-
DJ13-1 汇编语言程序设计-2
目录
一、段定义伪指令
伪指令 SEGMENT 和 ENDS 用于定义一个逻辑段。
使用时必须配对,分别表示定义的开始与结束。格式如下:
- 段名 SEGMENT [定位类型] [组合类型] [′类别名′]
- ...
- 段名 ENDS
[ ] 内的是可选参数,设有默认值。各个参数之间用空格分隔,参数之间的顺序不能改变。
1. 段名
① 段名由用户自己任意选定,但要符合标识符定义规则。
② 最好选用与该逻辑段用途相关的名称。如:数据段1为 DATA1,数据段2为 DATA2 等。
③ 一对 SEGMENT 和 ENDS 前的段名必须一致。
④ 段名代表段地址。
- ...
- MOV AX, DSEG ; 将DSEG存储的段地址送入DS,此后将由DS提供段地址
- MOV DS, AX
- MOV AX, ESEG ; 将ESEG存储的段地址送入ES,此后将由ES提供段地址
- MOV ES, AX
- ...
段地址 = 段基地址 = 段基址
2. 定位类型
功能:定位类型决定了当前段起始数据边界,即第一个可存放数据的存储单元的位置,再由起始数据边界决定当前段地址。
定位类型可以有4种取值:PAGE、PARA、WORD、BYTE 。
① PAGE:表示该段从一个页面的边界开始存放数据。
由于一个页面为 256 个字节且页面编号从 0 开始,因此 PAGE 定位类型的段起始地址的最后 8 位二进制数一定为 0,即以 00H 结尾的地址。
② PARA:表示该段从一个小节的边界开始存放数据。
由于一个小节为 16 个字节且页面编号从 0 开始,因此 PARA 定位类型的段起始地址的最后 4 位二进制数一定为 0,即以 0H 结尾的地址。
在省略情况下,定位类型默认为 PARA 。
③ WORD:表示该段从一个偶数字节地址开始存放数据。
WORD 定位类型的段起始地址的最后一位二进制数一定为 0,即以 0B 结尾的地址。
④ BYTE:表示该段起始数据单元地址可以是任一地址值。
定位类型 段起始地址 PAGE XXX00H PARA XXXX0H WORD XX...X0B BYTE XX...XXB 3. 组合类型
功能:指定段与段之间的连接关系和定位。
它有六种取值选择:NONE、PUBLIC、STACK、COMMON、MEMORY、AT 。
① NONE
表示本段与其它逻辑段无连接关系,不同的程序模块中,即使具有相同的段名,也分别装入内存。
默认情况下,组合类型是 NONE 。
② PUBLIC
表示对于不同程序模块中用 PUBLIC 说明的具有相同段名的逻辑段,汇编时将它们连接在一起,构成一个大的逻辑段。
③ STACK
- 把不同程序模块中所有同名的堆栈段连接成一个连续堆栈段。
- 系统自动对 SS 段寄存器初始化为该连续段的段地址,并初始化堆栈指针 SP 。
④ COMMON
对不同程序模块中用 COMMON 说明的同名逻辑段,连接时从同一个地址开始装入,即所有逻辑段重叠在一起,连接之后的长度等于最长的逻辑段。
⑤ MEMORY
表示本段在存储器中应定位在所有其它段之后的最高地址上。如果有多个用 MEMORY 说明的段,则只处理第一个用 MEMORY 说明的段,其余的被视为 COMMON 。
不是在整个内存的最高地址上,只是在我们这个程序的最高地址上。
⑥ AT
根据表达式的值定位段地址。如:AT 8000H,则段地址为 8000H,即本段的起始物理地址为 80000H 。
4. 类别名
定义:类别名为某一个段或几个相同类型段设定类型名称。
格式:类别名必须用单引号引起来。
所用字符串可任意选定,但它不能使用程序中的标号、变量名或其它定义的符号。
功能:系统进行连接处理时,把不同程序模块类别名相同的段存放在相邻的存储区,但段的划分与使用仍按原来的设定。优先级:组合类型 > 类别名。
组合类型和类型名的应用举例:
- STACK1 SEGMENT PARA STACK 'STACK0' ; STACK已是一种组合类型,不能作类型名
- DB 2H DUP(0)
- STACK1 ENDS
- DATA1 SEGMENT PARA 'DATA'
- X1 DB 10H, 20H, 30H
- DATA1 ENDS
- STACK2 SEGMENT PARA 'STACK0'
- DB 8H DUP(0)
- STACK2 ENDS
- CODE SEGMENT PARA MEMORY ; CODE段被装入在最高地址上
- ASSUME CS:CODE, DS:DATA1, SS:STACK1
- MAIN:
- ...
