-
Machine Learning机器学习学习记录
Machine Learning机器学习
聚类
(1)K-Means
1.1 基本思路
k-均值(k-means )算法是一种划分聚类算法,其目标是将一个没有标签的数据集中的N个数据对象(实例) 划分为k个簇,使得每个簇内的数据对象具有高度的相似性,不同簇间的数据对象具有较大的差异性。
k-均值算法具有一个迭代过程,在这个过程中,数据集被分组成k个预定义的不重叠的簇,使簇的内部点尽可能相似,同时试图保持簇在不同的空间,它将数据点分配给簇,以便簇的质心和数据点之间的平方距离之和最小,在这个位置,簇的质心是簇中数据点的算术平均值。1.2 k均值算法流程
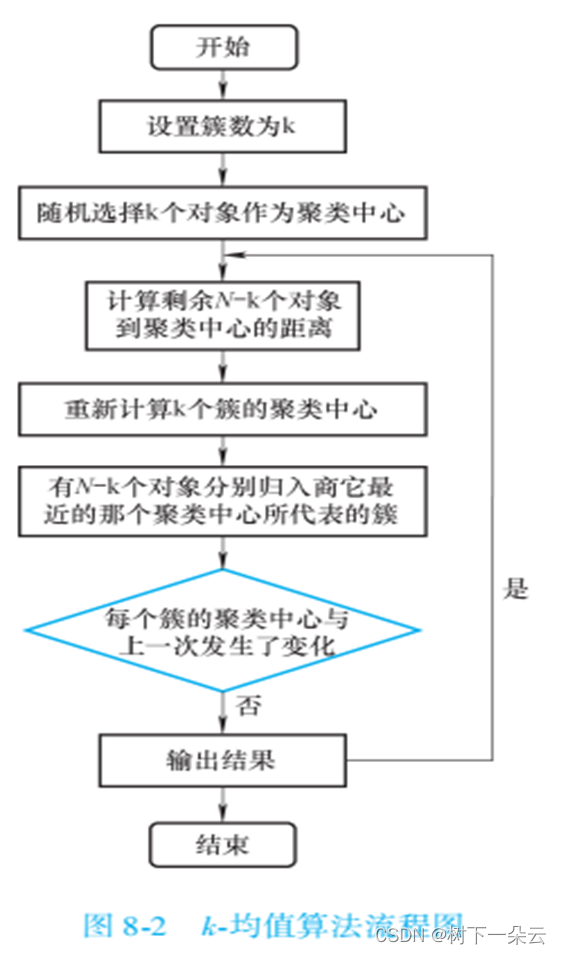

k均值算法的特点
k-均值算法的优点
- 原理比较简单,容易实现,收敛速度快,可解释性较好。
- 需要调节的参数较少(主要是聚类簇数 k ),且聚类效果较好。
k-均值算法的缺点
- 聚类簇数 k 值的选取不好把握,一般只能通过暴力搜索法来确定。
- 只适合簇型数据,对其他类型的数据聚类效果一般。
- 如果各隐含类别的数据不平衡,则聚类效果不佳。
- 采用迭代方法,得到的结果只是局部最优。
- 当数据量较大时,计算量也比较大,采用小批量 k-均值的方式虽然可以缓解,但可能会牺牲准确率。
- 对噪音和异常点比较的敏感。
簇内误差平方和
聚类算法聚出的类有什么含义呢?这些类有什么样的性质?我们认为,被分在同一个簇中的数据是有相似性的,而不同簇中的数据是不同的
追求簇内差异小,簇外差异大。而这个“差异“,由样本点到其所在簇的质心的距离来衡量。
对于一个簇来说,所有样本点到质心的距离之和越小,我们就认为这个簇中的样本越相似,簇内差异就越小。而距离的衡量方法有多种,令 表示簇中的一个样本点, 表示该簇中的质心,n表示每个样本点中的特征数目,i表示组成点 的每个特征,则该样本点到质心的距离可以由以下距离来度量:

如采用欧几里得距离,则一个簇中所有样本点到质心的距离的平方和为:

其中,m为一个簇中样本的个数,j是每个样本的编号。这个公式被称为簇内平方和(cluster Sum of Square),又叫做Inertia。而将一个数据集中的所有簇的簇内平方和相加,就得到了整体平方和(Total Cluster Sum of Square),又叫做total inertia。Total Inertia越小,代表着每个簇内样本越相似,聚类的效果就越好。因此KMeans追求的是,求解能够让Inertia最小化的质心。实际上,在质心不断变化不断迭代的过程中,总体平方和是越来越小的。我们可以使用数学来证明,当整体平方和最小的时候,质心就不再发生变化了。如此,K-Means的求解过程,就变成了一个最优化问题。Kmeans有损失函数吗?
