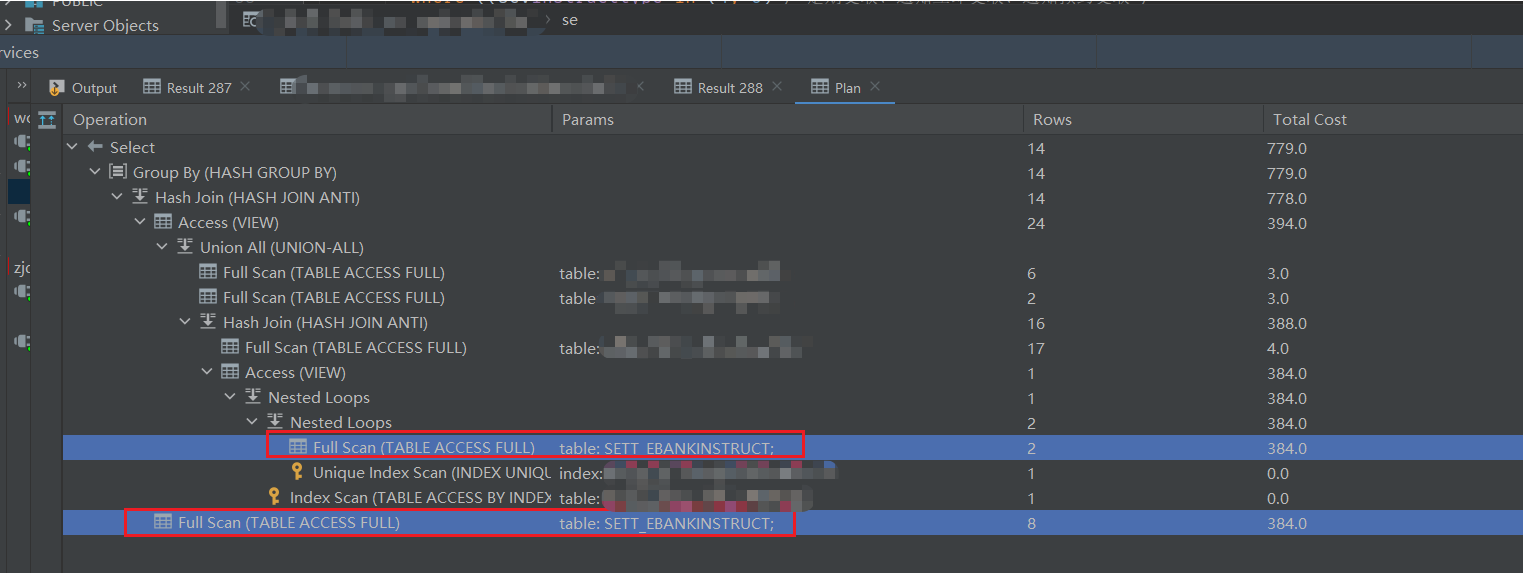
其中点击 Explain Plan (Raw),也是可以的,就是查看原生的执行计划样子,大概长这样:
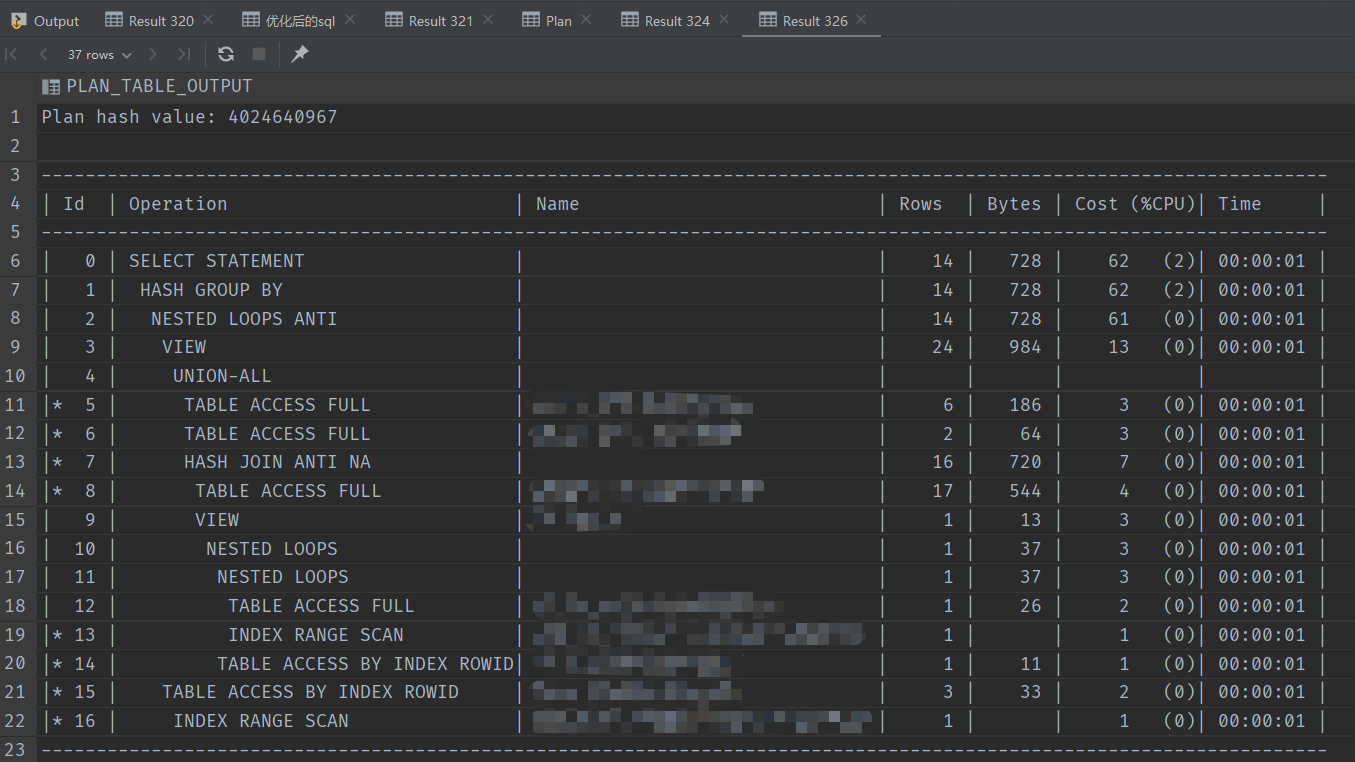
2.1.3 分析执行计划
在 1.2 节可视化那个图中,我们主要看表格中的 Total Cost, 它代表着该条操作的总消耗,我们根据层级关系逐个排查,找到最为耗时的操作,排查发现此处两个Full Scan 全表扫描的性能消耗占据了全部总消耗的98% ((384+384)/779)😖
之后根据执行计划的层级关系我们去 SQL 中找到这两个全表扫描对应的部分:
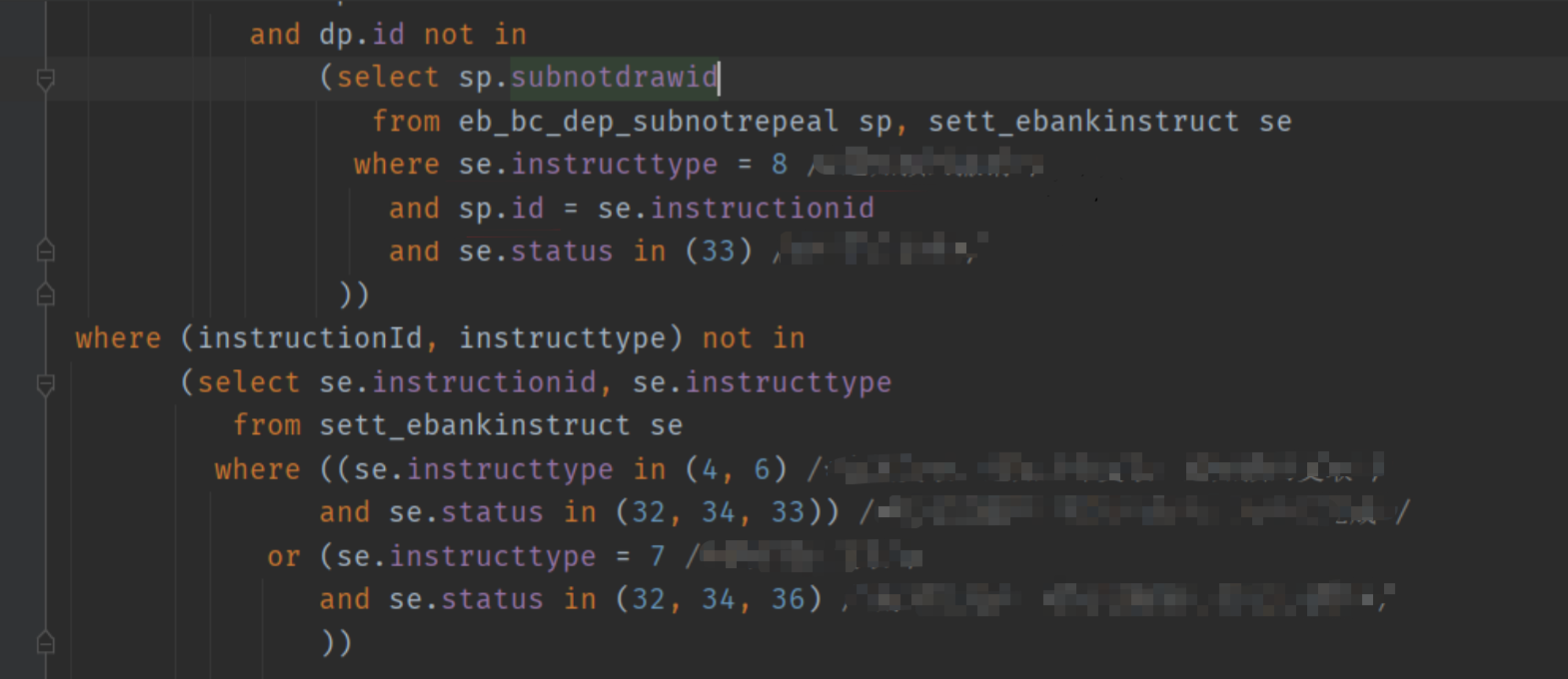
查一下 sett_ebankinstruct 这个表的数量 有近十万条,看了一下表的定义,一个索引都没加。。。
在此次 SQL 中,使用sett_ebankinstruct的字段只有 instructionid 和 instructtype。
instructionid : 很有可能会作为关联条件去连接多个表,并且该字段不会频繁的update,故在该字段上加索引。
如何加索引呢?
create index 索引名称
on 表名 (字段);
在此处加索引的 SQL 为:
create index IDX_SETT_EBANKINSTRUCT_INSTRID