- CODE ENDS
- DATA2 SEGMENT BYTE 'DATA'
- X2 DB 40H, 50H, 60H
- DATA2 ENDS
- END MAIN
分配存储空间及加载到内存:
若选用了 PARA 定位类型说明,则在一个段的结尾与另一个段的起始之间可能存在一些空白。
- 当定位类型为 PAGE 和 PARA 时,段基物理地址与段起始地址相同。
- 当定位类型为 WORD 和 BYTE 时,段基物理地址与段起始地址可能不同。
段基物理地址 = 段基地址 × 16;段起始地址 = 物理地址
实质:偏移地址是否为 0 。若为 0,则相同;若不为 0,则不同。

二、设定段寄存器伪指令
1. 设定段寄存器伪指令
格式:ASSUME 段寄存器名:段名,段寄存器名:段名,…
其中,段寄存器名可以为CS、DS、ES 和 SS,段名是用 SEGMENT/ENDS 伪指令定义的段名。
功能:ASSUME 的功能是告诉汇编程序,在处理源程序时,定义的逻辑段与哪个段寄存器关联。即对应的标号、变量等对应的段地址用哪个段寄存器来表示,可以在程序中多次设定。
ASSUME 并不设置各个段寄存器的具体内容,段寄存器的值是在程序运行时设定的。
应用举例:
- DATA1 SEGMENT
- VAR1 DB 12H
- DATA1 ENDS
- DATA2 SEGMENT
- VAR2 DB 34H
- DATA2 ENDS
- STACK1 SEGMENT STACK ; 必须定义堆栈段
- DW 20H DUP(0)
- STACK1 ENDS
- CODE SEGMENT
- VAR3 DB 56H
- ASSUME CS:CODE, DS:DATA1, ES:DATA2, SS:STACK1
- START:
- ...
- INC VAR1 ; DS:[ ],即指令编码中有段前缀DS
- INC VAR2 ; ES:[ ],即指令编码中有段前缀ES
- INC VAR3 ; CS:[ ],即指令编码中有段前缀CS
- ...
- CODE ENDS
- END START
2. 段寄存器的初始化方法
(1)DS 和 ES 的装入
- DATA1 SEGMENT
- VAR1 DB 12H
- DATA1 ENDS
- DATA2 SEGMENT
- VAR2 DB 34H
- DATA2 ENDS
- STACK1 SEGMENT STACK ; 必须定义堆栈段
- DW 20H DUP(0)
- STACK1 ENDS
- CODE SEGMENT
- VAR3 DB 56H
- ASSUME CS:CODE, DS:DATA1, ES:DATA2, SS:STACK1
- START:
- MOV AX, DATA1 ; 段名代表段地址
- MOV DS, AX
- MOV AX, DATA2 ; 段名代表段地址
- MOV ES, AX
- ...
- CODE ENDS
- END START
(2)SS 的装入
SS 的装入有两种方法。
① 简便方法
- 在段定义伪指令的组合类型项中,使用 STACK 参数;
- 在段寻址伪指令 ASSUME 语句中,把该段与 SS 段寄存器关联。
- STACK1 SEGMENT STACK
- DW 20H DUP(0)
- STACK1 ENDS
- CODE SEGMENT
- ASSUME CS:CODE, SS:STACK1
- START:
- ...
