-
cartgrapher ukf 代码清晰属实不错
原理
UKF
- KF 系列求解:
Kalman filter需要线性模型EKF通过泰勒展开线性化- 更好的方式线性化 ->
Unscented Transform->UKF- 计算一组(所谓的)sigma 点
- 从变换和加权的 sigma 点计算高斯
Unscented Transform- 计算一系列的 Sigma 点
- 每个Sigma点有一个权重
- 通过非线性函数转换 Sigma 点
- 权重点计算高斯
Sigma and weight
Sigma 点- 选择
χ
[
i
]
{\chi^{[i]}}
χ[i],
w
[
i
]
{w^{[i]}}
w[i] 使得:
- ∑ i w [ i ] = 1 {\sum_i w^{[i]} = 1} ∑iw[i]=1
- μ = ∑ i w [ i ] χ [ i ] { \mu = \sum_i w^{[i]}\chi^{[i]}} μ=∑iw[i]χ[i]
- ∑ = ∑ i w [ i ] ( χ [ i ] − μ ) ( χ [ i ] − μ ) T {\sum = \sum_i w^{[i]}(\chi^{[i]}-\mu)(\chi^{[i]}-\mu)^T} ∑=∑iw[i](χ[i]−μ)(χ[i]−μ)T
- 没有唯一的解决方案
- 如何选择Sigma点
- 第一个Sigma点也是均值 χ [ 0 ] = μ {\chi^[0] = \mu} χ[0]=μ
- χ [ i ] = μ + ( ( n + λ ) ∑ ) i {\chi^[i] = \mu + (\sqrt{(n+\lambda)\sum})_i} χ[i]=μ+((n+λ)∑)i for i=1,…,n
-
χ
[
i
]
=
μ
−
(
(
n
+
λ
)
∑
)
i
−
n
{\chi^[i] = \mu - (\sqrt{(n+\lambda)\sum})_{i-n}}
χ[i]=μ−((n+λ)∑)i−n for i=1+n,…,2n
- 矩阵的开方根
- n n n 维度
- λ \lambda λ 缩放参数
- 矩阵开方根
- 定义 S S S, ∑ = S S \sum=SS ∑=SS
- 通过对角化计算:
-
∑
=
V
D
V
−
1
=
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
=
V
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
V
−
1
{\sum=VDV^{-1}= = V
( d 11 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ d n n ) ( d 11 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ d n n ) V^{-1}} ∑=VDV−1=⎝⎜⎛d11⋮0⋯⋱⋯0⋮dnn⎠⎟⎞=V⎝⎜⎛d11⋮0⋯⋱⋯0⋮dnn⎠⎟⎞⎝⎜⎛d11⋮0⋯⋱⋯0⋮dnn⎠⎟⎞V−1( d 11 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ d n n ) - 因此可以定义: S = V D 1 / 2 V − 1 {S=VD^{1/2}V^{-1}} S=VD1/2V−1
- 因此: S S = ( V D 1 / 2 V − 1 ) ( V D 1 / 2 V − 1 ) = V D V − 1 = Σ SS=(VD^{1/2}V^{-1})(VD^{1/2}V^{-1})=VDV^{-1}=\Sigma SS=(VD1/2V−1)(VD1/2V−1)=VDV−1=Σ
-
∑
=
V
D
V
−
1
=
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
=
V
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
V
−
1
{\sum=VDV^{-1}=
Cholesky Matrix开方根法- 矩阵开方根的替代定义: L , ∑ = L L T {L, \sum=LL^T} L,∑=LLT
- L , ∑ {L,\sum} L,∑ 有相同的特征向量
- Sigma 点和特征向量
- Sigma 点可以但不必位于
Σ
{\Sigma}
Σ 的主轴上
- χ [ i ] = μ + ( ( n + λ ) ∑ ) i {\chi^[i] = \mu + (\sqrt{(n+\lambda)\sum})_i} χ[i]=μ+((n+λ)∑)i for i=1,…,n
- χ [ i ] = μ − ( ( n + λ ) ∑ ) i − n {\chi^[i] = \mu - (\sqrt{(n+\lambda)\sum})_{i-n}} χ[i]=μ−((n+λ)∑)i−n for i=1+n,…,2n
- Sigma 点可以但不必位于
Σ
{\Sigma}
Σ 的主轴上
- Sigma 点 权重
- w m [ 0 ] = λ n + λ {w_m^{[0]}=\frac{\lambda}{n+\lambda}} wm[0]=n+λλ
- w c [ 0 ] = w m [ 0 ] + ( 1 − α 2 + β ) {w_c^{[0]}=w_m^{[0]}+(1-\alpha^2+\beta)} wc[0]=wm[0]+(1−α2+β)
