-
python数据容器
一、list列表
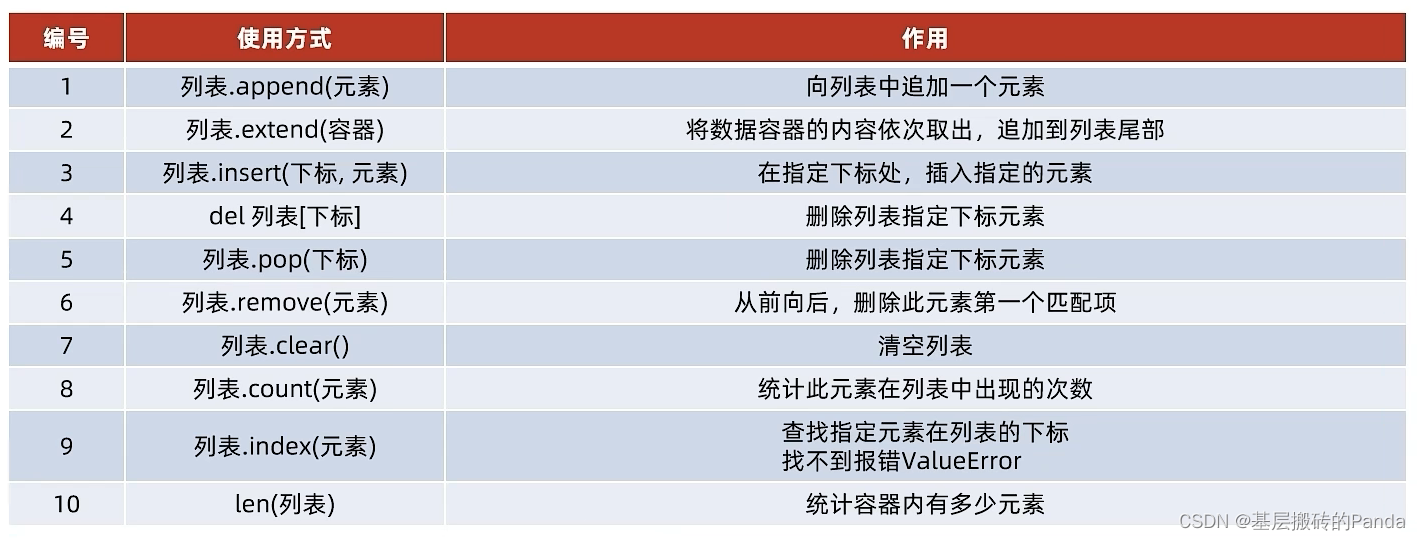
亮点:python中的list可以存储不同类型的元素
# list_demo.py # 数据列表的定义 及 下标获取指定元素 name_list = ["c++", "java", "python", "java"] print(name_list) print(name_list[0]) print(name_list[1]) print(name_list[2]) print(type(name_list)) person = ["lwang", 20, "beijing"] print(person) print(person[0]) print(person[1]) print(person[2]) print(type(person)) array = [[1,2,3],[4,5,6]] print(array) print(array[0]) print(array[0][0]) print(array[0][1]) print(array[0][2]) print(array[1]) print(array[1][0]) print(array[1][1]) print(array[1][2]) print(type(array)) # list提供的方法 # 查找指定元素的下标 index = name_list.index("c++") print("c++ idex: %d" % index) # 修改指定下标的元素 name_list[1] = "c#" print("name_list[1]: %s" % name_list[1]) print(name_list) # 在指定下标的位置插入元素 name_list.insert(1, "java") print(name_list) # 元素追加到一个元素到list末尾 name_list.append("php") print(name_list) # 元素追加整个容器的数据 lsit2 = [1,3,5] name_list.extend(lsit2) #python中的list可以存储不同类型的元素 print(name_list) # 删除元素语法 1. del list[index] 2. list.pop(index) pop方法 del name_list[0] print(name_list) element = name_list.pop(1) # 从list中pop出该元素,可以通过返回值接收弹出的元素 print(f"element = {element}") print(name_list) # remove 删除list中第一个匹配的元素 name_list.remove("java") print(name_list) name_list.append("java") print("name_list 中java的个数为:%d" % name_list.count("java")) print("name_list 中总共元素的个数为:%d" % len(name_list)) # name_list.clear() # print(name_list) # list 的遍历 print("==================== name_list 的遍历 ========================") def list_check_v1(): index = 0 for x in