在逻辑回归中曾有这样的结论:损失函数本质是用来衡量模型的拟合效果的,只有有着求解参数需求的算法,才会有损失函数。Kmeans不求解什么参数,它的模型本质也没有在拟合数据,而是在对数据进行一种探索。所以如果你去问大多数数据挖掘工程师,甚至是算法工程师,他们可能会告诉你说,K-Means不存在什么损失函数,Inertia更像是Kmeans的模型评估指标,而非损失函数。
但我们类比过了Kmeans中的Inertia和逻辑回归中的损失函数的功能,我们发现它们确实非常相似。所以,从“求解模型中的某种信息,用于后续模型的使用“这样的功能来看,我们可以认为Inertia是Kmeans中的损失函数,虽然这种说法并不严谨。
对比来看,在决策树中,我们有衡量分类效果的指标准确度accuracy,准确度所对应的损失叫做泛化误差,但我们不能通过最小化泛化误差来求解某个模型中需要的信息,我们只是希望模型的效果上表现出来的泛化误差很小。因此决策树,KNN等算法,是绝对没有损失函数的。KMeans算法的时间复杂度

1.3 K-Means算法的Python实现
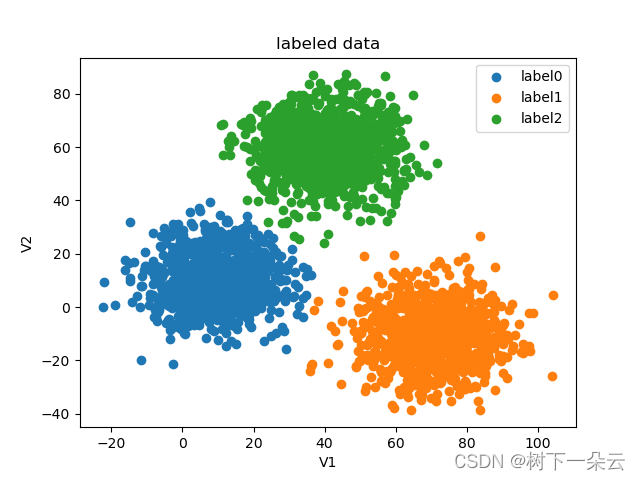
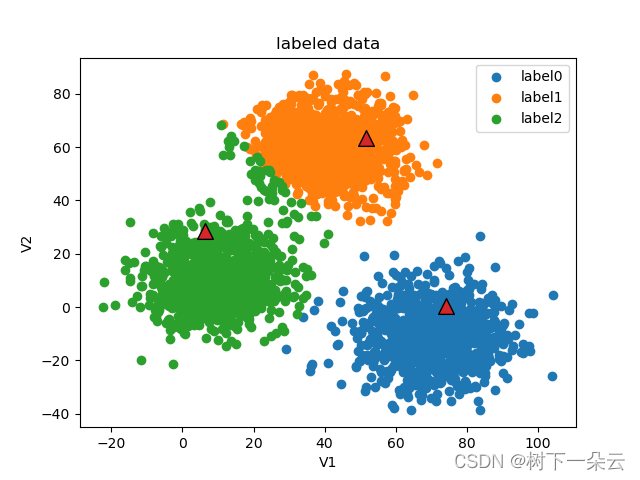
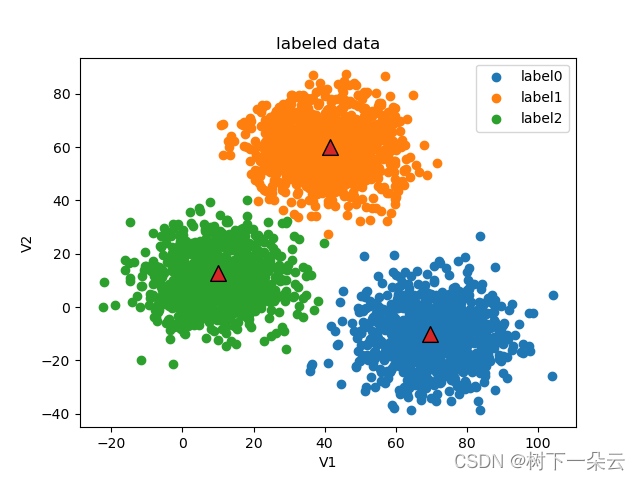
# -*- encoding : utf-8 -*- """ @project = sklearn_learning_01 @file = KMeans_Python @author = wly @create_time = 2022/12/7 21:52 KMeans算法的python实现 """ import pandas as pd import numpy as np import random import math from matplotlib import pyplot as plt class MyKmeans: def __init__(self, k, max_iter=10): self.k = k # 最大迭代次数 self.max_iter = max_iter # 训练集 self.data_set = None # 结果集 self.labels = None ''' 从训练集中随机选择k个点作为簇中心 ''' def init_centers(self): # 数据集包含数据个数 point_num = np.shape(self.data_set)[0] random_index = random.sample(list(range(point_num)), self.k) # print("point_num = ", point_num) # print("ransom_index = ", random_index) centers = [] for i in random_index: centers.append(self.data_set[i]) # print(centers) return centers ''' 计算两点间的欧拉距离 ''' def euler_distance(self, point1, point2): distance = 0.0 for a, b in zip(point1, point2): distance += math.pow(a - b, 2) return math.sqrt(distance) ''' 确定非中心点与哪个中心点最近 ''' def get_closest_index(self, point, centers): # 初始值设为最大 min_dist = math.inf label = -1 # enumerate() 函数同时列出数据和数据下标 for i, center in enumerate(centers): dist = self.euler_distance(center, point) if dist < min_dist: min_dist = dist label = i return label ''' 更新中心点 ''' def update_centers(self): # k类点分别存 points_label = [[] for i in range(self.k)] # print(np.array(points_label).shape) # print(points_label[0]) for i, label in