-
MEF:分层注意模块:协作细化模块
Attention-guided Global-local Adversarial Learning for Detail-preserving Multi-exposure Image Fusion
(注意引导的全局-局部对抗性学习,用于保留细节的多曝光图像融合)
我们提出了一种注意力引导的全局-局部对抗性学习网络,用于以粗到细的方式融合极端曝光图像。首先,在注意力权重图的指导下生成粗略的融合结果,从双方获得感兴趣的基本区域。其次,我们制定了边缘损失函数以及空间特征变换层,以完善融合过程。这样它就可以充分利用边缘信息来处理模糊的边缘。此外,通过结合全局-局部学习,我们的方法可以平衡像素强度分布,并从图像/补丁两个角度校正空间变化的源图像上的颜色失真。这样的全局-局部鉴别器可确保融合图像的所有局部补丁与真实的正常曝光图像对齐。在两个公开可用的数据集上的广泛实验结果表明,我们的方法在视觉检查和客观分析方面大大优于最新方法。此外,充分的消融实验证明,我们的方法在产生具有吸引人的细节,清晰的目标和忠实的颜色的高质量融合结果方面具有显着优势。介绍
多曝光融合 (MEF) 方法引起了极大的关注。MEF的目标是在不同的曝光下集成一系列LDR图像,然后将它们融合到HDR图像中。根据所需的LDR图像数量,MEF方法大致可分为两类,即非极限曝光融合(non-extreme exposure fusion)和极限曝光融合(extreme exposure fusion)。非极限曝光融合,融合性能取决于输入LDR图像的数量。然而,这些大量的LDR图像无疑增加了存储量,并对计算效率构成威胁。极限曝光融合,仅需要一对极端曝光图像。我们的工作也属于极端融合的范畴。
最近,受到先进的深度神经网络 (DNN) 在大量自然语言处理和计算机视觉任务 (例如,对象检测,图像恢复和深度估计中的成功启发),一些研究人员着手设计合适的DNN,以实现MEF并实现最先进的性能 。然而,这些基于DNN的MEF方法仍然存在一些局限性 : i) 这些方法在融合过程中采用简单的融合规则 (例如,权重平均,加法和串联) 来合并特征,使得融合的图像通常在精细结构或清晰目标方面存在缺陷。(ii) 在设计神经网络的过程中,现有的基于DNN的方法不太关注隐式细节。因此,融合的结果无法恢复真实的纹理细节,尤其是在极暗或明亮的区域。(iii) 现有的基于DNN的方法从整个图像角度提取深层特征,而忽略了跨不同补丁的局部信息。局部特征信息很难被充分利用,因此这些方法不能在空间变化的光条件下很好地执行,从而导致对其结果产生伪像。
