-
数据聚合——DSL&RestAPI
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。
1.1.聚合的种类
聚合常见的有三类:
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
1.2.DSL实现聚合
1.2.1.Bucket聚合语法(桶聚合)
相当于mysql中的分组
语法如下:
- # 聚合 - 桶聚合(bucket)- terms(分组汇总)
- GET /hotel/_search
- {
- "size": 0, // 设置size为0,结果中不包含文档详情,只包含聚合结果
- "aggs": { // 定义聚合,固定写法
- "brandAgg": { //给聚合起个名字
- "terms": { // 聚合的类型,按照品牌值聚合,所以选择terms
- "field": "brand", // 指定以哪个字段进行分组汇总
- "size": 20 // 希望获取的聚合结果数量
- }
- }
- }
- }
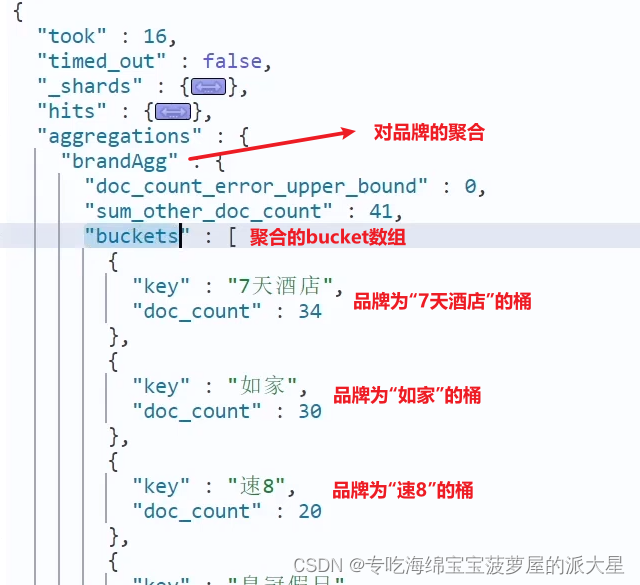
1.2.2.聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为count,并且按照count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
- GET /hotel/_search
- {
- "size": 0,
- "aggs": {
- "brandAgg": {
- "terms": {
- "field": "brand",
- "order": {
- "_count": "asc" // 按照_count升序排列
- },
- "size": 20
- }
- }
- }
- }
1.2.3.限定聚合范围
- # 聚合 - 桶聚合(bucket)- terms(分组汇总)
- # 限定数据范围
- # 在聚合之前先按照条件过滤一次
- GET /hotel/_search
- {
- "query": {
- "term": {
- "city": {
- "value": "北京"
- }
- }
- },
- "size": 0,
- "aggs": {