enumerate(self.labels): points_label[label].append(self.data_set[i]) centers = [] for i in range(self.k): # print(np.array(points_label[i]).shape) centers.append(np.mean(points_label[i], axis=0)) return centers ''' 判断是否停止迭代,新中心点与旧中心点一致或者达到设置的迭代最大值则停止 ''' def stop_iter(self, old_centers, centers, step): if step > self.max_iter: return True return np.array_equal(old_centers, centers) ''' 模型训练 ''' def fit(self, data_set): self.data_set = data_set.drop(['labels'], axis=1) self.data_set = np.array(self.data_set) point_num = np.shape(data_set)[0] # 初始化结果集 self.labels = data_set.loc[:, 'labels'] self.labels = np.array(self.labels) # 初始化k个随机点 centers = self.init_centers() # 保存上一次迭代的中心点 old_centers = [] # 当前迭代次数 step = 0 flag = False while not flag: # 存储 旧的中心点 old_centers = np.copy(centers) # 迭代次数+1 step += 1 print("current iteration: ", step) print("current centers: ", old_centers) # 本次迭代 各个点所属类别(即该点与哪个中心点最近) for i, point in enumerate(self.data_set): self.labels[i] = self.get_closest_index(point, centers) # 更新中心点 centers = self.update_centers() # 迭代是否停止的标志 flag = self.stop_iter(old_centers, centers, step) centers = np.array(centers) fig = plt.figure() label0 = plt.scatter(self.data_set[:, 0][self.labels == 0], self.data_set[:, 1][self.labels == 0]) label1 = plt.scatter(self.data_set[:, 0][self.labels == 1], self.data_set[:, 1][self.labels == 1]) label2 = plt.scatter(self.data_set[:, 0][self.labels == 2], self.data_set[:, 1][self.labels == 2]) plt.scatter(old_centers[:, 0], old_centers[:, 1], marker='^', edgecolor='black', s=128) plt.title('labeled data') plt.xlabel('V1') plt.ylabel('V2') plt.legend((label0, label1, label2), ('label0', 'label1', 'label2')) plt.show() if __name__ == '__main__': # 按文件名读取整个文件 data = pd.read_csv('data.csv') # 展示前几行数据,通常为展示前5行 # print(data.head()) X = data.drop(['labels'], axis=1) y = data.loc[:, 'labels'] # print(type(X)) fig1 = plt.figure() plt.scatter(X.loc[:, 'V1'], X.loc[:, 'V2']) plt.title('un-labled