CNN、RNN、DNN
在这项工作中,我们通过提出一个以注意力为导向的全局-局部对抗学习网络来解决上述挑战,以端到端的方式实现MEF任务。在我们的方法中,给定两个LDR源图像,通过分层注意和协作细化模块生成融合图像。全局-局部鉴别器旨在评估输出图像是否与图像级别和补丁级别的地面真相没有区别。这些新设计的模块可以以细粒度的方式提供高质量的HDR图像。此外,通过在相应的网络中集成边缘损失函数和空间特征变换层,可以恢复更多的纹理细节以满足高级目标。贡献
1)设计了用于特征合并的分层注意引导模块,该模块克服了简单设计的融合规则的局限性。与以前直接堆叠图像或特征的方法相比,我们的方法可以在黑暗和明亮区域捕获最重要的信息,从而显着提高了融合性能。
2)我们制定了边缘损失函数,并在网络中集成了空间特征变换层,该层使用增强的边缘信息去缓解模糊边缘伪影,并提供具有更逼真纹理细节的更好融合图像。
3)全局-局部鉴别器用于空间变化的光条件。它可以在图像和补丁透视图中区分融合图像与地面真相,因此可以显着改善颜色表示并减轻其他剩余的伪影,例如像素强度不平衡和目标模糊。
相关工作
传统框架:略
End-to-end Models
深度学习技术在处理各种计算机视觉任务方面取得了巨大的成功。Prabhakar等人首先将深度学习引入多曝光图像融合任务。通过使用MEF-SSIM作为训练损失函数并设计新颖的网络体系结构,该方法可以实现有希望的融合结果。为了去除伪影,Chen等人提出了一种基于单应性估计和注意力学习的融合方法。单应性网络允许该方法去除运动模糊引起的光晕,而注意力学习具有融合深度显着特征的能力。除此之外,Yin等人使用deep prior来指导融合过程,从而同时确保了语义一致性和纹理细节。Zhang等人设计了一种基于强度和梯度的比例保持的柔性无监督损失函数。在其损失函数中设置超参数可以有效地处理不同类型的图像融合。最近,Xu等人引入了一个统一的融合框架,该框架能够以端到端的方式处理不同的图像融合任务。为了进一步提高MEF融合性能,Xu等人首先将生成对抗网络 (GANs) 应用于MEF领域,实现了出色的融合性能。此外,他们在所提出的体系结构中引入了一种自我注意机制,该机制进一步确保了可以在融合结果上纠正不良伪影。Deng等人提出了一种耦合反馈网络,用于同时实现MEF任务和超分辨率任务。拟议的协作和交互网络可以产生高分辨率的融合结果。