- "brandAgg": {
- "terms": {
- "field": "brand",
- "size": 50
- }
- }
- }
- }
1.2.4.Metric聚合语法(度量聚合)
用以计算一些值,比如:最大值、最小值、平均值等
语法如下:
- # 聚合 - 度量聚合(metric)
- # 计算最大值,最小值
- # stats 表示要计算数值
- # field 按照哪个字段进行聚合
- GET /hotel/_search
- {
- "size": 0,
- "aggs": {
- "scoreAgg": {
- "stats": {
- "field": "score"
- }
- }
- }
- }

不过,一般度量聚合与桶聚合一起使用
- # 聚合 - 度量聚合(metric)
- # 与桶聚合进行嵌套使用
- # 先按照酒店品牌分组
- # "size": 0 表示不显示文档详情
- # "size": 50 显示的数量
- # 在分组的基础上再计算总数和最值
- GET /hotel/_search
- {
- "size": 0,
- "aggs": {
- "brandAgg": {
- "terms": {
- "field": "brand",
- "size": 50
- },
- "aggs": {
- "scoreAgg": {
- "stats": {
- "field": "score"
- }
- }
- }
- }
- }
- }

1.3.RestAPI实现聚合
请求

聚合结果解析
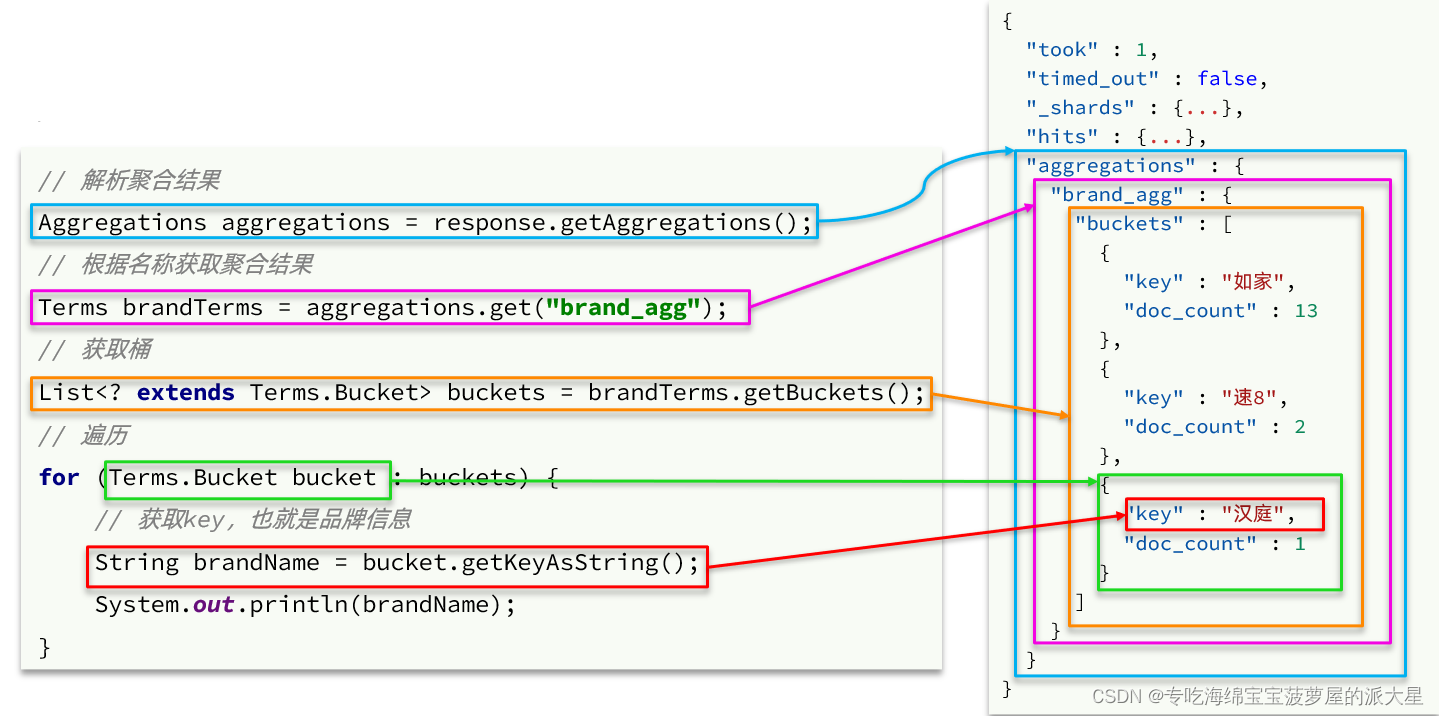
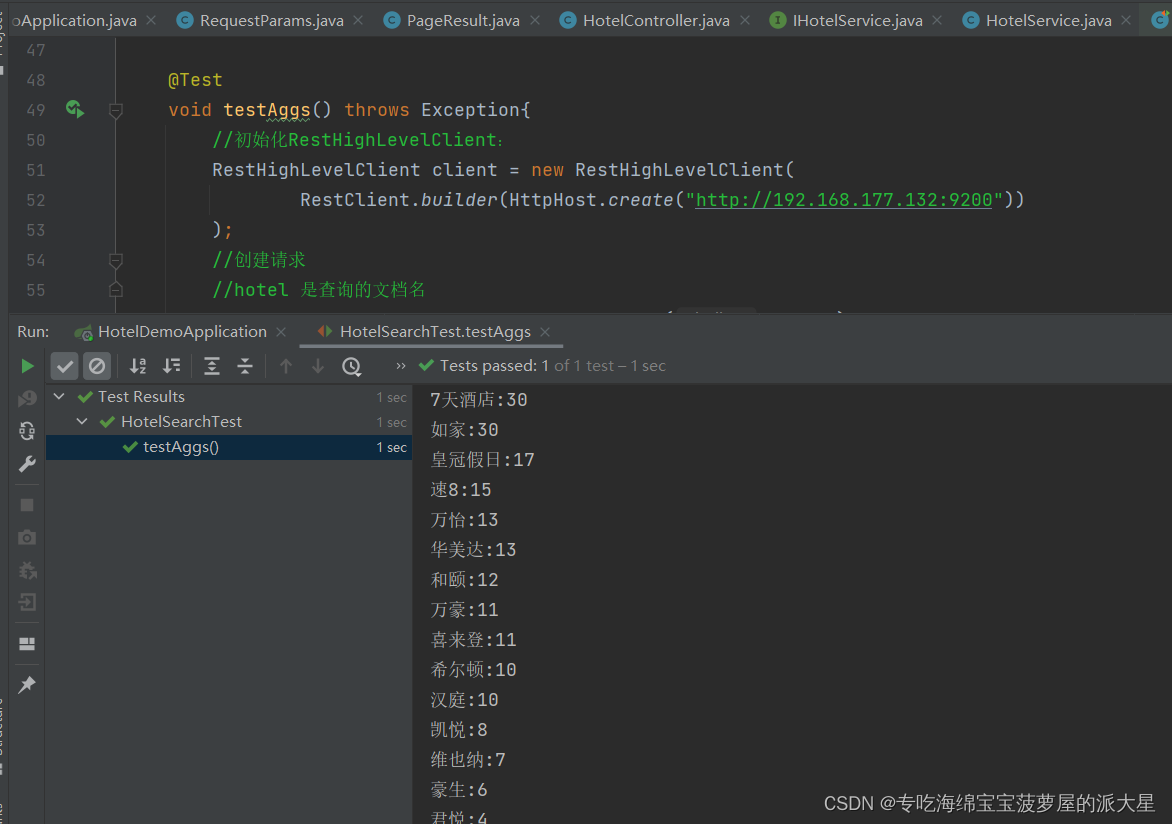
代码实现:
- @Test
- void testAggs() throws Exception{
- //初始化RestHighLevelClient:
- RestHighLevelClient client = new RestHighLevelClient(
- RestClient.builder(HttpHost.create("http://192.168.177.132:9200"))
- );
- //创建请求
- //hotel 是查询的文档名