data') plt.xlabel('V1') plt.ylabel('V2') plt.show() fig2 = plt.figure() label0 = plt.scatter(X.loc[:, 'V1'][y == 0], X.loc[:, 'V2'][y == 0]) label1 = plt.scatter(X.loc[:, 'V1'][y == 1], X.loc[:, 'V2'][y == 1]) label2 = plt.scatter(X.loc[:, 'V1'][y == 2], X.loc[:, 'V2'][y == 2]) plt.title('labeled data') plt.xlabel('V1') plt.ylabel('V2') plt.legend((label0, label1, label2), ('label0', 'label1', 'label2')) plt.show() myKmeans = MyKmeans(3) myKmeans.fit(data) # correct the results y_corrected = [] for i in myKmeans.labels: if i == 0: y_corrected.append(2) elif i == 1: y_corrected.append(0) else: y_corrected.append(1) # 校正的结果统计 print(pd.value_counts(y_corrected)) print(pd.value_counts(y))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
current iteration: 1
current centers: [[74.26682 0.2268598]
[51.69781 63.27919 ]
[ 6.254294 28.35686 ]]
current iteration: 2
current centers: [[ 69.77599323 -10.09654797]
[ 41.44094051 60.24487204]
[ 10.07608722 12.62897013]]
current iteration: 3
current centers: [[ 69.92418447 -10.11964119]
[ 40.70315711 59.73304659]
[ 9.4878081 10.71864891]]
current iteration: 4
current centers: [[ 69.92418447 -10.11964119]
[ 40.68362784 59.71589274]
[ 9.4780459 10.686052 ]]
0 1149
2 952
1 899
dtype: int64
2 1156
1 954
0 890
Name: labels, dtype: int64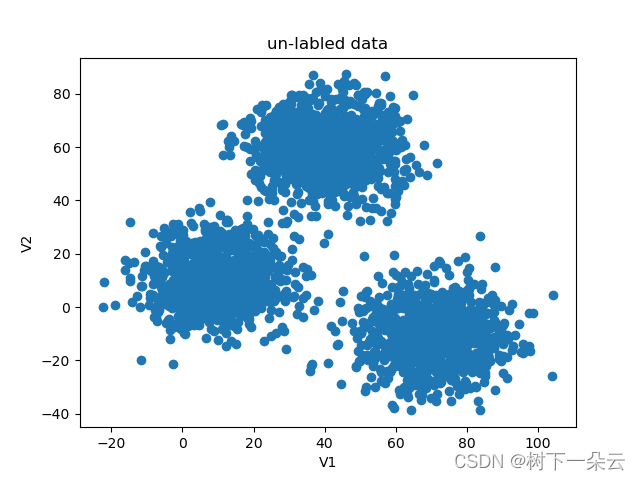
1.4 sklearn实现KMeans


需要注意的一件重要事情是,该模块中实现的算法可以采用不同类型的矩阵作为输入。 所有方法都接受形状[n_samples,n_features]的标准特征矩阵,这些可以从sklearn.feature_extraction模块中的类中获得。对于亲和力传播,光谱聚类和DBSCAN,还可以输入形状[n_samples,n_samples]的相似性矩阵,我们可以使用sklearn.metrics.pairwise模块中的函数来获取相似性矩阵。
n_clusters是KMeans中的k,表示着我们告诉模型我们要分几类。这是KMeans当中唯一一个必填的参数,默认为8类,但通常我们的聚类结果会是一个小于8的结果。通常,在开始聚类之前,我们并不知道n_clusters究竟是多少,因此我们要对它进行探索。