- CODE ENDS
- END START
SS 将被系统自动装入 STACK 段的段地址,且 (SP) = 40H,即堆栈的长度。
② 普通方法
如果在段定义伪指令的组合类型中,未使用 STACK 参数,或者是在程序中要调换到另一个堆栈,这时可以使用类似于 DS 和 ES 的装入方法。
- STACK1 SEGMENT
- DW 20H DUP(0)
- STACK1 ENDS
- CODE SEGMENT
- ASSUME CS:CODE, SS:STACK1
- START:
- MOV AX, STACK1
- MOV SS, AX
- MOV SP, OFFSET STACK1
- ...
- CODE ENDS
- END START
(3)CS 的装入
CPU 在执行指令之前根据 CS 和 IP 的内容来从内存中提取指令,即必须在程序执行之前装入 CS 和 IP 的值。因此,CS 和 IP 的初始值就不能用可执行语句来装入。
装入 CS 和 IP 一般有以下两种情况。
① 汇编时系统软件按照 END 伪指令指定的地址装入初始的 CS 和 IP 。
任何一个源程序都必须以 END 伪指令来结束:
END 起始地址其中,起始地址可以是一个标号或表达式,它与程序中第一条指令语句前所加的标号必须一致。
- END 伪指令用来指示源程序结束和指定程序运行时的起始地址。
- 当程序被装入内存时,系统软件根据起始地址的段地址和偏移量分别被装入 CS 和 IP 中。
START 即为程序入点,标号名字可以随便取,但是一定要配对:
- ...
- CODE SEGMENT
- ...
- START:
- ...
- CODE ENDS
- END START
② 在程序运行期间,当执行某些指令时,CPU 自动修改 CS 和 IP,使它们指向新的代码段。
-
执行段间过程调用 CALL 和段间返回指令 RET
-
执行段间无条件转移指令 JMP
-
响应中断及中断返回指令
-
执行硬件复位操作
三、过程定义伪指令
在程序设计过程中,常常将具有一定功能的程序段设计成一个子程序。
在 MASM 宏汇编程序中,用过程来构造子程序。格式如下:
- 过程名 PROC [NEAR/FAR]
- ...
- RET
- 过程名 ENDP
过程名 :是子程序的名称,它被用作过程调用指令 CALL 的目的操作数。
过程名类同一个标号的作用,具有段、偏移量和类型三个属性。
类型属性使用 NEAR 和 FAR 来指定,若没有指定,则隐含为 NEAR 。