Attention Mechanism in Deep Learning
作为一种新兴技术,注意力机制已广泛应用于自然语言处理和计算机视觉领域。注意机制由人类生物视觉感知系统解释,该系统允许人类捕获ROI (感兴趣区域) 信息,并容易忽略其他不重要的信息。此后,各种注意力机制无疑为提高不同计算机视觉任务的性能做出了贡献,例如,图像恢复和图像增强,显着目标检测,语义分割等。最近,为了利用注意机制进行图像去噪,Tian等人设计了一个具有四个设计块 (例如,一个稀疏块和一个增强块) 的注意引导网络,该网络取得了显著的性能。一些研究人员引入了边缘/目标引导的注意机制来追求视觉愉悦的实验结果。Zhang等人提出了一种基于边缘注意力引导编码器网络的精确实现医学图像分割任务的新方法。Liu等人介绍了一种新颖的边缘注意引导网络,用于融合红外和可见光图像,该网络可以全面提取多尺度特征,并在融合过程中更加关注纹理细节。最近,Lv等人提出了一种基于多分支网络的注意力引导方法,以端到端的方式增强弱光图像。
方法
我们所提出的方法是通过用于特征聚合的分层注意模块和用于细节保存和亮度校正的协作细化模块来完成的,此外还通过全局-局部判别器来确保全局和局部特征与现实的地面真相更加相似。详细的工作流程如图2所示。
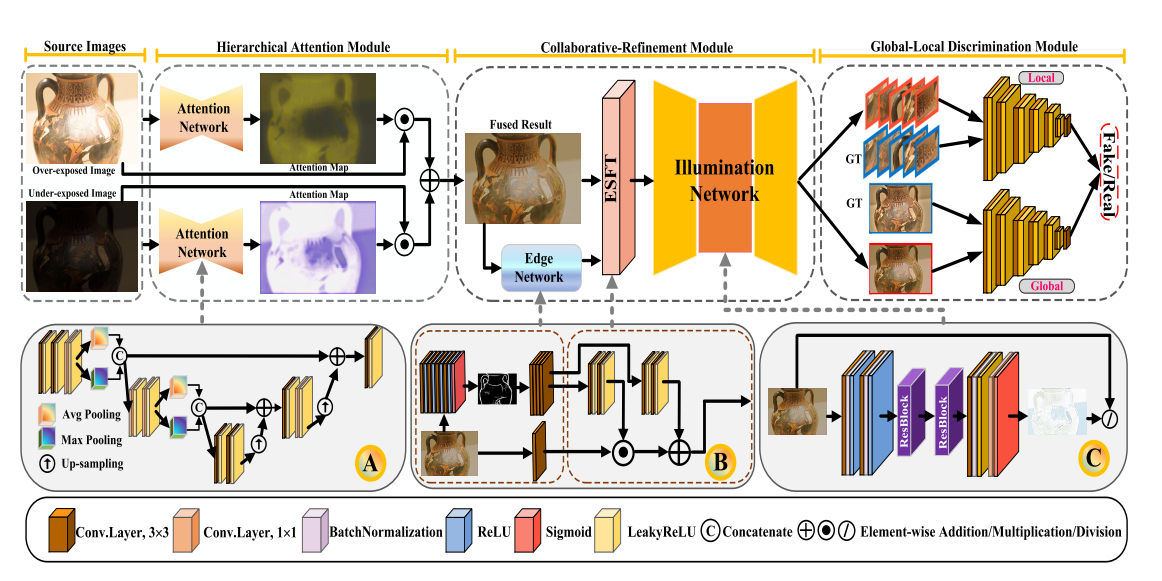
Hierarchical Attention Module
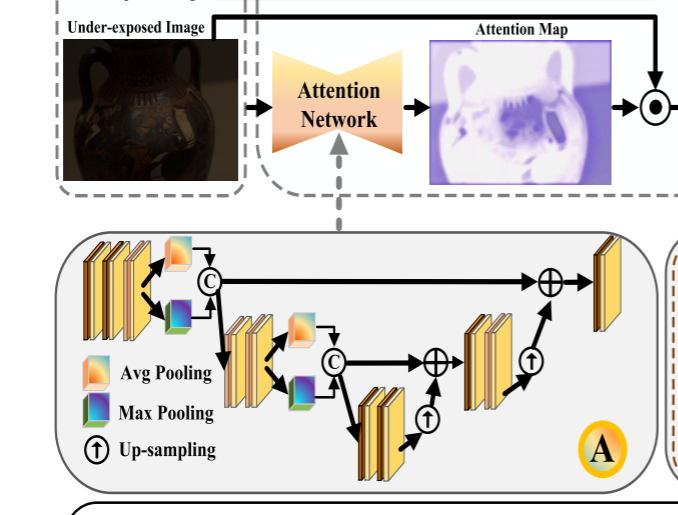
分层注意模块的目标是提供两个注意权重图,指导合并过程以生成视觉效果不错的图像。与以前直接连接特征以进行融合的方法不同,分层注意模块可以从源曝光过/曝光不足的图像中选择最显着的信息。因此,生成的融合图像具有完整的信息,并且噪声干扰或重影光晕更少。
给定具有3个通道的不同曝光设置的两个源LDR图像 (I1,I2),即,曝光过度的图像和曝光不足的图像。分层注意模块有助于提供两个注意权重图,它们引导I1,I2生成具有互补和完整信息的中间融合结果IA。所以,特征融合可以定义为:

A(·) 的详细架构显示在图2 (A部分) 的左侧部分。具体而言,分层注意模块首先通过卷积层将源图像传输到特征表示。然后,我们利用平均池和最大池特征来全面获取信息。经过三次下/上采样操作,分层注意模块可以完全拥有高/低级特征。结果,生成两个特征序列并将其串联在一起以增强特征表示。此外,为了补偿在最后一个卷积层的上采样操作期间丢失的特征,我们采用了来自相应卷积层的两个跳过连接。每个生成的注意力权重图都有三个通道,其值在范围内 [0,1]。此后,这些注意图引导融合这些中间特征以提供视觉愉悦的图像,该图像具有来自曝光过度/曝光不足的图像的补充信息。