# -*- encoding : utf-8 -*- """ @project = sklearn_learning_01 @file = KMeans算法 @author = wly @create_time = 2022/12/6 15:38 """ from sklearn.datasets import make_blobs import matplotlib.pyplot as plt from sklearn.cluster import KMeans import pandas as pd from sklearn.metrics import silhouette_score from sklearn.metrics import silhouette_samples from sklearn.metrics import calinski_harabasz_score from time import time if __name__ == '__main__': # 自己创建数据集 X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1) ax1 = plt.subplot(1, 2, 1) plt.title("unlabeled") ax1.scatter(X[:, 0], X[:, 1], marker='o', # 点的形状 s=8) # 点的大小 color = ["red", "pink", "orange", "gray"] ax2 = plt.subplot(1, 2, 2) plt.title("labeled") for i in range(4): ax2.scatter(X[y == i, 0], X[y == i, 1], marker='o', c=color[i], s=8) plt.show() # 基于这个分布,使用KMeans进行聚类 n_clusters = 3 # KMeans因为并不需要建立模型或者预测结果,因此我们只需要fit就能够得到聚类结果了 # KMeans也有接口predict和fit_predict,表示学习数据X并对X的类进行预测 cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X) y_pred = cluster.labels_ # print(y_pred.shape) # pre = cluster.fit_predict(X) # print(pre == y_pred) # 其实不必使用所有的数据来寻找质心,少量的数据就可以帮助确定质心 # 当数据量非常大的时候,可以使用部分数据来帮助确认质心 cluster_smallsub = KMeans(n_clusters=n_clusters, random_state=0).fit(X[:200]) y_pred_2 = cluster_smallsub.predict(X) # 数据量非常大的时候,效果会好 # 如果数据量还行,不是特别大,直接使用fit之后调用属性.labels_提出来 print(pd.value_counts(y_pred_2 == y)) # 重要属性cLuster_centers_,查看质心 centroids = cluster.cluster_centers_ print("得到质心如下:") print(centroids) print("centroids shape = ", centroids.shape) # 重要属性inertia_,查看总距离平方和 inertia = cluster.inertia_ print("inertia = ", inertia) ax1 = plt.subplot(1, 2, 1) plt.title("initial unlabeled") ax1.scatter(X[:, 0], X[:, 1], marker='o', # 点的形状 s=8) # 点的大小 color = ["red", "pink", "orange", "gray"] ax2 = plt.subplot(1, 2, 2) plt.title("predict labeled") for i in range(n_clusters): ax2.scatter(X[y_pred == i, 0], X[y_pred == i, 1], marker='o', s=8, c=color[i]) ax2.scatter(centroids[:, 0], centroids[:, 1], marker='x', s=15, c="black") plt.show() # 如果把聚类数换成4 n_clusters = 4 cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X) inertia_ = cluster_.inertia_ print("current n_cluster = ", n_clusters) print("inertial = ", inertia_) # 如果把聚类数换成6 