- w c [ i ] = w m [ i ] = 1 2 ( n + λ ) {w_c^{[i]}=w_m^{[i]} = \frac{1}{2(n+\lambda)}} wc[i]=wm[i]=2(n+λ)1 for i=1,…,2n
- 其中:
- w m [ i ] {w_m^{[i]}} wm[i] 用于计算均值,
- w c [ i ] {w_c^{[i]}} wc[i] 用于计算协方差
- 右边的为参数
- 选择
χ
[
i
]
{\chi^{[i]}}
χ[i],
w
[
i
]
{w^{[i]}}
w[i] 使得:
- 恢复高斯
- 从权重和 点计算高斯
- μ ′ = ∑ i = 0 2 n w m [ i ] g ( χ [ i ] ) {\mu'=\sum_{i=0}^{2n}w_m^{[i]}\ g({\chi}^{[i]})} μ′=∑i=02nwm[i] g(χ[i])
- Σ ′ = ∑ i = 0 2 n w c [ i ] ( g ( χ [ i ] ) − μ ′ ) ( g ( χ [ i ] ) − μ ′ ) T {\Sigma'=\sum_{i=0}^{2n} w_c^{[i]}(g(\chi^{[i]})-\mu')(g(\chi^{[i]})-\mu')^T} Σ′=∑i=02nwc[i](g(χ[i])−μ′)(g(χ[i])−μ′)T
UKF Algorithm
-
Sigma points and Weight
- 点:
- χ [ 0 ] = μ \chi^{[0]}=\mu χ[0]=μ
- χ [ i ] = μ + ( ( n + λ ) ∑ ) i {\chi^[i] = \mu + (\sqrt{(n+\lambda)\sum})_i} χ[i]=μ+((n+λ)∑)i for i=1,…,n
- χ [ i ] = μ − ( ( n + λ ) ∑ ) i − n {\chi^[i] = \mu - (\sqrt{(n+\lambda)\sum})_{i-n}} χ[i]=μ−((n+λ)∑)i−n for i=1+n,…,2n
- 权重:
- w m [ 0 ] = λ n + λ {w_m^{[0]}=\frac{\lambda}{n+\lambda}} wm[0]=n+λλ
- w c [ 0 ] = w m [ 0 ] + ( 1 − α 2 + β ) {w_c^{[0]}=w_m^{[0]}+(1-\alpha^2+\beta)} wc[0]=wm[0]+(1−α2+β)
- w c [ i ] = w m [ i ] = 1 2 ( n + λ ) {w_c^{[i]}=w_m^{[i]} = \frac{1}{2(n+\lambda)}} wc[i]=wm[i]=2(n+λ)1 for i=1,…,2n
- 参数:
- k ≥ 0 k \geq 0 k≥0
-
α
∈
(
0
,
1
]
\alpha \in (0,1]
α∈(0,1] 影响
Sigma点与均值的距离 - λ = α ( n + k ) − n \lambda =\alpha(n+k)-n λ=α(n+k)−n
- β = 2 \beta=2 β=2 优化选择为高斯
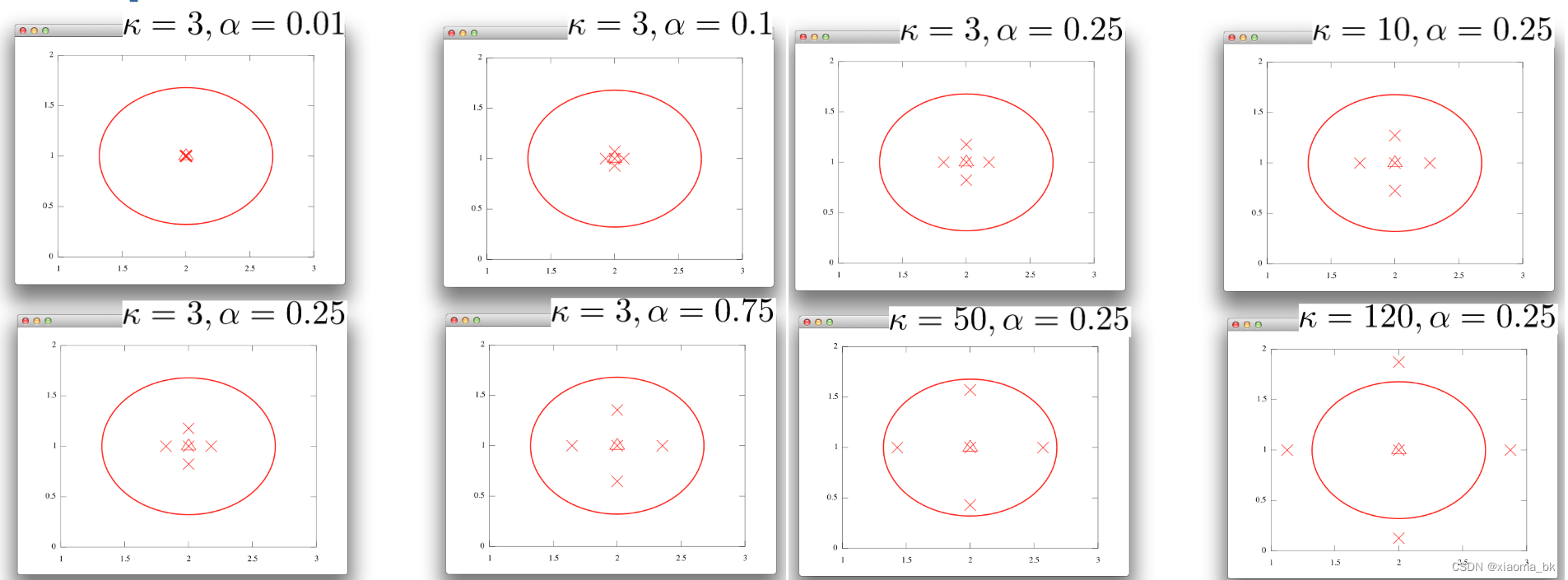
- 点:
-
Prediction
-
χ t − 1 = ( μ t − 1 , μ t − 1 + ( n + λ ) ∑ t − 1 μ t − 1 − ( n + λ ) ∑ t − 1 ) {\chi_{t-1}=(\mu_{t-1},\ \ \mu_{t-1}+\sqrt{(n+\lambda)\sum_{t-1}}\ \ \mu_{t-1}-\sqrt{(n+\lambda)\sum_{t-1}})} χt−1=(μt−1, μt−1+(n+λ)∑t−1 μt−1−(n+λ)∑t−1)
-
χ ˉ t ∗ = g ( u t , χ t − 1 ) {\bar{\chi}_t^* = g(u_t,\chi_{t-1})} χˉt∗=g(ut,χt−1)
-
μ t ˉ = ∑ i = 0 2 n w m [ i ] χ ˉ t ∗ [ i ] {\bar{\mu_t}=\sum_{i=0}^{2n}w_m^{[i]}\bar{\chi}_t^{*[i]}} μtˉ=∑i=02nwm[i]χˉt∗[i]
-
Σ ˉ t = ∑ i = 0 2 n w c [ i ] ( χ ˉ t ∗ [ i ] − μ t ˉ ) ( χ ˉ t ∗ [ i ] − μ t ˉ ) T + R t {\bar{\Sigma}_t=\sum_{i=0}^{2n}w_c^{[i]}(\bar{\chi}_t^{*[i]}-\bar{\mu_t})(\bar{\chi}_t^{*[i]}-\bar{\mu_t})^T+R_t} Σˉt=∑i=02nwc[i](χˉt∗[i]−μtˉ)(χˉt∗[i]−μtˉ)T+Rt
-
-
Correction
- χ t ˉ = ( μ t ˉ , μ t ˉ + ( n + λ ) ∑ t − 1 , μ t ˉ − ( n + λ ) ∑ t − 1 ) {\bar{\chi_{t} }=(\bar{\mu_{t}},\ \ \bar{\mu_{t}}+\sqrt{(n+\lambda)\sum_{t-1}},\ \ \bar{\mu_{t}}-\sqrt{(n+\lambda)\sum_{t-1}})} χtˉ=(μtˉ, μtˉ+(n+λ)∑t−1, μtˉ−(n+λ)∑t−1)