Collaborative-Refinement Module
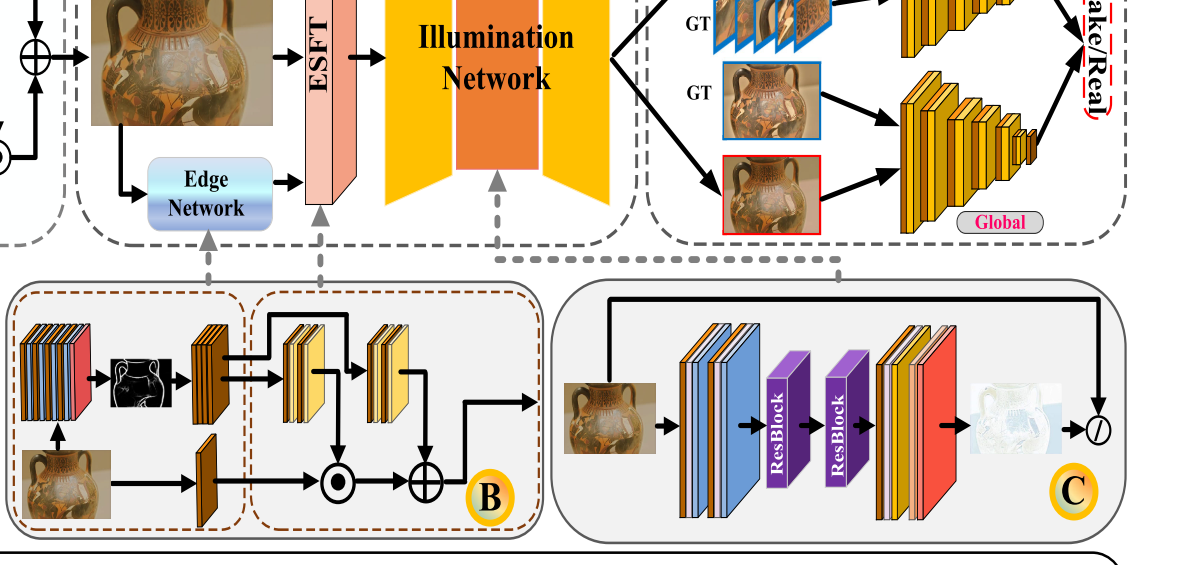
我们引入了一个协同细化模块,用于增强边缘细节并同时校正颜色失真。协同细化模块由边缘增强网络和亮度网络组成,有助于改善视觉效果。两个子网的详细架构如图2(B&C)所示
空间特征转换网络及其在超分辨中的应用
首先,边缘增强网络通过用拉普拉斯算子卷积参考地面真相来生成增强的边缘图。这些边缘图和融合的结果被串联以馈送到边缘空间特征变换 (ESFT) 层。此外,受Retinex理论的启发,我们提出了一个亮度网络来准确估计照明变化。来自分层注意模块的融合图像被馈送到四层CNN中,以生成边缘增强的地图。每个卷积层由归一化和ReLU激活函数组成,该函数具有应用的3 × 3 × 64特征。然后将边缘增强的地图和融合的图像串联到ESFT层中,以进一步关注真实的边缘信息。设计了一个ESFT层来学习映射函数⊗,该映射函数提供了基于先验条件 Φ 的调制参数对 (γ,β)。学习到的参数可以通过对边缘增强网络下的每个中间特征图的仿射变换来快速适应建立与融合图像的相关性。
具体地,参数对 (γ,β) 由先验条件 Φ 根据映射函数 Ω 提供: Φ → (γ,β)。结果:
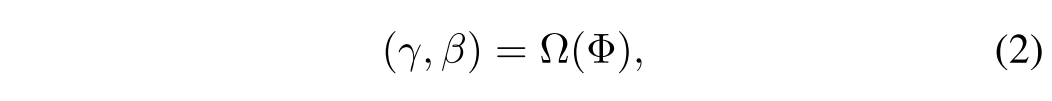
之后,我们可以从条件中获取 (γ,β),并且通过移动图层的特征图来执行转换:

其次,受Retinex理论的启发,引入了亮度网络来进一步校正颜色失真。根据该理论,假设在每个通道中执行照度估计,则反射率图可能包含源图像的原始颜色信息。为此,我们构建了亮度网络来实现颜色校正的过程,该过程由卷积层和两个重块组成。请注意,卷积层的内核大小为3 × 3。前两个卷积层设置为32。通过具有s形激活的两个ResBlocks获得细化的融合图像IR,它可以表述为:

Global-Local Discrimination Module
受先前方法的启发,我们在方法的最后介绍了一种基于PatchGAN的快速了解的全局-局部鉴别器,以平衡像素强度分布并同时克服小区域中丢失的细节。作为图像级鉴别器的补充,设计了局部鉴别器,以从补丁区域的角度克服上述问题。局部鉴别器从融合的图像和地面真相中随机裁剪局部补丁,并学会区分真实 (与地面真相) 或假 (与融合的图像)。因此,新添加的局部鉴别器可确保所有补丁都更符合地面事实,甚至减轻了残留的伪影,例如在小区域中过度/曝光不足。