on SETT_EBANKINSTRUCT (INSTRUCTIONID);
instructtype : 考虑到 instructtype 只是类型,并且使用的情况可能就是 = 或者in (具体的几个值),于是就不用加。
我们添加索引之后发现,第一个Full Scan 全表扫描已经消失😌,因为在 sp.id = se.instructionid 进行表连接的时候走了索引,但是第二个Full Scan全表扫描仍然存在,说明此处并未走索引😔 :
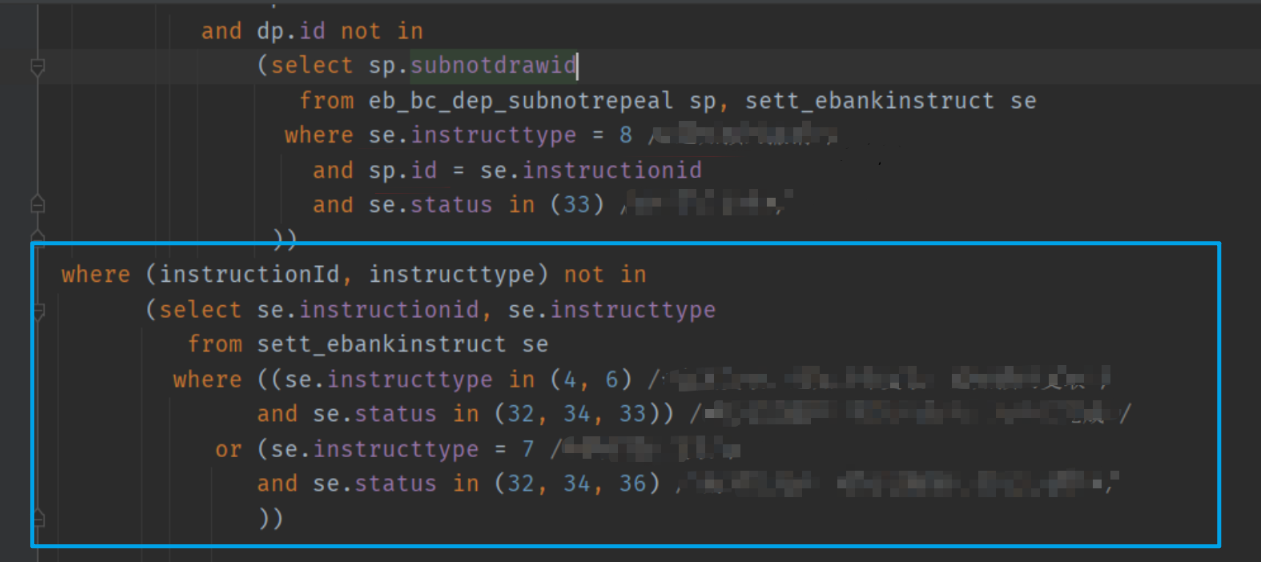
原因是此处使用 not in ,括号里的instructionId并未走内部子查询的索引,那么怎么改成走索引呢?将其改写成 not exists 即可。