- z t ˉ = h ( χ t ˉ ) {\bar{z_t}=h(\bar{\chi_t})} ztˉ=h(χtˉ)
- z t ^ = ∑ i = 0 2 n w m [ i ] z ˉ t [ i ] {\hat{z_t}=\sum_{i=0}^{2n}w_m^{[i]}\bar{z}_t^{[i]}} zt^=∑i=02nwm[i]zˉt[i]
- S t = ∑ i = 0 2 n w c [ i ] ( χ ˉ t [ i ] − μ ˉ t ) ( χ ˉ t [ i ] − μ ˉ t ) T {S_t=\sum_{i=0}^{2n}w_c^{[i]}(\bar{\chi}_t^{[i]}-\bar{\mu}_t)(\bar{\chi}_t^{[i]}-\bar{\mu}_t)^T} St=∑i=02nwc[i](χˉt[i]−μˉt)(χˉt[i]−μˉt)T
- K t = ∑ ˉ t x , z S t − 1 {K_t = \bar{\sum}_t^{x,z}S_t^{-1}} Kt=∑ˉtx,zSt−1
- ∑ t = ∑ ˉ t − K t S t K t T {\sum_t =\bar{\sum}_t - K_tS_tK_t^T} ∑t=∑ˉt−KtStKtT
UT/UKF/EKF Summary
- UT/UKF
- 无迹卡尔曼作为线性化的替代方案
- UT 是比泰勒展开更好的近似值
- UT 使用 sigma 点传播
- UT中的自由参数
- UKF 在预测和校正步骤中使用 UT
- UKF VS EKF
- 线性模型的结果与 EKF 相同
- 非线性模型比 EKF 更好的近似
- 差异通常“有点小”
- UKF 不需要雅可比行列式
- 相同的复杂度类
- 比 EKF 稍慢
- 仍然受限于高斯分布
cato_code
外围函数
检测是否为对称矩阵
检查A是否是对称矩阵,A减去A的转置~=0
- ∣ ∣ ( A − A T ) ∣ ∣ 2 < 1 e − 5 {||(A-A^T)||_2 < 1e-5} ∣∣(A−AT)∣∣2<1e−5
// Checks if 'A' is a symmetric matrix. template <typename FloatType, int N> void CheckSymmetric(const Eigen::Matrix<FloatType, N, N>& A) { // This should be pretty much Eigen::Matrix<>::Zero() if the matrix is // symmetric. //The NaN values are used to identify undefined or non-representable values for floating-point elements, //such as the square root of negative numbers or the result of 0/0. const FloatType norm = (A - A.transpose()).norm(); CHECK(!std::isnan(norm) && std::abs(norm) < 1e-5) << "Symmetry check failed with norm: '" << norm << "' from matrix:\n" << A; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
矩阵的开方根
本代码使用的为上述中 对角化的方法:
- 定义 S S S, ∑ = S S \sum=SS ∑=SS
- 通过对角化计算:
-
∑
=
V
D
V
−
1
=
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
=
V
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
V
−
1
{\sum=VDV^{-1}= = V
( d 11 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ d n n ) ( d 11 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ d n n ) V^{-1}} ∑=VDV−1=⎝⎜⎛d11⋮0⋯⋱⋯0⋮dnn⎠⎟⎞=V⎝⎜⎛d11⋮0⋯⋱⋯0⋮dnn⎠⎟⎞⎝⎜⎛d11⋮0⋯⋱⋯0⋮dnn⎠⎟⎞V−1( d 11 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ d n n ) - 因此可以定义: S = V D 1 / 2 V − 1 {S=VD^{1/2}V^{-1}} S=VD1/2V−1
-
∑
=
V
D
V
−
1
=
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
=
V
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
(
d
11
⋯
0
⋮
⋱
⋮
0
⋯
d
n
n
)
V
−
1