- NEAR:过程只能被本段指令调用。
- FAR:过程可以供其它段的指令调用。
RET 返回指令:每一个过程中必须包含有返回指令 RET,其作用是控制 CPU 从该过程中返回到调用过程的主程序。
四、当前位置计数器 $ 与定位伪指令 ORG
当前位置计数器 $:在汇编源程序时,使用地址计数器保存正在汇编的指令的段内偏移地址,用户可以用 $ 来引用地址计数器的值。
即这条含有 $ 的语句的段内偏移地址。
定位伪指令 ORG:ORG 伪指令给它下面一条语句指定起始偏移地址。
通常,段定义语句 SEGMENT 指出了段的起点,偏移地址为 0,段内各个语句或数据的地址,将会由段起始地址开始依次后推。当要对某条指令或某些数据规定特殊的存放地址时,可用 ORG 伪指令来实现,ORG 语句可放在程序的任何位置。
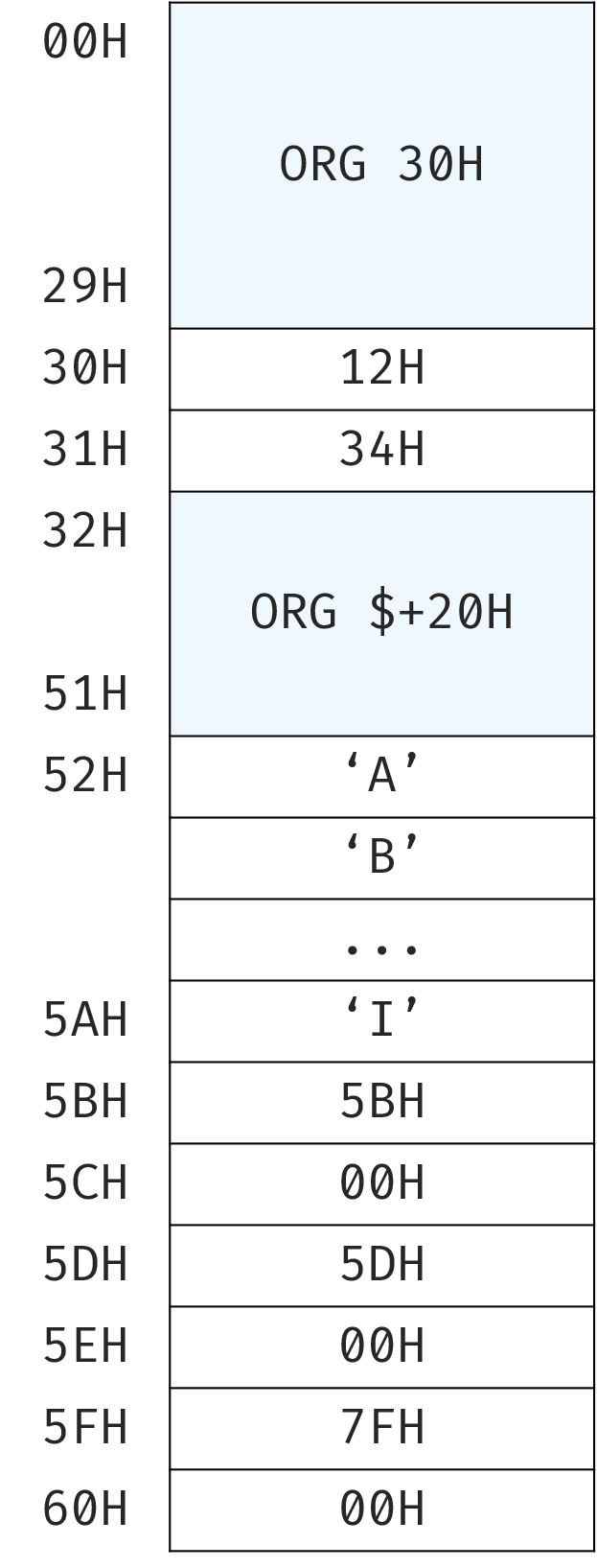
去年期末考试题:
- DATA1 SEGMENT
- ORG 30H
- DB1 DB 12H, 34H ; 起始地址为0000H:0030H
- ORG $+20H ; $=0032H
- STRING DB 'ABCDEFGHI' ; 起始地址为0000H:0052H
- COUNT EQU $-STRING ; $=005BH,EQU语句不占内存
- DB2 DW $ ; $=005BH
- ; DB3 DB $, $+20H ; 语法错误。$为16位
- DB3 DW $, $+20H ; $=005DH,$=005FH
- DATA1 ENDS
易错点:
- $ 用于存放 16 位的偏移地址,因此 $ 也是 16 位,需要用 DW 来定义变量。
- 同一条语句中的 $ 值是动态变化的,不要以为永远是这条语句的起始值。
分配存储空间:
-
相关阅读:
剑指 Offer II 097. 子序列的数目
基于红外技术的交通灯设计
请求地址‘/operlog‘,发生未知异常
JVM性能调优与实战基础理论篇-下
C语言——九九乘法表
套路【2】实验环境搭建
Android开发常见的报错问题(持续更新记录)
ClickHouse进阶(十二):Clickhouse数据字典-2-字典类型
C# 第五章『面向对象』◆第10节:委托
RedisObject各属性结构的作用
- 原文地址:https://blog.csdn.net/m0_64140451/article/details/128183334
