-
小样本学习跨域(Cross-Domain)问题总结
https://arxiv.org/abs/2001.08735
文章来源:小样本学习跨域(Cross-domain)问题总结 - 知乎
目录
一:A CLOSER LOOK AT FEW-SHOT CLASSIFICATION
二:A Broader Study of Cross-Domain Few-Shot Learning
三:FEW-SHOT ACOUSTIC EVENT DETECTION VIA META LEARNING
四:CROSS-DOMAIN FEW-SHOT CLASSIFICATION VIA LEARNED FEATURE-WISE TRANSFORMATION
提出Feature-wise transformation 层缓解跨域问题:
Cars、Places和Plantae三种细粒度数据集如下:
2.A 10 million Image Database for Scene Recognition
零·研究现状
近年来,小样本学习方向蓬勃发展,各种元学习模型以及相关调整策略在各大顶会的期刊上层出不穷,其中Omniglot和MiniImagenet做为被用到最多的小样本学习数据集,在5-way 5-shot的实验设置上:Omniglot数据集上的sota结果早早的达到了99%+;MiniImagenet数据集上的sota结果更是从50%左右不断刷新至现在的80%+,可谓是突飞猛进。按照这个增速,似乎通过元学习方法从根本上解决少样本问题指日可待,但实际情况确没有那么乐观。
问题之一就是Cross Domain跨域问题。近期跨域问题在越来越多的小样本学习论文中被讨论,其阻碍着元学习方法到实际场景的应用,本篇文章围绕下面几篇论文分别从图像和声音领域总结下小样本学习的跨域问题,其他领域的相关内容欢迎补充。
一:A CLOSER LOOK AT FEW-SHOT CLASSIFICATION
实验介绍:
MiniImageNet
CUB(CUB200-2011):该数据集由加州理工学院再2010年提出的鸟类细粒度数据集,也是目前细粒度分类识别研究的基准图像数据集,如图所示。

实验设置:
Backbone:ResNet-18
N-way k-shot:5-way 5-shot
实验结果:

Baseline = pre-training + fine-tuning(linear layer)
Baseline++ = pre-training + fine-tuning(cosine distance)
结果表明:
1.随着域差别的增加,CUB
2.在miniimagenet和CUB-miniimagenet两组实验中,pre-training+fine-tuning的结果优于各元学习模型,表明在小样本学习的跨域问题上,元学习方法似乎失去了优势。
二:A Broader Study of Cross-Domain Few-Shot Learning
文章为验证小样本学习方法在域迁移问题上的表现,建立 benchmark,利用ImageNet做为源域数据集,利用与自然图像不同的域进行目标域评估,如下图所示。相似度由三个正交标准衡量:1)透视失真的存在;2)语义内容;3)颜色深度。PS: 目标域与源域不相交。
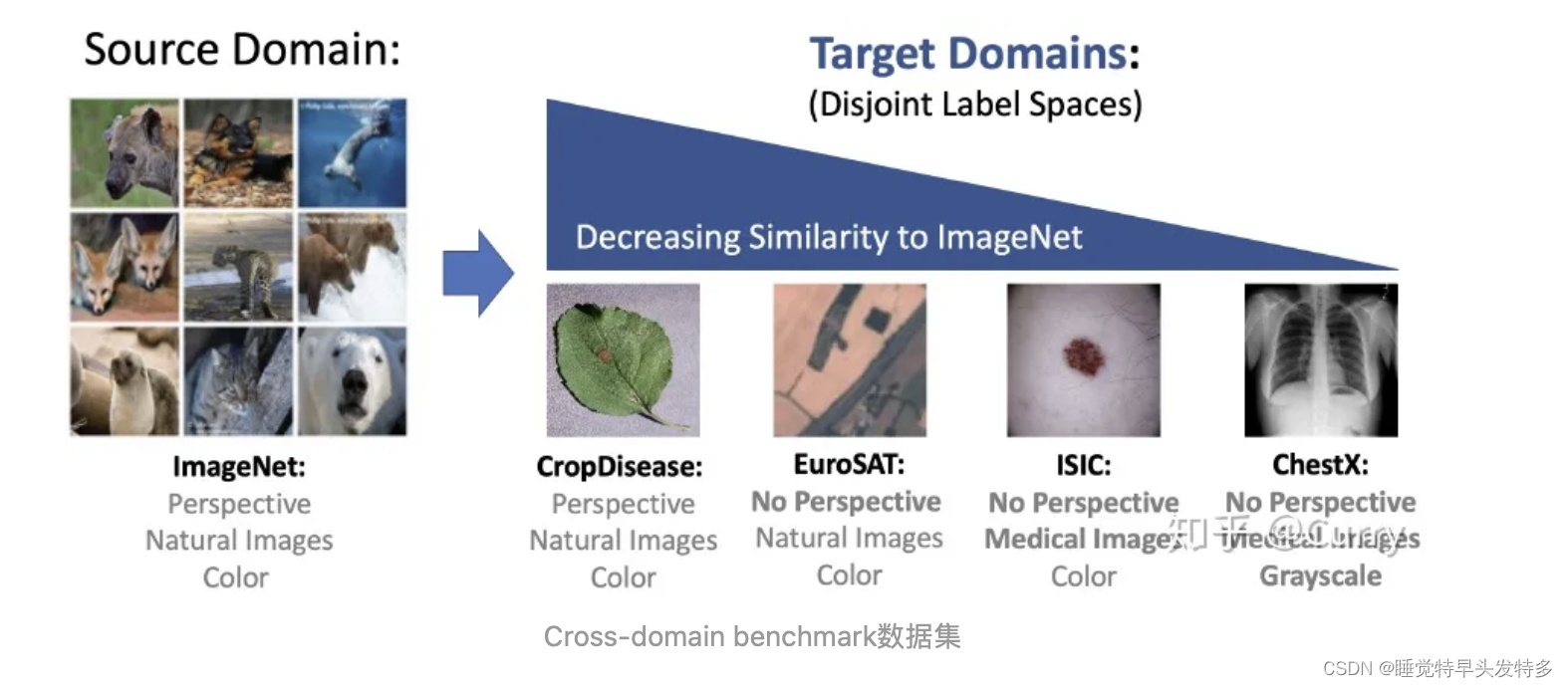
农业: CropDiseases2 彩色, 自然图像, 有自身的特点 (相似度 ⭐⭐⭐⭐)
卫星图: EuroSAT3 彩色, 自然图像, 无透视变形 (相似度 ⭐⭐⭐)
皮肤病: ISIC20184 彩色, 医学影像, 无透视变形 (相似度 ⭐⭐)
X光片: ChextX5 灰度, 医学影像, 无透视变形 (相似度 ⭐)元学习模型测试结果:

迁移学习测试结果:

固定特征提取器(Fixed feature extractor):利用预训练的模型作为固定的特征提取器;微调所有层(Ft all):使用标准的监督学习调整新任务的所有预训练参数;
微调last-k(Ft last-k):只有预训练模型的最后k层针对新任务进行优化,在本文中只考虑微调last-1、微调last-2、微调last-3;
Transductive fine tuning(Transductive Ft):查询图像的统计信息通过BN来使用;
结果表明:
在建立的benchmark跨域(Cross-Domain)数据集上:
1.不同元学习模型在同一目标域下的表现相近,而同一种元学习模型在不同目标域下的性能表现有明显差距,甚至60%的准确率差距;
2.随着目标域与源域相似度的逐渐增加,各个模型性能表现整体有较大幅度提升;
3.最先进的元学习方法MetaOpt没有比早期的元学习模型表现的更好;
4.与微调方法相比,所有的元学习方法的表现都明显不佳,在跨域问题中元学习方法再次被微调方法打败;一些元学习方法甚至被随机权重的网络所击败;
三:FEW-SHOT ACOUSTIC EVENT DETECTION VIA META LEARNING
文章对比了多种元学习方法和fine-tune方法在声事件检测任务上的性能对比,此处主要介绍cross-domain部分实验。
实验介绍:
数据集均抽取自Audioset子集,训练集均是家庭(household)的声音,测试集分别选自同一域下的不相交子集(In-domain)、Audioset子节点下的Music数据集以及与训练域差别最大的Animal数据集。
实验设置:
预处理:
每个音频片段计算log Mel filterbank能量特征做为网络的输入。
测试结果:
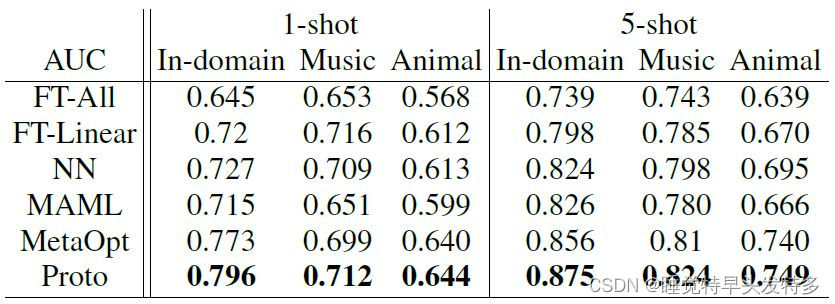
NN是最近邻的缩写,根据相邻的数据点对新数据进行分类。
结果表明:
1.在声事件检测任务上,元学习整体比Fine-tune方法有更好的表现;且Proto原型网络成绩最优;
2.随着域差异的增大,FT-liner和NN方法开始优于MAML;
3.与图像分类相同的是,随着与源域差异的增大,各个模型的表现都会变差;但是最大的下降幅度在15%左右,远小于图像分类最多60%的差异;原因在于所有音频经过了log Mel filterbank特征的提取,提取出来的特征图如下图所示,声音信号由完全不同的域,经过log Mel特征提取后,域差异会减小,因此跨域结果的下降幅度也会变小;