{\sum=VDV^{-1}=
代码实现:
-
几个术语: Av=λv. λ 为一标量,称为 v 对应的特征值。也称 v 为特征值 λ 对应的特征向量。 eigendecomposition,特征分解,谱分解,是将矩阵分解为由其特征值和特征向量表示的矩阵之积的方法。 需要注意只有对可对角化矩阵才可以施以特征分解。 eigenvalues 特征值, eigenvectors 特征向量 返回对称半正定矩阵的平方根B,M=B*B- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
template <typename FloatType, int N> Eigen::Matrix<FloatType, N, N> MatrixSqrt( const Eigen::Matrix<FloatType, N, N>& A) { CheckSymmetric(A);//必须是对称矩阵 Eigen::SelfAdjointEigenSolver<Eigen::Matrix<FloatType, N, N>> adjoint_eigen_solver((A + A.transpose()) / 2.); //A==A的转置,构造特征分解对象。 const auto& eigenvalues = adjoint_eigen_solver.eigenvalues();//特征值 CHECK_GT(eigenvalues.minCoeff(), -1e-5) << "MatrixSqrt failed with negative eigenvalues: " << eigenvalues.transpose(); //Cholesky分解:把一个对称正定的矩阵表示成一个下三角矩阵L和其转置的乘积的分解。 return adjoint_eigen_solver.eigenvectors() * adjoint_eigen_solver.eigenvalues() .cwiseMax(Eigen::Matrix<FloatType, N, 1>::Zero()) .cwiseSqrt() .asDiagonal() * adjoint_eigen_solver.eigenvectors().transpose(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
高斯分布
高斯分布
-
均值 : N × 1 N\times 1 N×1
-
协方差: N × N N\times N N×N
-
/* 高斯分布类 构造函数是N*1的均值矩阵和N*N的协方差矩阵 */ template <typename T, int N> class GaussianDistribution { public: GaussianDistribution(const Eigen::Matrix<T, N, 1>& mean, const Eigen::Matrix<T, N, N>& covariance) : mean_(mean), covariance_(covariance) {} const Eigen::Matrix<T, N, 1>& GetMean() const { return mean_; } const Eigen::Matrix<T, N, N>& GetCovariance() const { return covariance_; } private: Eigen::Matrix<T, N, 1> mean_; //N*1,均值 Eigen::Matrix<T, N, N> covariance_; //N*N。协方差 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
高斯 相加
-
均值:均值+均值
-
协方差:协方差+协方差
-
/*高斯分布性质: https://zh.wikipedia.org/wiki/%E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83 */ template <typename T, int N> GaussianDistribution<T, N> operator+(const GaussianDistribution<T, N>& lhs, const GaussianDistribution<T, N>& rhs) { return GaussianDistribution<T, N>(lhs.GetMean() + rhs.GetMean(), lhs.GetCovariance() + rhs.GetCovariance()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
高斯 相乘
-
均值: ( N × M ) ⋅ ( M × 1 ) = ( N × 1 ) (N\times M) \cdot (M \times 1) = (N \times 1) (N×M)⋅(M×1)=(N×1)
-
协方差: ( N × M ) ⋅ ( M × M ) ⋅ ( M × N ) = ( N × N ) (N\times M) \cdot (M \times M) \cdot (M \times N) = (N \times N) (N×M)⋅(M×M)⋅(M×N)=(N×N)
-