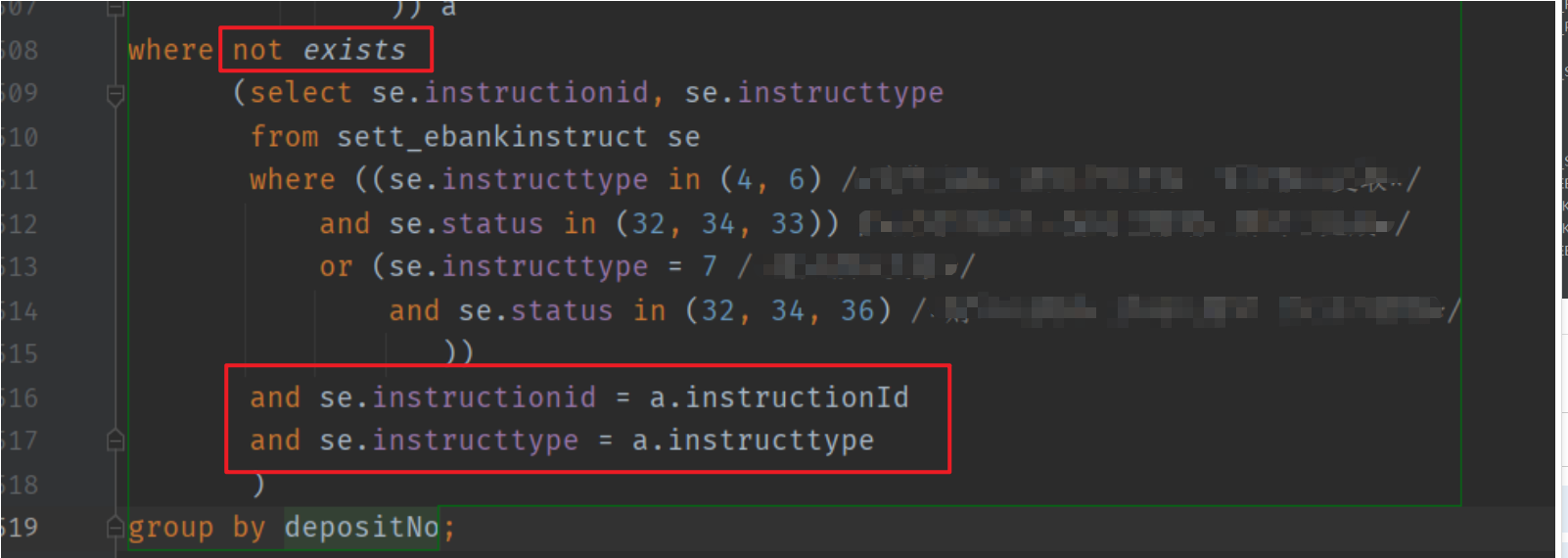
再次查看下执行计划,发现两个全表扫描都消失了,都变成了索引扫描(Index Scan)😆😆😆:
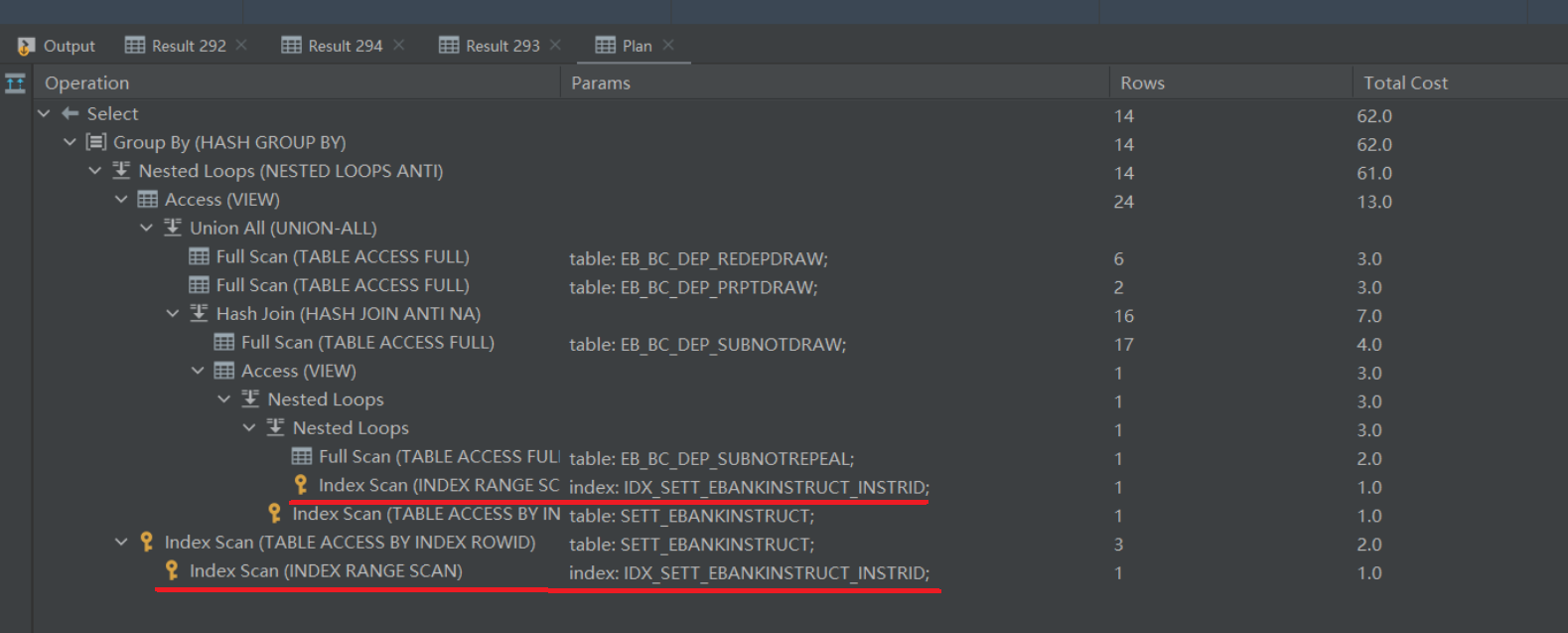
对比优化前后Total Cost:
优化前:779
优化后:62
优化提升:92%
3. 结论
如果排查确实是 SQL 问题,就直接看 执行计划 ,重点关注占用Total Cost的部分,然后查看对应的 SQL 。
- 如果是表频繁连接的字段,就要考虑加索引了。
not in改not exists,(业界流传not exists比not in快)
其实非也,如果主查询和子查询表大小相当,那么用in和exists差别不大。
如果子查询表大,用exists快,如果子查询表小,用in快。Where:数据量多的情况下,排除越多记录的条件应该是先执行。
Oracle下能排除掉多的条件放后面,因为Oracle的where是从右往左执行的,格式化 SQL 后也就是从下往上执行,这样写那么会先排除大量的数据,因而加快后续操作的速度。
MySQL正好和Oracle相反,MySQL下的Where是从左往右执行的,格式化 SQL 之后也就是从上往下执行,
因而MySQL下Where的条件应该是排除多的条件放前面。
__EOF__