name_list: print(f"当前的元素为:{x}") list_check_v1() print("==================== 分割线 ========================") def list_check_v2(): index = 0 while index < len(name_list): element = name_list.pop() print(f"当前的元素为:{element}") list_check_v2()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
二、元组tuple
元组中的元素不允许被修改

# tuple 元组 t1 = ("lwang", 20, "beijing") print(t1[0]) # 支持下标获取元素 # t1[0] = "panda" # 元组中的元素不允许被修改 print(t1) t2 = () t3 = tuple(); #元组中的元素可以是list t4 = ("c++", "java", "python", [1, 3, 5]) print(t4) t4[3][0] = 0 # 修改的是元组中的列表元素 print(t4) print("c++在t4中的index为:%d" % t4.index("c++")) idx = 0 while idx < len(t4): print(f"elemetn {t4[idx]}") idx += 1 print("=========== 分割线 ===========") for item in t4: print(f"item {item}")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
三、字符串string
同元组一样,也是不可修改的数据容器。
3.1 通过下标访问
3.2 index
语法:index = str.index(字符或者字符串),查找指定字符或者字符串在str中的起始位置
3.1 replace
字符串替换,语法:newstr = str.replace(str1, str2) 表示,将str中的str1全部替换为str2,不是修改str本身,而是生成了新的字符串,通过返回值接收。
3.4 split
字符串分割,存入到列表对象。语法:list = str.split(分割标识)。str本身不变,会得到一个列表对象,通过返回值接收。
3.4 strip
去掉字符串前后的指定字符。new_str = str.strip(字符或者字符串) 参数默认为 “空格”
3.5 count
获取指定字符串在原始字符串中出现的次数。
3.5 len
获取字符串的长度。
str = ("hello world i am panda") print(str) print(str[0]) # str[0] = "H" # 不允许修改 print("am 的idx 是%d " % str.index("am")) new_str = str.replace("o", "O") print(new_str) res_list = str.split(" ") print(res_list) str2 = (" here is strip test ") str3 = ("122121212here is strip test122121212") new_str2 = str2.strip() print(new_str2) new_str3 = str3.strip("12") print(new_str3) cnt = str.count("l") print(f"l 在str中出现的次数为:{cnt}") print(f"str的长度为:{len(str)}")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