templateGaussianDistribution - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
UKF 代码实现
卡尔曼滤波器的操作包括两个阶段:
- 预测与更新。在预测阶段,滤波器使用上一状态的估计,做出对当前状态的估计。
- 在更新阶段,滤波器利用对当前状态的观测值优化在预测阶段获得的预测值,以获得一个更精确的新估计值。
类
templateclass UnscentedKalmanFilter { public: using StateType = Eigen::Matrix void Observe( std::function & states) { StateType weighted_error = kMeanWeight0 * compute_delta_(mean_estimate, states[0]); for (int i = 1; i != 2 * N + 1; ++i) { weighted_error += kMeanWeightI * compute_delta_(mean_estimate, states[i]); } return weighted_error; } //计算均值。基于权重误差评判计算 StateType ComputeMean(const std::vector & states) { CHECK_EQ(states.size(), 2 * N + 1); StateType current_estimate = states[0]; StateType weighted_error = ComputeWeightedError(current_estimate, states); int iterations = 0; while (weighted_error.norm() > 1e-9) { double step_size = 1.; while (true) { const StateType next_estimate = add_delta_(current_estimate, step_size * weighted_error); const StateType next_error = ComputeWeightedError(next_estimate, states); if (next_error.norm() < weighted_error.norm()) { current_estimate = next_estimate; weighted_error = next_error; break; } step_size *= 0.5; CHECK_GT(step_size, 1e-3) << "Step size too small, line search failed."; } ++iterations; CHECK_LT(iterations, 20) << "Too many iterations."; } return current_estimate; } // 常值确定参数 sqr=a*a, OuterProduct=V*V^T N*1 || 1*N -> 外积,N*N constexpr static FloatType kAlpha = 1e-3; constexpr static FloatType kKappa = 0.; constexpr static FloatType kBeta = 2.; constexpr static FloatType kLambda = sqr(kAlpha) * (N + kKappa) - N; constexpr static FloatType kMeanWeight0 = kLambda / (N + kLambda); constexpr static FloatType kCovWeight0 = kLambda / (N + kLambda) + (1. - sqr(kAlpha) + kBeta); constexpr static FloatType kMeanWeightI = 1. / (2. * (N + kLambda)); constexpr static FloatType kCovWeightI = kMeanWeightI; // 成员变量 //1),N*1矩阵,对N个变量的估计 GaussianDistribution constexpr FloatType UnscentedKalmanFilter constexpr FloatType UnscentedKalmanFilter constexpr FloatType UnscentedKalmanFilter constexpr FloatType UnscentedKalmanFilter constexpr FloatType UnscentedKalmanFilter constexpr FloatType UnscentedKalmanFilter constexpr FloatType UnscentedKalmanFilter constexpr FloatType UnscentedKalmanFilter - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
预测
步骤:
-