n_clusters = 6 cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X) inertia_ = cluster_.inertia_ print("current n_cluster = ", n_clusters) print("inertial = ", inertia_) # 聚类算法的模型评估指标:当真实标签未知的时候:轮廓系数 # 计时 轮廓系数 t0 = time() print("silhouette_score(n_cluster = 3) = ", silhouette_score(X, y_pred)) t1 = time() print("silhouette_score 所需时间为:", t1 - t0) # 聚类数为6时 print("silhouette_score = ", silhouette_score(X, cluster_.labels_)) # silhouette_sample,它的参数与轮廓系数一致,但返回的 # 是数据集中每个样本自己的轮廓系数。 print(silhouette_samples(X, y_pred).shape) print(silhouette_samples(X, y_pred).mean()) # 卡林斯基-哈拉巴斯指数 # 计时 卡林斯基-哈拉巴斯指数 # ,calinski-harabaz指数比轮廓系数的计算块了一倍不止 t0 = time() print("calinski_harabasz_score = ", calinski_harabasz_score(X, y_pred)) t1 = time() print("calinski_harabasz_score 所需时间为:", t1 - t0)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
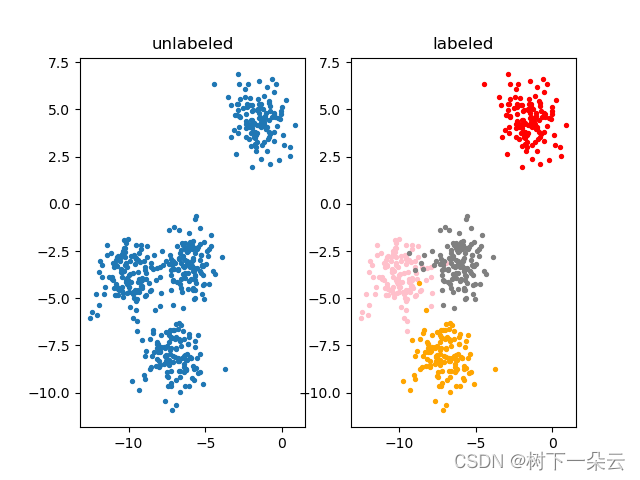
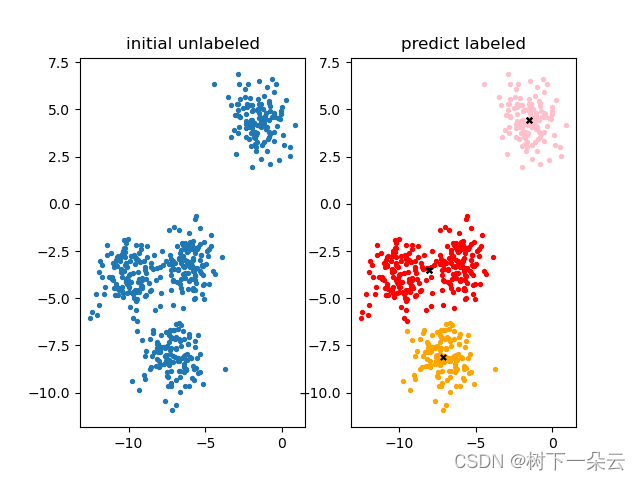
False 371
True 129
dtype: int64
得到质心如下:
[[-8.0807047 -3.50729701]
[-1.54234022 4.43517599]
[-7.11207261 -8.09458846]]
centroids shape = (3, 2)
inertia = 1903.5607664611764
current n_cluster = 4
inertial = 908.3855684760615
current n_cluster = 6
inertial = 733.1538350083081
silhouette_score(n_cluster = 3) = 0.5882004012129721
silhouette_score 所需时间为: 0.004983186721801758
silhouette_score = 0.5150064498560357
(500,)
0.5882004012129721
calinski_harabasz_score = 1809.991966958033
calinski_harabasz_score 所需时间为: 0.0009975433349609375(2)K-Means++算法
K-Means++算法是K-Means算法的改进版,主要是为了选择出更优的初始聚类中心。

2.1 基本思路
- 在数据集中随机选择一个样本作为第一个初始聚类中心;
- 选择其余的聚类中心:
1、计算数据集中每一个样本与已经初始化的聚类中心之间的距离,并选择其中最短的距离,记为di;
2、以概率选择距离最大的样本作为新的聚类中心,重复上述过程,直到k个聚类中心点被确定。 - 对k个初始的聚类中心,利用K-Means算法计算出最终的聚类中心。
对“以概率选择距离最大的样本作为新的聚类中心”的理解:
即初始的聚类中心之间的相互距离应尽可能的远。假如有3 、 5 、 15 、 10 、 2 这五个样本的最小距离d i ,则其和sum为35,然后乘以一个取值在[ 0 , 1 )范围的值,即概率,也可以称其为权重,然后这个结果不断减去样本的距离d i ,直到某一个距离使其小于等于0,这个距离对应的样本就是新的聚类中心。
2.2 代码实现
K-Means++Python代码实现
sklearn实现K-Means++
(3)聚类算法的评估指标
面试高危问题:如何衡量聚类算法的效果?