- SearchRequest request = new SearchRequest("hotel");
- //设置参数
- //AggregationBuilders 工具类
- //terms 桶聚合--分组汇总,聚合的类型,按照品牌值聚合
- //field 按照哪个字段分组
- //size(50) 显示的数量
- request.source().size(0);//不在结果中包含文档详情
- request.source().aggregation(
- AggregationBuilders.terms("brandAgg").field("brand").size(50)
- );
- //执行请求
- //第一个参数:创建的请求,第二个参数:是否还有其他的选项,一般选DEFAULT
- SearchResponse response = client.search(request, RequestOptions.DEFAULT);
- //解析响应
- Aggregations aggregations = response.getAggregations();
- Terms brandAgg = aggregations.get("brandAgg");
- Listextends Terms.Bucket> buckets = brandAgg.getBuckets();
- for (Terms.Bucket bucket : buckets) {
- String key = bucket.getKeyAsString();
- long count = bucket.getDocCount();
- System.out.println(key + ":" + count);
- }
- }
-
相关阅读:
wordpress实时在线聊天室
Android事件分发机制
(BGV12)方案初学
基于Python实现制作的接金币小游戏
IP地址定位的特点
【LeetCode刷题-双指针】--16.最接近的三数之和
[架构之路-239]:目标系统 - 纵向分层 - 中间件middleware
Maven:命令行
【web-攻击数据存储区】(6.2)SQL注入
网络编程
- 原文地址:https://blog.csdn.net/LINING_GG/article/details/128210653