1、判断协方差 为对称矩阵 2、取当前状态的均值和 协方差开方根 (生成Sigma点要用) 3、计算状态转移矩阵,均值+协方差 均值直接权重相加,然后基于误差在一定范围得到`最优均值` 协方差 直接基于 `最优均值` 重新计算 4、更新状态 均值+协方差- 1
- 2
- 3
- 4
- 5
- 6
代码:
void Predict(std::function<StateType(const StateType&)> g, const GaussianDistribution<FloatType, N>& epsilon) { /// 1. 协方差是对称矩阵 CheckSymmetric(epsilon.GetCovariance()); // Get the state mean and matrix root of its covariance. /// 2. 取当前状态的均值+协方差开方根 const StateType& mu = belief_.GetMean(); const StateCovarianceType sqrt_sigma = MatrixSqrt(belief_.GetCovariance());//N*N // 由于UKF,采用点2N+1 std::vector<StateType> Y;//需要计算的状态矩阵,N*1矩阵。 Y.reserve(2 * N + 1);//公式:p65 /// 3. 计算状态转移矩阵,均值+协方差 Y.emplace_back(g(mu));//状态转移方程,公式p65:3.68,p70:3 const FloatType kSqrtNPlusLambda = std::sqrt(N + kLambda); for (int i = 0; i < N; ++i) { // Order does not matter here as all have the same weights in the // summation later on anyways. Y.emplace_back(g(add_delta_(mu, kSqrtNPlusLambda * sqrt_sigma.col(i)))); Y.emplace_back(g(add_delta_(mu, -kSqrtNPlusLambda * sqrt_sigma.col(i)))); } // 得到最优 均值 (误差小于阈值) const StateType new_mu = ComputeMean(Y); // 基于最新阈值重新计算新的协方差 StateCovarianceType new_sigma = kCovWeight0 * OuterProduct<FloatType, N>(compute_delta_(new_mu, Y[0])); for (int i = 0; i < N; ++i) { new_sigma += kCovWeightI * OuterProduct<FloatType, N>( compute_delta_(new_mu, Y[2 * i + 1])); new_sigma += kCovWeightI * OuterProduct<FloatType, N>( compute_delta_(new_mu, Y[2 * i + 2])); } CheckSymmetric(new_sigma); //更新状态 均值+协方差 belief_ = GaussianDistribution<FloatType, N>(new_mu, new_sigma) + epsilon; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
观测更新
步骤:
1、判断 观测均值和协方差,均值0附近,协方差对称矩阵 2、取当前状态的均值和 协方差开方根 (生成Sigma点要用) 3、计算0均值sigma点和Z,得出 总体观测均值 ,协方差 均值经转移方程后直接权重相加,得到`最新均值` 协方差 直接基于 `最新均值` 重新计算,同时加上观测自身的协方差 4、计算 (x,z)的sigma。x 即sigma,z (z_t -z_u) 5、得到 K_t 6、更新 协方差 。原协方差-ksk^T 7、更新状态 均值+协方差- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
代码实现:
/** * @brief Observe 观测步骤 * @param h 'h' 将状态转换为应该为零的观察值,传感器读数应该已经包含在这个函数中。 * @param delta 'delta' 是测量噪声,必须具有零均值。 */ void Observe( std::function<Eigen::Matrix<FloatType, K, 1>(const StateType&)> h, const GaussianDistribution<FloatType, K>& delta) { /// 1. 观测均值0附近,观测协方差是对称矩阵 CheckSymmetric(delta.GetCovariance()); // We expect zero mean delta. CHECK_NEAR(delta.GetMean().norm(), 0., 1e-9); /// 2. 