三、数据容器(序列)的切片
实际上就是从原始序列中按照指定的步长取子序列。可以从左往右取,也可以从右往左取。
# 切片 # 语法:序列[start:end:step],表示从start位置开始没间隔step选取一个元素,不包含end位置的元素,返回新的序列 # step 可以为负数,表示从右往左取元素,默认step为1 name_list = ["c++", "java", 1, 2, 3, 4] new_list = name_list[1:4] print(new_list) new_list = name_list[-1:-4:-1] print(new_list) t1 = ("one", "two", "three", "four", "five", ["six", "seven", "eight", "nine"]) print(t1) t2 = t1[0:5:2] print(t2) str = "1234567891011" print(str) new_str = str[::1] print(new_str) new_str = str[::3] print(new_str) new_str = str[::] # 起始可以不写,表示从头到尾,默认step为1 print(new_str) new_str = str[::-1] # 起始可以不写,表示从头到尾,step为-1,表示从尾到头取,步长为1 print(new_str)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
三、集合set
不允许重复,乱序。
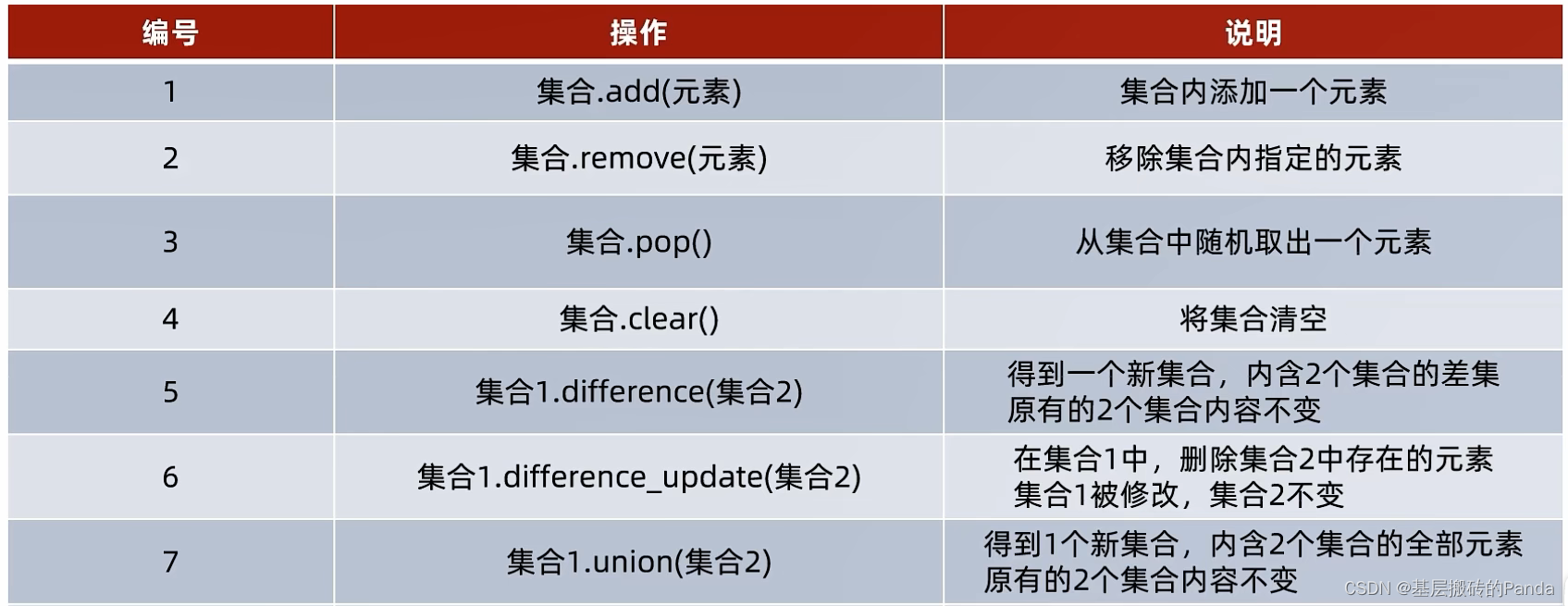
# 集合 set # 乱序,不重复 my_set = {"c++", "java", "c++", "python"} print(my_set) print(f"my_set的类型是:{type(my_set)}") # 1.添加元素 my_set.add(1) print(my_set) # 2.移除指定元素 my_set.remove(1) print(my_set) # 3.随机弹出一个元素,集合本身元素减1 element = my_set.pop() print(element) print(my_set) # 4.清空集合 # my_set.clear() # print(my_set) # 5.求差集 # 语法:s1.difference(s2) 意思是,s1集合有s2没有的元素 s1 = {1, 2, 3, 4, 5} s2 = {4, 5, 7, 8, 9} # s3 = s1.difference(s2) # print(f"集合s1 和 s2 的差集为:{s3}") # # s3 = s2.difference(s1) # print(f"集合s2 和 s1 的差集为:{s3}") # 6.消除两个集合的差集,语法:s1.difference_update(s2) # 功能: 删除集合s1中和s2相同的元素,s1发生变化,s2不变,查看s1 s1.difference_update(s2) print(f"集合s1消除 和 s2 的差集后为:{s1}") # 7.求并集 s3 = s1.union(s2) print(s3) # 8.统计集合元素的个数 count = len(s3) print("合并后的s3的元素个数是:%d 个" % count) # 9.集合的遍历 for item in s3: print(item)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
四、字典dict
