-
Paper reading:Fine-Grained Head Pose Estimation Without Keypoints (CVPR2018)
Paper reading:Fine-Grained Head Pose Estimation Without Keypoints (CVPR2018)
一、 背景
为什么要读这篇论文,因为LZ之前要做头部姿态估计,看到一些传统的方法,都是先进行人脸检测,然后再进行关键点定位,当然现在可以一起做,anyway,得到最后的关键点位置,再使用一个通用的3D人脸模型,通过solvePnP来得到最终的头部姿态,但是不管是脑子中考虑还是最后的动手实践,得到的结论就是这种方式的头部姿态方法不robust。可以想一下:每个人的脸型不一样吧,物管肯定也有差异,3D通用模型也有很多方式,关键点定位也有偏差,这些都是不确定的,只能说当精度要求不高,并且关键点定位足够准确,且头部姿态估计的对象和3D的通用人脸模型相对匹配的情况下,这种方式才比较好,那么问题来了,算法的泛化能力呢。。。
于是乎,还是往深度学习的方法上瞅瞅,就看到了题目中的文章,简单测试了下,觉得效果可行,那么就开始阅读论文和代码吧。
二、 数据集准备
主要使用的数据是300W-LP,下载的地址为: http://www.cbsr.ia.ac.cn/users/xiangyuzhu/projects/3ddfa/main.htm

大概有2.6个G,下载可能需要一段时间,所以有的时候LZ如果确定要尝试一种方法,首先就要开始准备下载数据集,在下载数据集的时候可以在慢慢阅读下论文。
当然这些数据都是合成的,所以有些图片看起来会有点奇怪

三、 训练代码运行的一些问题
1. python2和python3的兼容性问题
LZ用的是python3,原始论文使用的是python2,所以会存在一些兼容性的问题,这些都比较好修改,例如把xrange替换成range这种。
2. pytorch的版本问题
因为是两三年前的代码了,pytorch可能版本比较旧,也会存在一些代码的修改
- utils.py中
# 直接注释掉这一行 # from torch.utils.serialization import load_lua- 1
- 2
- 训练代码以train_hopenet.py为例吧
error:
RuntimeError: Mismatch in shape: grad_output[0] has a shape of torch.Size([1]) and output[0] has a shape of torch.Size([]).- 1
solution:
# grad_seq = [torch.ones(1).cuda(gpu) for _ in range(len(loss_seq))] grad_seq = [torch.tensor(1.0).cuda(gpu) for _ in range(len(loss_seq))]- 1
- 2
error:
IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number- 1
solution:
# print('Epoch [%d/%d], Iter [%d/%d] Losses: Yaw %.4f, Pitch %.4f, Roll %.4f' # % (epoch + 1, num_epochs, i + 1, len(pose_dataset) // batch_size, loss_yaw.data[0], # loss_pitch.data[0], loss_roll.data[0])) print('Epoch [%d/%d], Iter [%d/%d] Losses: Yaw %.4f, Pitch %.4f, Roll %.4f' % (epoch + 1, num_epochs, i + 1, len(pose_dataset) // batch_size, loss_yaw.item(), loss_pitch.item(), loss_roll.item()))- 1
- 2
- 3
- 4
- 5
- 6
运行就没啥问题了
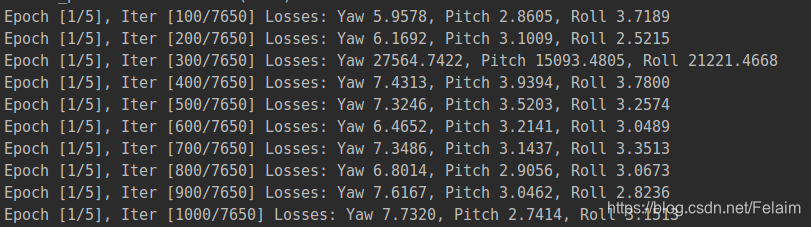 但是這個後面得看一下,爲什麼loss會突然增到這麼大。。。
但是這個後面得看一下,爲什麼loss會突然增到這麼大。。。四、测试结果
因为这个算法的流程是要先进行人脸检测,然后在人脸检测框四周扩充一定的范围后进行头部姿态估计的,按照上述的方法,经过测试,确实效果还可以,但是如果是一整张大图,直接回归出头部姿态,这个结果就是非常不准确的了,下面我们来看下代码,看看是否有值得借鉴的信息。
五、代码部分
5.1 训练代码
我们就以train_hopenet.py为例,其他只是换了backbone,原理都是一样的,当然LZ还是小小改动了一下源码
- 一些常规设置
def parse_args(): """Parse input arguments.""" parser = argparse.ArgumentParser(description='Head pose estimation using the Hopenet network.') parser.add_argument('--gpu', dest='gpu_id', help='GPU device id to use [0]', default=0, type=int) parser.add_argument('--num_epochs', dest='num_epochs', help='Maximum number of training epochs.', default=5, type=int) parser.add_argument('--batch_size', dest='batch_size', help='Batch size.', default=16, type=int) parser.add_argument('--lr', dest='lr', help='Base learning rate.', default=0.001, type=float) parser.add_argument('--dataset', dest='dataset', help='Dataset type.', default='Pose_300W_LP', type=str) parser.add_argument('--data_dir', dest='data_dir', help='Directory path for data.', default='', type=str) parser.add_argument('--filename_list', dest='filename_list', help='Path to text file containing relative paths for every example.', default='', type=str) parser.add_argument('--output_string', dest='output_string', help='String appended to output snapshots.', default='', type=str) parser.add_argument('--alpha', dest='alpha', help='Regression loss coefficient.', default=0.001, type=float) parser.add_argument('--snapshot', dest='snapshot', help='Path of model snapshot.', default='', type=str) args = parser.parse_args() return args- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 主函数
- 1
5.2 Hopenet部分