四:CROSS-DOMAIN FEW-SHOT CLASSIFICATION VIA LEARNED FEATURE-WISE TRANSFORMATION
文章提出了一种在域迁移下有效增强基于度量的少镜头分类框架的方法。该方法的核心思想是利用特征转换层来模拟从不同领域的任务中提取的各种特征分布。同时提出了一种learn to learn的方法来优化特征转换层的超参数,通过使用多个可见域来模拟泛化过程。
跨域问题的形成与动机:
基于度量的元学习模型通常由特征编码器E和度量函数M组成,旨在提高模型从可见域到任意不可见域的泛化能力。关键的观察是任务提取的图像特征在看不见域中的分布与在可见域中的分布有显著差异。如下图所示,在seen domain下,元训练得到的模型具有较好的表现,而在unseen domains下,模型的泛化能力显得不足,即出现了跨域问题。
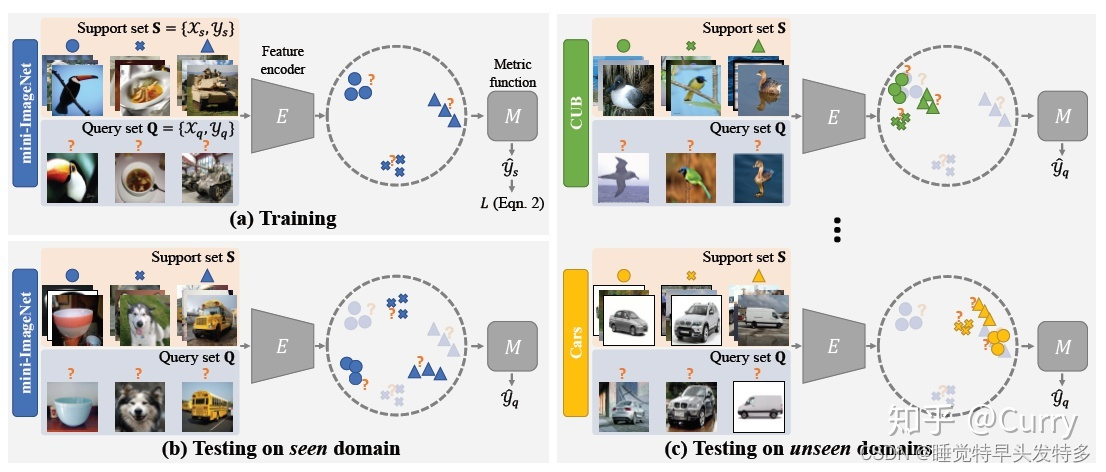
提出Feature-wise transformation 层缓解跨域问题:
如下图所示,(a)文章提出了一个基于特征的转换层来调制特征编码器E中的中间特征激活z,该转换层利用由超参数θγ和θβ参数化的高斯分布采样的缩放项和偏差项。在训练阶段,我们在特征编码器中插入一组特征转换层来模拟从不同领域的任务中提取的特征分布。(b) 我们设计了一种learn to-learn算法来优化特征转换层的超参数θγ和θβ,该算法在可视域(top)上进行优化后,在不可见域(bottom)上最大化应用度量模型的性能。

实验介绍:
本文的实验中使用了分类数据集:minimagenet、CUB、Cars、Places和Plantae。其中针对mini ImageNet和CUB数据集沿用了Ravi&Larochelle(2017)和Hilliard(2018)等人划分式。对于其他数据集,通过随机拆分类来手动处理数据集。下表总结了每个数据集的训练、验证和测试类别的数量。

Cars、Places和Plantae三种细粒度数据集如下:
1.Cars

2.A 10 million Image Database for Scene Recognition

3.Plantae

实验设置:
5-way 1-Shot / 5-way 5-Shot
Backbone:ResNet-10实验结果一:
采用常规跨域实验设置:我们在mini-ImageNet上训练模型,并在其余数据集上评估训练后的模型,FT表明使用提出的feature-wise transformation layers特征转换层来训练模型。

实验结果二:
采用leave one out设置:从CUB、Cars、Places和Plantae中选择一个作为unseen domain进行评估,mini-ImageNet和其余的域作为训练模型的seen domain。FT和LFT分别表示为应用预训练的特征提取器和使用所提出的learn to learn feature-wise transformation层。

结果表明:
1.结合大量实验验证了提出的feature-wise transformation层适用于不同的基于度量的少镜头分类算法,并且在基线上显示出一致的改进。
-
相关阅读:
使用c++实现输出爱心(软件:visual Studio)
uniapp——上传图片获取到file对象而非临时地址——基础积累
用友政务财务系统 FileDownload 任意文件读取漏洞复现
第一期 | 整洁,从桌面开始
【音视频基础】视频基础理论
java开源商城免费搭建 VR全景商城 saas商城 b2b2c商城 o2o商城 积分商城 秒杀商城 拼团商城 分销商城 短视频商城
【Linux】Ubuntu升级nodejs版本
抗混叠在微小目标检测中的重要性
用customize-cra+react-app-rewired配置px2rem
音视频领域的未来发展方向展望
- 原文地址:https://blog.csdn.net/m0_57656758/article/details/128193248