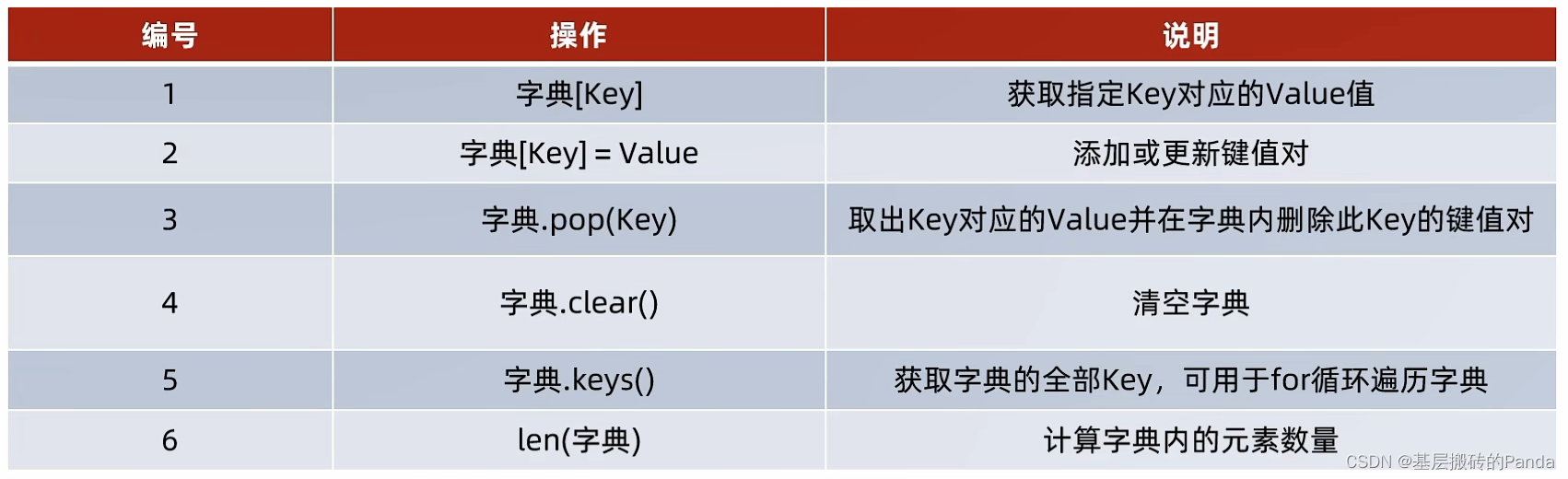
# 字典 dict # 语法: {k1:v1, k2:v2, ... , kn:vn} # 1.定义 # 不允许重复的key,如果出现了重复的key,新值会覆盖掉旧值 my_dict = {"lwang":100, "panda":90, "jazz":80, "lwang":70} print(my_dict) print(my_dict["lwang"]) print(my_dict["panda"]) print(my_dict["jazz"]) # 2.字典嵌套 person_info = { "lwang":{"age":20, "addr":"beijing"}, "lyz":{"age":18, "addr":"beijing"}, "darren":{"age":30, "addr":"changsha"}, } print(person_info) print("lyz's age = %d " % person_info["lyz"]["age"]) # 3.添加元素 my_dict["lyz"] = 100 print(my_dict) # 4.修改指定元素 my_dict["lwang"] = 149 print(my_dict) # 5.删除元素 score = my_dict.pop("lwang") print(score) print(my_dict) # # 6.清空字典 # my_dict.clear() # print(my_dict) # 7.获取全部的key keys = my_dict.keys() print(keys) # 8.遍历 for key in keys: print(f"key:value = {key}:{my_dict[key]}") # 9.字典元素的个数 num = len(my_dict) print("my_dict 元素的个数是:%d " % num)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
-
相关阅读:
k8s集群安装部署单机MySQL(使用StorageClass作为后端存储)
Codeforces 403D Beautiful Pairs of Numbers(组合数学DP)
目标检测算法改进系列之Backbone替换为NextViT
Spring Boot 配置静态资源路径
轻量封装WebGPU渲染系统示例<18>- 材质多pass实现GPU Compute计算(源码)
YOLOv5 加入SE注意力机制
Easy Touch 5 简单使用
【设计模式深度剖析】【2】【行为型】【命令模式】| 以打开文件按钮、宏命令、图形移动与撤销为例加深理解
阿里35+老测试员生涯回顾,自动化测试真的有这么吃香吗?
1.3.2有理数减法(第一课时)作业设计
- 原文地址:https://blog.csdn.net/weixin_46935110/article/details/128158598