class Hopenet(nn.Module): # Hopenet with 3 output layers for yaw, pitch and roll # Predicts Euler angles by binning and regression with the expected value def __init__(self, block, layers, num_bins): self.inplanes = 64 super(Hopenet, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(block, 64, layers[0]) self.layer2 = self._make_layer(block, 128, layers[1], stride=2) self.layer3 = self._make_layer(block, 256, layers[2], stride=2) self.layer4 = self._make_layer(block, 512, layers[3], stride=2) self.avgpool = nn.AvgPool2d(7) self.fc_yaw = nn.Linear(512 * block.expansion, num_bins) self.fc_pitch = nn.Linear(512 * block.expansion, num_bins) self.fc_roll = nn.Linear(512 * block.expansion, num_bins) # Vestigial layer from previous experiments self.fc_finetune = nn.Linear(512 * block.expansion + 3, 3) for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2. / n)) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def _make_layer(self, block, planes, blocks, stride=1): downsample = None if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample)) self.inplanes = planes * block.expansion for i in range(1, blocks): layers.append(block(self.inplanes, planes)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.view(x.size(0), -1) pre_yaw = self.fc_yaw(x) pre_pitch = self.fc_pitch(x) pre_roll = self.fc_roll(x) return pre_yaw, pre_pitch, pre_roll- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
5.3 datasets部分
这里LZ就选择其中的一个数据集Pose_300W_LP来进行解释
class Pose_300W_LP(Dataset): # Head pose from 300W-LP dataset def __init__(self, data_dir, filename_path, transform, img_ext='.jpg', annot_ext='.mat', image_mode='RGB'): self.data_dir = data_dir self.transform = transform self.img_ext = img_ext self.annot_ext = annot_ext filename_list = get_list_from_filenames(filename_path) self.X_train = filename_list self.y_train = filename_list self.image_mode = image_mode self.length = len(filename_list) def __getitem__(self, index): #这个比较重要的是数据处理部分 img = Image.open(os.path.join(self.data_dir, self.X_train[index] + self.img_ext)) img = img.convert(self.image_mode) mat_path = os.path.join(self.data_dir, self.y_train[index] + self.annot_ext) # Crop the face loosely pt2d = utils.get_pt2d_from_mat(mat_path) #这个是从mat中得到对应的68个关键点的坐标 x_min = min(pt2d[0, :]) y_min = min(pt2d[1, :]) x_max = max(pt2d[0, :]) y_max = max(pt2d[1, :]) # k = 0.2 to 0.40 k = np.random.random_sample() * 0.2 + 0.2 x_min -= 0.6 * k * abs(x_max - x_min) y_min -= 2 * k * abs(y_max - y_min) x_max += 0.6 * k * abs(x_max - x_min) y_max += 0.6 * k * abs(y_max - y_min) img = img.crop((int(x_min), int(y_min), int(x_max), int(y_max))) # We get the pose in radians pose = utils.get_ypr_from_mat(mat_path) # And convert to degrees. pitch = pose[0] * 180 / np.pi yaw = pose[1] * 180 / np.pi roll = pose[2] * 180 / np.pi # Flip? rnd = np.random.random_sample() if rnd < 0.5: yaw = -yaw roll = -roll img = img.transpose(Image.FLIP_LEFT_RIGHT) # Blur? rnd = np.random.random_sample() if rnd < 0.05: img = img.filter(ImageFilter.BLUR) # Bin values bins = np.array(range(-99, 102, 3)) binned_pose = np.digitize([yaw, pitch, roll], bins) - 1 # Get target tensors labels = binned_pose cont_labels = torch.FloatTensor([yaw, pitch, roll]) if self.transform is not None: img = self.transform(img) return img, labels, cont_labels, self.X_train[index] def __len__(self): # 122,450 return self.length- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
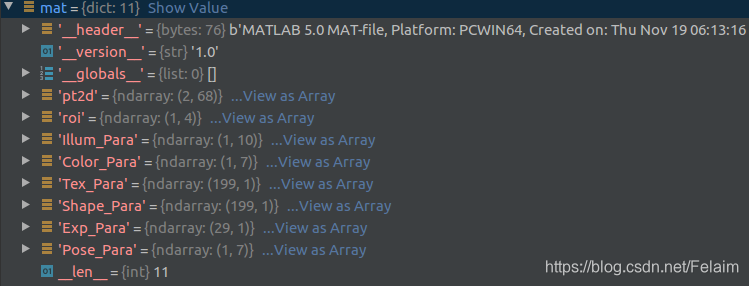
数据集中的mat主要包含这几个部分:
-
相关阅读:
Selenium系列教程 - 番外篇 控制浏览器的两种方式
10款Visual Studio实用插件
优化算法 -AdGrad算法
云原生之K8S------K8S持久化存储PV、PVC
10 创建型模式-原型模式
轻松掌握 jQuery 基础
Spring-web-Mvc
react跨域如何解决?
详解|一级建造师考试报名流程有哪些?
我们又重写了一个关键服务
- 原文地址:https://blog.csdn.net/Felaim/article/details/109068925