全局和局部鉴别器具有丢弃最后sigmoid层的相同结构。每个判别模块有六个块,每个块由卷积层和ReLU激活层组成。卷积层的滤波器数目分别为64、128、256和512。
Loss function
我们的生成器的损失函数由三个部分组成,即内容损失LC,感知Lper损失和对抗损失LG:
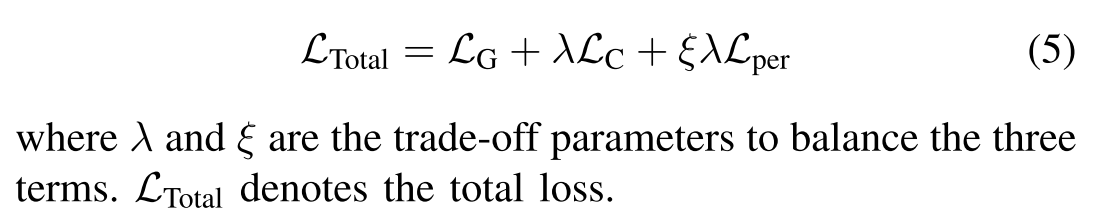
内容损失的目标是生成具有与地面真相相似的像素强度分布的图像。因此,我们期望通过最小化生成的输出IR和地面真相IGT之间的l2-norm来训练网络,这可以描述如下:

感知损失有助于测量特征域中的差异,例如VGG网络Φ 。我们将感知损失定义为:
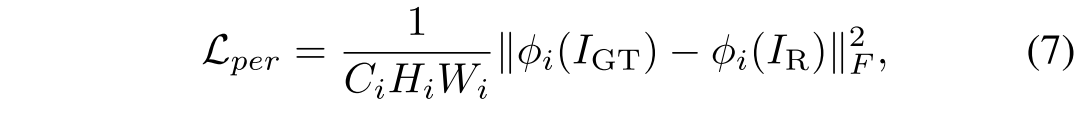
其中高度和宽度表示为H和W。C是通道号,i表示层索引。我设置为4。
此外,我们稍微修改了全局-局部鉴别器,该鉴别器采用最小二乘GAN损耗来代替sigmoid函数。因此,损失函数LG定义为:
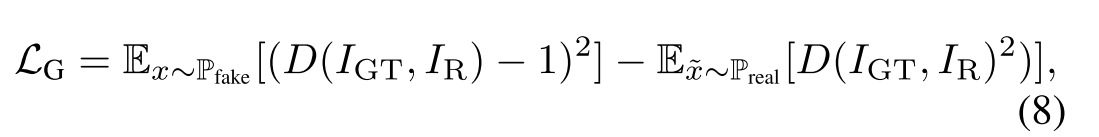
除了生成器之外,我们还使用全局-局部鉴别器来强制融合的结果,以分别从图像和补丁角度保留更多信息。因此,判别损失有两个部分。对于局部鉴别器,我们同时在融合图像和地面真相中选择相同的补丁。基于LSGAN的损失函数可以表示为: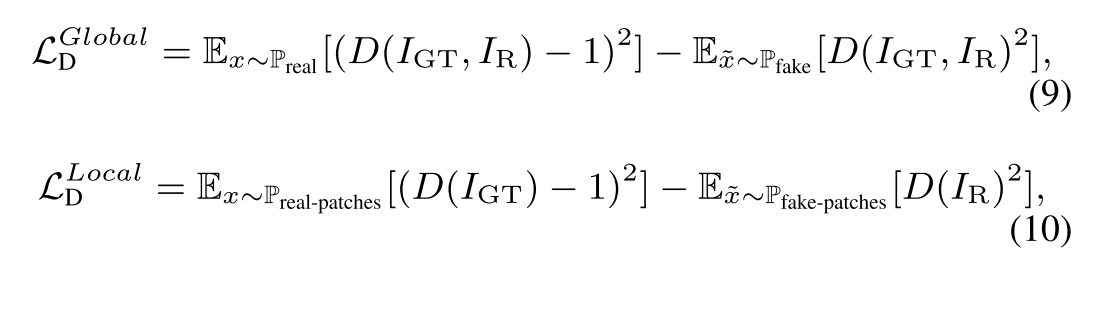
-
相关阅读:
面向对象设计模式之工厂方法模式
妹子天天要换新头像?没问题,通过爬虫爬取精美头像
使用Avalonia UI 的 MVVM 框架在ViewModel里使用ShowDialog报错
【AI】实现在本地Mac,Windows和Mobile上运行Llama2模型
Sora:视频生成模型作为世界模拟器
Windows安装cuda和cudnn教程最新版(2023年9月)
基于聚类算法的IMT-2030应用场景初步研究
人工智能 | ShowMeAI资讯日报 #2022.06.23
Git分支管理流程
TypeScript核心
- 原文地址:https://blog.csdn.net/weixin_43690932/article/details/127969665