取当前状态的均值+协方差开方根 // Get the state mean and matrix root of its covariance. const StateType& mu = belief_.GetMean(); const StateCovarianceType sqrt_sigma = MatrixSqrt(belief_.GetCovariance()); // As in Kraft's paper, we compute W containing the zero-mean sigma points, // since this is all we need. // 计算0均值的sigma点,及转移后的sigma值 std::vector<StateType> W; W.reserve(2 * N + 1); W.emplace_back(StateType::Zero()); std::vector<Eigen::Matrix<FloatType, K, 1>> Z; Z.reserve(2 * N + 1); Z.emplace_back(h(mu)); /// 3. 计算0均值sigma点和Z,得出 总体观测均值 Eigen::Matrix<FloatType, K, 1> z_hat = kMeanWeight0 * Z[0]; const FloatType kSqrtNPlusLambda = std::sqrt(N + kLambda); for (int i = 0; i < N; ++i) { // Order does not matter here as all have the same weights in the // summation later on anyways. W.emplace_back(kSqrtNPlusLambda * sqrt_sigma.col(i)); Z.emplace_back(h(add_delta_(mu, W.back()))); W.emplace_back(-kSqrtNPlusLambda * sqrt_sigma.col(i)); Z.emplace_back(h(add_delta_(mu, W.back()))); z_hat += kMeanWeightI * Z[2 * i + 1]; z_hat += kMeanWeightI * Z[2 * i + 2]; } /// 4. 得出总体观测的 协方差(递推协方差+自身协方差) Eigen::Matrix<FloatType, K, K> S = kCovWeight0 * OuterProduct<FloatType, K>(Z[0] - z_hat); for (int i = 0; i < N; ++i) { S += kCovWeightI * OuterProduct<FloatType, K>(Z[2 * i + 1] - z_hat); S += kCovWeightI * OuterProduct<FloatType, K>(Z[2 * i + 2] - z_hat); } CheckSymmetric(S); // 递推协方差 对称矩阵 S += delta.GetCovariance(); /// 5. 计算Sigma_x,z Eigen::Matrix<FloatType, N, K> sigma_bar_xz = kCovWeight0 * W[0] * (Z[0] - z_hat).transpose(); for (int i = 0; i < N; ++i) { sigma_bar_xz += kCovWeightI * W[2 * i + 1] * (Z[2 * i + 1] - z_hat).transpose(); sigma_bar_xz += kCovWeightI * W[2 * i + 2] * (Z[2 * i + 2] - z_hat).transpose(); } /// 6. 计算 K_t,更新协方差 const Eigen::Matrix<FloatType, N, K> kalman_gain = sigma_bar_xz * S.inverse(); const StateCovarianceType new_sigma = belief_.GetCovariance() - kalman_gain * S * kalman_gain.transpose(); CheckSymmetric(new_sigma); /// 7. 更新 状态方程 belief_ = GaussianDistribution<FloatType, N>( add_delta_(mu, kalman_gain * -z_hat), new_sigma); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
点评
- 预测、更新的状态方程都可以动态给出
- 代码结构清晰,属实不错
- KF 系列求解:
-
相关阅读:
构建企业全生命周期数字化资产管理新模式
UVA-548 树 题解答案代码 算法竞赛入门经典第二版
Apollo之Docker部署
linux uname详解 -s -r -a 查看内核版本
torch_flops: 准确捕获forward中所有算子的FLOPs计算库
uniapp实现发送获取验证码
【freertos】007-系统节拍和系统延时管理实现细节
自然语言处理学习笔记(十)———— 停用词过滤
Fiddler抓取的一些问题
机器学习入门到大神专栏总览
- 原文地址:https://blog.csdn.net/xiaoma_bk/article/details/128191327