聚类模型的结果不是某种标签输出,并且聚类的结果是不确定的,其优劣由业务需求或者算法需求来决定,并且没有永远的正确答案。
不同于分类模型和回归,聚类算法的模型评估不是一件简单的事。在分类中,有直接结果(标签)的输出,并且分类的结果有正误之分,所以我们使用预测的准确度,混淆矩阵,ROC曲线等等指标来进行评估,但无论如何评估,都是在”模型找到正确答案“的能力。而回归中,由于要拟合数据,我们有SSE均方误差,有损失函数来衡量模型的拟合程度。但这些衡量指标都不能够使用于聚类。
KMeans的目标是确保**“簇内差异小,簇外差异大”,我们就可以通过衡量簇内差异**来衡量聚类的效果。
Inertia越小模型越好嘛。

3.1 当真实标签已知的时候
虽然我们在聚类中不输入真实标签,但这不代表我们拥有的数据中一定不具有真实标签,或者一定没有任何参考信息。当然,在现实中,拥有真实标签的情况非常少见(几乎是不可能的)。如果拥有真实标签,我们更倾向于使用分类算法。但不排除我们依然可能使用聚类算法的可能性。如果我们有样本真实聚类情况的数据,我们可以对于聚类算法的结果和真实结果来衡量聚类的效果。常用的有以下三种方法:

3.2 当真实标签未知的时候:轮廓系数
在99%的情况下,我们是对没有真实标签的数据进行探索,也就是对不知道真正答案的数据进行聚类。这样的聚类,是完全依赖于评价簇内的稠密程度(簇内差异小)和簇间的离散程度(簇外差异大)来评估聚类的效果。其中轮廓系数是最常用的聚类算法的评价指标。它是对每个样本来定义的,它能够同时衡量:
1) 样本与其自身所在的簇中的其他样本的相似度a,等于样本与同一簇中所有其他点之间的平均距离
2) 样本与其他簇中的样本的相似度b,等于样本与下一个最近的簇中的所有点之间的平均距离
根据聚类的要求”簇内差异小,簇外差异大“,我们希望b永远大于a,并且大得越多越好。单个样本的轮廓系数计算为:
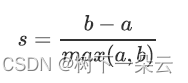

在sklearn中,我们使用模块metrics中的类silhouette_score来计算轮廓系数,它返回的是一个数据集中,所有样本的轮廓系数的均值。但我们还有同在metrics模块中的silhouette_sample,它的参数与轮廓系数一致,但返回的是数据集中每个样本自己的轮廓系数。
轮廓系数有很多优点,它在有限空间中取值,使得我们对模型的聚类效果有一个“参考”。并且,轮廓系数对数据的分布没有假设,因此在很多数据集上都表现良好。但它在每个簇的分割比较清洗时表现最好。但轮廓系数也有缺陷,它在凸型的类上表现会虚高,比如基于密度进行的聚类,或通过DBSCAN获得的聚类结果,如果使用轮廓系数来衡量,则会表现出比真实聚类效果更高的分数。3.3 当真实标签未知的时候:Calinski-Harabaz Index
除了轮廓系数是最常用的,我们还有卡林斯基-哈拉巴斯指数(
Calinski-Harabaz Index,简称CHI,也被称为方差比标准),戴维斯-布尔丁指数(Davies-Bouldin)以及权变矩阵(Contingency Matrix)可以使用。
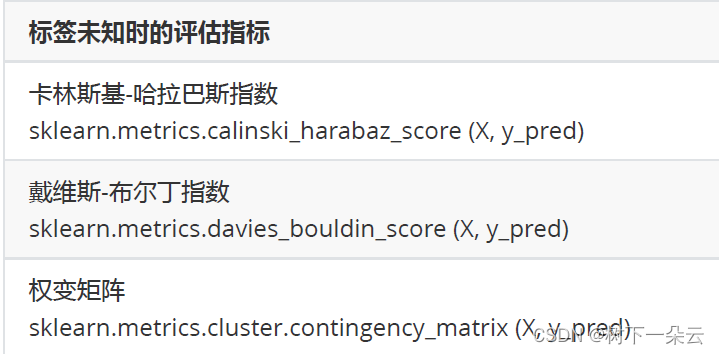

虽然calinski-Harabaz指数没有界,在凸型的数据上的聚类也会表现虚高。但是比起轮廓系数,它有一个巨大的优点,就是计算非常快速。(4)轮廓系数找最佳n_cluster(基于sklearn)
参考:
1、https://blog.csdn.net/qq_42730750/article/details/107119433
2、https://www.cnblogs.com/shelocks/archive/2012/12/20/2826787.html
3、k-means及k-means++原理【python代码实现】 -
相关阅读:
reuseaddr和reuseport
Springboot支付宝沙箱支付---完整详细步骤
阿里云日志上报乱码问题记录
Pytorch的grid_sample是如何实现对grid求导的?(源码解读)
数据离散化
【Linux】实验二 Makefile 的编写及应用
Python中的self与类的理解
【电路笔记】-脉冲宽度调制(PWM)与电机转速控制
Spring更简单的读取和存储
奇舞周刊第 470 期:(10 月最新) 前端图形学实战:从零开发几何画板 (vue3 + vite 版)...
- 原文地址:https://blog.csdn.net/qq_43629083/article/details/128197192
